主存储器 ¶
计算机体系结构回顾 (page 3-4) ¶
计算机系统由几个核心组件构成,它们协同工作以执行程序。这些组件主要包括:
- 中央处理器 (CPU):执行指令的核心单元,内部包含:
- 算术逻辑单元 (ALU):执行算术和逻辑运算。
- 控制单元 (Control Unit):协调 CPU 内部各组件以及 CPU 与其他系统组件(如内存、I/O 设备)之间的操作。
- 寄存器 (Registers):高速存储单元,用于暂存指令、数据和地址。例如程序计数器 (Program Counter, PC) 存放下一条指令的地址,当前指令寄存器 (Current Instruction Register) 存放当前正在执行的指令。
- 模式位 (Mode):指示 CPU 当前处于内核模式还是用户模式。
- 主存储器 (Memory):存储程序指令和数据。CPU 可以直接访问主存和寄存器。
- 输入 / 输出系统 (I/O System):管理计算机与外部设备之间的通信。
在现代计算机体系结构中,为了提升性能,引入了诸多高级特性:
- 指令级并行 (Instruction-Level Parallelism, ILP):通过技术如动态分支预测,使得 CPU 能够同时处理多条指令。
- 内存层次结构 (Memory Hierarchy) 与缓存 (Cache):通过引入高速缓存(Cache)来缓解 CPU 与主存之间的速度差异,这是流水线 CPU 设计实现的关键部分。
核心问题是如何高效地使用内存?这涉及到操作系统和硬件的协同工作。
内存技术和管理层级 (page 5) ¶
计算机系统中的存储器按速度、容量和成本形成一个层次结构:
| 级别 | 名称 | 典型大小 | 实现技术 | 访问时间 (ns) | 带宽 (MB/sec) | 管理者 | 备份者 |
|---|---|---|---|---|---|---|---|
| 1 | 寄存器 | < 1 KB | 定制内存,多端口,CMOS | 0.25 – 0.5 | 20,000–100,000 | 编译器 | 缓存 |
| 2 | 缓存 | > 16 MB | 片上或片外 CMOS SRAM | 0.5 – 25 | 5,000–10,000 | 硬件 | 主存 |
| 3 | 主存 | > 16 GB | CMOS DRAM | 80 – 250 | 1,000–5,000 | 操作系统 | 磁盘 |
| 4 | 磁盘存储 | > 100 GB | 磁盘等 | 5,000,000 | 20 – 150 | 操作系统 | CD 或磁带 |
操作系统在内存管理中的角色
主存储器和磁盘存储通常由操作系统 (Operating System, OS) 管理。当处理像主存或磁盘这样相对“慢”的存储级别时,花费更多时间来做出“聪明”的决策(例如,复杂的分配算法、页面替换策略)是值得的。这解释了为什么操作系统在内存管理方面会执行复杂的操作,而硬件(如缓存控制器)则倾向于执行简单但快速的操作。
操作系统回顾:内存管理 (page 6) ¶
本章节将回顾操作系统在内存管理方面的一些基本策略和演进。
大纲 (page 7) ¶
- 内存分配的演进
- 如何移动进程
- 分区 (Partition)
- 内存分区 – 固定与可变
- 首次适应 (First fit)、最佳适应 (Best fit)、最差适应 (Worst fit)
- 碎片问题:内部碎片 (Internal Fragmentation) 与外部碎片 (External Fragmentation)
- 分段 (Segmentation)
- 逻辑地址 (Logical Address) vs 物理地址 (Physical Address)
- 内存管理单元 (MMU):地址转换 + 保护
背景知识 (page 8) ¶
- 程序必须从磁盘加载到内存中,并置于一个进程的上下文中才能运行。
- CPU 能直接访问的存储只有主存和寄存器。
- 内存单元仅看到一连串的地址和读 / 写请求:
- 地址 + 读请求
- 地址 + 数据和写请求
- 寄存器访问通常在一个 CPU 时钟周期内完成。
- 主存访问可能需要多个 CPU 时钟周期,导致 CPU 暂停 (stall)。
- 缓存 (Cache) 位于主存和 CPU 寄存器之间,用于缓解速度差异。
- 内存保护 (Protection) 是必需的,以确保进程正确运行,防止进程互相干扰。这可以通过硬件或软件机制实现。
内存的概念视图 (page 9) ¶
内存可以看作一个巨大的字节数组,每个字节都有一个唯一的地址。例如,地址 0000 0000 0000 0010 处可能存储着内容 0000 0000。
内存分配的早期演进 (page 10-11) ¶
批处理系统 (Batch systems) (page 10) ¶
在早期的批处理系统中:
- 同一时间只有一个程序加载到物理内存中。
- 程序会一直运行直到完成。
- 问题:如果作业(程序)大小超过物理内存怎么办?
- 解决方案:覆盖 (Overlays) / 分而治之 (Divide and conquer)
- 将程序划分为多个部分(覆盖段
) 。 - 只加载当前需要执行且能放入内存的部分。
- 当一个部分执行完毕后,加载下一个需要的部分到同一内存区域。
- 这类似于编译器中的趟 (passes)。程序员需要手动管理这些覆盖段。
- 将程序划分为多个部分(覆盖段
- 解决方案:覆盖 (Overlays) / 分而治之 (Divide and conquer)
多道程序设计 (Multi-programming) (page 11) ¶
为了提高 CPU 利用率,引入了多道程序设计:
- 物理内存中同时驻留多个进程。
- 允许 CPU 在某个进程等待 I/O 时快速切换到另一个就绪进程。
- 为了实现这一点,需要将物理内存分割成多个片段,即分区 (Partitioning)。
分区带来的需求:
- 保护 (Protection):必须防止进程破坏其他进程或操作系统内核的内存空间。
- 快速执行 (Fast execution):内存访问不应因保护机制而显著减慢。
- 快速上下文切换 (Fast context switch):设置地址映射不应花费过长时间。
物理内存与进程加载 (page 12-14) ¶
在简单的多道程序设计模型中,物理地址空间可能如下所示 (page 12):
- 操作系统内核 (OS Kernel) 占据一部分内存。
- 其余内存被划分为若干分区,用于加载用户进程(Process 1, Process 2, Process 3
) 。 - 可能存在空闲分区 (Empty)。
加载进程 (Loading a Process) (page 13):
- 最初,所有地址都需要在加载时进行重定位 (Relocate),以使其相对于分区在物理内存中的起始地址。
- 内存保护由操作系统分配和设置。进程被块对块地加载到物理内存。
- 一旦进程启动,其分区在内存中不能移动。
- 为什么? 因为程序内部的地址(例如,跳转指令的目标地址、数据指针)在加载时已经解析为绝对物理地址。如果移动了进程,这些地址就会失效,导致程序崩溃或错误。
示例场景 (page 14):
假设 Process 2 运行结束并释放了其内存分区,此时内存中出现了一个新的空闲块。
移动进程的挑战与逻辑地址的引入 (page 15-16) ¶
问题 (page 15): 如果一个新的进程 (Process 4) 到来,它需要的空间大于当前最大的单个空闲分区,会发生什么?
