计算机系统 III:存储层次结构 (Memory Hierarchy) ¶
§3.1 引言 (page 3-24) ¶
计算机系统中的存储部件扮演着至关重要的角色,它们负责暂存程序指令和数据,是程序执行的基础。本章节将深入探讨存储层次结构的设计理念、关键技术以及性能优化。
存储器的种类 (page 3) ¶
存储器技术多种多样,从早期的机械式存储到现代的电子和光学存储,其发展伴随着计算机技术的整体进步。
- 寄存器 (Register): CPU 内部的极少量高速存储单元,用于暂存指令、数据和地址。
- 缓存 (Cache): 位于 CPU 和主存之间的高速小容量存储器,用于缓解 CPU 和主存之间的速度不匹配。
- 内存 (Memory): 通常指主存储器 (Main Memory),程序运行时指令和数据的主要存放地。
- 外存 / 存储 (Storage): 容量较大、速度较慢的非易失性存储设备,如硬盘、固态硬盘等,用于长期保存数据。
存储器的具体实现技术包括: - 机械式存储 (Mechanical memory): - 声波/扭矩波延迟线存储 (Acoustic wave/torque wave delay line memory) - 磁鼓存储 (Magnetic Drum Memory) - 磁芯存储 (Magnetic core memory) - 电子式存储 (Electronic memory): - SRAM (Static Random Access Memory): 静态随机访问存储器,速度快,成本高,常用于构建缓存。 - DRAM (Dynamic Random Access Memory): 动态随机访问存储器,速度较 SRAM 慢,但密度高、成本低,常用于构建主存。 - SDRAM (Synchronous DRAM): 同步动态随机访问存储器。 - 闪存 (Flash Memory): 非易失性存储器,广泛应用于固态硬盘和各种便携式设备。 - ROM (Read-Only Memory): 只读存储器。 - PROM (Programmable ROM): 可编程只读存储器。 - EPROM (Erasable PROM): 可擦除可编程只读存储器。 - 光学存储 (Optical memory): 如 CD-ROM, DVD-ROM 等。
局部性原理 (Principle of Locality) (page 4) ¶
程序在执行时,对存储器的访问往往表现出局部性,这是构建高效存储层次结构的基础。
局部性原理
时间局部性 (Temporal locality): 如果一个存储单元被访问,那么它在不久的将来很可能再次被访问。就像你最近从书架上取下的一本书,你很可能马上会再次翻阅它。
空间局部性 (Spatial locality): 如果一个存储单元被访问,那么它附近地址的存储单元也很可能在不久的将来被访问。例如,程序顺序执行指令,或处理数组中的连续元素。
存储器的访问 (page 5) ¶
CPU 通过 Load 和 Store 指令与存储系统交互:
- Load R2, 0(R1): 从寄存器 R1 指向的内存地址加载数据到寄存器 R2。
- Store R2, 0(R1): 将寄存器 R2 中的数据存储到寄存器 R1 指向的内存地址。
存储层次的特性 (page 6) ¶
理想的存储器应兼具极高的速度、极大的容量和极低的成本,但这三者在现实技术中往往难以同时满足。因此,计算机系统采用分层的方式组织存储器,即存储层次结构。
| 速度 | 组件 | 大小 | 每比特成本 ($/bit) | 当前技术 |
|---|---|---|---|---|
| 最快 | 处理器 | |||
| 存储器 | 最小 | 最高 | SRAM | |
| 存储器 | DRAM | |||
| 最慢 | 存储器 | 最大 | 最低 | 磁性磁盘 (Magnetic disk) |
这个表格形象地展示了不同层级存储器的特性:越靠近 CPU 的存储器速度越快、容量越小、单位成本越高。
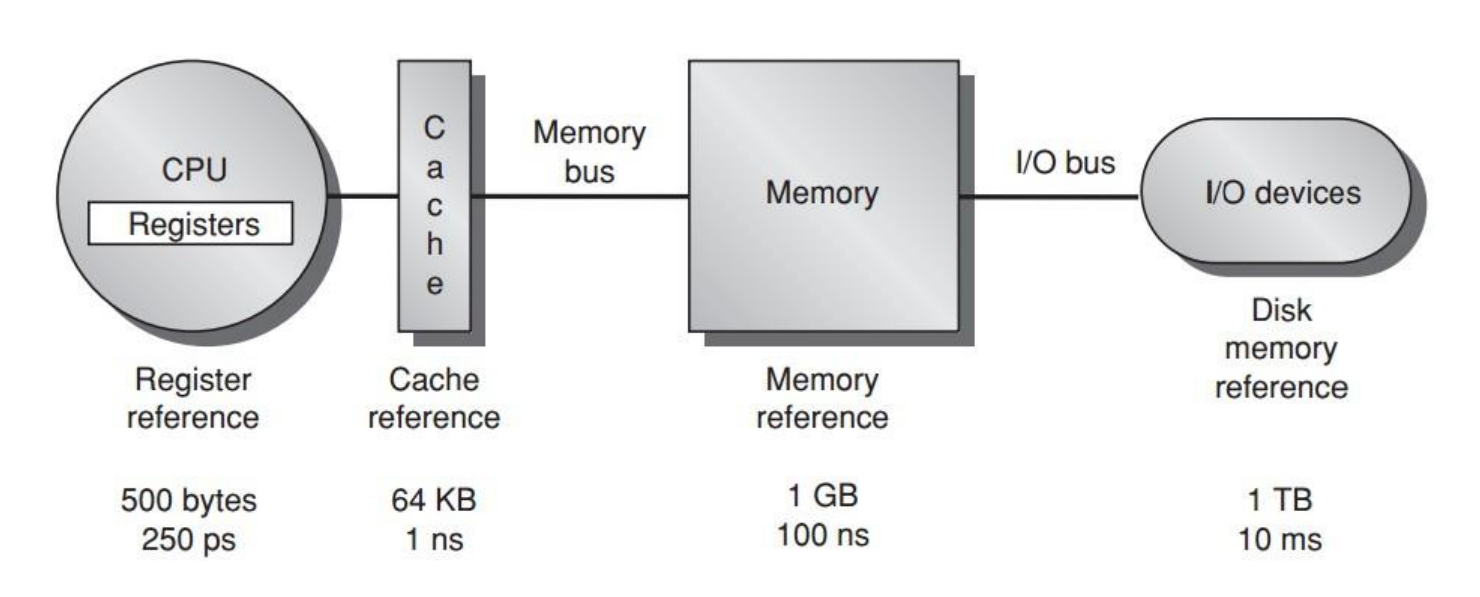
存储层次的演进 (page 7-10) ¶
- 数据处理与临时存储 (CPU 内 ) (page 7): CPU 内的寄存器 (Register) 直接参与数据处理,提供最快的临时存储。
- 临时存储 (CPU 与主存 ) (page 8): 引入主存 (Memory) 作为程序和数据的主要存放地,通过内存总线 (Memory Bus) 与 CPU 连接。
- 更快的临时存储 ( 引入外存 ) (page 9): 引入容量更大、成本更低的外存 (Storage),如闪存 (Flash memory)。此时,从 CPU 访问不同层级存储器的速度差异巨大,容量也显著不同。红色箭头表示容量增大方向,绿色箭头表示速度增快方向。
- 更快的临时存储 ( 引入缓存 ) (page 10): 在 CPU 和主存之间加入缓存 (Cache),进一步弥合速度差异。
典型的存储层次结构 (page 11-13) ¶
不同类型的计算设备,其存储层次结构配置有所差异,但基本思想一致:
-
个人移动设备 (Personal mobile device) (page 11):
- 寄存器 (Register): ~1000 bytes, ~300ps
- L1 Cache: ~64KB, ~1ns
- L2 Cache: ~256KB, ~5-10ns
- 主存 (Memory): 1-2GB, 50-100ns
- 存储 (Storage, e.g., Flash): 4-64GB, 25-50µs
- 1000 皮秒 (picoseconds) = 1 纳秒 (nanosecond) = 10 -6 毫秒 (millisecond)
-
笔记本或台式机 (Laptop or a desktop) (page 12):
- 寄存器 : ~1000 bytes (Laptop) / ~2000 bytes (Desktop), ~300ps
- L1 Cache: ~64KB, ~1ns
- L2 Cache: ~256KB, ~5-10ns
- L3 Cache: 4-8MB (Laptop) / 8-32MB (Desktop), 10-20ns
- 主存 : 4-16GB (Laptop) / 8-64GB (Desktop), 50-100ns
- 存储 (Flash/SSD): 256GB-1TB (Laptop) / 256GB-2TB (Desktop), 50-100µs
-
服务器 (Server) (page 13):
- 寄存器 : ~4000 bytes, ~200ps
- L1 Cache: ~64KB, ~1ns
- L2 Cache: ~256KB, ~3-10ns
- L3 Cache: 16-64MB, 10-20ns
- 主存 : 32-256GB, 50-100ns
- 存储 (Flash storage): 1-16TB, 100-200µs
- 存储 (Disk storage): 16-64TB, 5-10ms ( 通过 I/O 总线连接 )
存储层次的核心思想
存储层次结构利用局部性原理,将频繁访问的数据放置在速度更快、容量更小、成本更高的存储层级中,而将不常访问的大量数据放置在速度较慢、容量较大、成本较低的层级中。这样可以在满足大容量存储需求的同时,尽可能提供接近最快存储层级的平均访问速度。
什么是缓存 (Cache)? (page 14-20) ¶
缓存 (Cache) (page 19-20)
根据韦氏词典 (Webster's New World Dictionary, 1976),"Cache" 指的是一个用于隐藏或存储物品的安全场所。 在计算机体系结构中,缓存 (Cache) 是指当地址离开处理器后遇到的内存层次结构中的最高或第一个级别。它通过缓冲 (buffering) 技术来重用频繁出现的项目,从而提高数据访问速度。 简单来说,缓存是一个小而快速的存储,用于存储最近或频繁访问的数据项的副本,使得处理器可以快速获取这些数据,而不必每次都从较慢的主存中读取。
当程序 / 指令需要数据时 (data request),它会首先查询缓存。如果数据在缓存中 (in),则缓存直接提供数据,这是一个快速的过程,且可能涉及优化 (optimization)。如果数据不在缓存中 (out),则需要从下一级存储(如主存)获取。
缓存的基本操作和术语 (page 21-24) ¶
-
缓存命中 (Cache Hit) / 缓存未命中 (Cache Miss) (page 21):
- 当处理器在缓存中能 (can) 找到请求的数据项时,称为缓存命中。
- 当处理器在缓存中不能 (cannot) 找到请求的数据项时,称为缓存未命中。
- 命中率 (Hit rate): 缓存命中的次数占总访问次数的比例。
- 未命中率 (Miss rate): 缓存未命中的次数占总访问次数的比例。
Miss rate = 1 - Hit rate。 - 命中时间 (Hit time): 访问缓存并获取数据所需的时间。
- 未命中惩罚 (Miss penalty): 发生缓存未命中时,从下一级存储获取数据并将其放入缓存所需的额外时间。
-
缓存块 / 行 (Block/Line) (page 22-24):
- 缓存和主存之间数据传输的最小单位。
- 当发生缓存未命中时,并不仅仅是请求的那个字 (word) 被调入缓存,而是包含该字的整个数据块会从主存复制到缓存中的一个块 / 行。
- 这么做的依据是空间局部性:如果一个数据项被访问,其附近的数据项也可能很快被访问。将整个块调入可以提高未来访问的命中率。
§3.2 技术趋势与存储层次 (Technology Trend and Memory Hierarchy) (page 25-40) ¶
处理器与存储器的性能差距 (page 25, 28) ¶
自 1980 年以来,处理器的性能以远超存储器(特别是 DRAM)的性能增长速度发展,导致了两者之间日益扩大的性能差距,通常被称为“内存墙 (Memory Wall)”。下图直观展示了这一趋势:处理器性能曲线的斜率远大于内存性能曲线。
( 图示参考 page 25,显示 Processor Performance 和 Memory Performance 随年份增长的对数坐标图 )
这种性能差距使得存储系统成为现代计算机性能提升的主要瓶颈之一。存储层次结构和缓存技术是弥补这一差距的关键手段。page 28 的图示再次强调了不同存储层级在大小 (Size) 和速度 (Speed) 上的权衡,缓存位于 CPU 和主存之间,试图平衡这两者。
存储技术概览 (page 26-27) ¶
| 存储技术 (Memory technology) | 典型访问时间 (Typical access time) | 2012 年每 GB 价格 ($ per GiB in 2012) |
|---|---|---|
| SRAM 半导体存储 (SRAM semiconductor memory) | 0.5-2.5 ns | \(500-\)1000 |
| DRAM 半导体存储 (DRAM semiconductor memory) | 50-70 ns | \(10-\)20 |
| 闪存半导体存储 (Flash semiconductor memory) | 5,000-50,000 ns | \(0.75-\)1.00 |
| 磁盘存储 (Magnetic disk) | 5,000,000-20,000,000 ns | \(0.05-\)0.10 |
- SRAM (Static Random Access Memory): 静态随机存取存储器,速度非常快,功耗较高,通常用于构建 CPU 缓存。
- DRAM (Dynamic Random Access Memory): 动态随机存取存储器,速度比 SRAM 慢,但密度更高,成本更低,主要用于主存。
- SDRAM (Synchronous DRAM): 同步动态随机存取存储器,其操作与系统时钟同步。
- DDR SDRAM (Double Data Rate SDRAM): 双倍数据速率同步动态随机存取存储器,在一个时钟周期内传输两次数据,有效提高了带宽。
- HBM (High Bandwidth Memory): 高带宽存储器,一种新型 DRAM 技术,通过 3D 堆叠和更宽的接口提供极高的带宽,常用于 GPU 等高性能计算场景。
