数据级到线程级并行 ¶
本篇文档旨在全面、深入地探讨现代计算机系统中的核心主题——并行计算。我们将从计算机系统的宏观抽象模型出发,理解程序、指令集与处理器之间的关联,并逐步深入探讨两种主要的并行形式:数据级并行(DLP)和线程级并行(TLP
计算机系统的宏观视角 (page 3-9) ¶
在深入并行计算之前,我们首先建立一个宏观的认知框架,理解计算机系统不同层次之间的关系。
状态机:程序、指令集与处理器的统一抽象 (page 4-5) ¶
从根本上说,计算机系统的核心组件都可以被抽象为状态机 (State Machine)。一个状态机由状态集合、激励事件、状态转移规则和初始状态定义。
- 程序是状态机:一个程序的状态可以由其所有变量的当前值和程序计数器(PC)共同定义。程序的每一条语句(如 C 语言语句)的执行,就是一次状态转移。其状态转移的规则由高级语言的语义(如 C 语言标准手册)所规定。
- 处理器是状态机:一个硬件处理器的状态由其内部所有寄存器、时序逻辑电路(如触发器)的当前值定义。时钟信号的每个周期都会触发一次状态转移,其规则由组合逻辑电路和处理器的设计文档决定。
- 指令集是状态机:指令集(Instruction Set Architecture, ISA)是介于软件和硬件之间的抽象层。它定义了一个抽象的计算机模型,其状态包括寄存器和内存。每一条指令的执行都会根据指令的语义(由指令集手册规定)来改变这个抽象状态。
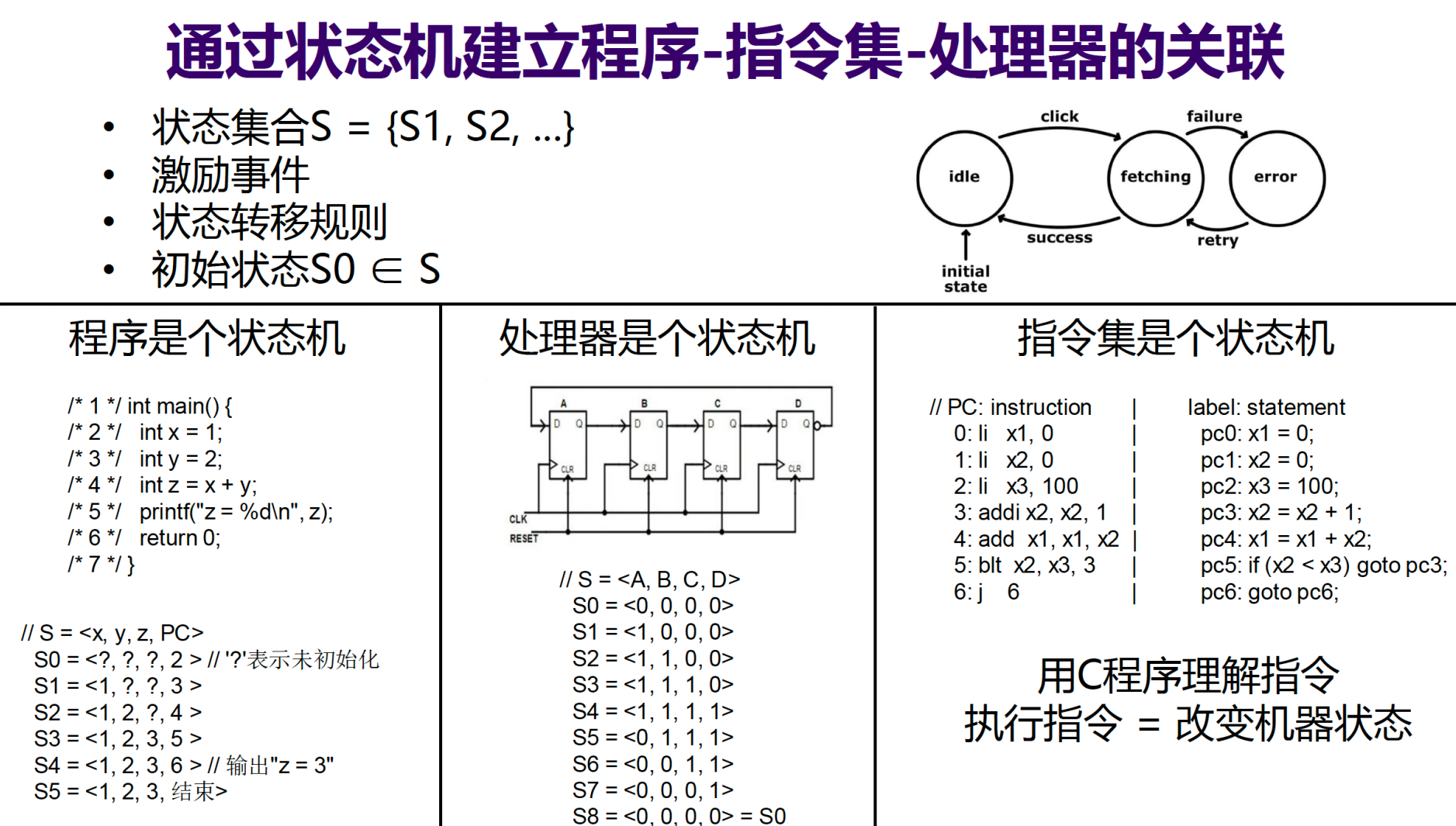
这三个状态机关联在一起,构成了程序在处理器上运行的基本原理:
- 编译 (Compilation):编译器将高级语言程序(如 C 代码)翻译成语义等价的指令序列。
- 实现 (Implementation):架构师根据指令集手册设计出行为等价的电路,即处理器。
- 运行 (Execution):指令序列控制处理器内部的电路进行状态转移,从而实现了程序的逻辑。
计算机系统的分层与演进 (page 6-9) ¶
一个完整的计算机系统可以看作是一个分层的软硬件协同体系。随着技术的发展,这个体系的复杂性也在不断增加,以支持更强大的计算能力,尤其是并行处理能力。
- 系统 1 ( 基础单周期模型 ):这是最简单的计算机模型,包含 CPU(控制器、运算器、寄存器组、PC
) 、内存和 I/O 设备。它对应冯 · 诺依曼架构的基本原理,能够执行 ISA 定义的指令。 - 系统 2 ( 流水线与操作系统 ):为了提升性能,引入了流水线 (Pipelining) 技术。这带来了冒险 (Hazard) 问题,需要在硬件层面增加冒险检测 (Hazard Detection) 和前递单元 (Forwarding Unit)。同时,为了管理复杂的硬件资源和多任务,引入了操作系统 (Operating System),通过系统调用 (System Call) 与硬件交互,实现了进程管理、调度和通信等功能。
- 系统 3 ( 高级并行与存储层次 ):为了进一步挖掘性能,系统引入了更高级的并行技术。
- 指令级并行 (Instruction-Level Parallelism, ILP):通过分支预测单元 (Branch Prediction Unit, BPU)、寄存器重命名 (Register Renaming, RAT)、保留站 (Reservation Stations, RS) 和重排序缓冲区 (Re-order Buffer, ROB) 等技术实现超标量和乱序执行。
- 数据级并行 (Data-Level Parallelism, DLP) 和 线程级并行 (Thread-Level Parallelism, TLP):这是本篇的重点,通过专门的硬件单元(如 SIMD 单元)和多核架构来利用。
- 存储层次 (Memory Hierarchy):引入了 Cache 和 内存管理单元 (Memory Management Unit, MMU)/TLB 来解决 CPU 与主存之间的速度鸿沟,并支持虚拟内存。
数据级并行 (DLP) 与 SIMD 架构 (page 10-129; page 130-137) ¶
Flynn 分类法
迈克尔 · 弗林(Michael J. Flynn)在 1966 年提出了基于指令流和数据流数量的计算机架构分类法,即 Flynn 分类法:
- SISD (Single Instruction, Single Data):单指令流,单数据流。这是传统的串行冯 · 诺依曼计算机模型。
- SIMD (Single Instruction, Multiple Data):单指令流,多数据流。一条指令可以同时对多个数据执行操作。这是实现 DLP 的关键。向量处理器和阵列处理器是其典型代表。
- MISD (Multiple Instruction, Single Data):多指令流,单数据流。较为罕见,有时用于容错系统。
- MIMD (Multiple Instruction, Multiple Data):多指令流,多数据流。多个处理器同时执行不同的指令处理不同的数据。多核处理器是其主流实现。
