指令级并行 (ILP) ¶
指令级并行(Instruction-Level Parallelism, ILP)是指处理器在同一时间执行多条指令的能力。这是通过利用指令之间的独立性来实现的,从而提高程序的执行效率。在现代处理器设计中,ILP 是一个核心概念,它通过流水线(Pipelining
流水线技术回顾 (page 2) ¶
流水线是一种通过重叠指令的执行来提高处理器吞吐量的技术。它将指令执行过程分解为多个阶段,不同指令的这些阶段可以并行执行。就像洗衣店的例子(page 2)所示,通过将洗衣、烘干、折叠等任务并行化,可以显著缩短完成多件衣物所需的总时间。
依赖关系 (Dependences) ¶
在流水线执行中,指令之间的依赖关系是导致流水线停顿(Stall)的主要原因。理解这些依赖关系对于优化流水线性能至关重要。
数据依赖 (Data Dependences) (page 3) ¶
数据依赖是指一条指令的执行需要前一条指令产生的结果。数据依赖可以分为以下三种类型:
-
写后读 (Read After Write, RAW) (page 7)
- 定义:一条指令尝试读取一个寄存器或存储器位置,而该位置在之前的指令中被写入。
- 示例 (page 7):
在这里,
FSUB.D指令读取F6,而F6是由FADD.D指令写入的。如果FSUB.D在FADD.D完成写入之前读取F6,就会导致不正确的结果。
-
读后写 (Write After Read, WAR) (page 7)
- 定义:一条指令尝试写入一个寄存器或存储器位置,而该位置在之前的指令中被读取。这是一种名称依赖(Name Dependence
) 。 - 示例 (page 7):
在这里,
FADD.D尝试写入F6,而FDIV.D在此之前读取了F6。如果FADD.D的写入过早发生,可能会破坏FDIV.D所需的旧值。
- 定义:一条指令尝试写入一个寄存器或存储器位置,而该位置在之前的指令中被读取。这是一种名称依赖(Name Dependence
-
写后写 (Write After Write, WAW) (page 7)
- 定义:两条指令尝试写入相同的寄存器或存储器位置。这同样是一种名称依赖。
- 示例 (page 7):
在这里,
FDIV.D和FSUB.D都尝试写入F2。如果FSUB.D的写入在FDIV.D之后完成,但FDIV.D的写入被覆盖,或者写入顺序颠倒,会导致F2最终的值不正确。
Note
在经典的五级整型流水线中,由于指令按序执行且写回(WB)阶段在最后,WAR 和 WAW 冒险通常不会发生。然而,在更复杂的乱序执行处理器中,它们是必须解决的关键问题。
名称依赖 (Name Dependences) (page 4) ¶
名称依赖是指两条指令使用相同的寄存器或存储器位置,但这些位置并不用于传递真实的数据值。它们是由指令对相同名称(寄存器或内存地址)的使用引起的。名称依赖可以分为 WAR 和 WAW 两种类型。
-
反依赖 (Anti-dependence) (WAR): 当一条指令的输出寄存器与前面指令的输入寄存器相同,并且执行顺序颠倒会破坏输入值时,发生反依赖。
- 示例 (page 4):
Text Only在这里,
FDIV.D F2, F6, F4 (Instruction 1: uses F6 as source) FADD.D F6, F0, F12 (Instruction 2: writes to F6) FSUB.D F8, F6, F14 (Instruction 3: uses F6 as source)FADD.D写入F6,而FDIV.D和FSUB.D读取F6。如果FADD.D提前完成写入,会导致FDIV.D和FSUB.D读取到错误的值。通过寄存器重命名(Register Renaming),可以将F6替换为新的临时寄存器S,从而消除这种依赖,如附件所示:
- 示例 (page 4):
-
输出依赖 (Output-dependence) (WAW): 当两条指令写入同一个寄存器时,发生输出依赖。
寄存器重命名 (Register Renaming)
寄存器重命名是一种硬件技术,用于消除名称依赖(WAR 和 WAW 冒险
控制依赖 (Control Dependences) (page 5) ¶
控制依赖是指一条指令的执行是否发生,取决于前面一条分支指令的结果。 - 示例 (page 5):
在这里,Statement 1 的执行依赖于 p1 的结果,而 Statement 2 的执行依赖于 p2 的结果。在流水线中,如果分支条件未能及时确定,会导致流水线无法确定下一条要取出的指令,从而造成停顿。
冒险 (Hazards) (page 6) ¶
冒险是流水线中阻止下一条指令在下一个时钟周期开始执行的情况。它们阻碍了流水线的理想吞吐量。
依赖 (Dependency) vs. 冒险 (Hazard)
- 依赖是程序的固有属性,存在于指令之间,与硬件实现无关。
- 冒险是特定流水线结构在遇到特定依赖时产生的问题。一条指令因为冒险而无法在预定的时钟周期执行。
换言之,不同的流水线设计可能会将同一个依赖关系表现为不同的冒险,或者通过某些技术(如转发)来避免冒险的发生。
-
结构冒险 (Structure Hazards) (page 6)
- 定义:当所需的硬件资源忙碌时发生。例如,如果只有一条内存端口,而指令需要同时访问指令存储器和数据存储器,就会发生结构冒险。
- 解决方案:复制资源(如哈佛结构分离指令和数据缓存)或增加流水线级数。
-
数据冒险 (Data Hazards) (page 6, 8-15)
- 定义:当一条指令需要等待前一条指令完成数据读 / 写操作时发生。
- 类型:RAW, WAR, WAW(如前所述
) 。 - 转发 (Forwarding) / 旁路 (Bypassing) (page 8-10):
- 这是一种硬件技术,用于解决 RAW 冒险。它通过将前一条指令的计算结果直接转发给后续需要该结果的指令,而不需要等待结果写回寄存器文件。例如,ALU 计算结果可以在 ALU 阶段结束时直接转发给下一条指令的 ALU 输入,从而避免一个时钟周期的停顿。附件中的图示清晰地展示了数据如何通过红色箭头从一个指令的执行阶段直接传送到另一个指令的执行阶段。
- 带气泡的转发 (Forwarding with Bubble) (page 11-12):
- 尽管有转发机制,某些数据依赖关系仍然可能导致停顿(“气泡”或“泡泡”,Bubble
) 。例如,加载指令(LD)的结果通常在内存访问阶段之后才可用。如果紧随其后的指令需要这个加载结果,即使有转发,也可能需要一个或多个时钟周期的停顿,因为数据尚未从内存中取出。附件中的表格(page 12)展示了加载指令LD R1, 0(R2)后,DADD R4, R1, R5需要等待R1的值,导致stall。