- 闪存 (Flash Memory) (page 27): 电可擦除可编程只读存储器 (EEPROM),非易失性,广泛用于 SSD、U 盘等。Intel 3D NAND SSD 是其一种实现。
- 持久性内存 (Persistent Memory) (page 27): 如 Intel Optane DC Persistent Memory,它结合了 DRAM 的部分速度特性和 Flash 的非易失性,可作为大容量内存或快速存储使用。
Page 27 展示了一个存储金字塔模型,从底部的 HDD/Tape 到 SSD,再到 DRAM,顶层是 Today's Focus ( 可能指 Persistent Memory 或更高性能的 DRAM)。这个模型体现了容量、性能和成本的权衡。
Page 26 展示了 DRAM 的内部组织结构图,包括 Bank ( 存储体 )、Row ( 行 )、Column ( 列 ) 以及 Precharge ( 预充电 )、Activate ( 激活 ) 等操作。现代 DRAM 通常组织成多个 Bank,每个 Bank 包含一系列的行。发送 PRE 命令打开或关闭一个 Bank。行地址与 ACT 命令一起发送,将该行数据传输到行缓冲区 (row buffer)。当数据在行缓冲区后,可以通过连续的列地址来传输,其宽度与 DRAM 的接口宽度 ( 如 DDR3 中的 4, 8, 16 bits) 一致,或者通过指定块起始地址进行块传输。每个命令都与时钟同步。
现代计算机系统的存储层次目标 (page 29) ¶
利用局部性原理,现代计算机系统的存储层次旨在实现两个主要目标:
- 以最廉价的技术提供用户所需的尽可能大的存储容量。
- 以最快速的技术提供接近其速度的平均访问性能。
Page 29 的图示展示了一个典型的存储层次结构,从 CPU 核心的寄存器 (Register) 和片上缓存 (On-Chip Cache, SRAM),到二级缓存 (Second Level Cache, SRAM),再到主存 (Main Memory, DRAM),最后到二级存储 (Secondary Storage, Disk)。各层级的速度和容量差异巨大: - Speed (ns): 1s (寄存器) -> 10s (L2 Cache) -> 100s (主存) -> 10,000,000s (10ms, 磁盘) - Size (bytes): 100s (寄存器) -> Ks (L2 Cache) -> Ms (主存) -> Gs (磁盘)
缓存局部性再探 (page 30) ¶
缓存的有效性高度依赖于局部性原理:
- 时间局部性 (Temporal locality): 如果一个字被请求,它很可能很快再次被请求。
- 空间局部性 (Spatial locality): 如果一个字被请求,它所在块内的其他数据也可能很快被请求。
缓存未命中的原因 (The "3C" Model) (page 31) ¶
缓存未命中是影响性能的关键因素,其主要原因可以归为三类:
- 强制性未命中 (Compulsory miss) / 冷启动未命中 (Cold start miss): 第一次访问一个块时发生的未命中。即使有无限大的缓存,这种未命中也是不可避免的,因为数据最初必须从较低层级加载。
- 容量性未命中 (Capacity miss): 当缓存无法容纳程序工作集(即当前活跃使用的数据和指令)所需的所有块时发生的未命中。即使是全相联缓存,如果工作集大小超过缓存容量,也会发生容量性未命中。块因为缓存已满而被替换出去,之后又被重新访问。
- 冲突性未命中 (Conflict miss) / 碰撞性未命中 (Collision miss): 在直接映射或组相联缓存中,当多个不同的内存块映射到同一个缓存位置(或组)时,即使缓存整体有空闲空间,也可能因为特定位置(或组)的竞争而发生未命中。程序对不同块的多个地址进行重复引用,而这些地址映射到缓存中的相同位置。
未命中时间构成
缓存未命中所需的时间取决于两个因素: - 延迟 (Latency): 检索到块的第一个字所需的时间。 - 带宽 (Bandwidth): 检索块中剩余部分数据所需的时间。
利用局部性增强性能 (page 32) ¶
存储层次结构正是通过以下方式利用局部性来提升性能:
- 大多数程序并非均匀访问所有代码或数据。
- 时间局部性: 如果一个项目被引用,它很可能很快再次被引用。
- 策略:将最近访问的数据项保持在更靠近处理器的地方(即更高层级的缓存
) 。
- 策略:将最近访问的数据项保持在更靠近处理器的地方(即更高层级的缓存
- 空间局部性: 如果一个项目被引用,其附近的项目很可能很快被引用。
- 策略:将最近访问的连续字组(即块)移动到更靠近处理器的地方。
不同计算机类型对存储层次的关注点 (page 33-34) ¶
- 桌面计算机 (Desktop computers):
- 主要为单个用户运行单个应用程序。
- 更关注存储层次的平均延迟 (average latency)。
- 服务器计算机 (Server computers):
- 通常有数百用户同时运行数十个应用程序。
- 更关注内存带宽 (memory bandwidth)。
- 嵌入式计算机 (Embedded computers):
- 常用于实时应用 (Real-time applications),对最坏情况性能 (Worst-case performance) 和最佳情况性能 (Best case performance) 的考量很重要。
- 更关注功耗 (power) 和电池寿命 (battery life),这可能导致硬件与软件在功能实现上的取舍。
- 通常运行单个应用并使用简单的操作系统,内存层次的保护作用常被削弱。
- 主存非常小,且通常没有磁盘存储。
缓存相关术语列表 (page 35) ¶
Page 35 列出了 36 个与缓存相关的重要术语,例如:
Cache, full associative, write allocate, Virtual memory, dirty bit, unified cache, Memory stall cycles, block, block offset, misses per instruction, direct mapped, write back, Valid bit, data cache, locality, Block address, hit time, address trace, Write through, cache miss, set, Instruction cache, page fault, miss rate, random replacement, index field, cache hit, Average memory access time, page, tag field, n-way set associative, no-write allocate, miss penalty, Least-recently used, write buffer, write stall.
这些术语将在后续章节中详细解释。
广义的“缓存”概念 (page 36, 60) ¶
在计算机体系结构中
" 几乎所有东西都是缓存 "
- 寄存器 (Registers) 可以看作是变量的“缓存”,由软件(编译器)管理。
- 一级缓存 (First-level cache) 是二级缓存的缓存。
- 二级缓存 (Second-level cache) 是主存的缓存。
- 主存 (Memory) 可以看作是磁盘(虚拟内存)的缓存。
- TLB (Translation Lookaside Buffer) 是页表 (page table) 的缓存。
- 分支预测 (Branch-prediction) 中的分支历史表等可以看作是预测信息的缓存。
Page 36 和 60 的图示是一个金字塔模型,从上到下依次是:寄存器、L1 缓存(片上
多级缓存组织 (page 37-38) ¶
Page 37 重复了 page 11-13 的个人设备、桌面 / 笔记本、服务器的存储层次图。 Page 38 展示了一个典型的多级缓存组织: CPU (包含寄存器 Regs) -> L1 d-cache (数据缓存) & L1 i-cache (指令缓存) -> L2 Unified Cache (统一缓存) -> Main Memory -> Disk。
分离缓存与统一缓存 (Split vs. Unified Caches) (page 39) ¶
- 统一缓存 (Unified cache):
- 所有内存请求(指令和数据)都通过单个缓存。
- 优点:硬件需求少,设计相对简单。
- 缺点:指令和数据访问可能产生冲突,带宽共享可能导致性能较低。
- 分离缓存 (Split I & D cache):
- 为指令和数据分别设置独立的缓存(通常指 L1 缓存
) 。 - 优点:
- 减少指令和数据访问的冲突。
- 可以针对指令和数据的不同访问特性进行优化(例如,指令缓存通常是只读的,可以简化设计
) 。 - 提高带宽,允许同时取指和取数。
- 缺点:需要额外的硬件。
- 为指令和数据分别设置独立的缓存(通常指 L1 缓存
图示显示了两种配置:
Proc -> Unified Cache-1 -> Unified Cache-2( 两级统一缓存 )Proc -> I-Cache-1和Proc -> D-Cache-1,两者共同汇聚到Unified Cache-2(L1 分离,L2 统一 )
Intel Pentium 缓存组织示例 (page 40) ¶
一个早期 Intel Pentium 处理器的缓存组织示例:
| 缓存类型 (Cache type) | 相联度 (Associativity, E) | 块大小 (Block size, B) | 组数 (Sets, S) | 缓存大小 (Cache size, C) |
|---|---|---|---|---|
| 片上 L1 指令缓存 (on-chip L1 i-cache) | 4 | 32 B | 128 | 16 KB |
| 片上 L1 数据缓存 (on-chip L1 d-cache) | 4 | 32 B | 128 | 16 KB |
| 片外 L2 统一缓存 (off-chip L2 unified cache) | 4 | 32 B | 1024-16384 | 128 KB - 2 MB |
§3.3 缓存设计的四个核心问题 (Four Questions for Cache Designers) (page 41-93, page 2-16) ¶
缓存设计需要解决四个基本问题。这些问题不仅适用于 CPU 缓存,也适用于广义的存储层次设计。
缓存设计的四个核心问题 (page 42, 51, 63, 68, page 2)
Q1: 块放置 (Block Placement): 当从低一级存储调入一个块时,它可以放置在当前缓存(高一级)的哪个位置? - 策略:全相联 (Fully Associative), 组相联 (Set Associative), 直接映射 (Direct Mapped)。
Q2: 块识别 (Block Identification): 如何判断请求的数据块是否存在于缓存中,如果存在,如何找到它? - 机制:标签 (Tag) / 块内偏移 (Block Offset) / 组索引 (Set Index),有效位 (Valid bit)。
Q3: 块替换 (Block Replacement): 当发生缓存未命中,且缓存中没有空闲位置时,应该替换哪个已有的块? - 策略:随机 (Random), 最近最少使用 (LRU, Least-Recently Used), 先进先出 (FIFO, First-In First-Out)。
Q4: 写策略 (Write Strategy): 当处理器执行写操作时,如何更新缓存和主存中的数据? - 策略:写回 (Write Back) 或写直达 (Write Through),结合写分配 (Write Allocate) 或非写分配 (No-Write Allocate / Write Around)。
Page 41 的图示说明了缓存未命中的情况:当引用一个不在缓存中的字 Xn 时,会导致未命中,缓存需要从内存中获取包含 Xn 的整个块,并将其插入缓存中。这就引出了问题:数据项是否在缓存中?如果在,如何找到它?