数据级并行(Data-Level Parallelism, DLP)是指程序中存在大量可以同时对不同数据执行相同操作的机会。这种并行性在科学计算、多媒体处理等领域非常普遍。开发 DLP 的主要架构是 SIMD。
向量处理器 (Vector Processor) (page 12-44) ¶
向量处理器 (Vector Processor) 与标量处理器 (Scalar Processor)
- 向量处理器:一种流水线处理器,它设置了向量数据表示方式(即向量寄存器)和相应的向量指令。一条向量指令可以对整个向量(一组数据)进行操作。
- 标量处理器 (Scalar Processor):传统的流水线处理器,没有向量数据表示和向量指令,一次只能处理单个数据元素(标量
) 。
向量处理的核心优势在于,向量中的各个元素在运算时通常是独立的,极少存在数据依赖关系,这天然地适合流水线并行处理。
向量计算的处理方式 ¶
考虑一个典型的向量运算 D = A × (B + C),其中 A, B, C, D 都是长度为 N 的向量。有三种处理该运算的方式:
- 水平处理 (Horizontal processing)
- 过程:按行(row-wise)计算,依次完成每个元素
d_i的完整计算。即先计算d_1 = a_1 × (b_1 + c_1),再计算d_2 = a_2 × (b_2 + c_2),以此类推。这等价于一个循环程序。 - 问题:
- 数据相关:在计算每个
d_i时,k_i = b_i + c_i和d_i = a_i × k_i之间存在写后读 (Read-After-Write, RAW) 相关。 - 流水线效率低:如果加法和乘法使用不同的功能单元(例如,在静态多功能流水线中
) ,则每次循环都需要切换功能单元,导致流水线频繁排空和重新充满,吞吐率甚至低于串行执行。因此,水平处理不适合向量处理器。
- 数据相关:在计算每个
- 过程:按行(row-wise)计算,依次完成每个元素
- 垂直处理 (Vertical processing)
- 过程:按列(column-wise)计算,先完成所有元素的加法,再完成所有元素的乘法。即
K = B + C,然后D = A × K。 - 特点:这种方式将一个复杂的向量表达式分解为一系列简单的向量指令。数据相关只在向量指令之间存在(
D依赖K) ,而向量指令内部的元素计算是并行的。 - 架构要求:由于中间结果向量
K需要被存储,这种方式要求处理器具有内存 - 内存 (memory-memory) 架构,即源向量和目标向量都存储在内存中。这会导致较高的内存访问延迟。
- 过程:按列(column-wise)计算,先完成所有元素的加法,再完成所有元素的乘法。即
- 垂直与水平结合处理 ( 分组处理 , Grouping)
- 过程:将长向量 N 分成 S 个长度为 n 的组(
N = S × n + r) ,然后对每个组(剩下的 r 也视为一个组,故共 S+1 个组)进行垂直处理。 - 特点:这是对垂直处理的优化,旨在平衡计算和访存。
- 架构要求:为了高效处理分组,最好将当前处理的组缓存在高速存储中。这引出了寄存器 - 寄存器 (register-register) 架构,即设置专门的向量寄存器 (vector registers) 来存储源向量、目标向量和中间结果,从而形成高效的操作流水线。
- 过程:将长向量 N 分成 S 个长度为 n 的组(
向量处理方式对比
| 处理方式 | 核心思想 | 优点 | 缺点与架构要求 |
|---|---|---|---|
| 水平处理 | 循环处理每个元素 | 逻辑简单,类似标量代码 | RAW 依赖严重,流水线效率极低 |
| 垂直处理 | 分解为多个向量指令 | 充分利用流水线,依赖少 | 需要存储整个中间向量,要求内存 - 内存架构,延迟高 |
| 分组处理 | 垂直处理的分块版本 | 平衡计算与访存 | 要求寄存器 - 寄存器架构,引入向量寄存器 |
现代向量处理器(如 CRAY-1)和 SIMD 扩展(如 RV64V)普遍采用寄存器 - 寄存器架构。
CRAY-1 向量处理器案例分析 (page 23-29) ¶
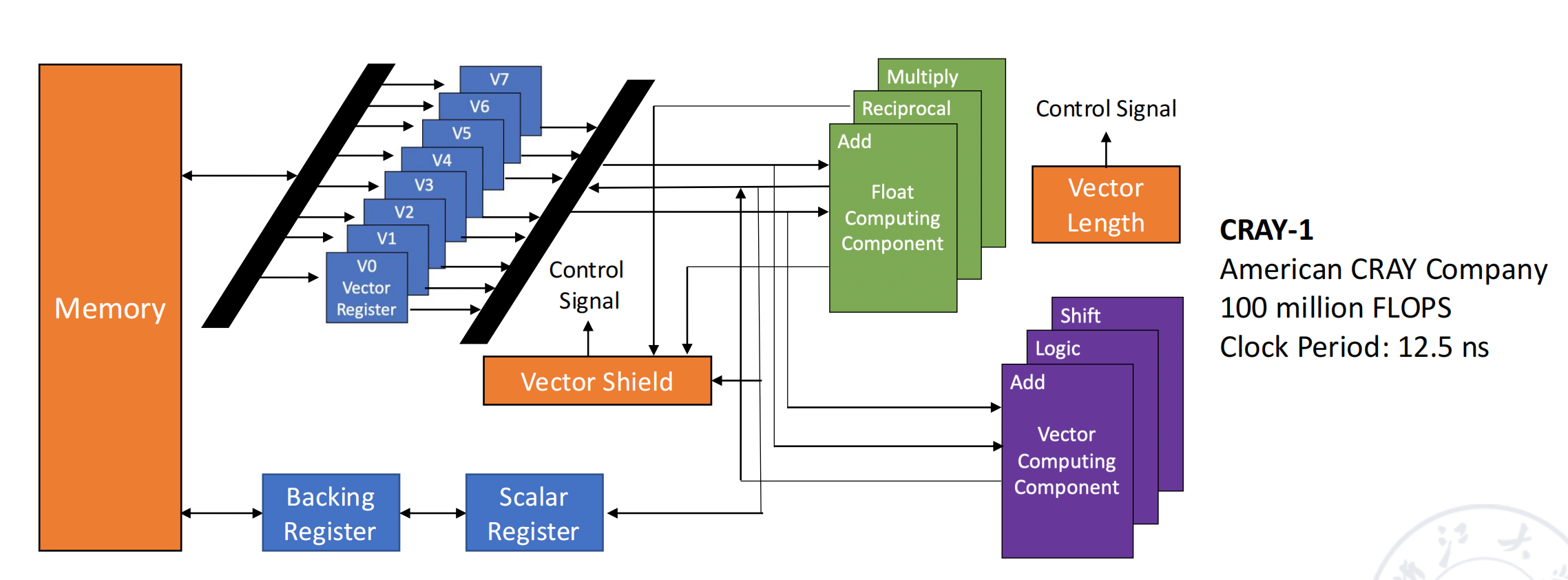
CRAY-1 是向量处理器的里程碑。其设计思想至今仍有影响力。
- 核心架构:
- 12 个并行功能单元:包括向量、浮点、标量、地址计算单元,每个单元都是流水化的,可以并行工作。
- 寄存器 - 寄存器架构:拥有 8 个向量寄存器(Vi
) ,每个寄存器包含 64 个 64-bit 的元素。 - 高性能:时钟周期 12.5ns,峰值性能可达 100 MFLOPS。
- 并行执行的冲突:
- Vi 冲突:并行执行的多条向量指令使用了同一个向量寄存器作为源或目标。
- 写后读相关:
V3 ← V0 × V4依赖于V0 ← V1 + V2的结果。 - 资源冲突:
V3 ← V1 × V4与V0 ← V1 + V2同时读取V1是允许的(如果寄存器堆支持多端口读) 。
- 写后读相关:
- 功能单元冲突:并行执行的多条指令需要使用同一个功能单元(例如,两条浮点乘法指令