- 等待:Process 4 必须等待,直到有足够大的连续空闲空间。这可能导致饥饿 (Starvation)。
- 尝试移动现有进程:例如,移动 Process 3 到另一个空闲位置,以合并小的空闲分区形成一个足够大的分区。然而,如前所述,这很困难,因为进程内部的地址是物理地址。
解决方案:逻辑地址 (Logical Address) (page 16):
- 引入逻辑地址的概念,进程使用逻辑地址。
- 逻辑地址在运行时 (runtime) 被转换为物理地址。
- 逻辑地址可以被定义为进程在其分配的分区内的偏移量 (offset)。
- 例如:如果一个进程的分区从物理地址
0x14000开始,当程序(在其逻辑地址空间中)访问地址0x00346时,机器(通过某种机制)实际访问的是物理地址0x14000 + 0x00346 = 0x14346。
- 例如:如果一个进程的分区从物理地址
- 现在可以移动进程了吗? 是的。
- 如何移动? 当移动进程时,操作系统只需更新该进程分区新的物理起始地址(基地址
) 。由于进程内部使用的是逻辑地址,这些逻辑地址在运行时会与新的基地址相加,得到正确的物理地址。进程本身对这种移动是无感的。
- 如何移动? 当移动进程时,操作系统只需更新该进程分区新的物理起始地址(基地址
最简单的实现:基址寄存器和界限寄存器 (page 17-21) ¶
这是实现逻辑地址到物理地址转换和保护的一种简单硬件机制。
- 基址寄存器 (Base register):存储进程分区的起始物理地址。
- 界限寄存器 (Limit register):存储进程分区的大小(或结束地址的偏移量
) 。
工作方式 (page 17, 19):
- 地址转换:CPU 生成的每个逻辑地址都会加上基址寄存器的值,得到物理地址。这个基址寄存器也被称为重定位寄存器 (Relocation register)。
- 保护:CPU 生成的每个逻辑地址都会与界限寄存器的值进行比较。
- 如果逻辑地址
>=界限寄存器的值,则发生地址越界错误,CPU 会陷入 (trap) 到操作系统,产生寻址错误 (addressing error)。 - 否则,地址有效,继续进行转换。
- 如果逻辑地址
- 加载时机:基址寄存器和界限寄存器的值由操作系统在每次上下文切换 (Context Switch) 时加载。
- 为什么? 因为每个进程都有自己独立的逻辑地址空间和对应的物理分区,切换进程时必须更新这些寄存器以反映当前运行进程的内存布局。
硬件地址保护机制 (page 19):
- CPU 必须检查用户模式下生成的每一个内存访问,确保其逻辑地址在
0到limit-1之间。 - 加载基址和界限寄存器的指令是特权指令 (privileged instructions)。
- 为什么? 如果用户程序可以随意修改这两个寄存器,它们就能访问到内存的任何位置(包括其他进程或操作系统内核
) ,从而绕过内存保护机制,导致系统崩溃或安全问题。
- 为什么? 如果用户程序可以随意修改这两个寄存器,它们就能访问到内存的任何位置(包括其他进程或操作系统内核
优点 (page 20):
- 内置保护:由界限寄存器提供,无需为每个页面或块进行物理保护检查。
- 快速执行:地址加法和界限检查在硬件层面完成,速度快,通常在每条指令的执行周期内完成。
- 快速上下文切换:只需改变基址和界限寄存器的内容。
- 加载时无需重定位程序地址:所有逻辑地址都相对于 0 开始。
- 分区可随时挂起和移动:进程对这种变化无感知。只需更新基址寄存器。
移动进程示例 (page 21): 假设 Process 3 需要被移动,同时一个新的 Process 4 需要加载。
- 操作系统可以将 Process 3 的内容复制到一个新的空闲槽位。
- 然后更新 Process 3 的基址寄存器指向新的物理起始地址(界限寄存器不变,因为其大小没变
) 。 - Process 4 可以加载到因 Process 3 移动而产生的或其他合适的空闲分区,并为其设置相应的基址和界限寄存器。
关于基址和界限寄存器实现的说明
这种基址和界限寄存器的方案是最早也是最简单的动态重定位和保护机制之一。它将一个进程的整个逻辑地址空间映射到一个连续的物理内存块。虽然简单有效,但它要求整个进程必须连续存放,这可能导致后续讨论的外部碎片问题。
内存分配策略 (page 22) ¶
当内存中有多个空闲块时,操作系统需要决定为新进程分配哪个块。主要有两种分区策略:
- 固定分区 (Fixed partitions)
- 可变分区 (Variable partitions)
固定分区策略 (Fixed Partitioning Strategies) (page 23-24) ¶
- 内存被预先划分为若干个大小相等(或不等但固定)的分区(除了操作系统本身占用的区域外
) 。 - 多道程序的度 (Degree of multiprogramming) 取决于分区的数量。
- 策略简单:
- 所有进程必须能完全装入某个分区。
- 找到任何一个空闲分区,加载进程。
- 问题:内部碎片 (Internal Fragmentation) (page 23, 24)
- 当分配给进程的分区大于进程实际需要的内存时,分区内未被使用的内存就构成了内部碎片。
- 这部分未使用的内存无法被其他进程使用,造成浪费。
- 例如 (page 24),如果所有分区大小相同,一个较小的 Process 1 加载到一个分区后,该分区内剩余的空间就是内部碎片。
内部碎片 (Internal Fragmentation) (page 25)
分配给进程的内存块可能大于其请求的大小。这个大小差异就是分区内部的内存,但未被使用。为了避免或减少碎片,需要设计更复杂的算法。
- 问题
: “合适”的分区大小是多少? (page 23)- 如果分区太小,可能无法容纳大进程。
- 如果分区太大,小进程会导致大量内部碎片。
- 使用多种不同大小的固定分区可以在一定程度上缓解此问题,但管理更复杂。
可变分区策略 (Variable Partitioning Strategies) (page 26-28) ¶
- 内存根据进程的需求动态地划分分区。分区的数量和大小都是可变的。
- 管理更复杂:
- 需要数据结构来跟踪已用内存块和空闲内存块(称为孔 (hole)
) 。 - 当新进程到达时,从一个足够大的孔中为其分配内存。
- 需要数据结构来跟踪已用内存块和空闲内存块(称为孔 (hole)
- 问题:外部碎片 (External Fragmentation) (page 26)
- 随着进程的加载和释放,内存中会散布许多小的、不连续的空闲块。这些空闲块的总和可能足以满足某个进程的需求,但由于它们不连续,无法分配给该进程。这些无法利用的、位于已分配分区之间的空闲内存就是外部碎片。
可变分区的分配过程 (page 27): - 多分区分配:系统维护一个已分配分区和空闲分区(孔)的列表。 - 可变分区大小:分区大小根据进程需求确定,以提高效率。 - 孔 (Hole):可用的内存块。内存中会散布着各种大小的孔。 - 分配过程: 1. 当一个进程到达时,操作系统从一个足够大的孔中为它分配内存。分配后,孔的大小会减小,或者如果大小正好匹配,孔就消失。 2. 当一个进程退出时,它释放其占用的分区。如果释放的分区与一个或多个相邻的空闲分区(孔)接触,它们会合并成一个更大的孔。 - 操作系统维护关于已分配分区和空闲分区(孔)的信息。
空闲块分配算法 (Hole Fitting Algorithms) (page 28):
当需要为大小为 n 的请求从空闲内存块列表中分配空间时,有以下几种常见策略:
- 首次适应 (First-fit):从列表开头查找,分配第一个足够大的空闲块。速度快。
- 最佳适应 (Best-fit):遍历整个列表(除非列表按大小排序
) ,分配能容纳请求且大小最接近的(即最小的足够大的)空闲块。这会产生最小的剩余孔。 - 最差适应 (Worst-fit):遍历整个列表,分配最大的空闲块。这会产生最大的剩余孔,理论上可能为后续较大的请求留下空间,但实践中往往效果不佳,容易打碎大块内存。
算法性能
碎片化是所有这三种方法都面临的严重问题。模拟和实验表明,首次适应和最佳适应通常比最差适应性能更好,无论是在空间利用率还是执行时间方面。首次适应通常是最快的。
外部碎片示例 (page 29):
- 初始状态:OS, Process 1, Process 2, Process 3 依次排列。
- Process 2 终止:Process 2 占用的空间变成一个孔。
- Process 4 启动:如果 Process 4 需要的空间小于 Process 2 留下的孔,它会被分配到这个孔的一部分。此时,孔会变小,或者如果 Process 4 正好填满,孔消失。如果 Process 4 较大,可能无法放入。图中假设 Process 4 能够放入 Process 2 留下的孔中,但可能会留下更小的无法利用的碎片。
外部碎片 (External Fragmentation) (page 30)
指的是在已分配的内存块之间存在许多不连续的、未使用的内存空间。虽然这些空闲空间的总量可能大于某个新进程的请求,但由于它们不连续,请求无法得到满足。
解决方法:紧缩 (Compaction)
- 移动所有已分配的内存块,使它们在内存的一端连续排列,从而将所有小的空闲块合并成一个大的连续空闲块。
- 要求:程序在运行时必须是可重定位的 (relocatable),即它们的地址可以在运行时改变。这通常意味着使用逻辑地址和动态地址翻译机制(如基址 / 界限寄存器
) 。 - 缺点:紧缩操作非常耗时,会带来显著的性能开销,通常只在内存严重碎片化时才考虑执行。
分段 (Segmentation) (page 31) ¶
分段是一种内存管理方案,它更符合用户或程序员对程序的看法。
程序的用户视图 (page 32) ¶
用户通常不把程序看作一个单一的、线性的地址空间,而是看作一组逻辑单元的集合,例如:
- 主程序 (main program)
- 子例程 (subroutine) / 函数
- 栈 (stack)
- 符号表 (symbol table)
- 全局变量
- 等等 ...