Q1: 块放置 (Block Placement) (page 43-50) ¶
直接映射 (Direct Mapped) (page 43-44) ¶
- 定义: 每个主存块只能映射到缓存中的一个特定位置。
- 映射规则:
缓存块号 = (主存块号) MOD (缓存中总块数) - 地址划分: 主存地址通常被划分为三部分:标记 (Tag),索引 (Index),块内偏移 (Offset)。索引用于确定缓存中的哪一行,标记用于区分映射到同一行的不同主存块。
- Page 43 中
j(m bits) 代表索引部分。 - Page 44 展示了多个主存块(如 00001, 01001, 10001, 11001 都映射到索引为 001 的缓存行)通过不同的标记位来区分。
- Page 43 中
- 优点: 实现简单,查找速度快(只需检查一个位置
) 。 - 缺点: 冲突率较高。如果程序交替访问映射到同一缓存行的多个主存块,会导致频繁的替换和未命中(颠簸 , thrashing
) 。
全相联 (Fully Associative) (page 45) ¶
- 定义: 主存中的任何一个块可以放置在缓存中的任何一个位置。
- 映射规则: 无特定的索引映射,需要比较所有缓存行的标记。
- 地址划分: 主存地址划分为:标记 (Tag) 和块内偏移 (Offset)。
- 优点: 块放置灵活,冲突率最低。
- 缺点: 实现复杂且昂贵,查找速度慢(需要并行比较所有行的标记
) 。通常只用于小容量缓存(如 TLB 的某些设计或非常小的缓存) 。
N 路组相联 (N-way Set-Associative) (page 46-47) ¶
- 定义: 缓存被划分为若干个组 (Set),每个组包含 N 个缓存行 (N-way)。主存中的一个块可以映射到特定组内的任何一个行。
- 映射规则:
缓存组号 = (主存块号) MOD (缓存中总组数) - 地址划分: 主存地址划分为:标记 (Tag),组索引 (Set Index),块内偏移 (Offset)。
- Page 46 的
k(g bits) 代表组索引。示例为 2 路组相联 (2-way Set-associative),每个组包含 2 行。
- Page 46 的
- 特性:
- 直接映射是 1 路组相联的特例 (N=1)。
- 全相联是 M 路组相联的特例,其中 M 是缓存的总行数(即只有一个组
) 。
- 优点: 在直接映射和全相联之间取得平衡,冲突率低于直接映射,实现成本低于全相联。
- 为什么用中间位作索引 (Why Index With the Middle Bits?) (page 47): 如果使用高位地址作为索引,那么主存中连续的块可能会映射到同一个缓存组,这会降低空间局部性的利用效率。例如,一个大数组如果其起始地址使得多个连续块都映射到同一个组,那么在遍历这个数组时,即使缓存有足够总容量,也会在这个组内频繁发生冲突。使用中间位作为索引可以将连续的主存块更均匀地分布到不同的缓存组中。
块放置策略总结 (page 48-50) ¶
- 直接映射: 块只能放在缓存中的一个位置。
(块地址) MOD (缓存中块的数量)。 - 全相联: 块可以放在缓存中任何位置。
- 组相联: 块可以放在一个特定组内的任何位置。一个组是缓存中一组块的集合。
(块地址) MOD (缓存中组的数量)。- 如果一个组有 n 个块,则称缓存为 n 路组相联。
- 注意: 直接映射等同于 1 路组相联。全相联等同于 m 路组相联 ( 对于一个有 m 个块的缓存 )。
Page 49 的图示展示了块号为 12 的主存块在不同策略下的放置:
- 直接映射 (Direct Mapped) ( 假设缓存有 8 块 ): 12 mod 8 = 4。块 12 只能放在缓存的第 4 行。
- 全相联 (Fully-associative) ( 假设缓存有 8 行 ): 块 12 可以放在 0-7 行的任意位置。
- 2 路组相联 (2-way Set-associative) ( 假设缓存有 8 行,即 4 组,每组 2 行 ): 12 mod 4 ( 组数 ) = 0。块 12 可以放在第 0 组的任意一个行中。
Page 50 的表格总结了不同相联度的特性 (M 为缓存总行数 ):
| 类型 | 每组行数 (n) | 组数 (G) |
|---|---|---|
| 全相联 | M | 1 |
| 直接映射 | 1 | M |
| 组相联 | 1 < n < M | 1 < G < M |
- 相联度越高,缓存空间利用率越高,块冲突概率越低,未命中率也相应降低。
- 大多数实际缓存的 N 通常较小,如
N ≤ 4或 8,16。更高的相联度会增加硬件复杂度和功耗,且对命中率的提升边际效应递减。 - 问题:N 越大越好吗? 不是。相联度增加会带来硬件成本(比较器、多路选择器)和潜在的命中时间增加。
Q2: 块识别 (Block Identification) (page 52-59, 64) ¶
如何找到缓存中的块?
- 每个缓存块都有一个地址标签 (address tag),存储了该块在主存中的地址信息(高位部分
物理地址的格式 (page 53, 64) ¶
物理地址被划分为几个字段,用于在缓存中定位和识别数据:| Tag | Index | Byte Offset | 。
- 字节偏移 (Byte Offset):
- 选择块内的特定字节。
- 位数 =
log2(块大小,单位字节)。例如,块大小为 32 字节,则偏移为 5 位。
- 索引 (Index):
- 对于组相联缓存,选择缓存中的特定组 (set)。
- 对于直接映射缓存,选择缓存中的特定块 / 行 (block)。
- 位数 =
log2(组数)( 组相联 ) 或log2(总块数)( 直接映射 )。
- 标记 (Tag):
- 用于在选定的组(或直接映射的行)内匹配正确的块。
- 位数 =
地址总位数 - Index位数 - Byte Offset位数。
Page 64 的图示详细展示了不同映射方式下的地址结构和查找过程:
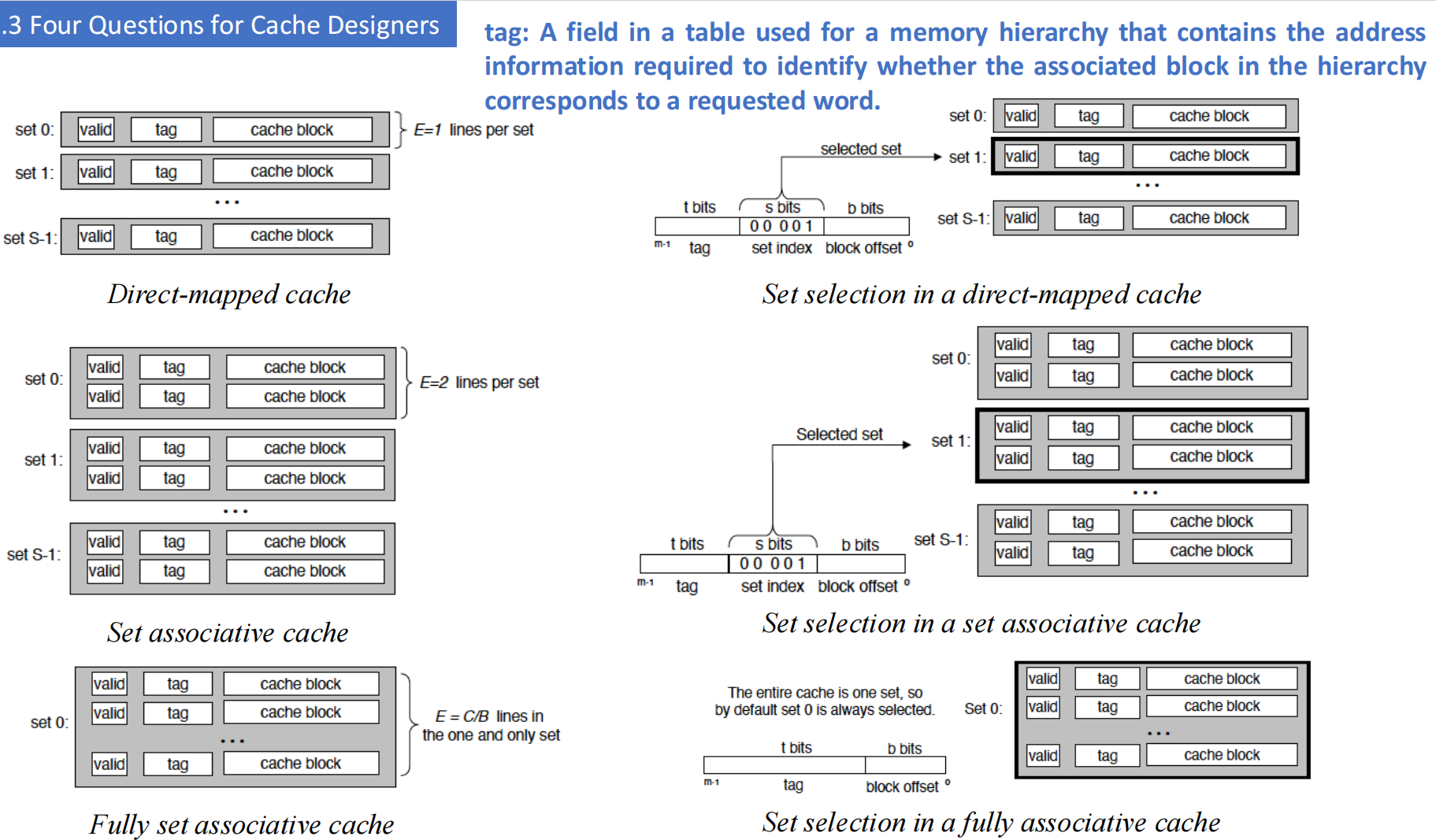
- 直接映射 (Direct-mapped cache): 地址中的 Index 字段直接选定一个缓存行。然后比较该行的 Tag 和地址中的 Tag。
E=1line per set。 - 组相联 (Set associative cache): 地址中的 Index 字段选定一个缓存组。然后并行比较组内所有行的 Tag 和地址中的 Tag。
E=2( 示例 ) lines per set。 - 全相联 (Fully set associative cache): 没有 Index 字段 ( 或者说只有一个组 )。并行比较所有缓存行的 Tag 和地址中的 Tag。
E=C/Blines in the one and only set (C 为缓存大小,B 为块大小 )。
Tag ( 标签 ) (page 64)
存储层次结构中表内的一个字段,包含了识别层次结构中关联块是否对应于所请求字的地址信息。
缓存行匹配与字选择图示 (page 54, 56, 58) ¶
- 直接映射缓存 (Direct-mapped cache) (page 54):
- 地址中的
set index(s bits) 选择一个缓存行 (set)。 - 检查该行的
valid bit是否为 1。 - 如果有效,比较地址中的
tag(t bits) 与缓存行中存储的tag。 - 如果 (1) 有效且 (2) 标签匹配,则为 cache hit。地址中的
block offset(b bits) 选择块内的具体字W0, W1, W2, W3。
- 地址中的
- 组相联缓存 (Set associative cache) (page 56):
- 地址中的
set index(s bits) 选择一个缓存组。 - 对于组内的每一行:
a. 检查
valid bit是否为 1。 b. 如果有效,比较地址中的tag(t bits) 与该缓存行中存储的tag。 - 如果组内有任何一行满足 (a) 有效且 (b) 标签匹配,则为 cache hit。地址中的
block offset(b bits) 选择块内的具体字。
- 地址中的
- 全相联缓存 (Fully associative cache) (page 58):
- 对于缓存中的所有行 ( 因为只有 "entire cache" 一个组 ):
a. 检查
valid bit是否为 1。 b. 如果有效,比较地址中的tag(t bits) 与该缓存行中存储的tag。 - 如果缓存中有任何一行满足 (a) 有效且 (b) 标签匹配,则为 cache hit。地址中的
block offset(b bits) 选择块内的具体字。
- 对于缓存中的所有行 ( 因为只有 "entire cache" 一个组 ):
a. 检查
块识别示例 (page 55, 57, 59) ¶
-
直接映射缓存示例 (1 字块 ) (page 55):
- 指令
LOAD R1, 0x04。假设地址0x04( 二进制 ...00000100)。 - 地址划分: 假设 4 个缓存行,块大小 1 字 (4 字节 )。
- 字节偏移 (Byte Offset, 2 bits):
00( 因为是字地址,最后两位是 00) - 索引 (Index, 2 bits,
log2(4)):01( 来自地址 ...0100 中的 01) -> 选择缓存行 1。 - 标签 (Tag, 剩下高位 ):
...00000
- 字节偏移 (Byte Offset, 2 bits):
- 查找: 访问缓存行 1。比较其 Tag 与地址 Tag。检查 Valid Bit。若命中,取出数据。
- 图中
MEMORY[0x04]的值为0x12345678。 0x04-> Index01( 指向缓存中的第 1 行 ), Tag0x000...0。- 假设此前缓存行 1 中已有数据
0x12345678,其 Tag 为0x000...0,Valid Bit 为 1。 - 比较地址 Tag (
0x000...0) 与缓存行 1 的 Tag (0x000...0) => 相等。 - 检查 Valid Bit (1) 与比较结果 (AND) => Hit。
- 指令
-
全相联缓存示例 (1 字块 ) (page 57):
- 假设缓存有 4 个块。地址格式为
| Tag | Byte Offset |( 无 Index)。 - CPU 发出地址,其 Tag 部分会与缓存中所有 4 个块的 Tag 并行比较。
- 每个块都有一个 Valid Bit。
- 如果任一块的 Valid Bit 为 1 且 Tag 匹配,则为 Hit。
- 假设缓存有 4 个块。地址格式为
-
2 路组相联缓存示例 (page 59):
- 假设缓存有 4 块,每块 1 字。2 块一组,因此有 2 组 (Set 0, Set 1)。
- 地址格式为
| Tag | Index (1 bit) | Byte Offset |。Index 位决定访问 Set 0 还是 Set 1。 - 假设 CPU 发出地址,Index 位为 0,则访问 Set 0。
- 并行比较 Set 0 中两个块的 Tag 与地址的 Tag,并检查它们的 Valid Bit。
- 如果 Set 0 中任一块命中,则为 Hit。
缓存中的总位数计算 (page 65-66) ¶
缓存总位数计算 (page 65-66)
示例 (page 65): 假设一个 4KiB 直接映射数据缓存,块大小为 1 个字 (4 字节 ),地址为 64 位。
- 缓存数据容量: 4KiB = 1024 字。由于块大小为 1 字,所以缓存有 1024 块。
- 块大小 (Block size): 1 word = 4 bytes。
- 字节偏移 (Byte Offset): \(log_2(4) = 2\) bits。
- 索引 (Index): 因为是直接映射,块数 = 1024。索引位数 \(n = log_2(1024) = 10\) bits。
- 幻灯片 page 65 中设定缓存大小是 \(2^n\) 个块,所以 \(n\) 直接是索引位数。块大小为 \(2^m\) 个字,所以 \(m\) 是字选择位。幻灯片这里的 \(m\) 对应块内字偏移,字节偏移固定为 2 位。
- 因此,Index 位数为
n。 - 块内字选择偏移为
m位。 - 总块大小为 \(2^m\) words = \(2^m \times 4\) bytes = \(2^{m+2}\) bytes。
- 所以幻灯片中的
Byte Offset(或说更细的块内地址)实际是m+2位。 - 幻灯片的图示 (page 65 右上 ) 的 Offset 是 Byte offset,包含 word offset (m bits) 和 byte-within-word offset (2 bits)。
- 标记 (Tag): \(64 - (\mathrm{Index\_bits} + \mathrm{Byte\_Offset\_bits}) = 64 - (n + m + 2)\) bits。
- 每行总位数: 数据位 (\(2^m \times 32\) bits) + 标记位 (\(64 - n - m - 2\) bits) + 有效位 (1 bit)。
- 缓存总位数: ( 每行总位数 ) \(\times\) ( 行数 \(2^n\)) \(= 2^n \times (2^m \times 32 + (64 - n - m - 2) + 1)\) \(= 2^n \times (2^m \times 32 + 63 - n - m)\) bits。
示例 1 (page 66): 一个直接映射缓存,16KiB 数据,四字 (four-word) 块,64 位地址。求总位数?