- 尽管有转发机制,某些数据依赖关系仍然可能导致停顿(“气泡”或“泡泡”,Bubble
- 代码调度以避免停顿 (Code Scheduling to Avoid Stalls) (page 13-15):
- 这是一种编译器技术,通过重新排列指令顺序来减少或消除停顿。其核心思想是,将没有依赖关系的指令插入到可能导致停顿的指令之间,从而填补空闲的流水线槽。
代码调度示例 (page 13-15)
原始代码序列 :
// A = B + C; D = E - F
LD Rb, B
LD Rc, C
DADD Ra, Rb, Rc // stall, 等待 Rc
SD Ra, A
LD Re, E
LD Rf, F
DSUB Rd, Re, Rf // stall, 等待 Rf
SD Rd, D
调度后代码序列 :
通过插入不相关的加载指令,成功避免了暂停。在 page 15 的例子中,通过指令重排,执行周期从 13 个减少到了 11 个。- 控制冒险 (Control Hazards) (page 6, 16-19)
- 定义:当流水线无法确定下一条要取出的指令时发生,通常由分支指令引起。
- 分支决定控制流 (Branch determines flow of control) (page 16):
- 处理器需要根据分支指令的条件(例如
if语句)来确定下一条指令的地址。然而,在流水线中,分支指令的条件判断和目标地址计算通常发生在较晚的阶段(如 ID 或 EX 阶段) 。 - RISC-V 流水线中,为了提前确定分支结果,需要额外的硬件来在 ID 阶段比较寄存器并计算目标地址。
- 处理器需要根据分支指令的条件(例如
- 分支停顿 (Stall on Branch) (page 17-18):
- 最简单的处理方式是当遇到分支指令时,停顿流水线,直到分支结果确定并且下一条指令地址明确。这会引入显著的性能损失。
- 附件中的表格(page 17)展示了分支无论被“采用”(taken)还是“不采用”(not taken
) ,都会导致后续指令的多个周期停顿。
- 等待分支结果 (Wait until branch outcome determined) (page 19):
- 这是一种直观但效率低下的处理方式,即在分支结果确定之前,不取下一条指令,流水线会填充“气泡”直至分支目标确定。
- 延迟槽 (Delay Slot) (page 22)
- 这是一种架构特性(在早期 RISC 如 MIPS, SPARC 中使用
) ,分支指令后面的那条指令(位于延迟槽中)无论分支是否跳转都会被执行。编译器负责找到一条有用的指令(或NOP)来填充这个延迟槽。
- 这是一种架构特性(在早期 RISC 如 MIPS, SPARC 中使用
延迟槽的现代观点 (page 32)
延迟槽在简单的流水线中能有效减少分支延迟。但它将流水线的微架构细节暴露给了指令集架构(ISA
分支预测 (Branch Prediction) (page 20) ¶
为了减少控制冒险造成的停顿,分支预测技术应运而生。处理器会预测分支的走向(Taken 或 Not Taken
-
预测分支结果 (Predict outcome of branch) (page 20):
- 如果预测正确,流水线几乎没有停顿。
- 如果预测错误,则需要冲刷流水线(Flush Pipeline
) ,并重新获取正确的指令,这将导致显著的性能损失。
-
静态分支预测 (Static Branch Prediction) (page 21):
- 基于分支的典型行为进行预测。
- 常见的策略:
- 总是预测不跳转 (Predict Not Taken):简单有效,因为很多
if条件分支不跳转。 - 基于方向的预测:向后跳转(通常是循环)预测为跳转,向前跳转(通常是条件判断)预测为不跳转。
- 总是预测不跳转 (Predict Not Taken):简单有效,因为很多
- 动态分支预测 (Dynamic Branch Prediction) (page 21, 33-37):
- 通过硬件记录分支的历史行为,并假设未来的行为会延续当前趋势。
- 当预测错误时,流水线会停顿以便重新获取指令,并更新历史记录。
- 分支预测缓冲区 (Branch Prediction Buffer, BHT) (page 33-34):
- 一个存储分支历史记录的缓存,通过最近的分支指令地址进行索引。
- 存储分支结果(“采用”或“不采用”
) 。 - 执行分支时,首先检查 BHT,如果命中则根据预测结果获取指令;如果预测错误,则冲刷流水线并更新 BHT。
- 1 位预测器 (1-Bit Predictor) (page 35):
- 只存储上一次分支的结果。
- 缺点:在内层循环(Inner Loop)的最后一个迭代中容易发生两次错误预测。例如,一个循环分支在最后一次迭代时不被采用,但预测器仍然预测为采用;下一次循环开始时,它又预测为不采用,但实际应该采用,导致两次错误预测。
- 2 位预测器 (2-Bit Predictor) (page 36-37):
- 使用两个比特来存储分支历史,实现一个有限状态机(Finite State Machine, FSM
) 。 - 状态转换:例如
, “强预测采用”(Strongly Taken) 、 “弱预测采用”(Weakly Taken) 、 “弱预测不采用”(Weakly Not Taken) 、 “强预测不采用”(Strongly Not Taken) 。需要连续两次错误预测才能改变强预测的状态。 - 优点:对于循环分支,即使偶尔出现不采用的情况,也能更好地保持正确的预测,从而减少错误预测的次数(通常只在内层循环的最后一次迭代中发生一次错误预测
) 。
- 使用两个比特来存储分支历史,实现一个有限状态机(Finite State Machine, FSM
分支的数据冒险 (Data Hazards for Branches) (page 28-30) ¶
分支指令的条件判断通常依赖于之前 ALU 或加载指令的结果。这会引入数据冒险。
- 如果比较寄存器是第 2 或第 3 条先行 ALU 指令的目的(Destination
) ,可以通过转发解决,通常不会引入停顿 (page 28)。 - 如果比较寄存器是先行 ALU 指令或第 2 条先行加载指令的目的,可能需要 1 个停顿周期 (page 29)。
- 如果比较寄存器是紧邻的先行加载指令的目的,可能需要 2 个停顿周期 (page 30)。
指令交付与推测的高级技术 (Advanced Techniques for Instruction Delivery and Speculation) (page 41) ¶