这些逻辑单元称为段 (segments)。每个段都有其名称和长度。地址通过段名(或编号)和段内偏移量来指定。
问题 (page 32): 既然程序可以被看作多个逻辑段,我们能否拥有多组“基址和界限”寄存器,每个段一组?是的,这就是分段的基本思想。
ELF 二进制基础 (page 33) ¶
可执行和可链接格式 (Executable and Linkable Format, ELF) 是 Linux 和许多类 Unix 系统中标准的可执行文件、目标文件和共享库的格式。一个典型的 ELF 文件(如 a.out)包含:
- ELF 头 (ELF header):描述文件的整体信息。
- 程序头表 (Program header table):告诉系统如何创建进程映像。供链接器 (Linker) 和加载器 (Loader) 使用。
- 节头表 (Section header table):包含描述文件节区的信息。
- 常见的节区 (Sections) 包括:
.text: 代码 (code).rodata: 已初始化的只读数据 (initialized read-only data).data: 已初始化的数据 (initialized data).bss: 未初始化的数据 (uninitialized data),在程序加载时通常初始化为零。
这些节区天然地构成了程序的逻辑分段。
C 程序的内存布局 (page 34) ¶
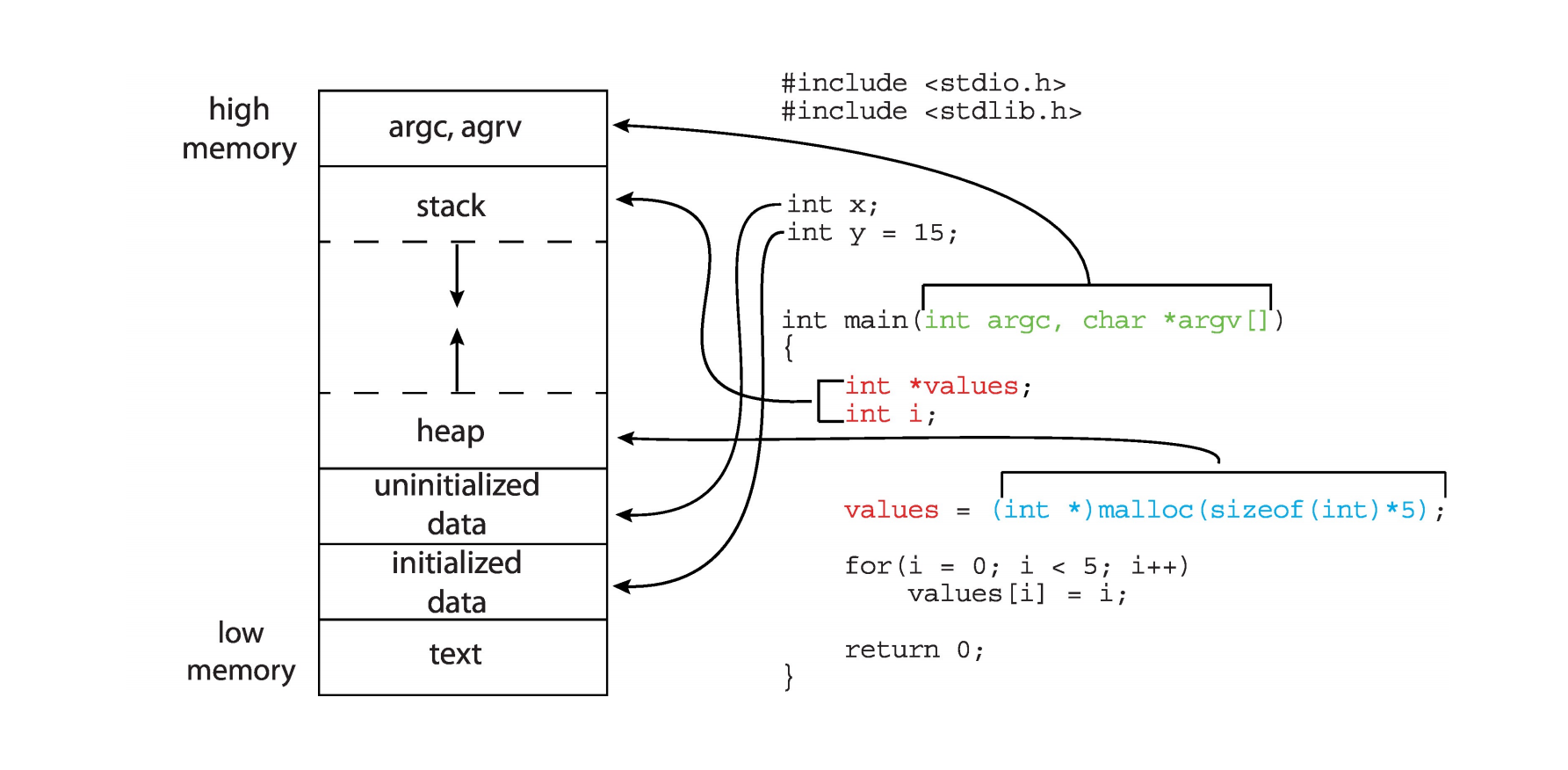
一个典型的 C 程序在运行时的内存布局可以划分为以下几个段:
- 文本段 (Text segment,.text ): 存放可执行指令,通常是只读的。位于低地址。
- 数据段 (Data segment):
- 已初始化数据段 (Initialized data,.data ): 存放已初始化的全局变量和静态变量。
- 未初始化数据段 (Uninitialized data,.bss ): 存放未初始化的全局变量和静态变量,在程序启动时由系统初始化为 0。
- 堆 (Heap): 动态分配的内存(例如,通过 malloc() 分配argc , argv ) 和环境变量通常位于栈的顶部。
这种布局反映了程序逻辑结构,分段机制可以很好地支持这种结构。
进程地址空间示例 (page 35-36) ¶
该页展示了一个 Linux 系统上 cat /proc/self/maps 命令的输出,它显示了当前进程的内存映射。每一行代表一个内存区域(VMA - Virtual Memory Area.text 段来自可执行文件 (/bin/cat)。
- .data 和 .bss 段也来自可执行文件。
- 堆 ([heap]) 用于动态内存分配。
- 共享库 (e.g., libc-2.27.so) 被映射到进程空间。
- 栈 ([stack])。
- 内核空间 ([vsyscall], [vvar], [vdso])。
这进一步说明了进程的地址空间在逻辑上是分段的。
分段的逻辑视图:
- 用户空间 (User space):进程看到的逻辑地址空间由多个独立的段组成(如图中的段 1, 2, 3, 4
) 。 - 物理内存空间 (Physical memory space):这些逻辑段被映射到物理内存中,它们在物理内存中不必是连续的。每个段可以被加载到物理内存的不同位置。图中段 1, 4, 2, 3 在物理内存中可能是分散存放的,并且它们之间可能有空隙。
分段机制的实现 (page 37) ¶
- 逻辑地址 由一个二元组构成:
<segment-number, offset>。segment-number( 段号 ):用于索引段表。offset( 段内偏移 ):指在段内的地址偏移量。
- 段表 (Segment table):每个进程都有一个段表。段表中的每个条目(段描述符)对应一个段,并包含:
- 基址 (Base):该段在物理内存中的起始地址。
- 界限 (Limit):该段的长度。
- 其他信息:如访问权限(读 / 写 / 执行
) 、特权级等。
分段查找 / 地址转换过程 (page 38) ¶
当 CPU 生成一个逻辑地址 <segment-number, offset> 时:
- 索引段表:使用
segment-number作为索引,在进程的段表中查找对应的条目。这个段表本身通常存放在内存中,段表基址寄存器 (Segment Table Base Register, STBR) 指向段表的起始位置。 - 检查偏移量:从段表条目中取出该段的界限 (Limit)。
- 比较
offset与Limit。 - 如果
offset >= Limit,则发生寻址越界错误,触发保护性陷阱 (protection fault)。
- 比较
- 计算物理地址:如果偏移量有效(
offset < Limit) ,则从段表条目中取出该段的基址 (Base)。- 物理地址 =
Base + offset。
- 物理地址 =
- 访问内存:使用计算出的物理地址访问主存。
- 段表条目中通常还包含权限位 (R/W/X - Read/Write/Execute),用于检查访问是否合法(例如,不能写入只读段
) 。如果权限检查失败,也会触发保护性陷阱。
- 段表条目中通常还包含权限位 (R/W/X - Read/Write/Execute),用于检查访问是否合法(例如,不能写入只读段