- 数据容量 : 16 KiB = \(16 \times 2^{10}\) Bytes.
- 每个字 4 Bytes ( 标准假设 )。\(16 \text{ KiB} = 16 \times 1024 / 4 \text{ words} = 4096 \text{ words} = 2^{12}\) words.
- 块大小 : 4 words = \(4 \times 4 = 16\) Bytes. 所以 \(2^m = 4 \implies m=2\) ( 这里 m 是块内字偏移的位数 )。
- 字节偏移位数 : \(\text{log}_2(16) = 4\) bits. ( 其中包括字内字节偏移 2 bits, 块内字偏移 m=2 bits)
- 缓存块数 ( 行数 ): \(\text{总数据字节数} / \text{每块字节数} = 16 \text{ KiB} / 16 \text{ B} = 2^{14} / 2^4 = 2^{10} = 1024\) 块 .
- 索引位数 (\(n\)): \(\text{log}_2(1024) = 10\) bits.
- 标记位数 : \(64 - (\mathrm{Index\_bits} + \mathrm{Byte\_Offset\_bits}) = 64 - (10 + 4) = 64 - 14 = 50\) bits.
- 或者按照 page 66 的公式
tag = 64-(n+m+2),这里 \(n=10\) ( 索引块的位数 ), \(m=2\) ( 块内选字的位数 ), \(2\) ( 字内选字节的位数 )。 tag = 64 - (10 + 2 + 2) = 64 - 14 = 50bits.
- 或者按照 page 66 的公式
- 每块数据位 : \(4 \text{ words} \times 32 \text{ bits/word} = 128\) bits.
- 每块总位数 : 数据位 (128) + 标记位 (50) + 有效位 (1) = \(128 + 50 + 1 = 179\) bits.
- 缓存总位数 : \(1024 \text{ 块} \times 179 \text{ bits/块} = 183300 \text{ bits} = 179 \text{ Kibit} = 22.375 \text{ KiBytes}\).
地址映射到多字缓存块 (page 67) ¶
示例 2:地址映射示例 (page 67)
考虑一个拥有 64 个块 (block) 且块大小为 16 字节 (bytes) 的缓存。字节地址 1200 映射到哪个块号?
- 缓存块号 = ( 主存块地址 ) MOD ( 缓存中的块数 )
- 主存块地址 (Block address) = \(\lfloor \text{字节地址} / \text{每块字节数} \rfloor = \lfloor 1200 / 16 \rfloor = \lfloor 75 \rfloor = 75\).
- 缓存块号 = \(75 \text{ MOD } 64 = 11\).
因此,字节地址 1200 映射到缓存中的第 11 号块 ( 从 0 开始计数 )。 实际上,这个块 (主存块75) 映射了从字节地址 \(75 \times 16 = 1200\) 到 \(75 \times 16 + 16 - 1 = 1215\) 之间的所有地址。
有限状态机控制简单缓存 (page 61-62) ¶
缓存的控制逻辑可以通过一个有限状态机 (Finite-State Machine, FSM) 来实现。
- 有限状态机 (finite-state machine): 一个顺序逻辑功能,由一组输入、输出、将当前状态和输入映射到新状态的下一状态函数 (next-state function),以及将当前状态和可能的输入映射到一组断言输出的输出函数组成。
- 下一状态函数 (next-state function): 一个组合逻辑函数,根据输入和当前状态确定有限状态机的下一个状态。
Page 62 展示了一个简单缓存控制的 FSM 状态图,包含以下主要状态和转换:
- Idle ( 空闲 ): 等待 CPU 请求。
- 收到
Valid CPU request: 转移到Compare Tag。
- 收到
- Compare Tag ( 比较标签 ): 比较地址标签,检查是否命中。
Cache Hit: 标记Cache Ready, (如果是写操作且命中,设置Dirty Bit) ,返回Idle。Cache MissandOld Block is Clean( 旧块是干净的,无需写回 ): 转移到Allocate。Cache MissandOld Block is Dirty( 旧块是脏的,需要写回 ): 转移到Write-Back。
- Allocate ( 分配 ): 从内存读取新块。
Memory Ready: ( 数据已读入 ) 转移到Compare Tag( 此时应为命中并向 CPU 提供数据,然后返回 Idle,或者简化为直接返回 Idle,这里图示指向 Compare Tag 再到 Idle)。Memory not Ready: 等待。
- Write-Back ( 写回 ): 将脏块写回内存。
Memory Ready: ( 写回完成 ) 转移到Allocate。Memory not Ready: 等待。
Q3: 块替换 (Block Replacement) (page 69-92) ¶
当发生缓存未命中,并且需要调入的新块所映射的缓存组已满时,必须选择该组中的一个现有块进行替换。
- 直接映射缓存 (Direct-mapped cache) (page 69): 替换策略非常简单,因为每个主存块只能映射到一个固定的缓存行。因此,如果该行已被占用,就直接替换它。
- 组相联和全相联缓存 (Set-associative and fully-associative caches) (page 73): 一个组内有 N 个块可供选择进行替换。
块替换策略 (page 74) ¶
- 随机替换 (Random replacement):
- 随机选择组中的任一个块进行替换。
- 优点 : 硬件实现简单(需要一个随机数生成器
) ,平均情况下性能尚可。将分配均匀地分布在缓存中。 - 缺点 : 可能会替换掉一个即将被访问的块,性能不稳定。
- 最近最少使用 (LRU, Least-Recently Used):
- 选择组中最长时间未被访问的块进行替换。
- 原理 : 基于时间局部性,最近访问的块更可能再次被访问,因此最久未被访问的块最不可能很快被再次访问。
- 优点 : 通常性能较好。
- 缺点 : 实现复杂,需要额外的位来跟踪访问顺序或时间戳,硬件开销大。
- 先进先出 (FIFO, First-In First-Out):
- 选择组中最早进入缓存的块进行替换。
- 原理 : 类似于排队,最早来的最早离开。
- 优点 : 实现比 LRU 简单(只需一个替换指针或时间戳
) 。 - 缺点 : 可能会替换掉频繁使用的块(例如,一个块很早就进入缓存但一直被频繁访问
) 。性能通常不如 LRU。
缓存未命中处理流程 (page 71-72) ¶
- 缓存命中 (cache hit): 如果缓存报告命中,计算机继续使用数据,就像什么都没发生一样。
- 缓存未命中 (cache miss) : 对于缓存未命中,我们可以暂停整个处理器,本质上是冻结临时寄存器和程序员可见寄存器的内容,同时等待内存操作。
指令缓存未命中的处理步骤 (page 72):
- 将原始 PC 值(对于 MIPS 等流水线,可能是 PC+4,所以要用发生取指的 PC,即 PC-4 如果 PC 已更新)发送到内存。
- 指示主内存执行读操作,并等待内存完成其访问。
- 将数据从内存写入缓存条目,将地址的高位(来自 ALU 计算的有效地址,如果是数据缓存;对于指令缓存,是 PC 值)写入标记字段,并设置有效位为 1。
- 从第一步重新启动指令执行,这将重新获取指令,这次会在缓存中找到它。
块替换算法示例 (page 70, 75-79) ¶
Page 70 展示了一个直接映射缓存(8 个块,初始为空)在给定二进制地址序列访问下的状态变化,包括索引、有效位、标签、数据,并标出每次访问是命中 (hit) 还是未命中 (miss)。
场景 (page 75): 假设缓存块大小为 3 ( 即可以容纳 3 个页面 / 块 ),访问序列为 : 2, 3, 2, 1, 5, 2, 4, 5, 3, 4。
使用 FIFO, LRU, OPT (Optimal, 理想最优算法,替换未来最长时间不被访问的块) 模拟缓存的使用和替换。
替换算法模拟 : FIFO (page 76)
缓存容量 : 3
访问序列: 2, 3, 2, 1, 5, 2, 4, 5, 3, 4
| Time | Seq | C0 | C1 | C2 | Hit/Miss | FIFO 队列 ( 队头最早 ) |
|---|---|---|---|---|---|---|
| 1 | 2 | 2 | M | 2 | ||
| 2 | 3 | 2 | 3 | M | 2, 3 | |
| 3 | 2 | 2 | 3 | H | 2, 3 | |
| 4 | 1 | 2 | 3 | 1 | M | 2, 3, 1 |
| 5 | 5 | 5* | 3 | 1 | M | 3, 1, 5 (2 被替换 ) |
| 6 | 2 | 5 | 2* | 1 | M | 1, 5, 2 (3 被替换 ) |
| 7 | 4 | 5 | 2 | 4* | M | 5, 2, 4 (1 被替换 ) |
| 8 | 5 | 5 | 2 | 4 | H | 5, 2, 4 |
| 9 | 3 | 3* | 2 | 4 | M | 2, 4, 3 (5 被替换 ) |
| 10 | 4 | 3 | 2 | 4 | H | 2, 4, 3 |
FIFO 命中 : 3 次 (2, 5, 4)。 PPT 图示有 3 次命中。
替换算法模拟 : LRU (page 77)
缓存容量 : 3
访问序列: 2, 3, 2, 1, 5, 2, 4, 5, 3, 4
| Time | Seq | C0 | C1 | C2 | Hit/Miss | LRU 栈 ( 栈顶 MRU) |
|---|---|---|---|---|---|---|
| 1 | 2 | 2 | M | 2 | ||
| 2 | 3 | 2 | 3 | M | 3, 2 | |
| 3 | 2 | 2* | 3 | H | 2, 3 | |
| 4 | 1 | 2 | 3 | 1* | M | 1, 2, 3 |
| 5 | 5 | 2 | 5* | 1 | M | 5, 1, 2 (3 被替换 ) |
| 6 | 2 | 2* | 5 | 1 | H | 2, 5, 1 |
| 7 | 4 | 2 | 5 | 4* | M | 4, 2, 5 (1 被替换 ) |
| 8 | 5 | 2 | 5* | 4 | H | 5, 4, 2 |
| 9 | 3 | 3* | 5 | 4 | M | 3, 5, 4 (2 被替换 ) |
| 10 | 4 | 3 | 5 | 4* | H | 4, 3, 5 |
LRU 命中 : 4 次 (2, 2, 5, 4)。PPT 图示有 4 次命中。
替换算法模拟 : OPT (Optimal) (page 78)
缓存容量 : 3
访问序列: 2, 3, 2, 1, 5, 2, 4, 5, 3, 4 (未来序列用于决策)
| Time | Seq | C0 | C1 | C2 | Hit/Miss | Future use of C0, C1, C2 items | Replaced |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 2 | M | ||||
| 2 | 3 | 2 | 3 | M | |||
| 3 | 2 | 2 | 3 | H | |||
| 4 | 1 | 2 | 3 | 1* | M | ||
| 5 | 5 | 2 | 3* | 5 | M | 2 (at 6), 5 (at 8), 3 (at 9). 未来最远不用的是 1. | 1 |
| 6 | 2 | 2 | 3 | 5 | H | ||
| 7 | 4 | 2* | 4 | 5 | M | 2(none), 4(at 10), 5(at 8). 未来最远不用的是 3( 无限远 ) or 2( 不再用 ). | 3 |
| 8 | 5 | 2 | 4 | 5 | H | ||
| 9 | 3 | 3 | 4 | 5 | M | 3(none), 4(at 10), 5(none). 此处若替换 2,未来 3、4、5 均有用,选不再用的 2。 | 2 |
| 10 | 4 | 3 | 4 | 5 | H |
OPT 命中 : 5 次。PPT 图示有 5 次命中。 (2, 2, 5, 4, 3(No, 4 is hit))
结论 (page 78): 命中率与替换算法相关。 结论 (page 79): 命中率与访问序列和缓存块大小 ( 容量 ) 相关。