) 。后一条指令必须等待前一条指令的最后一个元素计算完成并释放功能单元后才能开始。
- Vi 冲突:并行执行的多条向量指令使用了同一个向量寄存器作为源或目标。
- 指令类型:CRAY-1 支持多种向量指令格式,包括:
- 向量 - 向量操作:
Vk ← Vi op Vj - 向量 - 标量操作:
Vk ← Si op Vj - 内存加载 / 存储:
Vk ← Memory,Memory ← Vi
- 向量 - 向量操作:
提升向量处理器性能的技术 (page 30-41) ¶
-
多功能单元并行:CRAY-1 有 12 个独立的功能单元,只要不存在资源冲突,就可以并行执行不同类型的操作。
-
向量链接 (Vector Chaining)
- 思想:将存在写后读(RAW)依赖的向量指令的执行过程像流水线一样连接起来。一旦第一个操作数准备好,就可以立即送入下一个功能单元,而无需等待整个前序向量指令全部完成。这本质上是将流水线思想应用到了向量指令序列的执行中。
- 条件:两条指令存在 RAW 依赖,且不争用功能单元。
向量链接性能分析
问题:在 CRAY-1 上计算 D = A × (B+C),向量长度为 N (N ≤ 64)。假设浮点加法流水线 6 级,浮点乘法 7 级,访存和寄存器传输各需 1 个时钟周期(beat
指令序列:
1. V3 ← memory (加载向量 A)
2. V2 ← V0 + V1 (B 和 C 已在 V0, V1)
3. V4 ← V2 × V3 (最终结果存入 V4)
流水线启动开销:一条向量指令从开始到第一个结果产出所需的时间。
- 访存:1 (启动) + T_mem + 1 (写回),这里简化为 1+6+1=8 拍 (假设内存延迟为 6)。
- 加法:1 (读) + T_add + 1 (写回) = 1 + 6 + 1 = 8 拍。
- 乘法:1 (读) + T_mul + 1 (写回) = 1 + 7 + 1 = 9 拍。
总执行时间 (T_first_result + N - 1)
- 串行执行:三条指令依次执行。
T = (8 + N - 1) + (8 + N - 1) + (9 + N - 1) = 3N + 22
-
部分并行:指令 (1) 和 (2) 无依赖,可以并行。指令 (3) 依赖它们的结果。
T = max(T_load, T_add) + T_mul = max(8 + N - 1, 8 + N - 1) + (9 + N - 1) = 2N + 15 -
使用向量链接:指令 (2) 和 (3) 之间、指令 (1) 和 (3) 之间都可以形成链接。指令 (1) 和 (2) 并行启动。指令 (3) 的第一个元素计算,需要等待指令 (2) 的第一个结果(第 8 拍)和指令 (1) 的第一个结果(第 8 拍
) 。因此,指令 (3) 可以在第max(8, 8) = 8拍后启动。\(T = max(T_{load setup}, T_{add setup}) + T_{mul} + N - 1 => T = \max(8, 8) + 9 + N - 1 = 8 + 9 + N - 1 = N + 16\)
这里的 \(T_{mul}\) 是乘法流水线的深度加传输开销,即 9 拍。
结论:向量链接技术极大地重叠了指令执行,显著减少了总执行时间。
-
分段向量处理 (Segmented Vector):当向量长度超过向量寄存器长度时,硬件和软件会自动将长向量分割成段,以循环方式处理。这个过程对程序员是透明的。
-
多处理器系统:如 CRAY-2, CRAY Y-MP 等后续机型通过集成多个向量处理器来进一步提升整体性能。
RV64V 和多通道 (Multiple Lanes) (page 42-44) ¶
现代 RISC-V 指令集中的向量扩展(V 扩展)借鉴了 CRAY-1 的思想,并进行了现代化改造。
- RV64V 特点:
- 基于 CRAY-1 的寄存器 - 寄存器模型。
- 32 个向量寄存器,由 16 个读端口和 8 个写端口。
- 全流水线的向量功能单元。
- 多通道 (Multiple Lanes) 设计:为了实现每个时钟周期处理多个元素,向量单元可以被设计为多个并行的通道。例如,一个 4 通道的加法器可以同时计算
c[0]=a[0]+b[0],c[1]=a[1]+b[1],c[2]=a[2]+b[2],c[3]=a[3]+b[3]。 - 硬件接线简化:RV64V 指令集规定,向量运算中,一个向量寄存器的第 N 个元素只能与另一个向量寄存器的第 N 个元素进行运算。这个“硬连线”属性极大地简化了多通道并行设计,因为不需要复杂的交叉开关。
DAXPY 在标量 RISC-V 与 RV64V 上的对比
DAXPY 操作: Y = a*X + Y( 双精度浮点 )
标量 RISC-V 代码 ( 循环实现 ):
Loop: fld f1, 0(x5) # Load X[i]
fmul.d f1, f1, f0 # a * X[i]
fld f2, 0(x6) # Load Y[i]
fadd.d f2, f2, f1 # (a * X[i]) + Y[i]
fsd f2, 0(x6) # Store new Y[i]
