GuardReasoner
GuardReasoner: Towards Reasoning-based LLM Safeguards
As LLMs increasingly impact safety-critical applications, ensuring their safety using guardrails remains a key challenge. This paper proposes GuardReasoner, a new safeguard for LLMs, by guiding the guard model to learn to reason. Concretely, we first create the GuardReasonerTrain dataset, which consists of 127K samples with 460K detailed reasoning steps. Then, we introduce reasoning SFT to unlock the reasoning capability of guard models. In addition, we present hard sample DPO to further strengthen their reasoning ability. In this manner, GuardReasoner achieves better performance, explainability, and generalizability. Extensive experiments and analyses on 13 benchmarks of 3 guardrail tasks demonstrate its superiority. Remarkably, GuardReasoner 8B surpasses GPT-4o+CoT by 5.74% and LLaMA Guard 3 8B by 20.84% F1 score on average. We release the training data, code, and models with different scales (1B, 3B, 8B) of GuardReasoner : https://github.com/yueliu1999/GuardReasoner/.
概述 (Content) ¶
GuardReasoner 是一种通过基于推理的安全措施来使大型语言模型 (LLMs) 更安全的新方法。
传统护栏的缺点:
- Performance: they are typically trained using straightforward instruction tuning, limiting reasoning ability and performance.
- Explainability: they mainly function as classifiers that merely provide moderation results, lacking explainability.