栈替换算法 (Stack Replacement Algorithm) (page 80-86) ¶
- 栈替换算法 (page 80): 一个替换算法如果具有这样的特性:在任何时刻 \(t\),容量为 \(n\) 的缓存 \(B_t(n)\) 中包含的块集合总是容量为 \(n+1\) 的缓存 \(B_t(n+1)\) 中块集合的子集,即 \(B_t(n) \subseteq B_t(n+1)\),则称该算法为栈替换算法。
- LRU 是栈替换算法 (page 81, 85): 增加缓存容量总能(或至少不差于)保持原来小容量缓存中的所有块,并可能容纳更多块,因此命中率不会下降。Page 81 以 n=3 和 n=4 的 LRU 缓存为例,显示了 \(B_t(3) \subseteq B_t(4)\)。Page 85 显示 n=3 时 LRU 命中 2 次,n=4 时命中 4 次。
- FIFO 不是栈替换算法 (page 82, 86): 增加缓存容量有时可能导致命中率下降,这种现象称为 Belady 异常 (Belady's Anomaly)。Page 82 以 n=3 和 n=4 的 FIFO 为例,在第 5 次访问 '1' 时, \(B_5(3) = \{4,1,3^*\}\) (\(3^*\) 代表块 3 最早进入 ),而 \(B_5(4)=\{1^*,2,3,4\}\)。可见 \(B_5(3) \not\subseteq B_5(4)\) ( 块 3 在 \(B_5(3)\) 中却不在 \(B_5(4)\) 中,因为 FIFO 替换的是最早进入的,而 LRU 总是替换最久未用的 )。Page 86 显示,对于序列
1,2,3,4,1,2,5,1,2,3,4,5,n=3 时 FIFO 命中 3 次,n=4 时命中 2 次。
Page 83-84 展示了对于给定序列 2,3,2,1,5,2,4,5,3,2,使用 LRU 算法时,缓存容量 \(N\) 从 1 到 6,命中次数和命中率的变化。命中率随 \(N\) 增加而单调不减。
LRU 硬件实现 (Comparison Pair Method) (page 87-92) ¶
对于一个 N 路组相联缓存的组,如何用硬件实现 LRU?比较对法 (Comparison Pair Method) 是一种思路。
- 基本思想 (page 87): 将组内的每对缓存块组合起来,使用一个“比较对触发器”记录这对缓存块中哪个被更近访问过。然后用门电路组合所有这些触发器的状态,找出 LRU 块。
- 示例 (3 个块 A, B, C) (page 88-90):
- 需要 3 对比较:AB, AC, BC。对应触发器 \(T_{AB}, T_{AC}, T_{BC}\)。
- \(T_{AB}=1\) 表示 A 比 B 更新近访问;\(T_{AB}=0\) 表示 B 比 A 更新近访问。其余类似。
- 判断 C 是 LRU (page 89): 如果 C 最久未被访问,那么 A 一定比 C 新 (\(T_{AC}=1\)),B 也一定比 C 新 (\(T_{BC}=1\))。无论 A 和 B 谁新,此时要替换的是 C。其布尔表达式为 \(C_{LRU} = T_{AC} \bullet T_{BC}\) 。
- 类似地,\(B_{LRU} = T_{AB} \bullet \overline{T_{BC}}\) ( 当 A 比 B 新,C 比 B 新时,B 是 LRU)
- \(A_{LRU} = \overline{T_{AB}} \bullet \overline{T_{AC}}\) ( 当 B 比 A 新,C 比 A 新时,A 是 LRU)
- 状态更新 (page 90):
- 访问 A 后 : \(T_{AB}=1, T_{AC}=1\) (A 比 B 新,A 比 C 新 )。
- 访问 B 后 : \(T_{AB}=0, T_{BC}=1\) (B 比 A 新,B 比 C 新 )。
- 访问 C 后 : \(T_{AC}=0, T_{BC}=0\) (C 比 A 新,C 比 B 新 )。
- Page 90 的图展示了逻辑电路实现。
- 硬件开销分析 (p 个块 ) (page 91-92):
- AND 门数量 : \(p\) 个 ( 每个块一个信号指示其是否为 LRU)。
- 每个 AND 门的输入数量 : \(p-1\) 个。
- 比较对触发器数量 : \(C_p^2 = p(p-1)/2\) 个。
- Page 92 的表格显示,随着块数 p 增加,触发器数量按 \(p^2\) 增长,硬件成本迅速上升。因此,真 LRU 通常只用于路数较少 ( 如 2-4 路 ) 的情况。对于更多路数,会使用近似 LRU 算法。
作业 (Homework) (page 93) ¶
一个直接映射缓存,64 位地址。Tag: 63-10, Index: 9-5, Offset: 4-0。
1. 缓存块大小 (in words)?
- Offset: 4-0,共 5 位。块大小 = \(2^5 = 32\) 字节。
- 假设 1 word = 4 bytes。块大小 = \(32/4 = 8\) words。
2. 缓存有多少块 ?
- Index: 9-5,共 5 位。缓存块数 = \(2^5 = 32\) 块。
3. 总位数与数据存储位数的比率 ?
- Tag: 63-10,共 \(63-10+1 = 54\) 位。
- 每块数据位数: \(32 \text{ bytes} \times 8 \text{ bits/byte} = 256\) bits。
- 每块总位数: 数据 (256) + Tag (54) + Valid bit (1) = \(256 + 54 + 1 = 311\) bits。
- 总位数: \(32 \text{ 块} \times 311 \text{ bits/块} = 9952\) bits。
- 总数据存储位数: \(32 \text{ 块} \times 256 \text{ bits/块} = 8192\) bits。
- 比率: \(9952 / 8192 \approx 1.215\)。
4. 地址引用分析 :
给定十六进制地址序列: 00, 04, 10, 84, E8, A0, 400, 1E, 8C, C1C, B4, 884。
对每个地址:
- 将其转换为 64 位二进制。
- 提取 Tag (高 54 位), Index (中 5 位), Offset (低 5 位)。
- 判断 Hit/Miss,并记录替换情况。
- 最后计算命中率。
作业地址 0x00 分析
地址 : 0x00 (Hex) = 0 (Dec)
二进制 (64 位, 只显示低位): ...00000 00000 00000 (Tag Index Offset)
- Offset (bits 4-0): 00000 (0)
- Index (bits 9-5): 00000 (0)
- Tag (bits 63-10): ...00000 (0)
假设缓存初始为空 (Valid bits = 0 for all entries)。
访问 0x00:
- Tag=0, Index=0, Offset=0.
- 访问 Index 0。由于 Valid=0,这是 Miss。
- 将主存块 (地址 0x0 - 0x1F) 调入缓存 Index 0。设置 Tag=0, Valid=1。
- 替换的字节: (如果之前有内容,会被替换掉)。
地址 0x04:
二进制: ...00000 00000 00100
- Offset: 00100 (4)
- Index: 00000 (0)
- Tag: ...00000 (0)
访问 0x04:
- Tag=0, Index=0, Offset=4.
- 访问 Index 0。Valid=1 (来自上次 0x00 的加载)。比较 Tag: 地址 Tag (0) == 缓存 Tag (0)。 Hit.
需要依次处理所有地址来完成作业。
Q4: 写策略 (Write Strategy) (page 3-10) ¶
当处理器执行写操作 (Store) 时,如果数据在缓存中命中,或者发生写未命中,如何处理缓存和主存中的数据。
写命中 (Write Hit) 策略 (page 3) ¶
- 写穿 (Write-Through):
- 数据同时写入缓存和主存(或下一级存储
) 。 - 优点:
- 主存数据始终最新,简化了多处理器下的一致性维护和 I/O 操作。
- 实现相对简单。
- 读未命中不会导致写回操作。
- 缺点:
- 每次写操作都需要访问主存,速度较慢,可能产生写性能瓶颈。
- 需要较多内存带宽。
- 缓存控制位 : 只需要一个有效位 (valid bit)。因为主存总是最新的,所以可以直接丢弃缓存数据。
- 数据同时写入缓存和主存(或下一级存储
- 写回 (Write-Back):
- 数据只写入缓存。被修改的缓存块标记为“脏” (Dirty) 或“已修改” (Modified) 位。
- 该脏块只有在被替换出缓存时,才写回主存。
- 优点:
- 写操作速度快(只需访问缓存
) 。 - 多次对同一块的写操作只在最后替换时写回一次主存,显著减少了内存带宽需求。
- 写操作速度快(只需访问缓存
- 缺点:
- 主存中的数据可能不是最新的,增加了 I/O 和多处理器一致性维护的复杂性。
- 实现相对复杂。
- 缓存控制位 : 需要有效位 (valid bit) 和脏位 (dirty bit)。
写策略的权衡 (page 3)
- 写穿的优势: 读未命中不导致写操作,内存层次结构数据一致,实现简单。
- 写回的优势: 写操作以缓存速度进行,当同一块发生多次写操作时,主存带宽消耗更小。
写停顿 (Write Stall) 与写缓冲 (Write Buffers) (page 4-5) ¶
- 写停顿 (Write stall): 在写直达策略中,CPU 可能需要等待写操作完成(数据写入主存
) ,这会导致停顿。 - 写缓冲 (Write buffer):
- 一个小型、通常是全相联的 FIFO 缓存,用于暂存等待写入主存的数据。
- CPU 将数据写入写缓冲后即可继续执行,由写缓冲负责后续将数据写入主存。
- 作用: 减少写停顿,尤其是在写操作集中的情况下。
- 局限: 如果写操作的突发速率超过写缓冲的处理能力,写缓冲会填满,CPU 仍可能停顿。
- Page 5 (second PDF) 展示了写缓冲位于 CPU/Cache 和 DRAM ( 或更低级内存 ) 之间。
写未命中 (Write Miss) 策略 (page 6) ¶
当写操作的目标地址不在缓存中时:
- 写分配 (Write Allocate / Fetch on Write):
- 首先将包含目标地址的块从主存读入缓存(类似于读未命中
) 。 - 然后对缓存中的块执行写操作。
- 通常与写回 (Write-Back) 策略配合使用。因为写回策略期望数据在缓存中,通过写分配可以把数据先调进来。
- 首先将包含目标地址的块从主存读入缓存(类似于读未命中
- 非写分配 (No-Write Allocate / Write Around):
- 数据直接写入主存,不将块调入缓存。
- 通常与写直达 (Write-Through) 策略配合使用。因为写直达本来就要写主存,如果数据不在缓存,就没必要先把它调入缓存再写一遍主存。
- 一般原则:
- 写回缓存通常使用写分配。
- 写穿缓存通常使用非写分配。
Page 7 (second PDF) 的流程图对比了两种常见组合:
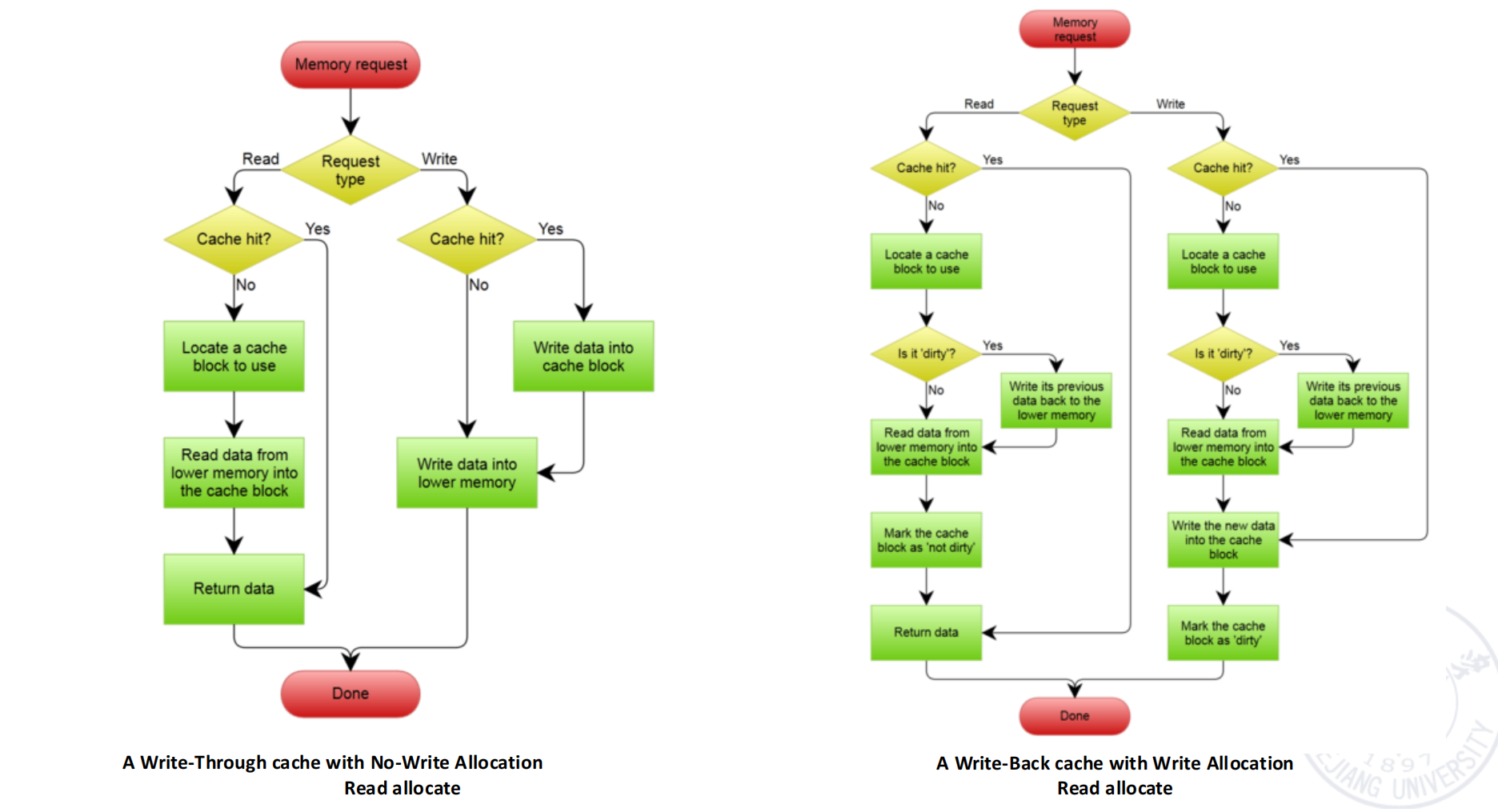
- A Write-Through cache with No-Write Allocation (Read allocate):
- 读请求: 命中则返回数据;未命中则定位缓存块,从低层内存读入,返回数据。
- 写请求: 命中则写缓存块并写低层内存;未命中则直接写低层内存。
- A Write-Back cache with Write Allocation (Read allocate):
- 读请求: 命中则返回数据;未命中则定位缓存块。
- 若旧块是脏的,先写回低层内存。
- 从低层内存读新块到缓存,标记为非脏,返回数据。
- 写请求: 命中则写缓存块,标记为脏;未命中则定位缓存块。
- 若旧块是脏的,先写回低层内存。
- 从低层内存读新块到缓存。
- 将新数据写入缓存块,标记为脏。
- 读请求: 命中则返回数据;未命中则定位缓存块。
写分配策略影响示例 (page 8-9)
假设一个全相联写回缓存,初始为空,有大量缓存条目。内存操作序列 ( 地址在方括号内 ):
write Mem[100];write Mem[100];read Mem[200];write Mem[200];write Mem[100];
比较使用 no-write allocate 和 write allocate 时的命中 / 未命中次数。
使用 No-Write Allocate:
write Mem[100]: Miss ( 写未命中,数据直接写主存,不调入缓存 )。 Cache: empty.write Mem[100]: Miss ( 同上 )。 Cache: empty.read Mem[200]: Miss ( 读未命中,调入 Mem[200])。 Cache:B[200].write Mem[200]: Hit (Mem[200] 在缓存中,写入缓存,标记为 dirty)。 Cache:B[200]*.write Mem[100]: Miss ( 写未命中,数据直接写主存 )。 Cache:B[200]*.
结果 (No-Write Allocate): 4 Misses, 1 Hit. (PPT page 9 标注的是 miss, miss, miss, hit, miss) - PPT 答案符合逻辑,第 4 步写 Mem[200] 在缓存中是 Hit。
使用 Write Allocate ( 写回缓存的典型搭配 ):
write Mem[100]: Miss ( 写未命中,调入 Mem[100],然后写入,标记为 dirty)。 Cache:B[100]*.write Mem[100]: Hit (Mem[100] 在缓存中,写入缓存,保持 dirty)。 Cache:B[100]*.read Mem[200]: Miss ( 读未命中,调入 Mem[200])。 Cache:B[100]*, B[200].write Mem[200]: Hit (Mem[200] 在缓存中,写入缓存,标记为 dirty)。 Cache:B[100]*, B[200]*.write Mem[100]: Hit (Mem[100] 在缓存中,写入缓存,保持 dirty)。 Cache:B[100]*, B[200]*.
结果 (Write Allocate): 2 Misses, 3 Hits. (PPT page 9 标注的是 miss, hit, miss, hit, hit) - PPT 答案符合逻辑。
写策略总结表 (page 10) ¶
| 读策略 | 写命中 (Hit) | 写未命中 (Miss) |
|---|---|---|
| Read through1 | Write-through: 同步写入缓存和后备存储。 | Write allocate: 未命中写位置的数据加载到缓存,然后执行写命中操作。 |
| Read allocate2 | Write-back: 只写入缓存 ( 并标记为脏 )。 | No-write allocate: 未命中写位置的数据不加载到缓存,直接写入后备存储。 |
虚拟内存 (Virtual Memory) (page 11-16) ¶
虚拟内存技术允许程序使用比物理内存更大的地址空间,并且可以为每个进程提供独立的地址空间。 Page 11-13 展示了存储层次图,并强调需要更大的内存来支持更多进程。
- 概念 (page 14-15): 虚拟内存将程序使用的虚拟地址 (Virtual address) 映射到物理内存 (Physical main memory) 或磁盘 (Disk) 上的物理地址 (Physical address)。
- 程序看到的地址空间是连续的虚拟地址。
- 物理上,这些虚拟页面可能分散在物理内存中,甚至部分存储在磁盘上(当物理内存不足时,不常用的页面会被换出到磁盘
) 。 - 这种机制使得程序可以使用不连续的物理内存位置,以及二级存储(磁盘)作为主存的扩展。
- 类比缓存的四个问题 (page 16): 虚拟内存系统的设计也面临与缓存类似的四个问题:
- 块放置 (Page Placement): 一个页面 (page, 虚拟内存的块 ) 可以放在主存的什么位置?( 通常是全相联的,任何虚拟页面可以放在任何物理页帧 )。
- 块识别 (Page Identification): 如何找到主存中的一个页面?( 通过页表 Page Table)。
- 块替换 (Page Replacement): 当发生缺页 (virtual memory miss / page fault) 且主存已满时,替换哪个物理页面?(LRU, FIFO 等近似算法 )。
- 写策略 (Write Strategy): 写操作如何处理?( 通常是写回,脏页面在被替换时写回磁盘 )。
§3.4 内存系统性能 (Memory System Performance) (page 17-23) ¶
CPU 执行时间与内存停顿 (page 17) ¶
CPU 的总执行时间受内存系统性能的显著影响:
\(\text{CPU Execution time} = (\text{CPU clock cycles} + \text{Memory stall cycles}) \times \text{Clock cycle time}\)
其中,内存停顿周期 (Memory stall cycles) 可以表示为: \(\text{Memory stall cycles} = \text{IC} \times \frac{\text{MemAccess}}{\text{Instruction}} \times \text{Miss rate} \times \text{Miss penalty}\) 或者 \(\text{Memory stall cycles} = \text{IC} \times \frac{\text{MemMisses}}{\text{Instruction}} \times \text{Miss penalty}\) (Misses per instruction * Miss penalty)
所以,CPU 时间可以表示为: \(CPUtime = IC \times (CPI_{Execution} + \frac{\text{MemAccess}}{\text{Inst}} \times \text{MissRate} \times \text{MissPenalty}) \times \text{CycleTime}\) 或者 \(CPUtime = IC \times (CPI_{Execution} + \frac{\text{MemMisses}}{\text{Inst}} \times \text{MissPenalty}) \times \text{CycleTime}\)
其中 : - \(IC\): 指令数 (Instruction Count) - \(CPI_{Execution}\): 执行阶段的每指令周期数(假设所有访存都命中缓存) - \(CPI_{Execution}\) 包括 ALU 和内存指令的执行周期。
平均内存访问时间 (Average Memory Access Time, AMAT) (page 18) [todo] ¶
AMAT
平均内存访问时间 (AMAT) 是衡量内存系统性能的一个重要指标。
\(AMAT = \text{Hit time} + (\text{Miss Rate} \times \text{Miss Penalty})\)
对于多级缓存,AMAT 的计算会更复杂。如果考虑指令和数据访问分开:
\(AMAT = (\text{HitTime}_{Inst} + \text{MissRate}_{Inst} \times \text{MissPenalty}_{Inst}) \times \text{Inst Access } \% + (\text{HitTime}_{Data} + \text{MissRate}_{Data} \times \text{MissPenalty}_{Data}) \times \text{Data Access } \%\)
Page 18 给出的另一种 CPU 时间公式,结合了 AMAT:
\(CPUtime = IC \times (\frac{\text{AluOps}}{\text{Inst}} \times CPI_{AluOps} + \frac{\text{MemAccess}}{\text{Inst}} \times AMAT) \times \text{CycleTime}\) (这里 \(CPI_{AluOps}\) 是指纯 ALU 操作的 CPI,AMAT 应以时钟周期为单位)
性能影响示例 (page 19) ¶
性能影响计算
假设:
- 所有指令通常占用 1.0 时钟周期 ( 忽略内存停顿,即 \(CPI_{Execution}=1.0\))。
- 缓存未命中惩罚 (Miss penalty) = 200 时钟周期。
- 平均未命中率 (Miss rate) = 2%。
- 每条指令平均有 1.5 次内存引用 (Memory references per instruction)。
- 每 1000 条指令平均有 30 次缓存未命中 (cache misses per 1000 instructions)。
问题: 包含缓存行为后,对性能有何影响?分别使用未命中率和平均每条指令未命中数来表示。
解答: 1. 使用每指令未命中数计算: - \(\frac{\text{Misses}}{\text{Instruction}} = \frac{30}{1000} = 0.03\) - \(\text{CPUtime} = IC \times (CPI_{Execution} + \frac{\text{Misses}}{\text{Instruction}} \times \text{Miss Penalty}) \times \text{CycleTime}\) - \(\text{CPUtime} = IC \times (1.0 + 0.03 \times 200) \times \text{CycleTime}\) - \(\text{CPUtime} = IC \times (1.0 + 6.0) \times \text{CycleTime} = IC \times 7.00 \times \text{CycleTime}\) - 因此,有效 CPI = 7.00。
- 使用未命中率计算:
- \(\text{Memory stall cycles per instruction} = \frac{\text{Memory references}}{\text{Instruction}} \times \text{Miss rate} \times \text{Miss Penalty}\)
- \(= 1.5 \times 0.02 \times 200 = 1.5 \times 4 = 6.0\)
- \(\text{CPUtime} = IC \times (CPI_{Execution} + \text{Memory stall cycles per instruction}) \times \text{CycleTime}\)
- \(\text{CPUtime} = IC \times (1.0 + 6.0) \times \text{CycleTime} = IC \times 7.00 \times \text{CycleTime}\)
- 有效 CPI = 7.00。
对比: - 有缓存时: CPI = 7.00。 - 无缓存时 ( 每次内存访问都看作未命中,惩罚为 200 周期,或直接访问主存时间 ): \(CPI = CPI_{Execution} + \frac{\text{Memory references}}{\text{Instruction}} \times \text{Main Memory Access Time (cycles)}\) 假设主存访问时间是 200 周期 (等同于未命中惩罚):
$CPI = 1.0 + 1.5 \times 200 = 1.0 + 300 = 301$。
缓存显著降低了 CPI。
缓存性能优化方法 (page 20-22) ¶
主要目标是降低 AMAT: \(AMAT = HitTime + MissRate \times MissPenalty\)
有超过 20 种缓存优化技术,可归为以下几类:
- 减少未命中惩罚 (Reduce the miss penalty):
- 多级缓存 (Multilevel caches): L1 miss 后访问 L2,L2 miss 后访问 L3 或主存。L2 比主存快得多。
- 关键字优先 (Critical word first / Early restart): 块中被请求的字优先传给 CPU,CPU 可以继续执行,同时块的剩余部分继续加载。
- 读未命中优先于写未命中 (Read miss before write miss): 如果读未命中和写缓冲中的写操作竞争内存总线,优先处理读未命中,因为 CPU 通常因读而停顿。
- 合并写缓冲 (Merging write buffers): 将写缓冲中对同一块的多个写操作合并,减少写入主存的次数。
- 受害者缓存 (Victim caches): 一个小型全相联缓存,存放最近被替换出主缓存的块。如果这些块很快被再次访问,可以从受害者缓存快速取回,降低有效未命中惩罚。
- 减少未命中率 (Reduce the miss rate):