addi x5, x5, **8**{: .hash} # Increment pointer for X
addi x6, x6, **8**{: .hash} # Increment pointer for Y
bne x28, x5, Loop # Check loop condition
addi, bne)和数据依赖。
RV64V 向量代码:
向量代码简洁明了,没有循环控制开销,将并行性明确地暴露给硬件。阵列处理器 (Array Processor) (page 45-52) ¶
阵列处理器 (Array Processor)
阵列处理器是 SIMD 的另一种实现形式。它由多个重复的处理单元 (Processing Elements, PE) 构成阵列,在一个单一控制单元 (Control Unit, CU) 的控制下,并行地对分配给各个 PE 的数据执行相同的指令。
Array processors are sometimes called parallel processors.
-
经典案例:ILLIAC IV
- 由 64 个 PE 组成 8x8 的阵列。
- 控制单元广播指令给所有 PE,PE 并行执行。
- 每个 PE 有自己的本地存储器 (PEM)。
-
根据系统中内存的组成,阵列处理器分为两种基本结构
- 分布式存储 (Distributed memory):每个 PE 拥有自己私有的本地存储器(PEM
) ,PE 之间通过互连网络(ICN)通信。这是 SIMD 阵列处理器的主流配置。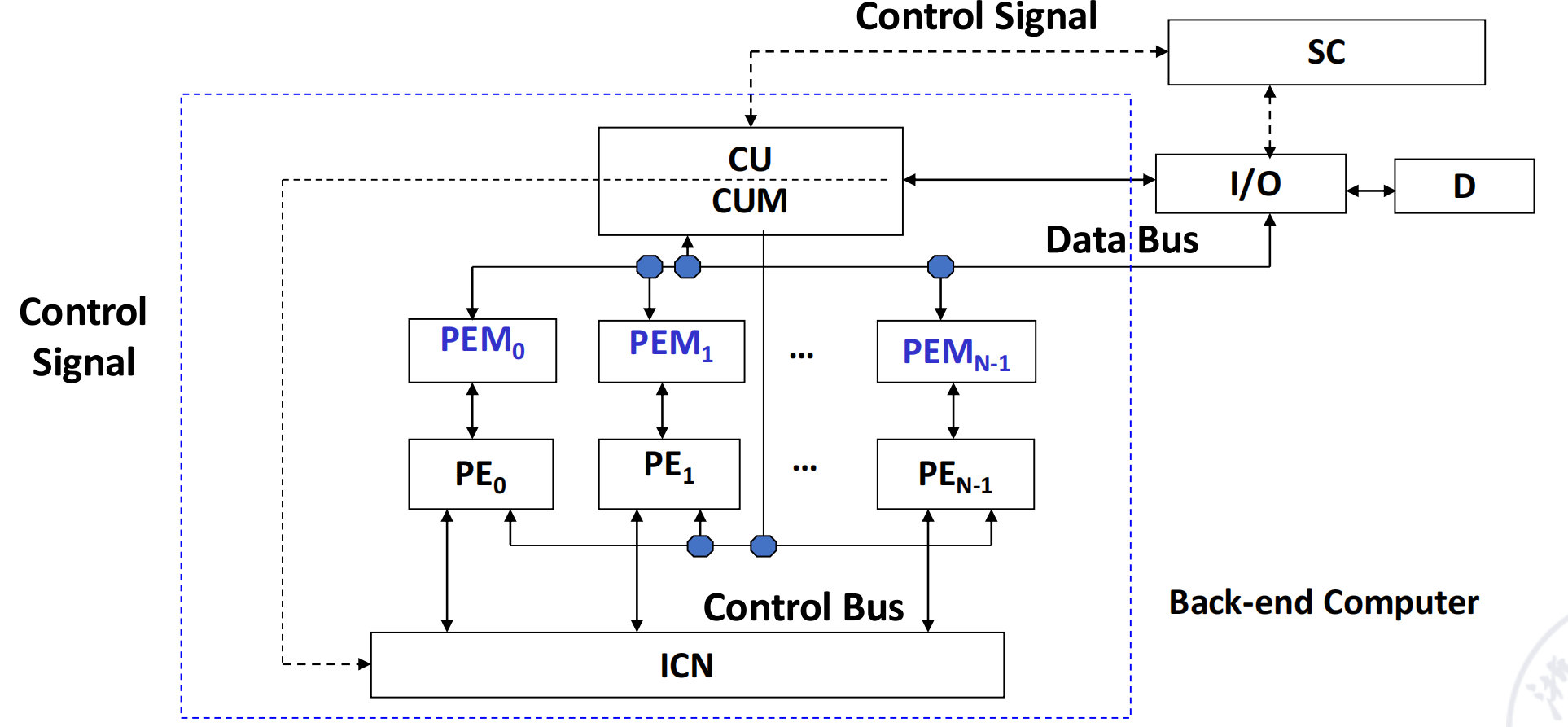
Distributated memory
- 分布式存储 (Distributed memory):每个 PE 拥有自己私有的本地存储器(PEM
- 集中式共享存储 (Centralized shared memory):所有 PE 共享一组存储模块(MM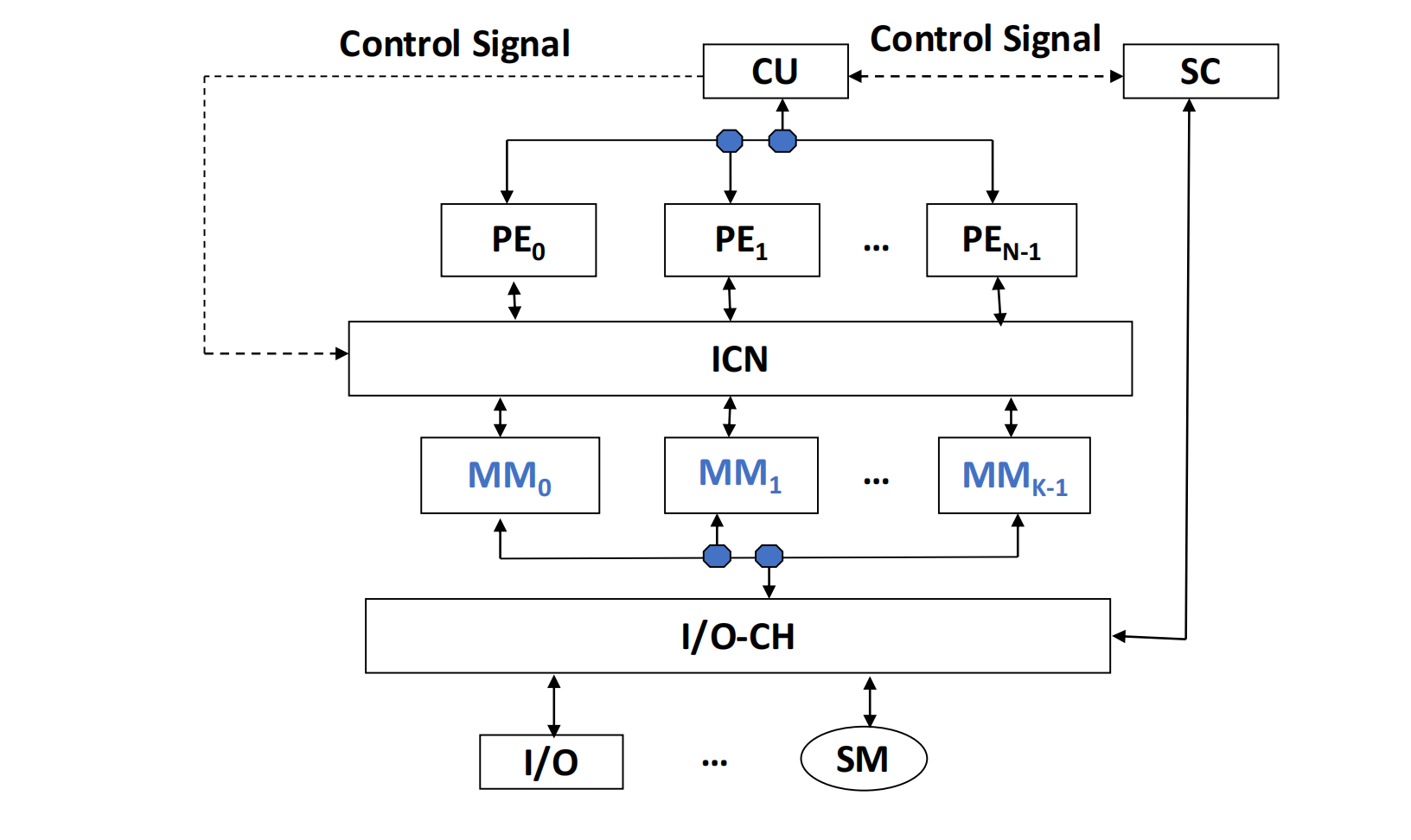
互连网络 (Interconnection Network) (page 53-128) ¶
无论是阵列处理器还是多核 / 多处理器系统,处理单元之间的通信都是通过互连网络实现的。
互连网络 (Interconnection Network)
互连网络是由交换单元和链路组成的网络,根据一定的拓扑结构和控制方式,实现计算机系统内多个处理器或功能部件之间的互连。
如果每两个处理单元之间都直接联通,需要 \(C_{n}^{2} = \frac{n(n-1)}{2}\) 次连接,难以实现。
设计核心问题 (page 57) ¶
- 拓扑结构 (Topology):节点和链路的连接方式;静态拓扑、动态拓扑。
- 时钟模式 (Time mode):处理单元同步 / 异步。
- 交换方式 (Switching):电路交换、分组交换。
- 控制策略 (Control):集中式 vs. 分布式。
互连网络分类与目的 (page 58-59) ¶
- 静态网络 (Static Network):节点间的连接路径在程序执行期间是固定的,通常用于 PE 之间或计算机节点之间的直接连接。
-
动态网络 (Dynamic Network):由交换机组成,可以根据应用需求动态改变连接状态,如总线、交叉开关等。
-
单级网络 (Single-stage)
-
多级网络 (Multi-stage)
-
互连网络的目的:经过有限次连接,任意两个处理单元可以在一步或者几步之内及进行信息传递。
静态互连网络 ( 单级网络 ) (page 62-95) ¶
静态网络的目标是使用有限的连接,让任意两个 PE 能够通过一步或几步完成信息传输。
- 立方体网络 (Cube Network)
- 定义:对于 N 个节点(\(N = 2^n\),即 \(n = \log N\)
) ,每个节点用 n-bit 二进制编码。\(Cube_i\) 函数将一个节点的地址P连接到其第i位取反的地址P'。 - 公式:\(Cube_i(P_{n-1}...P_i...P_0) = P_{n-1}...\overline{P_i}...P_0\)
- 特性:n 维立方体(超立方体 , Hypercube)网络中,任意两点间的最大距离(直径)为 n。
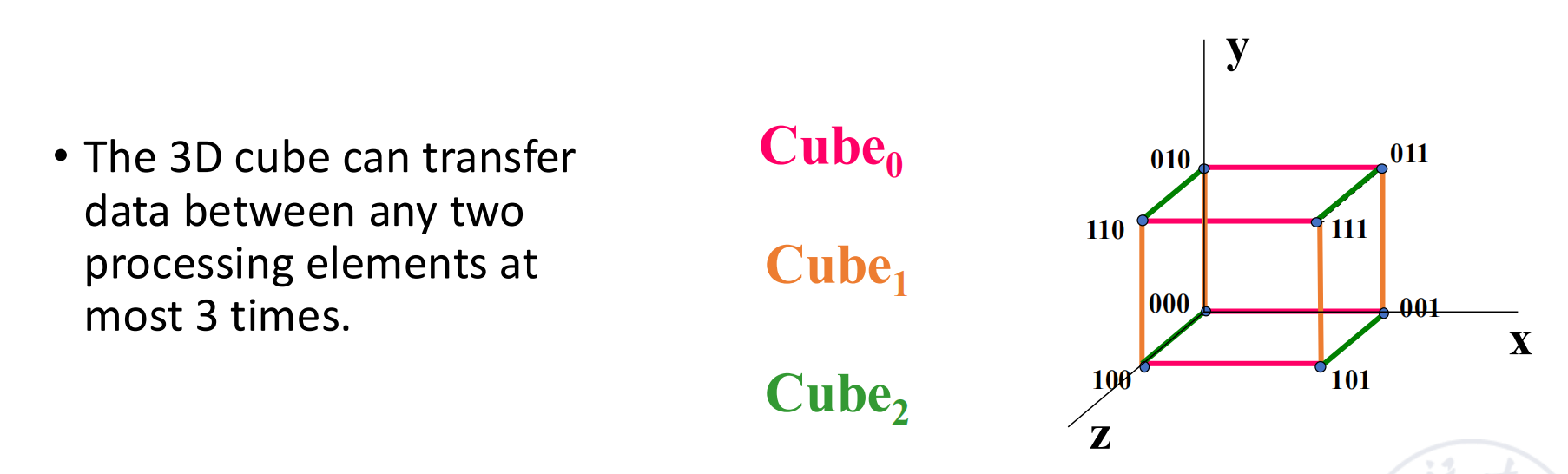
3D Cube Network
- 定义:对于 N 个节点(\(N = 2^n\),即 \(n = \log N\)
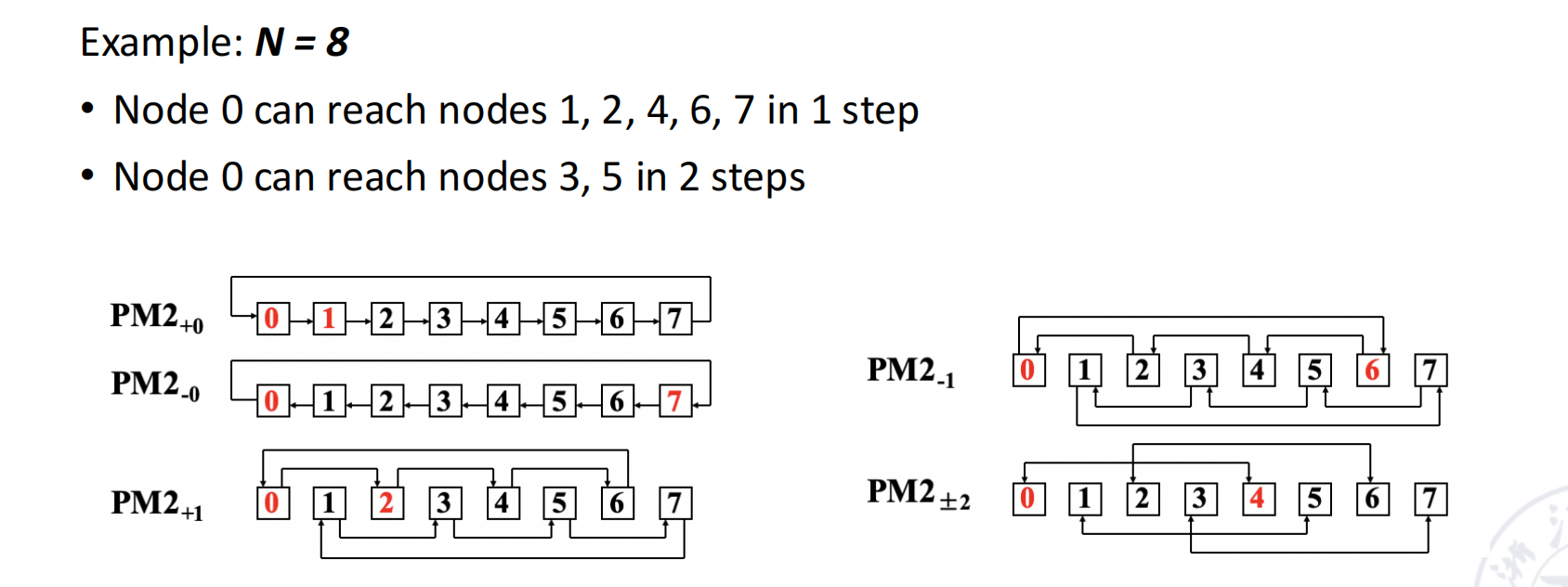
2. PM2I 网络 (Plus-Minus 2^i)
- 定义:节点 j 可以连接到 \((j + 2^i) \mod N\) 和 \((j - 2^i) \mod N\)。
- 应用:ILLIAC IV 阵列处理器使用PM2_±0 ( 左右邻居 ) 和PM2_±n/2 ( 上下邻居 ) 构成了其二维网格互连。
3. 混洗交换网络 (Shuffle-Exchange Network)
- 定义:由两种连接构成:
- 混洗 (Shuffle):将地址 P_{n-1}P_{n-2}...P_0 连接到 P_{n-2}...P_0P_{n-1}(循环左移一位Cube_0 连接,连接到最低位取反的地址。
- 特性:最大距离为 2n-1。
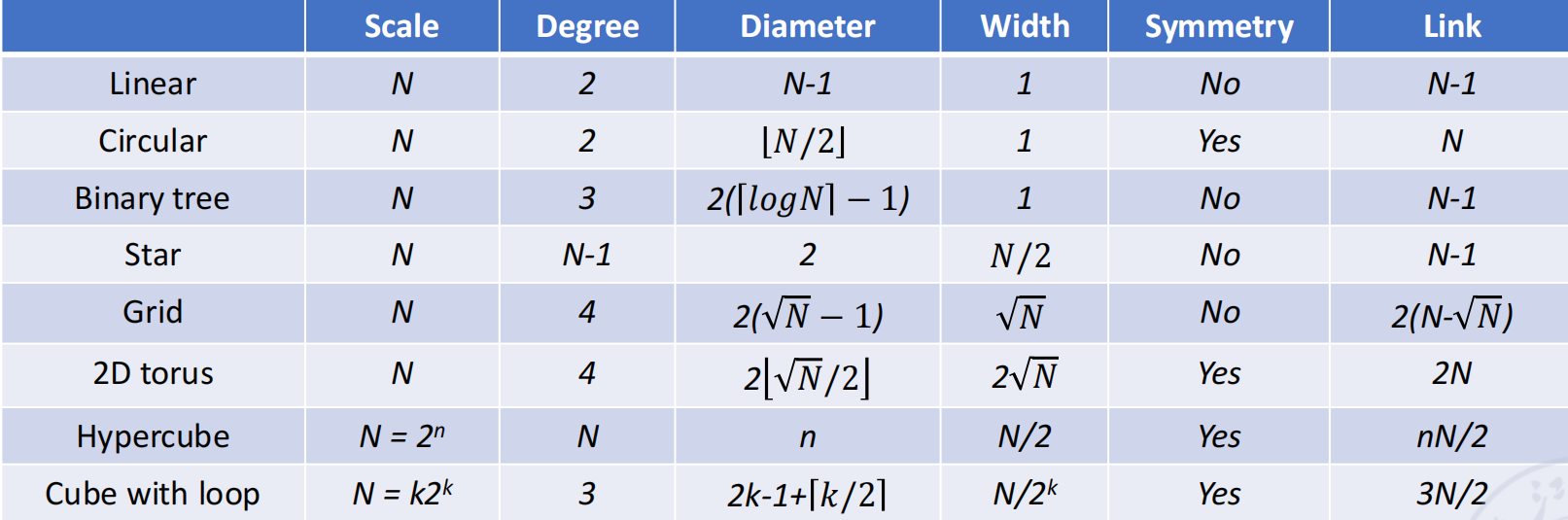
常见静态网络拓扑特性对比 (N 为节点数 )
动态互连网络 (page 96-128) ¶
动态网络的核心是可配置的交换单元,主要包括总线、交叉开关和多级互连网络。
- 总线 (Bus):所有设备共享一条通信链路。结构简单,但存在严重的争用问题,可扩展性差(通常 <=32 个处理器
) 。- 与线性阵列的区别:线性阵列的不同部分可以同时工作(没有冲突即可)
- 总线一次只能够为一对节点提供传输服务
- 与线性阵列的区别:线性阵列的不同部分可以同时工作(没有冲突即可)
- 交叉开关 (Crosspoint Switch):提供任意输入到任意输出的无阻塞连接。性能最好,但硬件成本极高(\(N*N\) 个交叉点开关
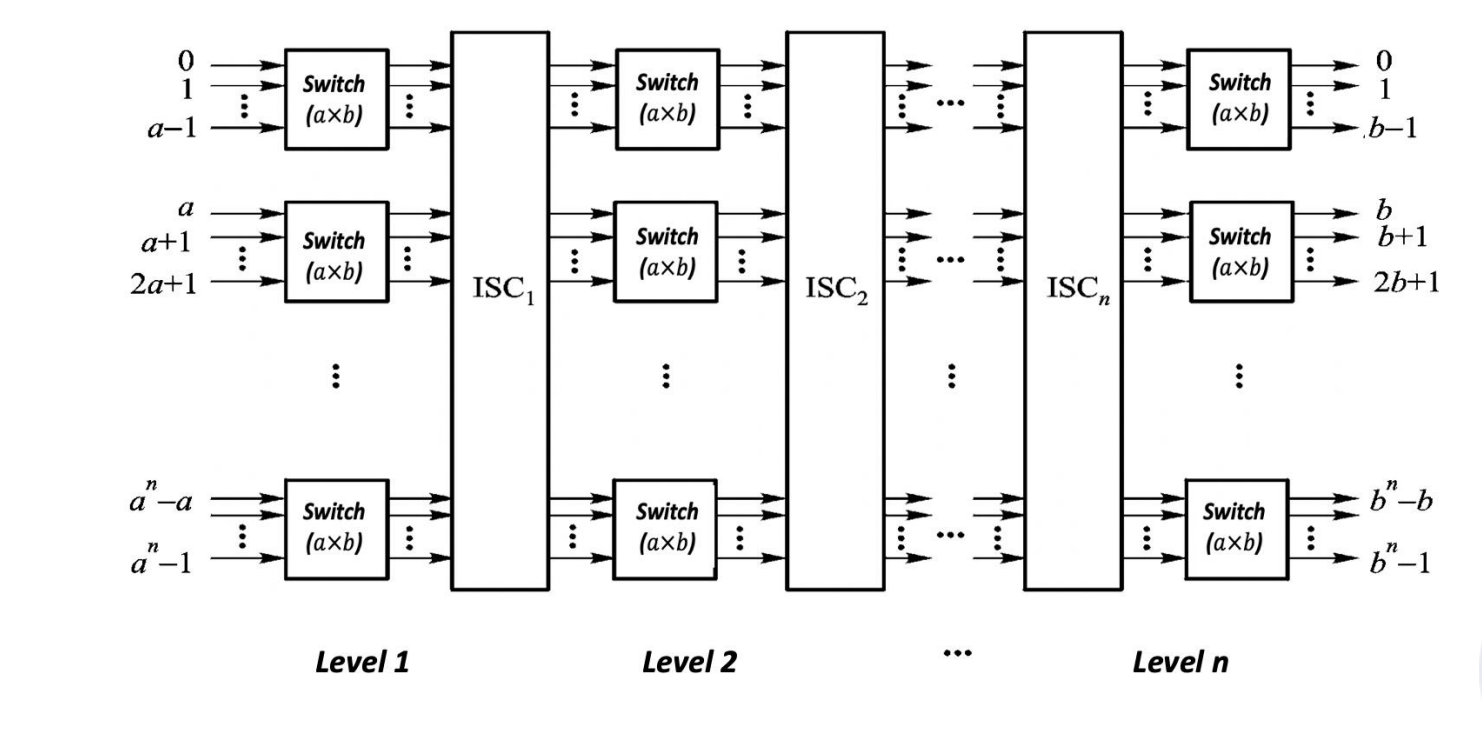
) ,复杂度为 \(O(N^2)\)。 - 多级互连网络 (Multi-stage Interconnection Network, MIN)
- 思想:用多个级别的、更小的交换单元(如 2x2 开关)来构建一个大型交换网络,是成本和性能之间的折衷。
- 基本组件:一个 2x2 交换单元可以有两种状态(直通、交换)或四种状态(增加上广播、下广播
) 。 - 常见拓扑:
- 多级立方体网络 (STARAN 网络 ):各级之间的连接遵循
Cube_i关系。 - 多级混洗交换网络 (Omega 网络 ):各级之间是混洗连接,交换单元是四功能的。
- 多级立方体网络 (STARAN 网络 ):各级之间的连接遵循
Omega 网络与 n-cube 网络的对比
- 数据流方向:Omega 网络的数据从 n-1 级流向 0 级,而 n-cube 网络从 0 级流向 n-1 级。如果忽略交换单元功能,Omega 网络是 n-cube 网络的逆网络。
- 交换单元功能:Omega 网络使用四功能交换单元(支持广播
) ,而 n-cube 网络使用二功能交换单元。 - 阻塞特性:两者都是阻塞网络 (Blocking Network)。例如,在 Omega 网络中,若要同时建立
5→0和7→1的连接,它们会在中间级的同一个交换单元(G)的同一个输出端口发生冲突,导致0→5和1→7的连接无法同时建立。全排列的非阻塞网络 (Non-blocking Network)(如 Benes 网络)通常需要更多级的交换。
图形处理器 (GPU) 作为 DLP 引擎 (page 130-137) ¶
GPU 是现代 SIMD 架构的杰出代表,它通过大规模并行处理单元来挖掘 DLP。
- 基本思想与编程模型:
- 异构执行模型 (Heterogeneous execution model):CPU 作为
host( 主机 ),负责控制逻辑;GPU 作为device( 设备 ),负责并行计算密集型任务。 - CUDA (Compute Unified Device Architecture):NVIDIA 推出的并行计算平台和编程模型。
- SIMT (Single Instruction, Multiple Thread):CUDA 的编程模型,是 SIMD 的一种演进。程序员编写单个线程的代码,GPU 硬件将成组的线程(称为 Warp,通常是 32 个线程)调度到 SIMD 执行单元上。
- 线程组织:线程 (Thread) -> 线程块 (Block) -> 网格 (Grid)。GPU 硬件负责线程管理。
- 异构执行模型 (Heterogeneous execution model):CPU 作为
- GPU 内存结构:
- 全局内存 (GPU memory):由所有 Grid 共享,访问速度慢。
- 共享内存 (Local memory):由一个 Block 内的所有线程共享,速度快,相当于程序员可控的 Cache。
- 私有内存 (Private memory):每个线程私有。
- GPU 架构与向量机对比:
- 相似点:都擅长处理 DLP 问题,都有类似掩码寄存器(用于处理分支)和大规模寄存器堆的机制。
- 不同点:
- GPU 没有标量处理器,所有计算都是并行的。
- GPU 使用多线程 (Multithreading) 来隐藏内存访问延迟,而向量机使用深度流水线。
- GPU 拥有大量简单的功能单元,而向量机拥有少量深度流水线化的复杂功能单元。
线程级并行 (TLP) 与 MIMD 架构 (page 2-38) ¶
当并行性存在于更高层次的、由数千到数百万条指令组成的独立“线程”之间时,我们称之为线程级并行(Thread-Level Parallelism, TLP
从 ILP 到 TLP 的转变 (page 3-6) ¶
- 动机:2004 年左右,由于功耗墙 (Power Wall) 和 登纳德缩放定律 (Dennard Scaling) 的失效,单纯依靠提高时钟频率和深化流水线来挖掘 ILP 的方式遇到了瓶颈,其收益递减。