- Generalization: they struggle to handle new types of harm due to their reliance on manually designed harmful categories.
DeepSeek-R1 等推理模型促使模型解决问题的能力大幅提高,而现有知名 llm guard 本身均为可视作分类器的大模型,将推理能力引入 guard 、结合显式的推理步骤,在识别输入 / 出中有害内容准确性大幅提高。
方法 (How) ¶
- 训练方法:
- Reasoning data synthesis
- 收集指令微调数据,并使用 GPT-4o 进行 synthesize reasoning processes,获得推理过程,形成 GuardReasonerTrain dataset;
- Reasoning supervised fine-tuning (RSFT)
- 使用上一步收集的数据进行,释放模型的基础推理能力;
- Hard Sample Direct Preference Optimization (HS-DPO)
- 回答正确,连带推理过程视作 positive item,否则视为 negative item;
- 引导模型更关注 hard sample,降低 positive item 的权重。
- Reasoning data synthesis
- Comparison experiment of 25 models on 5 benchmarks of the response harmfulness detection task.
1741845507038.png
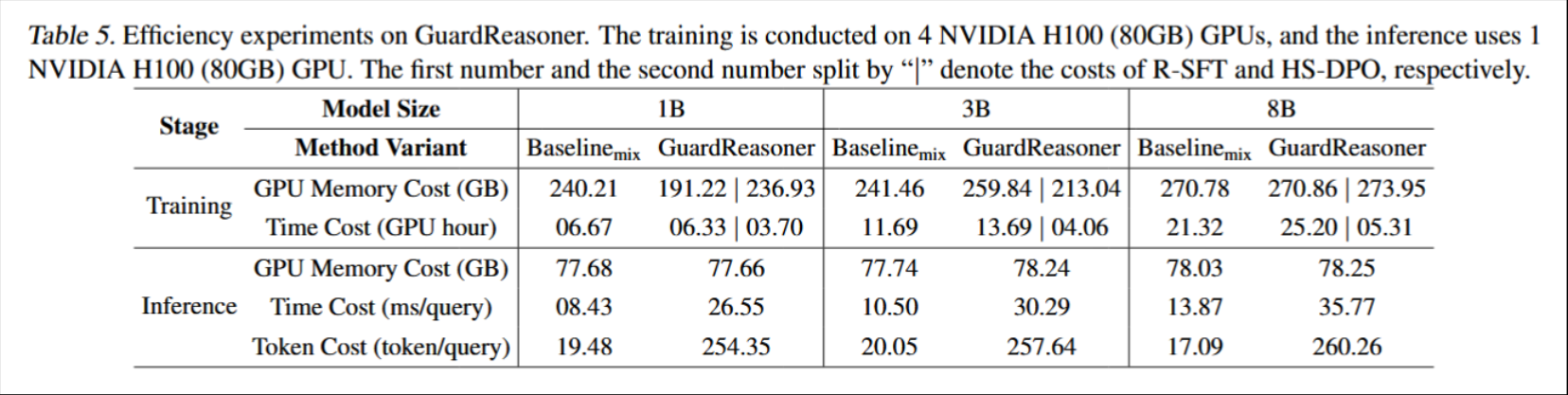
- 在上面的效率测试的结果可以看到,无论是训练时还是推理时,GPU 内存消耗基本不变,但是用时和 token 消耗大幅度提高,实际应用成本过高。
贡献 (Contribution) ¶
- 生成了一个用于训练护栏推理能力的数据集;
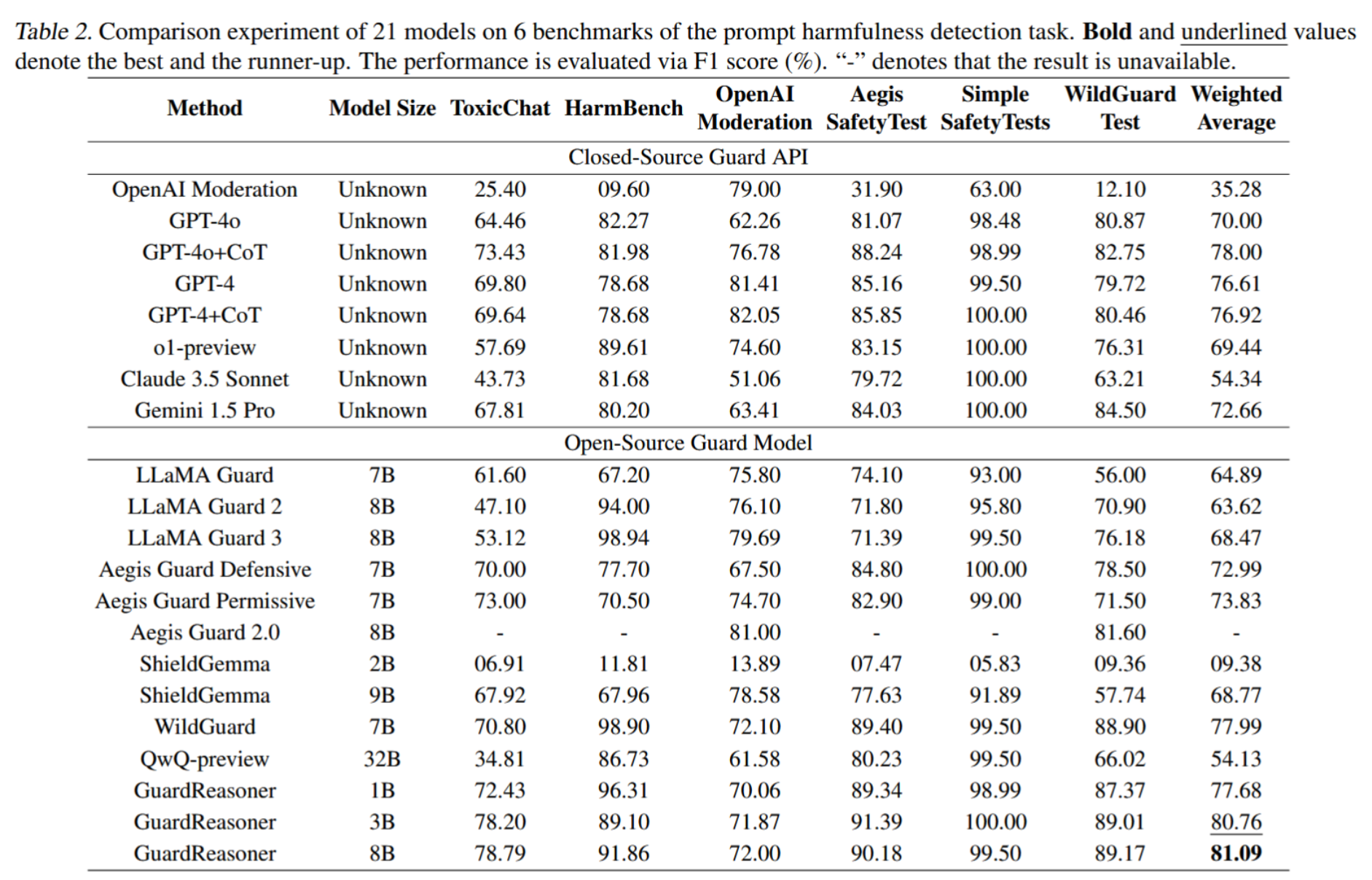
- 相比于传统的大模型护栏,GuardReasoner 通过引入推理能力实现了 performance, explainability, and generalizability 的综合提高,具体数据如下:
250313-153110.png
总结 (Summary) ¶
GuardReasoner 在安全系统方面代表了重要进步。其基于推理的方法提供了更细腻和准确的内容过滤,同时减少了误报。该技术有助于使 AI 系统在实际应用中更加可信和可靠。
但是从训练过程来看,GuardReasoner 更像是把 GPT-4o 对输入 / 出是否有害的判断能力蒸馏出来,随后进行微调以及一些操作,引入推理来提高护栏的判断准确度,进一步可挖掘空间小(感觉前沿大语言模型有什么提高能力的新进展,迁移到大护栏就成了……