- 更大的块大小 (Larger block size): 利用空间局部性,但过大可能增加冲突和未命中惩罚(传输时间长
) 。 - 更大的缓存容量 (Large cache size): 减少容量性未命中,但可能增加命中时间和成本。
- 更高的相联度 (Higher associativity): 减少冲突性未命中,但增加硬件复杂度和命中时间。
- 路预测 (Way prediction) 和 伪相联缓存 (pseudo-associativity): 试图在低相联度下达到高相联度的命中率,同时保持较快的命中时间。
- 编译器优化 (Compiler optimizations): 如循环交换、分块等,改善代码的访存模式以提高局部性。
- 更大的块大小 (Larger block size): 利用空间局部性,但过大可能增加冲突和未命中惩罚(传输时间长
- 减少命中时间 (Reduce the time to hit in the cache):
- 小而简单的缓存 (Small and simple caches): L1 缓存通常小且相联度低,以保证快速命中。
- 避免地址转换 (Avoiding address translation): 在缓存访问路径的关键部分使用虚拟地址索引或物理地址标签,或者在 TLB 和缓存访问并行进行。
- 流水线化缓存访问 (Pipelined cache access): 将缓存访问分解为多个阶段,提高吞吐量。
- 追踪缓存 (Trace caches) 3 : 存储动态指令序列(迹)而非静态指令块,用于提高指令供给带宽。
- 通过并行性减少未命中惩罚和未命中率 (Reduce miss penalty and miss rate via parallelism):
- 非阻塞缓存 (Non-blocking caches / Lockup-free caches): 允许缓存在处理一次未命中的同时,继续响应其他命中请求或处理后续的未命中 (hit under miss, miss under miss)。
- 硬件预取 (Hardware prefetching): 硬件根据访存模式自动将可能很快被访问的数据块提前调入缓存。
- 编译器控制的预取 (Compiler prefetching): 编译器插入预取指令,显式地将数据提前调入缓存。
Page 21-22 的表格总结了各种缓存优化技术对命中时间 (Hit time)、带宽 (Bandwidth)、未命中惩罚 (Miss penalty)、未命中率 (Miss rate)、功耗 (Power consumption)、硬件复杂度 (Hardware complexity) 的影响以及一些评论。例如:
- 更大的块大小: (+) 未命中率 , (0) 硬件复杂度。Pentium 4 L2 用 128 字节。
- 更高的相联度: (+) 未命中率 , (1) 硬件复杂度。广泛使用。
- 多级缓存: (+) 未命中惩罚 , (2) 硬件复杂度。如果 L1 块大小不等于 L2 块大小,则更复杂。
- HBM 作为附加缓存级别: (+/-) 各种指标,取决于新技术,严重依赖命中率提升。
总结 (Summary) (page 23) ¶
- 存储层次 (Memory hierarchy)
- 从单级到多级演变。
- 评估性能 (AMAT, CPI)。
- 缓存基础知识 (Cache basic knowledge)
- 映射规则 (Mapping rules: Direct, Set-associative, Fully-associative)。
- 访问方法 (Access method: Tag, Index, Offset, Valid bit)。
- 替换算法 (Replacement algorithm: LRU, FIFO, Random)。
- 写策略 (Write strategy: Write-through, Write-back, Write-allocate, No-write-allocate)。
- 缓存性能分析 (Cache performance analysis) -> 优化方向:减少未命中率,减少未命中惩罚,减少命中时间。
§3.6 CPU 漏洞 (CPU vulnerabilities) (third PDF) ¶
本节分析利用 CPU 缓存等微架构特性进行攻击的漏洞,特别是 Meltdown 和 Spectre。
相关背景 (page 2) ¶
- 缓存 (Cache): CPU 和主存之间数据交互的桥梁。
- 存储敏感数据(如密钥)时不易被察觉,一旦受攻击则易泄露。
- 不同应用的数据可能共享同一块缓存并相互替换,为侧信道攻击提供了可能。
- 可以突破安全隔离边界。
- 缓存侧信道攻击 (Cache Side-Channel Attack): 攻击者利用访存时延差异推测受害者的访存行为或泄露机密信息。
- 特点 : 细粒度、高隐蔽性。
- 影响 : 容易突破安全隔离边界,实现敏感数据泄露,可跨平台和 CPU。
- 缓存共享模式:
- 处理器核心间缓存共享 (e.g., L3 cache)。
- 同一处理器(核)内不同进程间缓存共享 (e.g., L1, L2 cache)。
计算机存储层次结构一般为:CPU 寄存器 -> 高速缓存 -> 主存储器 -> 辅助存储器。
漏洞介绍:Meltdown 和 Spectre (page 3) ¶
- Meltdown ( 熔断 ):
- 影响主流操作系统 (Linux, macOS, Windows) 上的 Intel CPU。
- 突破内存独立性限制,用户程序可访问整个内核空间和其他用户程序空间。
- 根源 : Intel CPU 的乱序执行 (out-of-order execution) 技术。通过对内存响应时间差建立侧信道攻击。
- “熔化”了由硬件实现的安全边界,低权限用户级应用可“越界”访问系统级内存。
- Spectre ( 幽灵 ):
- 破坏不同应用程序之间的隔离。
- 根源 : 预测执行 (speculative execution)。处理器推测未来有用的数据并执行计算,提前准备结果。
- 在此过程中,Intel CPU 未能很好地隔离低权限应用对内核内存的(预测性)访问,导致恶意应用可获取本应隔离的私有数据。
CPU 缓存缺陷分析 ( 乱序与预测执行 ) (page 4-5) ¶
现代处理器为了提升性能,广泛采用乱序执行和预测执行技术。
- 乱序执行 (Out-of-Order Execution): ( 对应 Meltdown)
- 当一条指令(如指令 A)等待资源(如内存读取)时,CPU 不会空闲,而是继续执行后续不依赖于指令 A 结果的指令(如指令 B
) 。 - 指令的完成 (commit/retire) 仍按程序顺序进行。
- 缺陷: 在指令 A(可能是一个权限检查失败的非法访问)正式完成并触发异常之前,其引发的后续指令(作为乱序执行的一部分)可能已经访问了数据并将数据加载到了 CPU 缓存中。虽然这些指令的最终结果会被丢弃,但 CPU 缓存的状态(某些行被加载)却可能保留下来。
- 当一条指令(如指令 A)等待资源(如内存读取)时,CPU 不会空闲,而是继续执行后续不依赖于指令 A 结果的指令(如指令 B
- 预测执行 (Speculative Execution): ( 对应 Spectre)
- 在遇到分支指令时,分支预测单元 (BPU, Branch Prediction Unit) 会预测哪个分支将被执行。
- CPU 会根据预测提前取指并执行该分支的指令。
- 如果预测正确,则节省了等待分支结果的时间。
- 如果预测错误,则丢弃预测执行的结果,恢复状态,并从正确的分支重新执行。
- 缺陷: 类似于乱序执行,在预测错误被发现、结果被丢弃之前,预测执行的指令可能已经访问了内存并将数据加载到了 CPU 缓存。这个缓存状态的改变可以被侧信道攻击检测到。
Page 4 的图示对比了: 1. 实际执行情况 ( 正常顺序 ): 指令 1 -> 指令 2 -> ( 指令 3 异常 ) -> 指令 4 不执行 -> 读取缓存数据。 2. 指令执行顺序 ( 乱序 / 预测 ): 指令 1 -> 指令 2 -> ( 指令 3 预测 / 乱序执行,发生异常,但未立即处理 ) -> ( 指令 4 预测 / 乱序执行,依赖指令 3 的数据,该数据被加载入缓存) -> ( 检测到异常,回滚 ) 指令 4 实际未执行。 - 关键点: "从内存到缓存加载这个环节不会验证访问的内存是否合法有效... CPU 是在缓存到寄存器这个环节才去检测地址是否合法"。
Page 5 强调 CPU 缓存对于用户是不可直接访问的,数据只有到了 CPU 寄存器用户才拥有访问权限。CPU 的这种设计逻辑本身没有问题,但如果能通过侧信道获取 CPU 缓存中的数据,则存在缺陷。
侧信道攻击缓存 (page 6) ¶
- 多核之间共享缓存(如 L3)以改善 CPU 与内存访问速度的矛盾。
- 缓存命中与失效的响应时间差异是缓存侧信道攻击的基础。
- 攻击者利用此差异,变相猜测 CPU 缓存中的数据。
- 即使数据在 CPU 缓存中但用户态 / 内核态无法直接访问,也可以通过侧信道方式(如
Flush+Reload,Prime+Probe)探测特定内存地址是否在缓存中,从而推断信息。
Meltdown 漏洞原理与攻击过程 (page 7-11) ¶
原理 (page 8) ¶
Meltdown 利用现代 CPU 的乱序执行特性,攻破硬件保证的内存隔离。 乱序执行时,CPU 在等待某些资源(如内存读取)时,会利用空闲计算能力继续执行后续指令。指令的提交 (retirement) 必须按顺序,CPU 的安全检查(如权限检查)在 retirement 时才进行。 结果是,在 CPU 对某条指令进行安全检查前,部分后续指令可能因乱序执行而被提前执行,即使原始指令是非法访问。
攻击过程 (page 9) ¶
典型的处理器流水线分为顺序部分 (In-order: Fetch, Decode, Dispatch, Commit) 和乱序部分 (Out-of-order: Execute)。
1. 获取指令、解码、分发到保留站 (Reservation Stations)。
2. 乱序执行指令,结果保存在重排序缓冲 (Reorder Buffer, ROB)。
3. 提交 / 退休 (Commit/Retire): ROB 中的指令按原始顺序提交,进行安全检查(如地址访问权限
攻击示例 (page 10) ¶
;rcx = kernel address (待窃取数据的内核地址)
;rbx = probe array (用户空间的一个探测数组)
mov al, byte [rcx] ; 非法读取内核地址 rcx 处 1 字节到 al (会导致异常)
shl rax, 0xc ; rax = al * 4096 (4KB,页大小,用于索引 probe_array 的不同页
; //一个内存页大小为 4KB,将 rax 值乘 4096,便于下一条指令实现对探测数组 probe_array 的不同页进行访问
mov rbx, qword [rbx+rax] ; 访问 probe_array[al*4096]
; //对于不同的 al 值,将导致不同的内存页被访问并存放到 CPU 缓存中
利用步骤:
- 指令获取解码。
- 乱序执行:
- 指令 3 (
mov al, byte [rcx]) 尝试读取内核地址。这通常会非常慢(如果不在缓存中)并且最终会因权限不足而失败。 - 在指令 3 的异常被正式处理之前,CPU 可能乱序执行指令 4 和指令 5。
- 指令 4 和 5 依赖于
al的值 ( 来自内核的数据 )。CPU 会预测性地或者作为乱序执行的一部分加载probe_array[al*4096]对应的缓存行到 CPU 缓存中。
- 指令 3 (
- 结果重排与异常处理: 当 CPU 到达提交阶段,发现指令 3 访问违例,会丢弃指令 3、4、5 的执行结果,恢复 CPU 状态到乱序执行前。但关键是,
probe_array中某个元素相关的缓存行可能已经加载到 CPU 缓存中,这个状态不会被恢复。 - 缓存侧信道攻击: 攻击者遍历
probe_array的各个元素(通常是每个元素映射到不同的缓存行,如probe_array[0*4096],probe_array[1*4096], ...,probe_array[255*4096]) 。通过测量访问每个元素的时间,找出哪个元素的访问时间远小于其他元素(因为它在缓存中) 。- 例如,如果发现访问
probe_array[N*4096]特别快,那么攻击者推断出从内核地址rcx读出的字节值al就是N。 - 重复此过程可以逐字节泄露内核内存数据。
- 例如,如果发现访问
缓解措施 (page 12) ¶
- KAISER (Kernel Address Isolation to have Side-channels Efficiently Removed) / KPTI (Kernel Page Table Isolation): 一种内核修改,当用户态程序运行时,不将内核内存映射到用户空间页表中(或只映射极小部分必要入口点