为了进一步提高 ILP,处理器采用了更复杂的指令交付(Instruction Delivery)和推测(Speculation)技术。
增加指令获取带宽 (Increasing Instruction Fetch Bandwidth) (page 41) ¶
- 分支目标缓冲区 (Branch-Target Buffer, BTB) / 分支目标缓存 (Branch-Target Cache) (page 41-42, 45-47):
- BTB 是一个存储分支指令地址及其对应目标地址的缓存。
- 取指时,用 PC 同时访问指令缓存和 BTB。
- 如果 PC 在 BTB 中命中 (hit),说明这是一条之前执行过的分支指令。
- 使用 BTB 中的预测位来预测分支行为。
- 如果预测跳转 (Taken),则直接使用 BTB 中存储的目标地址作为下一个 PC,从而实现零延迟的分支跳转。
- 如果预测不跳转 (Not Taken) 或 BTB 未命中 (miss),则正常执行 (PC+4)。
- 当分支指令最终在 EX 阶段被解析后,如果发现预测错误,则清空流水线,并用正确的结果更新 BTB。
- 2 bits BTB 延迟周期分析 (page 46):
- BTB 命中,预测 Taken,实际 Taken:0 延迟。
- BTB 命中,预测 Taken,实际 Not Taken:2 延迟(需要冲刷流水线
) 。 - BTB 未命中,预测 Not Taken,实际 Taken:2 延迟(需要计算目标地址并冲刷流水线
) 。 - BTB 未命中,预测 Not Taken,实际 Not Taken:0 延迟。
- 优势 (page 47):
- 更快地获取分支目标处的指令。
- 可以一次性提供多条分支目标处的指令,这对于多处理器系统是必要的。
- 分支折叠 (Branch Folding):在某些情况下,可以实现无延迟的无条件分支,甚至是有条件的无延迟分支。
- BTB 是一个存储分支指令地址及其对应目标地址的缓存。
专门的分支预测器 (Specialized Branch Predictors) (page 41) ¶
- 除了通用的分支预测器,还有针对特定类型分支的预测器,例如:
- 预测过程返回(Procedure Returns)
- 间接跳转(Indirect Jumps)
- 循环分支(Loop Branches)
集成指令获取单元 (Integrated Instruction Fetch Units) (page 43) ¶
- 现代处理器将多个指令获取功能集成到一个单元中,包括:
- 集成化的分支预测。
- 指令预取(Instruction Prefetch
) 。 - 指令存储器访问和缓冲。
- 指令获取不再是一个简单的单流水线阶段,因为它涉及多指令发射(Multiple Issue)的复杂性。
计算分支目标 (Calculating the Branch Target) (page 44-45) ¶
- 即使有分支预测器,仍然需要计算目标地址。
- 对于被采用的分支,即使预测正确,仍然可能存在 1 个周期的延迟,因为目标地址的计算需要时间。
- 分支目标缓冲(BTB)通过缓存目标地址来加速这一过程。
动态调度 (Dynamic Scheduling) (§2.1 Dynamic Scheduling, page 52) ¶
简单流水线技术的一个主要限制是它们使用按序指令发射和执行(in-order instruction issue and execution
顺序流水线的性能瓶颈 (page 52)
FDIV.D F4, F0, F2 // 长延迟指令
FSUB.D F10, F4, F6 // 依赖于 FDIV.D
FADD.D F12, F6, F14 // 与前两条指令无数据依赖
FSUB.D 因为等待 FDIV.D 的结果而暂停。这会导致完全独立的 FADD.D 也无法执行,造成了硬件资源的浪费。
乱序执行 (Out-of-Order Execution)
乱序执行是指处理器在指令准备就绪时(即其操作数可用且没有结构冒险)就执行它们,而不必严格按照程序顺序。这有助于填充流水线空闲槽,从而提高 ILP。
-
动态调度的核心思想(page 53):将 ID(指令译码)阶段拆分为两个子阶段:
- 发射 (Issue, IS) (page 55):
- 按程序顺序解码指令。
- 检查结构冒险:判断是否有可用的功能单元(Functional Unit)和保留站(Reservation Station
) 。 - 如果找到匹配的空闲保留站,则将指令发射到该站,并获取其操作数的值(如果操作数已经在寄存器中
) 。如果操作数尚未可用,则记录哪个功能单元将产生该操作数。 - 这一步负责寄存器重命名(Register Renaming
) ,消除 WAR 和 WAW 冒险。
- 读取操作数 (Read Operands, RO) (page 55):
- 等待所有操作数可用(即数据依赖解决
) 。 - 一旦操作数可用,指令就可以乱序执行。
- 等待所有操作数可用(即数据依赖解决
- 发射 (Issue, IS) (page 55):
-
引入冒险 (Hazards Introduced) (page 56):
- 乱序执行引入了 WAR 和 WAW 冒险的可能性,这些冒险在简单的五级整数流水线中通常不会出现,但在浮点流水线中可能出现。
- 示例 (page 56):
Text Only这里的
FDIV.D F10, F0, F2 // Writes F10 FSUB.D F10, F4, F6 // Writes F10 (WAW with FDIV.D) FADD.D F6, F8, F14 // Writes F6, Reads F8, F14FSUB.D和FDIV.D之间存在 WAW 冒险,因为它们都写入F10。FADD.D与FSUB.D之间可能存在 WAR 冒险(如果FADD.D写F6而FSUB.D读F6)。
记分板算法 (Scoreboard Algorithm) (page 57-66) ¶
记分板的四个阶段 ¶
- Issue ( 发射 ): 如果指令所需的功能单元空闲且没有 WAW 冒险,就发射该指令。
- Read Operands ( 读操作数 ): 监控源寄存器,一旦所有源操作数都可用(即没有 RAW 冒险
) ,就读取操作数。 - Execution ( 执行 ): 操作数就绪后,功能单元开始执行。
- Write Result ( 写回 ): 执行完毕后,如果目标寄存器没有被之前的指令读取(即没有 WAR 冒险
) ,就将结果写回寄存器。
记分板维护三张状态表 ¶
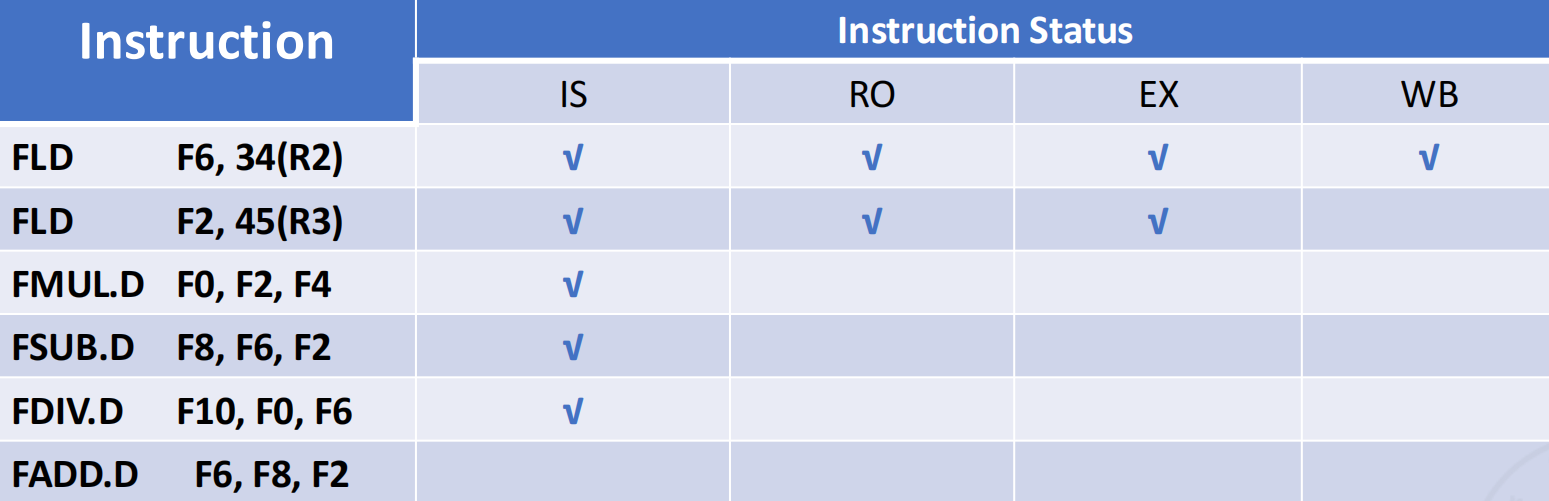
-
指令状态表 (Instruction Status): 记录每条指令处于哪个阶段(Issue, Read, Exec, Write