MMU 在分段中的角色 (page 50)
上述分段地址转换和保护检查的过程是由内存管理单元 (Memory-Management Unit, MMU) 硬件执行的。逻辑地址中的段号和偏移量输入 MMU,MMU 查询段表(可能通过缓存的段描述符
分段的特点和问题 (page 39) ¶
- 早期小型计算机的常用技术:
- 需要少量额外的硬件(段表寄存器,比较器,加法器
) 。 - 在 Unix 等系统中得到有效使用。
- 需要少量额外的硬件(段表寄存器,比较器,加法器
-
优点延续至今:分段的思想在现代硬件和操作系统中仍然存在并得到支持。
- x86 架构支持分段。
- Linux 在某种程度上也支持或利用了分段(尽管现代 Linux 主要依赖分页
) 。
-
是否仍然存在外部碎片问题? 是的。
- 虽然段的大小是可变的,并且可以根据逻辑单元的实际大小来定义,但当段被加载到物理内存和从物理内存中移除时,物理内存中仍可能产生大小不一的空闲块(孔
) 。这些孔可能太小而无法容纳任何新的段,从而导致外部碎片。
- 虽然段的大小是可变的,并且可以根据逻辑单元的实际大小来定义,但当段被加载到物理内存和从物理内存中移除时,物理内存中仍可能产生大小不一的空闲块(孔
- 如何进一步改进? 可以通过紧缩来解决,但代价高昂。更好的方法是将分段与分页结合,或者主要使用分页。
地址绑定 (Address Binding) (page 40-41) ¶
程序中的地址在从源代码到最终执行的不同阶段有不同的表示形式。将这些不同形式的地址关联起来的过程称为地址绑定。
- 源代码 (Source code):地址通常是符号地址 (symbolic addresses),例如变量名、函数名。
- 编译器 (Compiler):将符号地址绑定到可重定位地址 (relocatable addresses)。
- 例如
, “从本模块开始的第 14 个字节处”。这些地址是相对于模块起始位置的偏移。
- 例如
- 链接器 (Linker) 或加载器 (Loader):将可重定位地址绑定到绝对地址 (absolute addresses)(或物理地址,在没有 MMU 的简单系统中
) 。- 例如,物理地址
0x0E74014。
- 例如,物理地址
- 每个绑定步骤都将一个地址空间映射到另一个地址空间。
指令和数据到内存地址的绑定时机 (page 41):
- 编译时 (Compile time):
- 如果内存位置是先验已知的(例如,嵌入式系统中的固定地址
) ,可以生成绝对代码 (absolute code)。 - 如果起始位置改变,必须重新编译代码。
- 如果内存位置是先验已知的(例如,嵌入式系统中的固定地址
- 加载时 (Load time):
- 如果编译时内存位置未知,则必须生成可重定位代码 (relocatable code)。
- 加载器在将程序加载到内存时,会将可重定位地址转换为最终的物理地址。一旦加载,进程不能在内存中移动。
- 执行时 (Execution time / Run time):
- 如果进程在执行期间可能从一个内存段移动到另一个内存段,则地址绑定必须延迟到运行时进行。
- 这需要硬件支持进行地址映射(例如,基址和界限寄存器、段表、页表等 MMU 功能
) 。这是最灵活的方式,允许动态内存分配和进程重定位。
(page 42) 展示了一个用户程序的处理流程,以及地址绑定在不同阶段发生的情况。
逻辑地址与物理地址 (page 43-44) ¶
逻辑地址 vs. 物理地址 (page 43)
The concept of a logical address space that is bound to a separate physical address space is central to proper memory management
- 逻辑地址 (Logical address):由 CPU 生成的地址,也称为虚拟地址 (virtual address)。进程使用逻辑地址来引用内存。
-
物理地址 (Physical address):内存单元(实际的 RAM 芯片)看到的地址,即加载到内存地址寄存器 (Memory Address Register, MAR) 中的地址。
-
逻辑地址空间 (Logical address space):一个程序生成的所有逻辑地址的集合。
- 物理地址空间 (Physical address space):一个程序可以访问的所有物理地址的集合。
将逻辑地址空间绑定到分离的物理地址空间的概念是现代内存管理的基础。
回顾地址转换机制 (page 44, 49):
- CPU 生成逻辑地址。
- 逻辑地址与界限寄存器中的值比较。如果逻辑地址大于或等于界限值,则产生陷阱。
- 如果有效,逻辑地址与重定位寄存器(基址寄存器)中的值相加,得到物理地址。
- 该物理地址用于访问内存。
内存管理单元 (MMU) (page 46-48) ¶
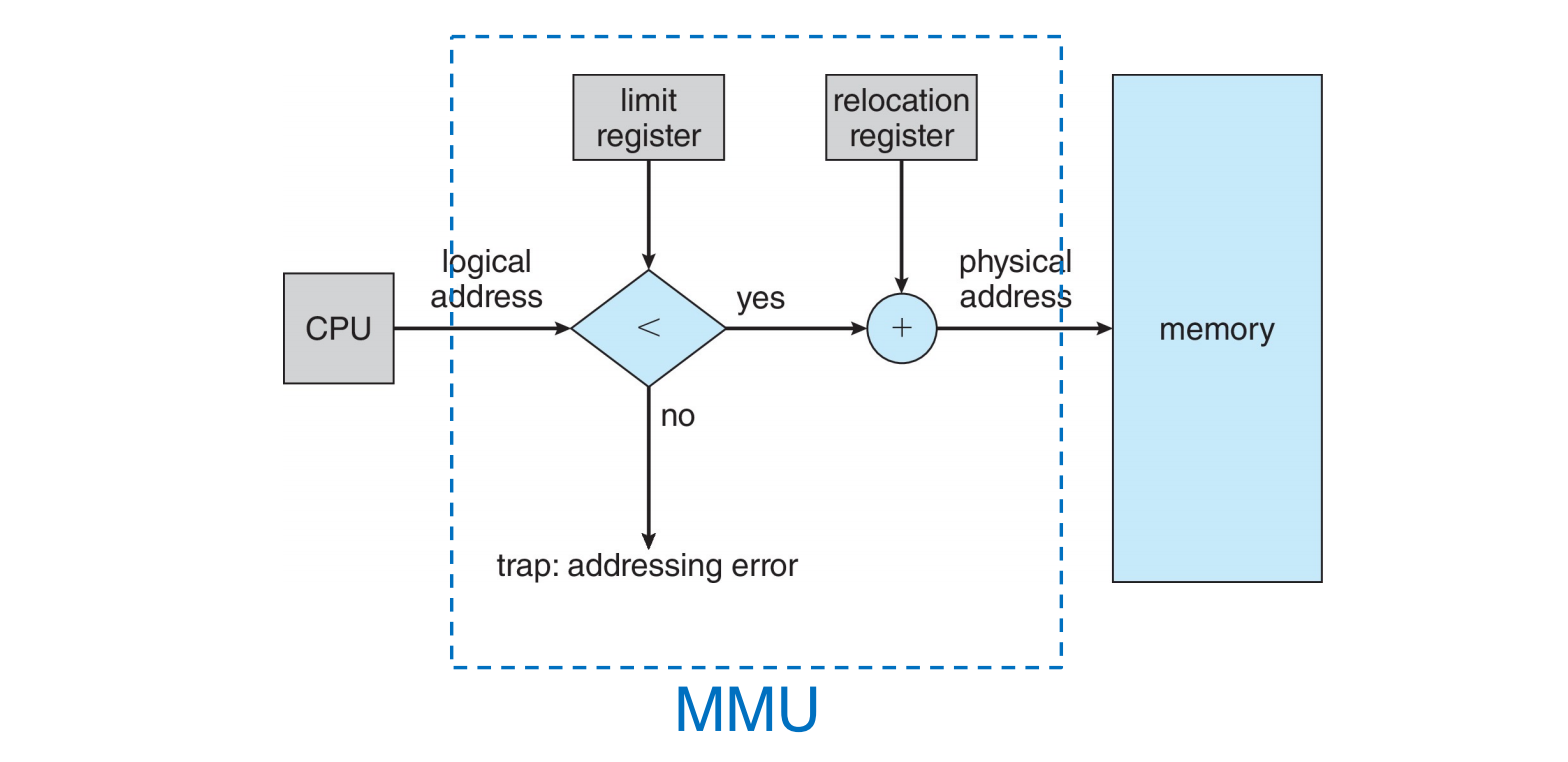
内存管理单元 (MMU) (page 46)
MMU (Memory-Management Unit) 是一种硬件设备,它在运行时将逻辑地址映射到物理地址。 - CPU 使用逻辑地址。 - 内存单元(主存硬件)使用物理地址。 - MMU 就像一个翻译器,将 CPU 使用的“语言”(逻辑地址)翻译成内存硬件使用的“语言”(物理地址)。