) 。这样用户态程序在乱序执行时也无法直接引用大部分内核地址。 - 问题: 由于 x86 架构设计,仍需在用户空间映射少量特权内存位置,留下残留攻击面。
Spectre 漏洞原理与攻击过程 (page 13-16) ¶
原理 (page 14) ¶
Spectre 利用 CPU 的预测执行 (Speculative Execution) 进行攻击。 分支指令执行时,CPU 会预测分支走向并提前执行。分支预测单元 (BPU) 存储分支历史,用于辅助预测。预测错误时,结果丢弃,状态重置。 然而,与乱序执行类似,预测执行对 CPU 缓存的影响会被保留。
攻击过程 (page 15) ¶
主要分三个阶段:
- 训练 CPU 的分支预测单元 (BPU): 使其在运行漏洞利用代码中的特定分支时,倾向于做出攻击者希望的错误预测。
- 预测执行: 错误的预测执行使得 CPU 访问目标地址(可能是受害者进程空间内的数据
) ,并将该地址的内容(或其衍生的地址)加载到 CPU 缓存中。 - 缓存侧信道攻击: 通过探测缓存状态,推测出哪个地址(通常是攻击者控制的一个探测数组的某个元素)被加载过,从而泄露信息。
攻击示例 (page 15) ¶
1. if (x < array1_size) { // 条件分支
2. y = array2[array1[x] * 256]; // array1[x] 是秘密数据
3. //do something using Y that is // (array1[x]*256 用于索引 array2 的不同缓存行)
4. //observable when speculatively executed // (e.g. load Y into cache)
5. }
攻击步骤:
- 训练 BPU: 反复用合法的
x( 使得x < array1_size为真 ) 调用此代码片段,让 BPU 学习到这个分支通常是会进入的。 - 触发预测执行: 然后,用一个恶意的、精心构造的
x( 使得x >= array1_size,即x是越界的 ) 调用代码。- 由于 BPU 被训练过,它很可能会错误地预测
x < array1_size为真。 - CPU 会预测执行第 2 行的代码。此时,
array1[x]会读取一个越界(可能是受害者进程私有)的数据。 - 这个被非法读取的值(假设为
S)会被用于计算array2[S * 256]的地址。这个地址的数据会被加载到 CPU 缓存中。
- 由于 BPU 被训练过,它很可能会错误地预测
- 检测与回滚: 稍后,CPU 会发现分支预测错误 ( 实际
x >= array1_size),于是丢弃预测执行的结果。 - 侧信道探测: 攻击者测量访问
array2各个元素 (array2[0*256],array2[1*256], ... ) 的时间。如果array2[V * 256]访问很快,则说明秘密值S就是V。
漏洞验证 (page 16) ¶
展示了攻击成功读取私密密码的截图。
缓解措施 (page 17) ¶
- 序列化指令 (e.g., LFENCE): 限制预测执行。在分支指令后插入 LFENCE 等指令,可以阻止其后的指令被预测执行,直到分支结果确定。
- 问题 : 并非所有 CPU 或系统配置都有效,且性能影响大。
- 插入推测执行阻止指令 (Speculative execution barriers): 如 Intel 的 Indirect Branch Restricted Speculation (IBRS), Indirect Branch Predictor Barrier (IBPB), Single Thread Indirect Branch Predictors (STIBP)。或者在每个条件分支后插入 LFENCE。
- 问题 : 严重降低性能。
- 微代码修复现有处理器 (Microcode updates):
- 问题 : 修补程序可能阻止预测执行或预测内存读取,但会极大破坏性能。
- 例如,retpoline 是一种软件构造,它用返回指令替换间接分支,以控制预测执行的目标,对性能影响相对较小。
Meltdown & Spectre 总结对比 (page 18) ¶
- 执行机制:
- Meltdown: 依赖乱序执行。
- Spectre: 使用分支预测来实现推测执行。
- 漏洞利用:
- Meltdown: 利用 Intel 处理器特有的提权漏洞,推测性执行的指令可绕过内存保护。从用户空间非法访问内核内存,在异常发生前,通过缓存侧信道泄露被访问内存的内容。
- Spectre: 利用难度大很多,需要精巧地操纵分支预测。影响更广泛,包括 AMD, ARM, Intel 等多数处理器。KAISER 补丁对 Spectre 无效。
漏洞复现与检测 (page 19-23) ¶
实验环境与工具 (page 20-21) ¶
- 虚拟机 : VMware Workstation
- 系统镜像 : Ubuntu, CentOS
- 物理处理器 : Intel Core i5-7300HQ
- 漏洞检测脚本。
列出了不同 CVE 编号对应的漏洞变种及其影响和缓解措施,例如:
- CVE-2017-5753 (Spectre-V1, Bounds Check Bypass): 编译器插入 LFENCE。
- CVE-2017-5715 (Spectre-V2, Branch Target Injection): 微码更新 (IBRS/IBPB/STIBP) 或 retpoline。
- CVE-2017-5754 (Meltdown, Rogue Data Cache Load): 内核更新 (KPTI)。
- CVE-2018-3640 (Spectre-V3a, Rogue System Register Read): 微码更新。
- CVE-2018-3639 (Spectre-V4, Speculative Store Bypass): 微码更新 + 内核更新使软件自我保护。
Page 21-22 展示了在 Ubuntu 和 CentOS 系统上运行漏洞检测脚本的结果,显示哪些漏洞存在,哪些已缓解。操作系统内核的差异会直接影响漏洞对系统的威胁程度。
POC 代码复现 (page 23) ¶
- Meltdown: POC 代码成功读取到内核中
linux_proc_banner地址上的数据。 - Spectre:
proc攻击利用 CPU 预测执行,提前将私有数据加载到 CPU 缓存,成功读取到内存中的字符数据 "The Magic Words are Squeamish Ossifrage."
攻击结果与场景 (page 24-25) ¶
在实际攻击场景中,这些漏洞可以做到:
- 泄露本地操作系统底层运作信息、密钥等。
- 绕过内核、虚拟机监控器 (HyperVisor) 的隔离防护。
- 在云服务中,泄露其他租户的隐私信息。
- 通过浏览器泄露受害者的账号、密码、内容、邮箱、cookie 等用户隐私信息。
其他新场景下的攻击 (page 25):
- 基于硬件特性的攻击: 利用查找逻辑、替换策略、预取技术、瞬态执行 (Transient Execution) 等处理器微架构特性。需要对硬件深入了解,发现难度大,通常对软件透明,难检测。
- 安全机制场景下的攻击: 即使在可信执行环境 (TEE, Trusted Execution Environment) 下,若不同安全域间存在缓存共享且隔离不彻底,TEE 也可能被缓存侧信道攻击。
- 性能驱动下的攻击: 某些场景对攻击性能(速度、精度、泄露信息量)要求苛刻,如被攻击程序运行窗口过短、系统并发噪声大、缓存预取干扰等。
攻击分布情况 (page 26) ¶
表格展示了各类攻击(访问驱动、建模分析、针对 LLC 的、新场景的)在 Intel, AMD, ARM 处理器上的分布情况。 结论:目前主流商用处理器均未能完全抵御缓存侧信道攻击。Intel 处理器因性能优化忽略了许多安全考虑,导致几乎任何 Cache 攻击均能实现。
Cache 安全增强方案 (page 27-33) ¶
商用处理器已有防御方案 (page 29) ¶
| 攻击类型 | Intel 防御方法 | ARM 防御方法 |
|---|---|---|
| 边界检查绕过 (Spectre-V1) | 内存屏障指令 : LFENCE | 新内存屏障指令 : CSDB |
| 分支目标注入 (Spectre-V2) | 返回跳板 (retpoline), IBRS, IBPB, STIBP | 无通用缓解方法 ( 具体实现可能不同 ) |
| 数据缓存恶意加载 (Meltdown) | 内核页表隔离技术 (KPTI) | (ARM 部分架构不受此影响 ) |
| 系统寄存器恶意加载 | 更新微码 | 非必要 |
| 推测存储绕过 (Spectre-V4) | LFENCE 指令 ; 特殊模块寄存器 (MSR) SSBD (Speculative Store Bypass Disable) 标识位 | 两种新内存屏障指令 : SSBB, PSSBB |
目前防御主要针对已披露的 Meltdown 和 Spectre。
基于软件的防御机制分析 (page 30) ¶
- 漏洞检测方法: 通过静态或动态程序分析,找出程序中可能存在缓存侧信道漏洞的部分。
- 用户级防御措施: 在漏洞检测基础上增强用户程序,如保持特定运算时间恒定 ( 抵抗计时攻击 )、清除缓存状态等。
- 系统级防御措施: 从操作系统 / 虚拟机管理器角度防御,如完善内存管理、锁定缓存行等,避免攻击者恶意探查。
- 优点: 软件实现灵活,可快速部署。
- 缺点: 依赖下层微架构实现,或需硬件额外支持以降低开销。长期看需从硬件层面防范。
基于硬件的防御机制分析 (page 31-32) ¶
- 缓存分组方法 (Cache Partitioning) (page 31):
- 将缓存划分为不同区域 (e.g., 基于路 Way-based Partitioning),分配给不同进程使用,实现隔离。
- 优点: 原理上完全避免侧信道攻击。
- 缺点: 实现受硬件限制,对性能影响较大。
- 图示 : Way 0 分给受保护进程,Way 1-3 分给其他进程。
- 缓存随机化方法 (Cache Randomization) (page 32):
- 消除特定地址在缓存中的固定映射,使攻击者难以推断访存地址。
- 基于表的映射: 随机映射存储于表,查表获取实际缓存索引。
- 基于计算的映射: 根据地址通过加密等方法计算随机映射。
- 优点: 性能开销较小,有效性得到验证。
- 缺点: 无法完全避免侧信道攻击,但能大幅缓解。
- 图示 : 传统缓存直接用地址某部分做索引;随机化缓存通过映射函数 (Mapping Function) 将物理地址映射到 Set Index。
其他防御策略 (page 33) ¶
- 针对目录结构的防御方法:
- 源头出发: 增加目录项数量,减少目录项使用冲突 ( 针对 LLC 中的目录 )。
- 最终目标出发: 检测跨核心缓存行替换,重载被替换的缓存行至 L2 ( 防止数据从 LLC 被逐出后信息泄露 )。
- 完善软硬件协作关系:
- 重新思考软硬件协作,定义新指令集体系结构 (ISA)。
- 数据遗忘编程 (Data Oblivious Programming): 消除机密信息与分支执行时延差异的关联。代码执行路径和内存访问模式不依赖于秘密数据。
- 通过优化基本块执行减少指令执行时的分支预测依赖。
总结 ( 全章 ) (page 34) ¶
- 技术趋势与存储层次 (Trend and Memory Hierarchy)
- 处理器 - 内存性能差距 (Processor-Memory Performance Gap)
- 缓存局部性 (Cache Locality): 时间局部性 (Temporal locality), 空间局部性 (Spatial locality)
- 缓存命中 / 未命中 (Cache hit/miss)
- 缓存设计的四个核心问题 (Four Questions for Cache Designers)
- 缓存性能 (Cache performance)
- CPU 漏洞与缓存安全 (CPU vulnerabilities & Cache security)
-
"Read through" 通常指一种缓存策略,其中数据不仅从缓存中读取,如果未命中,则从主存读取并通过缓存传递给 CPU,同时存储在缓存中。这里的表格标题可能是指缓存的一般读操作行为。 ↩
-
"Read allocate" 指在读未命中时,将数据块分配并加载到缓存中。这是标准的缓存行为。 ↩
-
追踪缓存 (Trace Cache) 是一种特殊的指令缓存,它存储的是处理器实际执行过的动态指令序列(称为“迹”或“trace”
) ,而不是静态的、按程序顺序排列的指令块。当处理器遇到一个已经被捕获在追踪缓存中的指令序列的入口点时,它可以直接从追踪缓存中获取整个序列,从而绕过传统指令缓存中可能存在的取指瓶颈(如分支指令、非连续内存访问等) 。这对于提高具有复杂控制流的程序的指令供给带宽特别有效。 ↩