) 。
- 功能单元状态表 (Function Component Status): (page 60) 记录每个功能单元(如 Integer, Mult, Add)的状态。
Busy: 功能单元是否繁忙。Op: 正在执行的操作。Fi,Fj, Fk: 目标寄存器和源寄存器。Qj, Qk: 产生源操作数的功能单元(用于解决 RAW 冒险) 。Rj, Rk: 源操作数是否已就绪将被读取。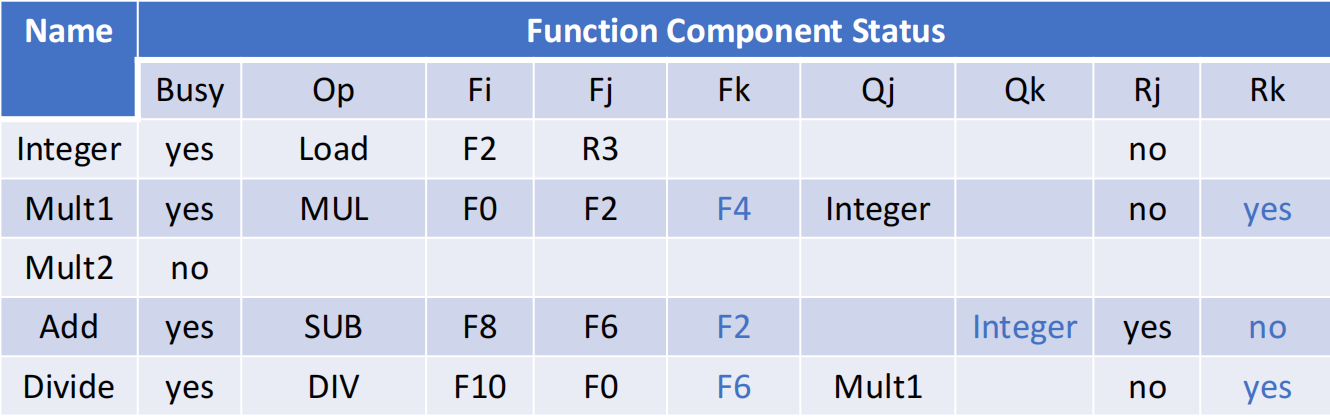
-
寄存器结果状态表 (Register Status): (page 60) 记录每个寄存器将由哪个功能单元写入。

记分板示例分析 (page 58-64)
考虑代码序列:
- 当第一条FLD F6 完成写回时 (page 59-60):
- FLD F6 已完成所有阶段。FLD F2 已发射,正在等待其执行单元完成。
- FMUL.D 已发射,它在等待 F2(由 FLD F2 产生)和 F4(假设已就绪)。它的 Qj 字段会指向 Integer 单元(因为 FLD F2 在此执行),Rj 为 "no"。
- FSUB.D 已发射,它在等待 F2 和 F6。由于 F6 已就绪,Rk 为 "yes";F2 未就绪,Qj 指向 Integer 单元,Rj 为 "no"。
- 寄存器状态表中,F2 的结果将由 Integer 单元产生,F0 由 Mult1 产生,F8 由 Add 单元产生。
记分板通过这些表格来判断指令何时可以进入下一阶段,从而实现了有限的乱序执行。但它的主要缺点是:
- 集中式控制:记分板成为瓶颈。
- 无法处理 WAR 和 WAW:当存在 WAR 或 WAW 冒险时,指令在发射阶段就会被暂停,限制了 ILP 的发掘。
- 每个时钟周期只发射一条指令。
Tomasulo 算法 (Tomasulo’s Approach) (page 67)¶
Tomasulo 算法是另一种更先进的动态调度方法,由 IBM 360/91 处理器首次采用。它通过使用保留站(Reservation Stations)和公共数据总线(Common Data Bus, CDB)来进一步提高乱序执行的效率。
- 主要思想 (Main Idea) (page 70):
- 分布式控制: 使用保留站 (Reservation Stations, RS) 来替代集中的记分板。每个功能单元有多个保留站。
- 寄存器重命名: 当一条指令发射时,它被分配到一个保留站。保留站会记录指令所需操作数的值(如果可用)或来源(即哪个保留站会产生这个值
) 。目标寄存器名被重命名为这个保留站的标识符(tag) 。这样,后续指令会直接从产生结果的保留站获取数据,而不是从原始寄存器,从而消除了名依赖。 - 公共数据总线 (Common Data Bus, CDB): 这是一个广播总线。当任何功能单元完成计算后,它会把结果(值)和它的来源标识(tag)一起广播到 CDB 上。所有正在等待这个结果的保留站会“监听”CDB,并捕获它们需要的数据。
- 三个阶段 (Three Steps) (page 71-73):
- 发射 (Issue) (page 71):
- 从指令队列头部获取下一条指令。
- 如果有一个匹配的空闲保留站,将指令发射到该站。
- 如果操作数在寄存器中可用,则将它们的值复制到保留站;否则,记录将产生这些操作数的功能单元。
- 如果保留站或缓冲区不足,则指令停顿,直到资源可用(结构冒险
) 。 - 这一步通过重命名寄存器来消除不在寄存器中的 WAR 和 WAW 冒险。
- 执行 (Execute) (page 72):
- 当所有操作数都可用时,操作在对应的功能单元中执行。
- 加载(Load)和存储(Store)指令需要两步执行:首先计算有效地址(当基址寄存器可用时
) ,然后将有效地址放入加载或存储缓冲区。
- 写入结果 (Write Results) (page 73):
- 当结果可用时,通过公共数据总线(CDB)广播结果。
- 所有等待该结果的保留站和寄存器(包括存储缓冲区)都会从 CDB 获取结果并更新自己的操作数。
- 存储指令在存储缓冲区中缓冲,直到待存储的值和存储地址都可用,然后尽快写入内存单元。
- 发射 (Issue) (page 71):
- Tomasulo 结构 (Basic Structure of a Floating-Point Unit using Tomasulo’s Algorithm) (page 69, 74-77):
- 指令队列 (Instruction Queue): 存储待发射的指令。
- 浮点寄存器 (FP Registers): 存储浮点数值,并带有一个
Qi字段(Register status Qi) ,指示哪个保留站将写入该寄存器的结果。 - 加载缓冲区 (Load Buffers) / 存储缓冲区 (Store Buffers): 用于处理内存加载和存储操作。
- 保留站 (Reservation Stations): 存储等待操作数和功能单元的指令。每个保留站有以下字段 (page 79):
Op( 操作 ): 要执行的操作。Qj,Qk( 源功能单元 ): 将产生相应源操作数的功能单元的名称。Vj,Vk( 源操作数值 ): 源操作数的值(如果已可用) 。Busy( 忙碌 ): 该保留站是否被占用。A( 地址 ): 用于内存地址计算。
- 公共数据总线 (Common Data Bus, CDB): 一条广播总线,所有功能单元将计算结果发布到 CDB 上,所有等待这些结果的保留站和寄存器都可以在一个周期内获取。
- Tomasulo 数据流 (Data flow)
- 指令从 Instruction queue 发射到 Reservation stations。
- 发射时,如果操作数在 FP registers 中就绪,值被直接送到 RS。
- 如果操作数未就绪,Register status Qi 表提供产生该操作数的 RS 的 Tag,该 Tag 被送到当前 RS。
- 当 RS 的操作数都就绪,它就在对应的 FP adder 或 FP multiplier 中执行。
- 执行结果通过 Common data bus (CDB) 广播。
- 所有等待该结果的 RS 和 FP registers 监听 CDB 并捕获结果。
- Tomasulo 算法与示例 (Tomasulo’s Algorithm and Examples) (page 80-84):
- 附件中提供了具体的代码序列