简单 MMU 方案 ( 基于重定位寄存器 ) (page 47-48): 这可以看作是基址寄存器方案的一般化。
- 基址寄存器现在被称为重定位寄存器 (relocation register)。
- 重定位寄存器中的值会加到用户进程生成的每个地址上,这个过程发生在地址发送到内存之前。
- 用户程序只处理逻辑地址,从不看到真实的物理地址。
- 执行时绑定 (Execution-time binding) 发生在对内存位置进行引用时。
- 逻辑地址被绑定到分离的物理地址。
- 例如 (page 48),如果重定位寄存器的值为
14000,逻辑地址范围为0到max。- 当 CPU 生成逻辑地址
346时,MMU 将其转换为物理地址14000 + 346 = 14346。 - 逻辑地址
0映射到物理地址R( 重定位寄存器的值 )。 - 逻辑地址
max映射到物理地址R + max。
- 当 CPU 生成逻辑地址
本章回顾总结 (page 51) ¶
- 分区演进: 从单道批处理到多道程序设计,引入了内存分区的概念。
- 内存分区 – 固定与可变:
- 固定分区简单但导致内部碎片。
- 可变分区灵活但导致外部碎片,需要首次适应、最佳适应、最差适应等分配算法。
- 碎片: 内部碎片(分区内浪费)和外部碎片(分区间浪费
) 。 - 分段:
- 提供与程序逻辑结构相符的内存视图。
- 逻辑地址是
<段号, 偏移量>。 - 使用段表进行地址转换和保护。
- 仍可能存在外部碎片。
- 逻辑地址 vs 物理地址: CPU 生成逻辑地址,MMU 将其转换为物理地址。
- MMU: 执行地址转换和保护的硬件。
分页 (Paging) (page 1) ¶
分页是另一种重要的内存管理方案,它允许进程的物理地址空间是非连续的,从而有效解决外部碎片问题,并简化内存管理。
分页的基本思想 (page 2) ¶
从 连续 (Contiguous) 分配到 非连续 (Noncontiguous) 分配。
- 进程的物理地址空间可以是非连续的。当物理内存可用时,就可以分配给进程,而不需要这些物理内存块是相邻的。
- 回顾:固定分区和可变分区(包括分段)都属于物理连续分配策略(每个段或分区本身在物理内存中是连续的
例如,在 (page 2) 的图中,Process 4 的内存需求被分成了三个小块,这些小块可以被放置到物理内存中任意三个空闲的位置,而不需要这三个位置是连续的。
分页的基本方法 (page 3) ¶
- 物理内存划分:将物理内存划分为固定大小的块,称为帧 (frames)。
- 帧的大小通常是 2 的幂,例如 4KB、8KB。
- 逻辑内存划分:将逻辑地址空间(进程的视角)也划分为相同大小的块,称为页 (pages)。
- 空闲帧跟踪:操作系统需要跟踪所有空闲的物理帧。
- 程序加载:要运行一个大小为
N个页的程序,操作系统需要找到N个空闲的物理帧,并将程序的N个页加载到这些帧中。这些帧在物理内存中不必是连续的。 - 地址转换:建立一种映射机制,将逻辑地址(由页号和页内偏移组成)转换为物理地址(由帧号和帧内偏移组成
) 。- 这种映射信息存储在页表 (page table) 中。
分页与内部碎片 (page 4) ¶
- 分页没有外部碎片问题,因为任何空闲帧都可以分配。
- 但是,分页仍然存在内部碎片问题。
- 例如:页 / 帧大小为 2,048 字节,程序大小为 72,766 字节。
- 程序需要
72,766 / 2,048 = 35个完整的页,还剩下1,086字节。 - 这
1,086字节需要占用第 36 个页(和对应的帧) 。 - 该帧中剩余的
2,048 - 1,086 = 962字节就是内部碎片。
- 程序需要
- 最坏情况下的内部碎片:一个程序只比
N个页大 1 个字节,它就需要N+1个帧,最后一个帧几乎完全是内部碎片((1 个帧大小 - 1 字节 ) 的浪费) 。 - 平均内部碎片:理论上大约是每个进程 1/2 个帧的大小。
- 实际上,由于程序通常包含多个页,只有最后一个页才可能产生内部碎片,所以平均内部碎片通常远小于 1/2 帧大小 * 进程数。
- 例如:页 / 帧大小为 2,048 字节,程序大小为 72,766 字节。
帧大小的选择:
| Aspect ( 衡量维度 ) | Small Page/Frame | Large Page/Frame |
|---|---|---|
| 内部碎片 (Internal Fragmentation) | 较少 | 较多 |
| 页表大小 (Page Table Size) | 更大 (more PTEs) | 更小 (less PTEs) |
| TLB 性能 (TLB Performance) | 未命中率可能更高 | 未命中率可能更低 |
| I/O 开销 (I/O Overhead) | 单次传输数据量小 | 单次传输数据量大 |
- 常用页大小:通常是 4KB。现代系统(特别是 64 位)也支持更大的页大小,如 64KB、2MB(称为大页 /Huge Page)或 1GB(称为巨页 /Giga Page
) ,以减少 TLB 压力和页表开销。
页表 (Page Table) 与帧表 (Frame Table) (page 5) ¶
页表 (Page Table)
页表存储逻辑页到物理帧的映射关系。每个进程通常都有自己的页表。
帧表 (Frame Table)
操作系统管理物理内存,因此需要了解物理内存(即所有帧)的分配细节(哪些帧空闲?已经分配多少帧了