- 转向:业界转向多核 (Multicore) 设计,将多个处理器核心集成到单个芯片上,通过 TLP 来继续提升性能。
行业观点
- " 我们正将所有未来的产品开发投入到多核设计中。我们相信这是行业的关键拐点。" - Intel 总裁 Paul Otellini, 2005
- " 自 2004 年以来,处理器设计者增加了核心数量以利用摩尔定律的扩展,而不是专注于单核性能。" - Hadi Esmaeilzadeh, et al., 2012
TLP 意味着程序中存在多个独立的执行流,每个流都有自己的程序计数器 (PC)。因此,开发 TLP 主要通过 MIMD (Multiple Instruction, Multiple Data) 架构来实现。
MIMD 架构分类 (page 8-34) ¶
MIMD 架构根据内存组织方式和通信机制可分为两大类:
- 多处理器系统 (Multi-processor System):基于共享内存 (Shared Memory)。
- 特征:所有处理器共享一个统一的地址空间。通信通过
LOAD和STORE指令隐式进行。 - 子分类 ( 按内存访问模型 ):
- UMA (Uniform Memory Access):所有处理器访问任何内存位置的延迟都是相同的。物理内存是集中式的,通常通过总线或交叉开关连接。也称为对称多处理器 (Symmetric Multiprocessors, SMP)。
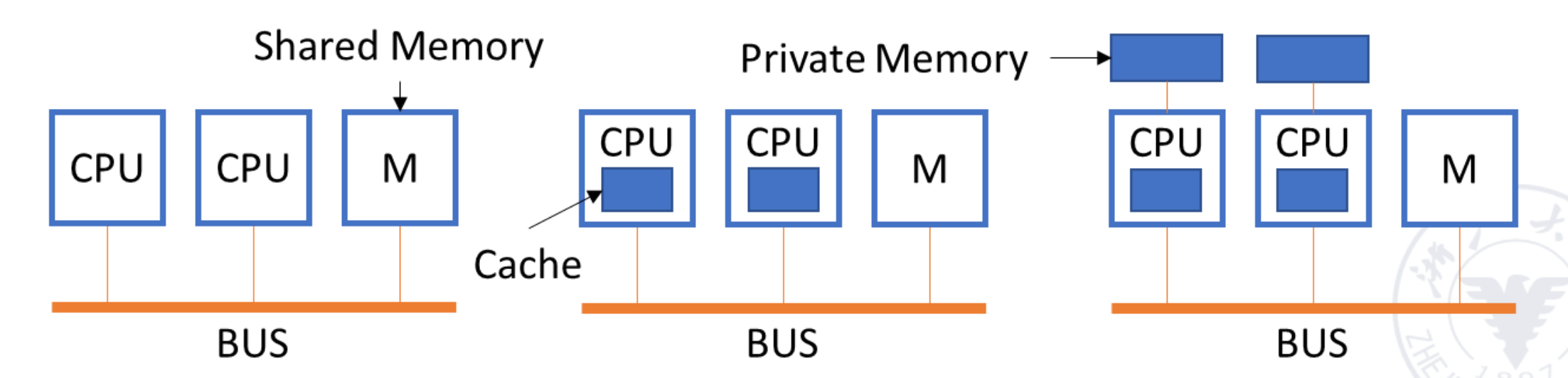
UMA
- UMA (Uniform Memory Access):所有处理器访问任何内存位置的延迟都是相同的。物理内存是集中式的,通常通过总线或交叉开关连接。也称为对称多处理器 (Symmetric Multiprocessors, SMP)。
- 特征:所有处理器共享一个统一的地址空间。通信通过
- NUMA (Non-Uniform Memory Access):物理内存是分布式的,每个处理器有自己的本地内存,但所有内存仍在同一个地址空间内。访问本地内存快,访问远程内存慢。也称为分布式共享内存 (Distributed Shared-Memory, DSM)。根据是否使用缓存一致性协议,又分为 NC-NUMA ( 无缓存 ) 和 CC-NUMA ( 有缓存一致性 )。
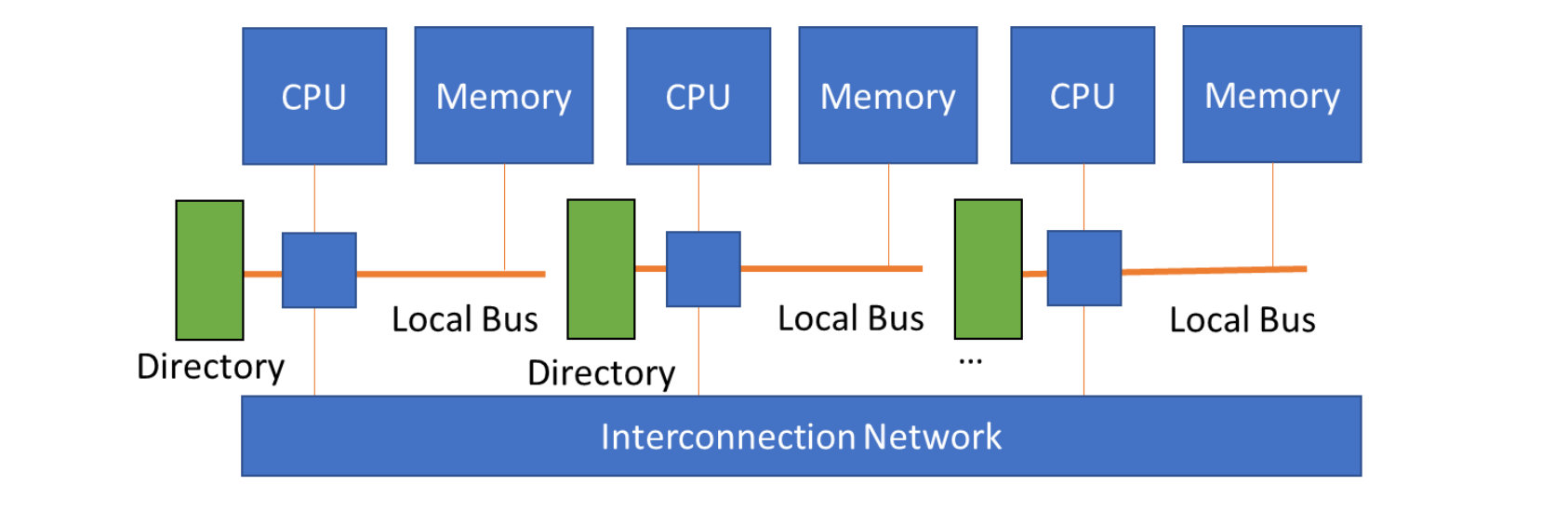
- COMA (Cache-Only Memory Access):NUMA 的一种特例,没有传统意义上的主存,所有分布式内存都作为缓存使用,数据会根据需要在运行时动态迁移到使用它的节点。
2. 多计算机系统 (Multi-computer System):基于消息传递 (Message Passing)。
- 特征:每个处理器拥有独立的私有内存(本地地址空间
并行处理的挑战 (page 35-38) ¶
开发 TLP 面临两大挑战,都可以用阿姆达尔定律 (Amdahl's Law) 来解释:
- 程序中有限的并行性:程序中总有一部分是无法并行的串行代码,这部分会成为性能提升的瓶颈。
- 高昂的通信成本:处理器间的数据同步和通信会带来额外的开销和延迟。
Amdahl 定律应用分析 (page 36-38)
问题 1:希望用 100 个处理器达到 80 倍的加速比。程序中允许的串行部分比例是多少?
公式: \(Speedup = \frac{1}{(1 - F_{parallel}) + \frac{F_{parallel}}{N}}\)
计算: \(80 = \frac{1}{(1 - F_{parallel}) + \frac{F_{parallel}}{100}}\) 解得 \(F_{parallel} \approx 0.9975\)
结论:串行部分只能占 1 - 0.9975 = 0.25%。这说明要达到高加速比,程序必须高度并行化。
问题 2:略 (page 37)
问题 3:在一个 32 核系统中,远程内存访问延迟为 100ns,处理器时钟为 4GHz ( 周期 0.25ns),基础 CPI 为 0.5。如果 0.2% 的指令涉及远程访存,那么与无通信的理想情况相比,性能下降了多少?
计算: - 远程访存成本:\(100ns / 0.25ns = 400\) 周期。 - 实际 CPI:\(CPI_{actual} = CPI_{base} + \mathrm{Remote\_freq} \times \mathrm{Remote\_cost} = 0.5 + 0.2\% \times 400 = 0.5 + 0.8 = 1.3\) - 性能比 ( 理想 / 实际 ):\(SP = \frac{\mathrm{Cycles}_{ideal}}{\mathrm{Cycles}_{actual}} = \frac{IC \times CPI_{base}}{IC \times CPI_{actual}} = \frac{0.5}{1.3} \approx 0.38\)