FLD F6, 34(R2),FLD F2, 45(R3),FMUL.D F0, F2, F4,FSUB.D F8, F2, F6,FDIV.D F10, F0, F6,FADD.D F6, F8, F2。 - 通过展示不同指令在 Issue, Execute, Write Result 阶段的进度,以及功能单元状态和寄存器状态的变化,详细演示了 Tomasulo 算法如何处理数据依赖和乱序执行。
- 例如,当第一个
FLD指令完成并写入结果后,FMUL.D等待F2的值(由第二个FLD提供) ,而FSUB.D等待F2和F6的值(F6由第一个FLD提供) 。
- 附件中提供了具体的代码序列
Tomasulo 算法的总结 (Summary of Tomasulo’s Algorithm) (page 85-87)¶
- 主要贡献 (Main Contributions) (page 85):
- 动态调度: 实现了真正的乱序执行,显著提升了 ILP。
- 硬件寄存器重命名: 通过保留站和 CDB 机制,从根本上消除了 WAR 和 WAW 冒险。
- Load/Store 解耦: Load/Store 指令有专门的缓冲区,可以独立进行地址计算和数据传输,进一步发掘并行性。
- 性能优于记分板: 性能更高,并行度更好,是现代乱序执行处理器的基础。
- 缺点 (Shortcomings) (page 86):
- 硬件复杂度高: 保留站、CDB 以及复杂的控制逻辑使得硬件设计非常复杂。
- CDB 成为瓶颈: 所有执行结果都必须通过 CDB 广播,如果功能单元很多,CDB 可能会饱和。现代处理器通常有多条 CDB。
- 内存依赖问题 (Memory Disambiguation): 算法本身不能完美解决 Load 和 Store 指令之间的内存地址依赖。例如,
LOAD addr和STORE addr,如果地址相同,它们的顺序不能颠倒。现代处理器需要额外的内存排序硬件来处理这个问题。
- ILP 限制导致多核发展 (Limitations on ILP approaches directly led to the movement to multicore) (page 87):
- 随着 ILP 技术的深入发展,其性能提升的瓶颈越来越明显,尤其是在处理分支密集、内存访问不规则的程序时。这直接推动了计算机体系结构向多核(Multicore)方向发展,通过并行执行多个线程或进程来提高整体吞吐量。
- 乱序执行不等于乱序完成 (Out-of-order execution doesn't mean out-of-order completion) (page 87):
- 这是一个关键点。乱序执行是指指令可以不按程序顺序开始执行。但为了保证程序的正确性(尤其是处理异常和精确异常
) ,指令通常仍需要按程序顺序提交(Commit)或完成(Retire) 。
- 这是一个关键点。乱序执行是指指令可以不按程序顺序开始执行。但为了保证程序的正确性(尤其是处理异常和精确异常
乱序执行 vs. 乱序完成 vs. 乱序提交
- 乱序执行 (Out-of-Order Execution): 指令的执行顺序与程序顺序不同。
- 乱序完成 (Out-of-Order Completion): 指令的完成(写回结果)顺序与程序顺序不同。Tomasulo 算法和记分板都支持乱序完成。
一个重要问题:乱序执行是否意味着乱序完成? (page 87)
是的,乱序执行通常会导致乱序完成。然而,这会带来一个严重问题:精确异常 (Precise Exceptions)。如果一条晚执行的指令(按程序顺序)先于一条早执行的指令完成,而早执行的指令发生了异常(如除零
为了解决这个问题,现代处理器引入了重排序缓冲区 (Re-Order Buffer, ROB)。指令虽然可以乱序执行和完成,但它们的结果会先写入 ROB。最终,指令会按照原始程序顺序按序提交 (in-order commit/retire),即将其结果从 ROB 正式写入寄存器堆或内存。这样既获得了乱序执行带来的高性能,又保证了异常和程序状态的精确性。
Tomasulo 算法示例分析 (page 1-2) ¶
让我们通过一个具体的例子来理解 Tomasulo 算法的工作流程。
实例分析:指令执行时间计算
假设 (page 1):
FLD( 浮点加载 ): 1 个执行周期FADD.D/FSUB.D( 浮点加 / 减 ): 2 个执行周期FMUL.D( 浮点乘法 ): 10 个执行周期FDIV.D( 浮点除法 ): 40 个执行周期- 指令发射 (Issue, IS) 和写回 (Write Back, WB) 阶段各需要 1 个时钟周期。
指令序列 :
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F2, F6FDIV.D F10, F0, F6FADD.D F6, F8, F2
执行流程追踪 (page 2) ¶
下表和时序图展示了每条指令在 Tomasulo 算法下的执行过程。
| Inst | Fi | Fj | Fk | is ( 发射 ) | ex ( 执行 ) | wb ( 写回 ) | 备注 |
|---|---|---|---|---|---|---|---|
| L.D | F6 | 34+R2 | 1 | 3 | 4 | 周期 2 计算地址,周期 3 访存,周期 4 写回。 | |
| L.D | F2 | 45+R3 | 2 | 4 | 5 | 周期 3 计算地址,周期 4 访存,周期 5 写回。 | |
| MUL.D | F0 | F2 | F4 | 3 | 6-15 | 16 | 周期 3 发射,但需等待 F2 在周期 5 完成。因此从周期 6 开始执行。 |
| SUB.D | F8 | F2 | F6 | 4 | 6-7 | 8 | 周期 4 发射,需等待 F2( 周期 5) 和 F6( 周期 4)。从周期 6 开始执行。 |
| DIV.D | F10 | F0 | F6 | 5 | 17-56 | 57 | 周期 5 发射,需等待 F0( 周期 16) 和 F6( 周期 4)。从周期 17 开始执行。 |
| ADD.D | F6 | F8 | F2 | 6 | 9-10 | 11 | 周期 6 发射,需等待 F8( 周期 8) 和 F2( 周期 5)。从周期 9 开始执行。 |
详细分析:
FLD F6( 周期 1-4): 在周期 1 发射 (is),周期 2 计算地址,周期 3 执行(访存) ,周期 4 写回 (wb)。FLD F2( 周期 2-5): 在周期 2 发射,周期 3 计算地址,周期 4 执行,周期 5 写回。FMUL.D F0( 周期 3, 6-16): 周期 3 发射。它需要F2的值,但此时F2还未就绪。F2的值在周期 5 结束时通过 CDB 广播。因此,FMUL.D可以在周期 6 开始执行。执行耗时 10 个周期(6 到 15) ,于周期 16 写回结果。FSUB.D F8( 周期 4, 6-8): 周期 4 发射。它需要F2( 周期 5 就绪 ) 和F6( 周期 4 就绪 )。两个操作数最晚在周期 5 结束时都已就绪,所以它也可以在周期 6 开始执行。执行耗时 2 个周期(6 到 7) ,于周期 8 写回。FDIV.D F10( 周期 5, 17-57): 周期 5 发射。它需要F0和F6。F6在周期 4 就绪,但F0的结果要等到FMUL.D在周期 16 写回后才可用。因此,FDIV.D必须等到周期 17 才能开始执行。执行耗时 40 个周期(17 到 56) ,于周期 57 写回。FADD.D F6( 周期 6, 9-11): 周期 6 发射。它需要F8( 周期 8 就绪 ) 和F2( 周期 5 就绪 )。最晚的操作数F8在周期 8 结束时就绪,所以它从周期 9 开始执行。执行耗时 2 个周期(9 到 10) ,于周期 11 写回。
关键观察点
- 乱序执行 (OoO):
FSUB.D虽然在FMUL.D之后,但它先于FMUL.D完成执行和写回 ( 周期 8 vs 周期 16)。 - 消除 WAR 和 WAW 冒险:
- WAR:
FADD.D需要F6的旧值(来自FLD) ,但它在FDIV.D之后。如果严格按序,FDIV.D会先读F6。在这里,FADD.D和FDIV.D各自从保留站获取F6的值(或等待其值的 CDB 广播) ,互不影响。 - WAW:
FADD.D的目标寄存器是F6,与第一条指令FLD F6相同。在 Tomasulo 算法中,当FADD.D发射时,寄存器状态表会指向FADD.D所在的保留站。之后任何需要F6的指令都会从FADD.D的保留站获取结果,从而解决了冲突。旧的FLD F6的结果可能被后续指令使用(如FSUB.D) ,也可能因为被新的FADD.D覆盖而不再需要。
- WAR:
Tomasulo 算法的硬件结构 (page 3) ¶
下图展示了采用 Tomasulo 算法的浮点单元的基本结构。
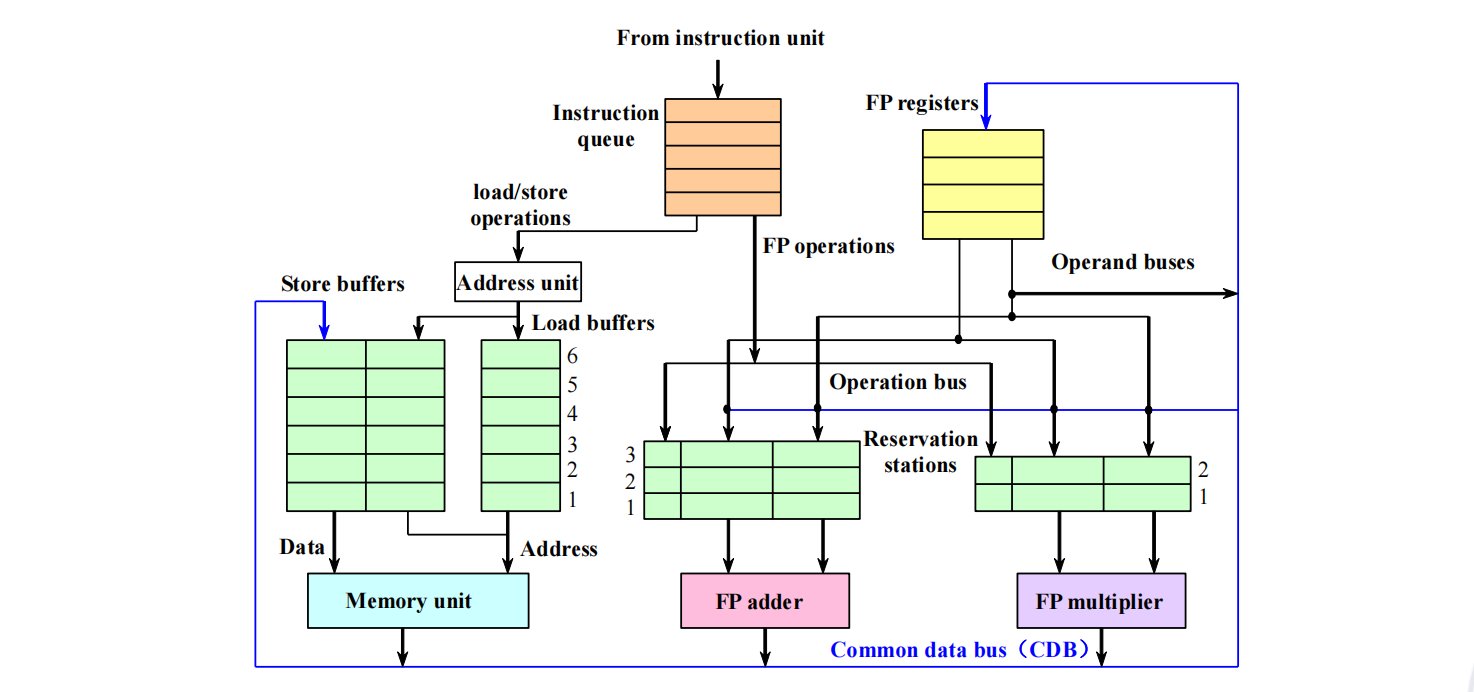
- 指令队列 (Instruction Queue): 缓存从指令提取单元送来的指令。
- 保留站 (Reservation Stations): 这是算法的核心。每种功能单元(如加法器、乘法器)都有一组保留站。当指令发射时,它被送到一个空闲的保留站。保留站会保存指令的操作码、操作数的值(如果可用)或者等待操作数的保留站标识 (Qj, Qk)。
- 加载 / 存储缓冲区 (Load/Store Buffers): 专门处理访存指令。加载缓冲区负责计算地址并从内存读取数据;存储缓冲区负责计算地址并向内存写入数据。
- 公共数据总线 (Common Data Bus, CDB): 连接了所有功能单元、保留站和浮点寄存器。当任何单元完成计算,它会把结果连同其来源(保留站标识)一起广播到 CDB 上。所有正在等待这个结果的单元(保留站、存储缓冲区)会“监听”CDB 并捕获它们需要的数据。
- 浮点寄存器 (FP Registers): 除了存储数据值,每个寄存器还有一个
Qi字段,用于指示当前是否有指令正在计算将要写入该寄存器的值。如果Qi不为 0,它将保存那个指令所在保留站的标识。
基于硬件的推测 (Hardware-Based Speculation) (§2.2 Hardware-Based Speculation, page 4) ¶
硬件推测是现代高性能处理器中的一项重要技术,它结合了动态分支预测、乱序执行和一种称为“重排序缓冲区”(Reorder Buffer, ROB)的机制,允许指令在控制依赖关系解决之前执行。
重排序缓冲区 (Reorder Buffer, ROB) (page 5) ¶
ROB 是一个用于缓存推测执行结果的先进先出 (FIFO) 队列。指令的执行结果不再直接写回寄存器,而是先写入 ROB。
ROB 的作用:
- 有序提交 (In-order Commit): 指令可以乱序执行完成 (WB),但必须按照它们在原始程序中的顺序提交 (Commit)。只有当一条指令到达 ROB 的队首且没有异常时,它的结果才能被真正写入寄存器或内存,成为体系结构状态的一部分。
- 精确异常 (Precise Exceptions): 如果一条推测执行的指令产生异常,该异常会被记录在 ROB 条目中。直到该指令到达 ROB 队首准备提交时,异常才会被处理。此时,可以清空 ROB 和保留站,丢弃所有后续指令,并跳转到异常处理程序,从而保证了异常状态的精确性。
- 错误预测恢复: 如果分支预测失败,所有在错误路径上发射的指令(在 ROB 中位于分支指令之后)都会被简单地从 ROB 中清除,它们的计算结果永远不会被提交。
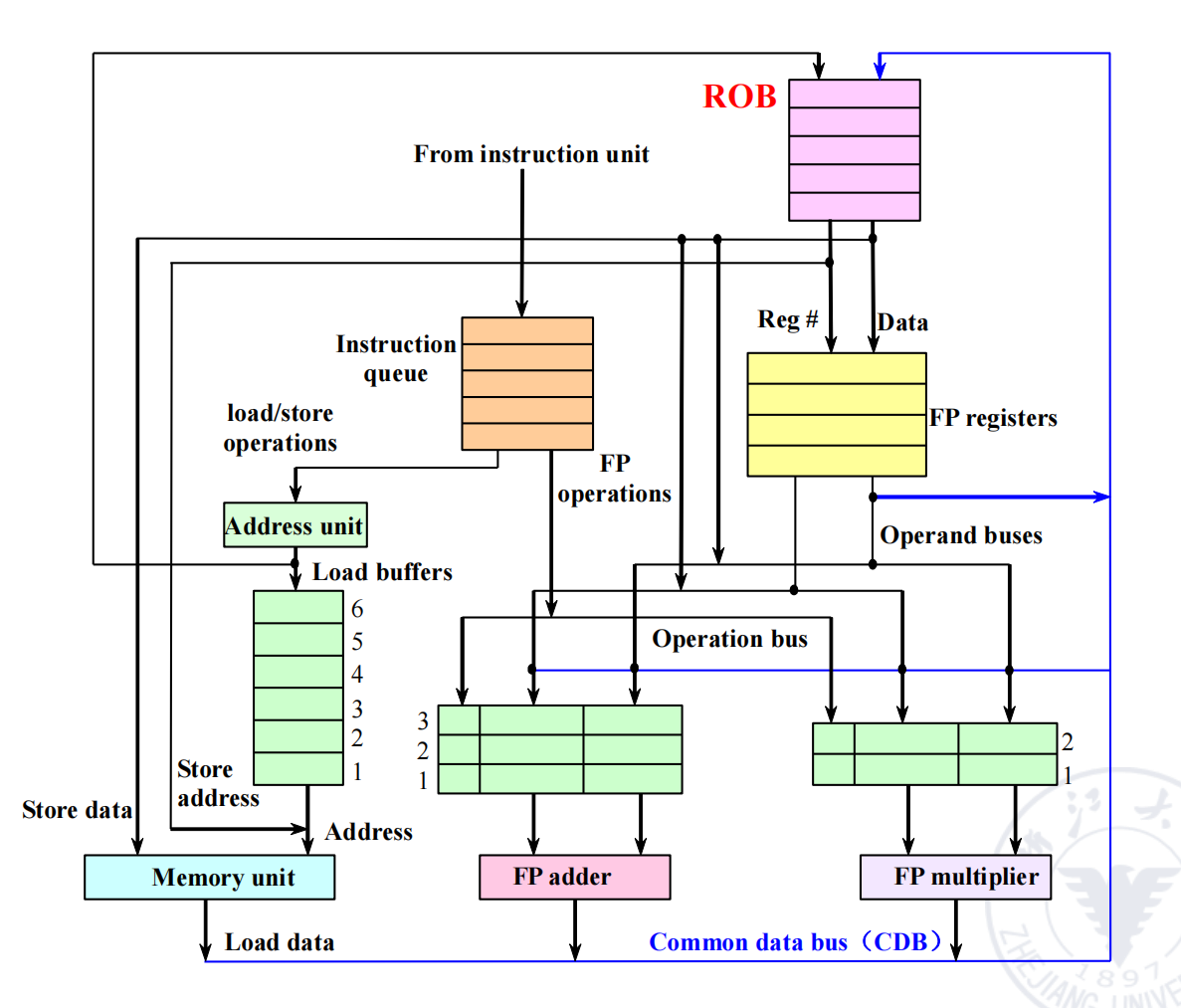
推测处理步骤 (Processing Steps of Speculation) (page 6) ¶
- 发射 (Issue): 从浮点操作队列(FP Op Queue)获取指令。
- 执行 (Execution): 在功能单元上操作数(EX
) 。 - 写入结果 (Write Result, WB): 完成执行并将结果写入重排序缓冲区(ROB
) ,而不是直接写入寄存器。 - 提交 (Commit): 按照程序顺序更新寄存器(如果推测正确
) 。
基于硬件的推测 (page 7)
结合了三个关键思想:
1. 动态分支预测 (Dynamic Branch Prediction): 硬件预测分支指令的走向(跳转或不跳转
硬件推测示例 (Hardware-Based Speculation Example) (page 9-11) ¶
我们来分析一下当指令序列中的 FMUL.D 执行完成(状态为 WB
状态表分析
指令序列 :
FLD F6, 34(R2)FLD F2, 45(R3)FMUL.D F0, F2, F4FSUB.D F8, F6, F2FDIV.D F10, F0, F6FADD.D F6, F8, F2
场景: FMUL.D已经执行完毕(在 ROB 中状态为 WBFLD 指令已经提交了。
保留站 (Reservation Station) 状态 (page 10) ¶
| Name | Busy | Op | Vj | Vk | Qj | Qk | Dest | A |
|---|---|---|---|---|---|---|---|---|
| Add1 | no | |||||||
| Add2 | no | |||||||
| Add3 | no | |||||||
| Mult1 | no | MUL | Mem[45+Regs[R3]] | Regs[F4] | 3 | |||
| Mult2 | yes | DIV | Mem[34+Regs[R2]] | 3 | 5 |