- 帧表为每个物理帧设有一个条目。
- 条目内容包括:该帧是否空闲,如果已分配,它属于哪个进程的哪个页。
分页示例 ( 分配前与分配后 )
(page 6) 图演示了当一个新进程(包含 page 0, 1, 2, 3)需要加载时的分配过程:
- 分配前 (Before allocation):
- 有一个空闲帧列表 (free-frame list),例如包含物理帧 14, 13, 18, 20, 15。
- 物理内存中,某些帧可能已被其他进程占用。
- 分配后 (After allocation):
- 新进程的 4 个页被加载到从空闲帧列表中选取的 4 个帧中。例如:
- Page 0 -> Frame 14
- Page 1 -> Frame 13
- Page 2 -> Frame 18
- Page 3 -> Frame 20
- 这些帧从空闲帧列表中移除。
- 为新进程创建一个页表 (new-process page table),记录这些映射关系:
- 逻辑页号 0 对应物理帧号 14 ( 假设
0 -> 14) - 逻辑页号 1 对应物理帧号 13 ( 假设
1 -> 13) - 逻辑页号 2 对应物理帧号 18 ( 假设
2 -> 18) - 逻辑页号 3 对应物理帧号 20 ( 假设
3 -> 20)
- 逻辑页号 0 对应物理帧号 14 ( 假设
- 空闲帧列表更新(例如,现在只剩 Frame 15
) 。
- 新进程的 4 个页被加载到从空闲帧列表中选取的 4 个帧中。例如:
分页:地址转换 (page 7) ¶
逻辑地址在分页机制中被划分为两部分:
- 页号 (Page number, p):
- 用作页表的索引,以查找到对应的物理帧号。
- 页表项 (PTE) 包含了对应的物理帧号 (frame number, f)。
- 页内偏移 (Page offset, d):
- 指在页 / 帧内的偏移量。这个偏移量在逻辑地址和物理地址中是相同的。
- 与从页表查找到的帧号组合起来,形成最终的物理地址。
地址结构:
如果逻辑地址空间大小为 \(2^m\) ( 即 \(m\) 位逻辑地址 ),页大小为 \(2^n\) 字节 ( 即 \(n\) 位页内偏移 ):
- 页号 p 的位数为 m - n 位。
- 页内偏移 d 的位数为 n 位。
| 页号 (p) | 页内偏移 (d) |
|---|---|
m - n bits |
n bits |
物理地址的结构类似,由 帧号 (f) 和 帧内偏移 (d) 组成。偏移 d 不变。
分页硬件 (MMU 实现 ) (page 8-10, 18) ¶
下图展示了分页地址转换的基本硬件流程,这是 MMU 的功能:
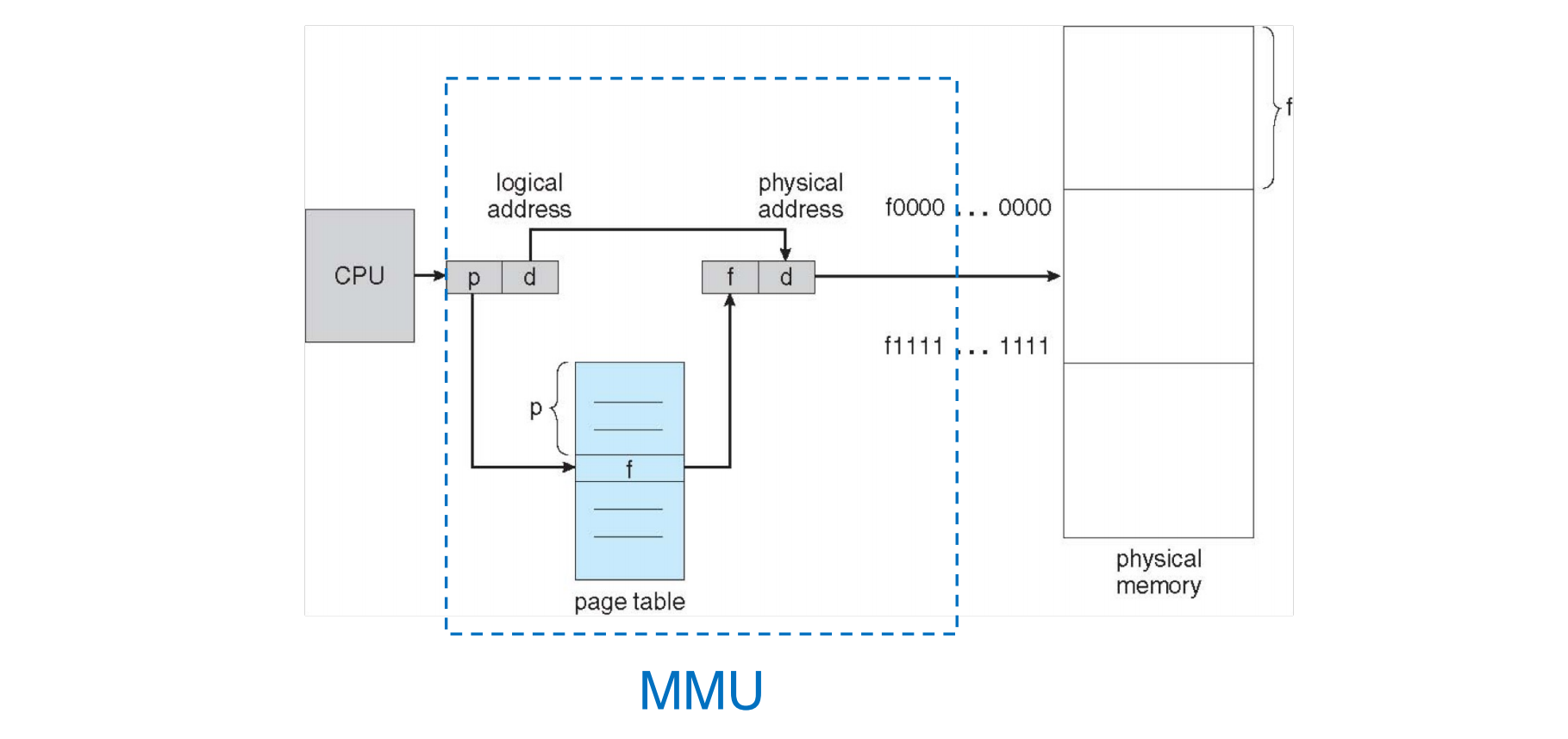
- CPU 生成逻辑地址。
- MMU 将逻辑地址拆分为页号
p和页内偏移d。 - MMU 使用页号
p作为索引访问(当前进程的)页表,获取对应的物理帧号f。页表通常存储在主存中。 - MMU 将帧号
f与页内偏移d组合形成物理地址。 - MMU 将此物理地址发送到物理内存。
分页示例 (page 9-10)
此图更具体地展示了一个例子:
- 逻辑内存:包含 Page 0, Page 1, Page 2, Page 3。
- 页表:
- 逻辑页 0 -> 物理帧 1
- 逻辑页 1 -> 物理帧 4
- 逻辑页 2 -> 物理帧 3
- 逻辑页 3 -> 物理帧 7
- 物理内存:
- 帧 0: ( 可能空闲或被其他进程使用 )
- 帧 1: 存放 Page 0
- 帧 2: ( 空闲 / 其他 )
- 帧 3: 存放 Page 2
- 帧 4: 存放 Page 1
- 帧 5: ( 空闲 / 其他 )
- 帧 6: ( 空闲 / 其他 )
- 帧 7: 存放 Page 3
这清晰地显示了逻辑上连续的页在物理上可以存储在不连续的帧中。
页表硬件支持 (page 11-12) ¶
最简单情况:页表在专用寄存器中 (page 11) ¶
- 页表完全存放在一组高速的专用硬件寄存器中。
- 优点:非常高效,访问寄存器速度极快。
- 缺点:
- 寄存器数量有限,导致页表大小非常受限,只能支持很小的逻辑地址空间或很少的页。
- 上下文切换时,需要保存和恢复所有这些寄存器,开销大。
- 不适用于现代通用操作系统。
替代方案:页表在主存中 (page 12) ¶
- 一个大的页表,将逻辑地址映射到物理地址。
- 页表应保存在主内存 (main memory) 中。
- 页表基址寄存器 (Page-Table Base Register, PTBR):指向当前进程页表的起始地址。
- PTBR 通常包含页表的物理地址。操作系统在调度一个进程运行时,会将该进程页表的物理起始地址加载到 PTBR 中。
- 页表长度寄存器 (Page-Table Length Register, PTLR):指示页表的大小(条目数
) 。用于防止逻辑地址的页号超出页表范围。
性能问题:
- 由于页表在主存中,每次数据 / 指令访问理论上需要两次内存访问:
- 第一次访问主存,根据 PTBR 和页号
p查阅页表,获取帧号f。 - 第二次访问主存,根据计算出的物理地址 (
f和d) 获取实际的数据 / 指令。
- 第一次访问主存,根据 PTBR 和页号
- 这会使内存访问速度减半,是不可接受的。如何减少页表导致的内存访问开销?