另一种理解是,无通信时的执行时间与有通信时的执行时间之比: \(\frac{\mathrm{Time\_with\_comm}}{\mathrm{Time\_no\_comm}} = \frac{CPI_{actual}}{CPI_{base}} = \frac{1.3}{0.5} = 2.6\)
结论:通信开销使得处理器速度慢了 2.6 倍。
多处理器系统中的存储一致性 (page 39-70) ¶
在共享内存多处理器系统中,缓存的引入带来了新的严峻挑战:缓存一致性 (Cache Coherence)。
缓存一致性 vs. 内存一致性 (page 41, 67) ¶
这两个概念密切相关但有所区别,是理解多处理器系统的关键。
缓存一致性与内存一致性
- 缓存一致性 (Cache Coherence):关注的是“一个内存地址的值”。它确保任何处理器对某个内存地址的读操作,总能得到最新写入的值,无论这个值是被哪个处理器写入的,也无论这个值存储在哪个缓存中。它保证了数据的“单一视图”。
-
核心要求:
- 写传播 (Write Propagation):一个处理器的写操作最终要对其他处理器可见。
- 事务串行化 (Transaction Serialization):所有处理器看到的对同一个内存位置的写操作顺序是一致的。
-
内存一致性 (Memory Consistency):关注的是“不同内存地址的操作顺序”。它定义了不同处理器对不同内存地址的读写操作,在其他处理器看来,其发生的顺序规则。例如,如果处理器 P1 先写 A 再写 B,内存一致性模型决定了其他处理器是否必须先看到 A 的新值,再看到 B 的新值。
关系:缓存一致性保证了单个存储单元的原子性,而内存一致性定义了跨不同存储单元的操作顺序。一个系统需要同时满足两者才能正确工作。
缓存一致性协议 (Cache Coherence Protocols) (page 43-66) [todo] ¶
- 迁移 (Migration) 和 复制 (Replication) 是缓存的两个基本优势,但也正因如此引发了一致性问题。当一个数据块被多个缓存复制后,其中一个副本被修改,就造成了数据不一致。
为解决缓存一致性问题,硬件实现了缓存一致性协议。主要有两类协议:
- 总线侦听协议 (Bus Snooping Protocol)
- 适用场景:基于总线的 UMA 系统。
- 工作原理:所有缓存控制器都“侦听”共享总线上的事务。当一个处理器要写入其缓存中的一个数据块时,它会通过总线广播一个消息。其他缓存控制器侦听到这个消息后,根据协议采取相应行动。
- 两种策略:
- 写使无效 (Write-Invalidate):广播一个“无效”消息,使其他缓存中该数据块的副本失效。这是最常用的策略。
- 写更新 (Write-Update/Broadcast):广播新的数据,更新其他缓存中的副本。这会消耗更多总线带宽。
- 基于目录协议 (Directory Based Protocol)
- 适用场景:基于互连网络的大规模 NUMA 系统。
- 工作原理:不依赖广播。系统维护一个“目录”(可以集中或分布式
) ,记录了每个内存块的状态以及它被哪些缓存所持有。当需要进行写操作时,控制器查询目录,只向持有该数据块副本的特定处理器发送点对点的无效或更新消息。 - 优势:避免了总线广播的瓶颈,具有更好的可扩展性。
深入写无效侦听协议 (MSI, MESI, MOESI) (page 51-65) ¶
写无效协议通过为每个缓存块维护一个状态来实现。
- MSI 协议:最基础的协议,包含三个状态。
- M (Modified):块已被当前处理器修改,与内存不一致。当前处理器是该块的唯一所有者。
- S (Shared):块是干净的(与内存一致
) ,可能在多个缓存中存在副本。 - I (Invalid):块的内容是无效的。
MSI 协议工作流程 (page 55-58)
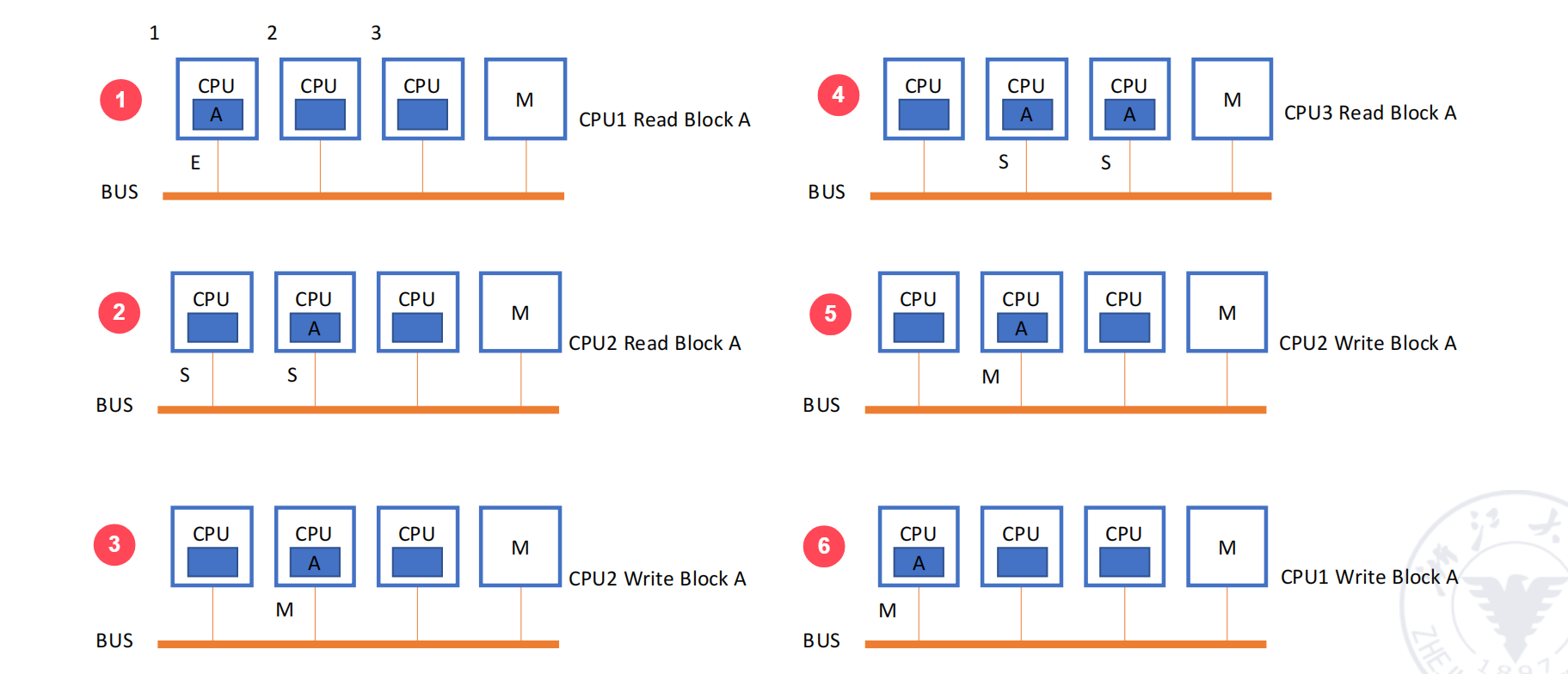
考虑三个处理器 C0, C1, C2 和内存地址 A104。初始时 C0, C1, C2 中都没有 A104。 1. C1 读 A104: C1 发生 Read Miss。它通过总线向内存请求数据。内存返回数据,C1 将其缓存块置为 S (Shared) 状态。 2. C0 读 A104: C0 发生 Read Miss。它也通过总线请求数据。内存返回数据,C0 将其缓存块置为 S (Shared) 状态。此时 C0 和 C1 都持有 A104 的共享副本。 3. C1 写 A104: C1 发生 Write Hit ( 因为本地有副本 )。它在总线上广播一个“写无效”请求。 - C0 侦听到该请求,将其 A104 的副本置为 I (Invalid) 状态。 - C1 将自己的副本状态从 S 更新为 M (Modified),并修改数据。现在 C1 独占了修改后的数据。 4. C2 读 A104: C2 发生 Read Miss,在总线发出读请求。 - C1 侦听到这个读请求,发现自己持有该块的 M 状态副本。它会中止 (abort) 内存的响应,自己将数据写回内存,然后将自己的状态从 M 变为 S,并将数据提供给 C2 和内存。 - C2 获得数据,将缓存块置为 S 状态。