Mult1( 用于FMUL.D) 已经是no,因为它已经执行完毕并将结果广播。Mult2( 用于FDIV.D) 处于yes状态,它正在等待操作数。它的Vj字段已经捕获了F6的值 ( 来自 ROB 1 ,即Mem[34+Regs[R2]]),但Vk字段对应的F0还没有就绪,所以Qk指向F0所在的 ROB 条目#3。
重排序缓冲区 (ROB) 状态 (page 11) ¶
| NO. | Busy | Instruction | Status | Dest | Value |
|---|---|---|---|---|---|
| 1 | no | FLD F6, 34(R2) | Commit | F6 | Mem[34+Regs[R2]] |
| 2 | no | FLD F2, 45(R3) | Commit | F2 | Mem[45+Regs[R3]] |
| 3 | yes | FMUL.D F0, F2, F4 | WB | F0 | 2 x Regs[F4] |
| 4 | yes | FSUB.D F8, F6, F2 | WB | F8 | 1 - 2 |
| 5 | yes | FDIV.D F10, F0, F6 | EX | F10 | |
| 6 | yes | FADD.D F6, F8, F2 | WB | F6 | 4 + 2 |
#1和#2( 两条FLD指令 ) 已经提交 (Commit),它们的Busy状态为no。#3(FMUL.D) 处于WB(Write Back) 状态,表示执行完成,结果已写入 ROB,正在等待提交。#4(FSUB.D) 和#6(FADD.D) 也已经WB,体现了乱序完成。#5(FDIV.D) 还在EX(Execute) 状态,因为它依赖#3的结果,执行时间很长。Value字段中的#1,#2等表示对其他 ROB 条目结果的引用。
寄存器状态 (Register Status) 表 (page 11) ¶
| Name | F0 | F2 | F4 | F6 | F8 | F10 | ... |
|---|---|---|---|---|---|---|---|
| ROB | 3 | 6 | 4 | 5 | ... | ||
| Busy | yes | no | no | yes | yes | yes | ... |
- 此表指示了每个寄存器最新的值将由哪个 ROB 条目产生。
F0的值将由 ROB 3 (FMUL.D) 提供,所以Busy为yes。F6的值最终将由 ROB 6 (FADD.D) 提供,而不是 ROB 1 (FLD F6)。这是寄存器重命名的体现。F2已经由 ROB 2 提交并写入寄存器堆,所以它的Busy为no。
硬件推测的练习与总结 (Practice and Summary of Hardware-Based Speculation) (page 12-38) ¶

这部分内容通过一个完整的动画展示了上述指令序列在带 ROB 的 Tomasulo 架构上逐个时钟周期的执行过程。最终的总结表 (page 37) 清晰地展示了每条指令的四个阶段(发射、执行完成、写回、提交)所处的时钟周期。
Tomasulo with Reorder Buffer - Summary (page 37)
| Instruction | Issue | Exec Comp | Writeback | Commit |
|---|---|---|---|---|
| FLD F6, 34(R2) | 1 | 3 | 4 | 5 |
| FLD F2, 45(R3) | 2 | 4 | 5 | 6 |
| FMUL.D F0, F2, F4 | 3 | 6-15 | 16 | 17 |
| FSUB.D F8, F6, F2 | 4 | 6-7 | 8 | 18 |
| FDIV.D F10, F0, F6 | 5 | 17-56 | 57 | 58 | | FADD.D F6, F8, F2 | 6 | 9-10 | 11 | 59 |
关键结论: 顺序发射 / 提交,乱序执行 / 写回 (In-order Issue/Commit, Out-of-Order Execution/Writeback)。
- 指令按程序顺序依次发射 (Issue: 1, 2, 3, ...)。
- 指令的执行 (Exec Comp) 和写回 (Writeback) 是乱序的,取决于数据依赖和功能单元的可用性 ( 例如,FSUB 在第 8 周期就写回,而 FMUL 在第 16 周期才写回 )。
- 指令的提交 (Commit) 必须严格按照程序顺序 (Commit: 5, 6, 17, 18, ...)。
FSUB.D即使在第 8 周期就完成了,也必须等到它前面的FMUL.D在第 17 周期提交后,才能在第 18 周期提交。
利用多发射和静态调度来利用 ILP (§2.3 Exploiting ILP Using Multiple Issue and Static Scheduling, page 39) ¶
到目前为止,我们讨论的都是单发射 (single-issue) 处理器,即每个时钟周期最多发射一条指令。为了进一步挖掘指令级并行,现代处理器普遍采用多发射 (Multiple-Issue) 技术。
多发射处理器类型 (Two types of multiple-issue processor) (page 40-43) ¶
1. 超标量 (Superscalar) (page 40) ¶
超标量处理器
- 可变发射数量: 每个时钟周期可以发射的指令数量不是固定的(通常有上限,如 2、4、8 条
) 。硬件会在运行时动态决定发射多少条指令。 - 硬件依赖检查: 处理器硬件负责检查指令间的依赖关系和资源冲突。
- 调度方式:
- 静态调度超标量: 依赖检查在硬件中进行,但指令调度主要由编译器静态完成。
- 动态调度超标量: 在硬件中同时进行依赖检查和指令调度(例如,结合 Tomasulo 算法
) 。这是目前主流高性能处理器的实现方式(如 Intel Core i 系列,AMD Ryzen 系列) 。
2. 超长指令字 (VLIW) (page 43) ¶
VLIW 处理器
- 固定发射数量: 每个时钟周期发射一个包含多条独立操作的“指令包 (packet)”或“长指令字”。
- 编译器依赖检查: 编译器负责解决所有指令间的依赖关系,将可以并行执行的指令打包在一起。硬件设计大大简化,因为它假定一个指令包内的所有操作都是可以并行执行的。
- 应用领域: 在数字信号处理 (DSP) 和嵌入式领域非常成功,因为这些领域的工作负载(如循环和矩阵运算)具有高度可预测的并行性。
超标量 vs. VLIW (page 44-46) ¶