- 转换检测缓冲区 (Translation Look-aside Buffer, TLB):CPU 可以缓存最近用过的地址转换结果(逻辑页号 -> 物理帧号的映射
) ,以避免对主存中页表的访问。
- 转换检测缓冲区 (Translation Look-aside Buffer, TLB):CPU 可以缓存最近用过的地址转换结果(逻辑页号 -> 物理帧号的映射
转换检测缓冲区 (Translation Look-aside Buffer, TLB) (page 13-19) ¶
TLB (Translation Look-aside Buffer) (page 13)
TLB 是一种特殊的、小型的、快速查找的硬件缓存,用于缓存页表中的条目(即地址转换结果:逻辑页号到物理帧号的映射
TLB 工作流程: 当 MMU 需要翻译一个逻辑地址时:
- 首先并行地在 TLB 中查找逻辑页号
p。 - TLB 命中 (TLB Hit):如果页号
p在 TLB 中找到:- 直接从 TLB 中获取对应的物理帧号
f。 - 无需访问主存中的页表。
- 用
f和偏移d形成物理地址。
- 直接从 TLB 中获取对应的物理帧号
- TLB 未命中 (TLB Miss):如果页号
p不在 TLB 中:- MMU 必须访问主存中的页表(使用 PTBR 和
p)来获取帧号f。 (这可能由硬件自动完成,或在某些 RISC 架构如 MIPS 中,由操作系统陷阱处理程序完成) 。 - 获取到
f后,用f和d形成物理地址。 - 同时,这个新的 ( 逻辑页号 , 物理帧号 ) 映射关系会被加载到 TLB 中。如果 TLB 已满,需要根据某种替换策略(如 LRU - Least Recently Used)替换掉一个现有条目。
- MMU 必须访问主存中的页表(使用 PTBR 和
- TLB 大小:TLB 通常很小,例如 64 到 1024 个条目,因为相联存储器昂贵。
相联存储器 (Associative Memory) (page 15)
相联存储器是一种支持并行搜索的内存。它不是通过地址来访问,而是通过内容来访问。在 TLB 的上下文中: - 将逻辑页号作为键 (key) 同时与 TLB 中所有条目的键部分进行比较。 - 如果找到匹配的键(即逻辑页号存在于 TLB 中),则返回对应的值(即物理帧号)。
TLB 与上下文切换 (page 14) ¶
- 每个进程都有其独立的页表,因此有其独立的逻辑到物理地址映射。
- 当操作系统进行上下文切换,从一个进程切换到另一个进程时:
- 需要切换页表(即更新 PTBR 指向新进程的页表
) 。 - TLB 必须与当前页表保持一致。
- 需要切换页表(即更新 PTBR 指向新进程的页表
- 处理 TLB 一致性的选项:
- 清空 TLB (Flush TLB):在每次上下文切换时,清空整个 TLB。简单,但代价高,因为新进程开始运行时 TLB 是空的,会导致大量 TLB 未命中,直到 TLB 被“预热”。
- 标记 TLB 条目 (Tag TLB entries):为 TLB 中的每个条目增加一个地址空间标识符 (Address-Space Identifier, ASID) 或进程 ID (PID)。ASID 唯一标识一个进程。
- 在 TLB 查找时,不仅要匹配逻辑页号,还要匹配当前进程的 ASID 与 TLB 条目中的 ASID。
- 这样,不同进程的转换结果可以共存于 TLB 中,上下文切换时无需清空 TLB。
- 共享 TLB 条目:某些 TLB 条目可以被多个进程共享(例如,内核代码的映射
) ,这些条目可以被标记为全局 (global) 或固定在 TLB 中。 - TLB 与操作系统:
- MIPS 架构: TLB 未命中会产生一个异常,由操作系统负责处理(即软件管理的 TLB
) 。操作系统在异常处理程序中查找页表,并将结果填入 TLB。 - x86 架构: TLB 未命中由硬件自动处理(硬件管理的 TLB
) 。硬件负责访问页表并将条目填入 TLB(称为硬件页表遍历 , hardware page walk) 。
- MIPS 架构: TLB 未命中会产生一个异常,由操作系统负责处理(即软件管理的 TLB
TLB 条目详解 (Arm Cortex-A73 示例 ) (page 16-17) ¶
现代处理器通常有更复杂的 TLB 结构。例如 Arm Cortex-A73 (page 16):
- 微 TLB (micro TLBs):通常有单独的指令微 TLB (I-uTLB) 和数据微 TLB (D-uTLB),非常小且快,位于 CPU 核心旁。
- 主 TLB (Main TLB):一个更大、共享的 TLB。
- 例如,一个 4 路组相联、1024 条目的缓存,用于存储虚拟地址 (VA) 到物理地址 (PA) 的映射,支持 4KB, 16KB, 64KB 的页大小。
- 例如,一个 2 路组相联、128 条目的缓存,用于存储 VA 到 PA 的映射,支持 1MB, 2MB, 16MB, 32MB, 512MB, 1GB 的块 / 大页大小。
TLB 匹配过程 (Arm Cortex-A73): TLB 条目匹配成功需要满足多个条件:
- 虚拟地址 (VA) 匹配:请求的 VA(根据页大小屏蔽掉偏移位,如 VA 的 [47:12] 位代表 4KB 页的页号部分)与 TLB 条目中的 VA 标记匹配。
- 内存空间匹配:例如,安全状态、特权级别等匹配。
- ASID 匹配:当前进程的 ASID(存储在 CONTEXTIDR, TTBR0, 或 TTBR1 寄存器中)与 TLB 条目的 ASID 匹配,或者该 TLB 条目被标记为全局 (global)。
- VMID 匹配:如果使用了虚拟化,当前虚拟机的 ID (VMID,存储在 VTTBR 寄存器中 ) 也需要与 TLB 条目中的 VMID 匹配。
带 TLB 的分页硬件 (page 19) ¶
此图展示了结合 TLB 的地址转换流程:
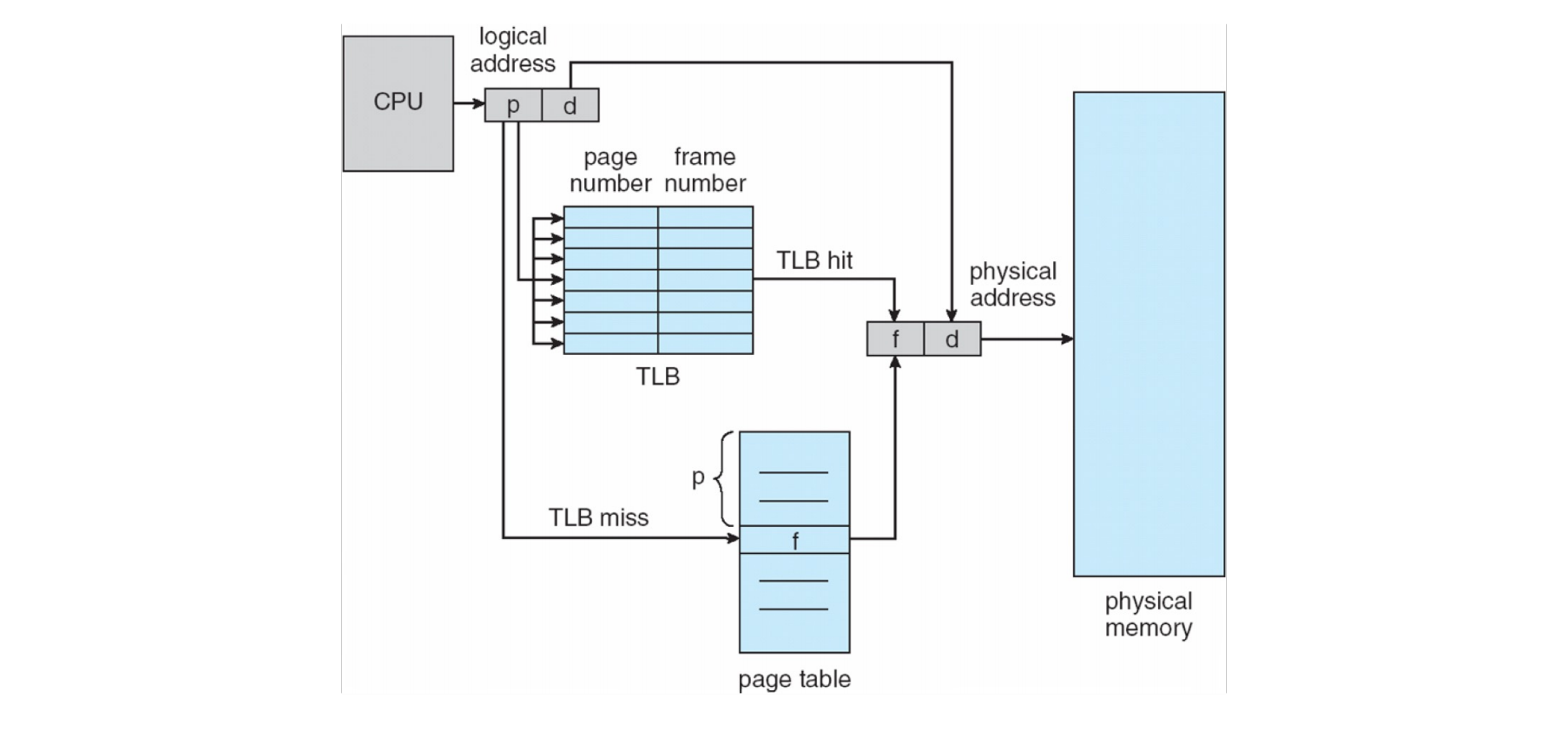
- CPU 生成逻辑地址,MMU 拆分为页号
p和偏移d。 - MMU 首先在 TLB 中查找页号
p。 - TLB 命中:如果找到,TLB 返回帧号
f。物理地址由f和d构成。 - TLB 未命中:如果未找到:
a. MMU(或OS,取决于架构)访问主存中的页表(基地址在PTBR,索引为
p)以获取帧号f。 b. 这个(p, f)映射被存入 TLB(可能替换现有条目)。 c. 物理地址由f和d构成。
有效访问时间 (Effective Access Time, EAT) (page 20) ¶
EAT 是衡量分页系统性能的重要指标。
- 命中率 (Hit ratio, \(\alpha\)): 在 TLB 中找到所需页号的概率(百分比t_mem (例如, 100 纳秒)。