- MESI 协议:MSI 的一个重要扩展,增加了 E (Exclusive) 状态,以优化“读 - 修改 - 写”序列。
- E (Exclusive):块是干净的(与内存一致
) ,且只存在于当前缓存中。 - 优势:当处理器要写入一个处于 E 状态的块时,它可以静默地 (silently) 将状态变为 M 并修改数据,无需在总线上广播无效消息。这减少了总线流量,提升了性能。
- 只有当一个处于 E 状态的块被其他处理器读取时,它才会变为 S 状态。
- E (Exclusive):块是干净的(与内存一致
- MOESI 协议:MESI 的进一步扩展,增加了 O (Owned) 状态。
- O (Owned):块已被修改(脏
) ,与内存不一致,但可能存在于其他缓存中(作为 S 状态的副本) 。持有 O 状态的缓存是“所有者”,负责在其他处理器请求时提供数据。 - 优势:允许将脏数据直接从一个缓存转发到另一个缓存,而无需先写回内存。这进一步减少了内存写回的延迟和带宽消耗。
- O (Owned):块已被修改(脏
内存一致性模型 (page 67-70) ¶
- 顺序一致性 (Sequential Consistency, SC):最强、最直观的模型。
- 要求:所有内存操作的执行结果,等同于所有处理器的操作以某种单一顺序交错执行的结果,且每个处理器内部的操作顺序保持不变。
- 缺点:过于严格,限制了许多硬件优化(如乱序执行、写缓冲
) ,导致性能下降。
- 松散一致性模型 (Relaxed Consistency Models):
- 核心思想:允许读写操作乱序完成,以获取更高性能,但提供同步操作 (Synchronization Operations)(如
acquire和release)来在必要时强制执行顺序。 - 类型:通过放宽 R→W, W→R, W→W, R→R 的顺序限制,派生出多种模型,如 Total Store Ordering (TSO), Partial Store Order (PSO), Weak Ordering, Release Consistency (RC) 等。程序员需要使用同步原语来确保程序的正确性。
- 核心思想:允许读写操作乱序完成,以获取更高性能,但提供同步操作 (Synchronization Operations)(如
特定领域架构 (DSA) (page 71-77) ¶
特定领域架构 (Domain-Specific Architectures, DSA)
DSA 是指为特定应用领域(如机器学习、图形处理)定制设计的计算机体系结构。与追求通用性的 CPU 不同,DSA 通过牺牲通用性来换取在特定任务上的极高性能和能效。
- 设计准则:
- 使用专用存储器,最小化数据搬运。
- 将资源更多地投入到算术单元或更大的存储器上。
- 使用与领域匹配的最简单的并行形式。
- 将数据大小和类型简化到领域所需的最低程度。
- 提供领域专用的编程语言或库。
- 示例:卷积神经网络
- 批次
- 量化
- 设定卷积核
- ……
案例:谷歌 TPU (Tensor Processing Unit) (page 74-77) ¶
TPU 是为深度神经网络(DNN)设计的典型 DSA。
- 核心设计:
- 大型矩阵乘法单元:其核心是一个
256x256的脉动阵列 (Systolic Array),可以在一个周期内执行 65536 次 8-bit 乘累加运算。 - 专用存储:拥有大容量的片上软件管理暂存器(Scratchpad
) ,如 24MiB 的统一缓冲和 4MiB 的累加器缓冲,以减少对主存的访问。 - 简化数据类型:主要使用 8-bit 整数进行量化计算,极大提升了能效。
- 简单并行:利用二维 SIMD 并行(脉动阵列
) 。 - 专用 ISA:指令集直接对应于神经网络操作,如
MatrixMatrixMultiply,Activate。 - 专用软件栈:通过 TensorFlow 框架进行编程。
- 大型矩阵乘法单元:其核心是一个
TPU 的设计完美体现了 DSA 的思想,通过对计算模式、数据类型和并行方式的特化,实现了远超通用 CPU 的性能和能效。
总结 (page 129; page 78) ¶
- SIMD 架构 通过向量处理器、阵列处理器和现代 GPU,高效地开发数据级并行,在科学计算和媒体处理等领域表现出色。其能效高于 MIMD,且允许程序员以一种更接近串行的方式思考。
- MIMD 架构 通过多核、多处理器系统来开发线程级并行,是应对后摩尔定律时代性能挑战的主流方式。它带来了复杂的内存系统设计问题。
- 存储一致性是多处理器系统设计的核心挑战,它被分解为缓存一致性和内存一致性两个层面。
- 缓存一致性协议确保数据值的统一,主要有适用于 UMA 的侦听协议(如 MSI, MESI)和适用于 NUMA 的目录协议。
- 内存一致性模型定义操作的顺序,从严格的顺序一致性到高性能的松散一致性模型。
- DSA 作为一种新的设计范式,通过为特定领域定制硬件,正成为未来体系结构发展的重要方向。