| 特性 | 超标量 ( 动态 ) | VLIW |
|---|---|---|
| 调度 | 硬件动态调度 | 编译器静态调度 |
| 复杂性 | 硬件复杂,需要动态的依赖检查逻辑 | 编译器复杂,硬件相对简单 |
| 代码兼容性 | 对程序员透明,旧代码不经重新编译也能运行(可能效率不高) | 硬件和指令集紧密耦合,代码不兼容,需要专门的编译器 |
| 并行性发掘 | 在运行时发掘并行性,对不规则代码适应性强 | 在编译时发掘并行性,对规则的、可预测的代码效果好 |
基于静态调度的多发射技术 (Multi-issue technology based on static scheduling) (page 47) ¶
- 在典型的超标量处理器中,每个时钟周期可以发射 1 到 8 条指令。
- 指令按序流出,并在流出时进行冲突检测。
- 在当前指令序列中,没有数据冲突或紧密冲突。
- MIPS 处理器如何实现超标量 (page 48-51):
- 假设:每个时钟周期流出两条指令:一条整数指令 + 一条浮点操作指令。
- 加载、存储和分支指令被归类为整数指令。
- 处理步骤 (page 49):
- 同时获取并解码两条指令(64 位
) 。 - 确定哪些指令可以流出(0~2 条
) 。 - 将它们发送到对应的功能单元。
- 同时获取并解码两条指令(64 位
- 执行过程:所有浮点指令被假定为加法指令,执行时间为 2 个时钟周期。为简化起见,整数指令总是放在浮点指令之前。
- 优点 (page 51):
- “1 条整数指令 + 1 条浮点指令”的并行流出方式,所需的硬件增加量较小。
- 浮点加载或存储指令会使用整数部分,这会增加对浮点寄存器的访问冲突,因此需要为浮点寄存器增加读 / 写端口。
- 由于流水线中的指令数量翻倍,方向路径(Forwarding Path)也必须增加。
基于动态调度的多发射技术 (page 52)
- 扩展的 Tomasulo 算法: 支持双路超标量(Two-way Superscalar
) 。- 每个时钟周期发射两条指令:一条整数指令和一条浮点指令。
- 相对简单的方法 (Relatively simple method) (page 52):
- 指令按序流向保留站,否则程序语义将被破坏。
- 将整数的功能单元表和浮点功能单元表分离,独立处理。这样,一条浮点指令和一条整数指令可以同时发送到各自的保留站。
RISC-V 循环执行示例 (RISC-V loop execution example) (page 53-58)¶
Loop: LD X2, 0 (X1) // X2=array element
ADDI X2, X2, 1 // increment X2
SD X2, 0 (X1) // store result
ADDI X1, X1, 8 // increment pointer by 8
// (each data occupies 8 bytes)
BNE X2, X3, Loop // branch if not last
- 假设 (Assumptions) (page 54):
- 每个时钟周期可以流出一条整数指令和一条浮点指令,即使它们相关。
- 有独立的整数 ALU 操作和地址计算组件,以及独立的浮点操作流水线功能组件。
- 指令流和写入结果各占用一个时钟周期。
- 有动态分支预测组件和独立的用于计算分支条件的组件。
- 分支指令独立流出,不使用延迟分支,且分支预测完美。在分支指令完成之前,其后续指令只能被获取和流出,但不能执行。
- 执行延迟 (Delay in generating the result) (page 55):
- 写入结果占用一个时钟周期。
- 整数操作:1 个周期。
- 加载:2 个周期。
- 浮点加法:3 个周期。
- 结果对比:
- 不带推测 (page 56): 15 条指令执行了 19 个周期,IPC (Instructions Per Cycle) = 15/19 ≈ 0.79。性能瓶颈在于数据依赖和分支指令导致的停顿。
- 带硬件推测 (page 58): 15 条指令执行了 14 个周期,IPC = 15/14 ≈ 1.07。推测执行显著减少了分支延迟带来的停顿,允许处理器更早地执行后续循环的指令,从而提高了并行度。
超流水线处理器 (Superpipelined processor) (page 68) ¶
超流水线(Superpipelining)是一种通过进一步细分流水线阶段来提高吞吐量的技术。
- 每个流水线阶段被进一步细分,使得多个指令可以在一个时钟周期内分时共享。这种处理器被称为超流水线处理器。
- 对于一个每个时钟周期能流出
n条指令的超流水线计算机,这n条指令并非同时流出,而是每条指令每1/n个时钟周期流出。 - 实际上,超流水线计算机的流水线周期是正常流水线的
1/n倍。 - 附件中展示了一个每时钟周期分时发射两条指令的超流水线计算机的时空图 (page 69-70)。
SGI MIPS R4000 处理器 (page 71) ¶
R4000 是一个典型的超流水线处理器,具有 8 个或更多指令流水线阶段。
- R4000 微处理器芯片包含 2 个缓存:指令缓存和数据缓存,容量均为 8 KB,数据宽度为 64 位。
- R4000 的核心处理组件包括:
- 一个 32x32 位的通用寄存器组。
- 一个算术逻辑单元 (ALU)。
- 一个专用的乘 / 除单元。
R4000 流水线结构 (R4000 Pipeline Structure) (page 72-77) ¶
R4000 的流水线有 8 个阶段,每个阶段都比传统 5 阶段流水线更精细:
- IF (Instruction Fetch): 指令获取前半部分;在此阶段进行程序计数器 (PC) 选择,并启动指令缓存访问。
- IS (Instruction Stage): 指令获取后半部分;完成指令缓存访问。
- RF (Register Fetch): 指令解码和寄存器获取;冒险检查,并检测指令缓存命中。
- EX (Execution): 执行阶段;包括有效地址计算、ALU 操作,以及分支目标计算和条件评估。
- DF (Data Fetch): 数据获取前半部分;数据缓存访问前半部分。
- DS (Data Stage): 数据获取后半部分;完成数据缓存访问。
- TC (Tag Check): 标签检查;确定数据缓存访问是否命中。
- WB (Write Back): 写回阶段;用于加载指令和寄存器 - 寄存器操作的写回。
(page 78) 图示了 R4000 流水线中指令的重叠执行,展示了其 8 阶段的并行性。
(page 79) 图中展示了加载指令 LD R1 之后,DADD.D R2, R1 需要等待 R1 的值。由于 LD 操作需要两个时钟周期(数据缓存访问