EAT 计算
- 如果 TLB 命中(概率 \(\alpha\)
) ,总访问时间 =t_mem( 只需一次内存访问获取数据 / 指令 )。 - 如果 TLB 未命中(概率 \(1-\alpha\)
) ,总访问时间 =t_mem( 查页表 ) +t_mem( 获取数据 / 指令 ) =2 * t_mem。
EAT 公式:
\(EAT = \alpha \times t_{\text{mem}} + (1-\alpha) \times (t_{\text{mem}} (\text{for page table}) + t_{\text{mem}} (\text{for data/instruction}))\)
如果我们考虑查找页表也是一次内存访问,那么:
\(EAT = \alpha \times t_{\text{mem}} + (1-\alpha) \times 2 \times t_{\text{mem}} = t_{\text{mem}} \times (\alpha + 2(1-\alpha)) = t_{\text{mem}} \times (2 - \alpha)\)
示例 1 (page 20): 假设 \(t_{\text{mem}} = 100\) ns,TLB命中率 \(\alpha = 80\% = 0.80\)。 \(EAT = 0.80 \times 100 \text{ ns} + 0.20 \times 200 \text{ ns}\) \(EAT = 80 \text{ ns} + 40 \text{ ns} = 120 \text{ ns}\) 这意味着访问时间减慢了 \((120-100)/100 = 20\%\)。
示例 2 (page 20): 假设 \(t_{\text{mem}} = 100\) ns,TLB命中率 \(\alpha = 99\% = 0.99\)。 \(EAT = 0.99 \times 100 \text{ ns} + 0.01 \times 200 \text{ ns}\) \(EAT = 99 \text{ ns} + 2 \text{ ns} = 101 \text{ ns}\) 这意味着访问时间仅减慢了 \(1\%\)。
结论: 高 TLB 命中率对于分页系统的性能至关重要。
内存保护 (Memory Protection) (page 21-23) ¶
内存保护通过与每个物理帧(实际上是每个页表项)关联的保护位来实现。
- 存在位 / 有效位 (Present bit / Valid-invalid bit):
- 每个页表项 (PTE) 都有一个存在位(也叫有效位
) 。 - 有效 (Valid/Present): 表示该逻辑页当前在物理内存中有一个有效的物理帧映射,因此可以被访问。
- 无效 (Invalid/Absent): 表示该逻辑页当前不在物理内存中(可能从未加载,或已被换出到磁盘
) ,或者该逻辑地址对进程来说是无效的(例如,在进程逻辑地址空间的“洞”里) 。访问无效页会导致缺页中断 (page fault)。
- 每个页表项 (PTE) 都有一个存在位(也叫有效位
- 其他保护位: 每个 PTE 还可以包含一些权限位,例如:
- 内核 / 用户 (Kernel/User): 指示该页是否只能在内核模式下访问,还是用户模式也可以访问。
- 读 / 写 (Read/Write): 控制对该页的读写权限。例如,代码段的页通常是只读的。
- 执行 (Execute): 控制该页的内容是否可以作为指令执行。
- 内核执行 (Kernel-execution): 可能特指内核是否可以执行此页。
- 为什么需要这些位?
- 确保进程只能访问其被授权访问的内存区域。
- 防止对只读数据(如代码)的意外或恶意修改。
- 防止用户代码执行内核数据,或内核执行用户数据(某些情况下
) 。
- 任何违反内存保护规则的访问都会导致硬件陷入 (trap) 到内核,由内核处理(通常是终止违规进程
) 。
更具体的保护机制 (XN, PXN) (page 22):
- XN (Execute Never) / XD (Execute Disable) / EVP (Enhanced Virus Protection):
- 用于保护代码和数据的分离。将内存区域标记为不可执行。
- 如果 CPU 尝试从标记为 XN 的内存区域取指执行,会产生故障。
- Intel 称之为 XD,AMD 称之为 EVP,ARM 称之为 XN。
- 这是防止某些缓冲区溢出攻击(在数据区注入并执行恶意代码)的重要手段。
- PXN (Privileged Execute Never):
- 防止内核执行用户空间内存中的指令。
- 如果处理器在特权级(如内核模式,ARM 中的 EL1)下运行,并且尝试从一个其对应 PTE 中 PXN 位被设置(通常是用户空间的页)的内存区域取指执行,则会产生权限故障。
- Intel 类似的技术是 SMEP (Supervisor Mode Execution Prevention)。
- 这可以防止内核被诱骗执行用户提供的恶意代码。
内存保护示例图 (page 23):
图中展示了一个页表,每个条目除了帧号外,还有v (valid/invalid bit) 和其他权限位 (R W X U - Read, Write, eXecute, User/Supervisor access)。
- 例如,Page 0 映射到 Frame 2,有效,权限为 R W X U ( 用户可读写执行 )。
- Page 6 标记为
i(invalid),访问它会导致 page fault。
页共享 (Page Sharing) (page 24-25) ¶
分页机制天然地支持在进程间共享内存。
- 共享代码 (Shared Code):
- 例如,一个程序的多个实例(如多个编辑器进程)可以共享同一份代码。
- 只需将这些进程的页表中对应代码页的条目指向物理内存中相同的代码帧。
- 常见的例子:文本编辑器、编译器、浏览器、共享库 (shared libraries, e.g., libc)。
- 进程间通信 (Inter-Process Communication, IPC): 共享内存是 IPC 的一种高效方式。进程可以通过读写共享的内存页来交换数据。
- 可重入代码 (Reentrant Code / Pure Code):
- 为了能被安全地共享,代码必须是可重入的,即非自修改代码 (non-self-modifying code),在执行期间不会改变自身。
- 如果代码是可重入的,多个进程可以同时执行它而不会互相干扰。
- 每个进程仍然拥有其私有的代码和数据页(例如,每个进程有自己的栈和数据区
) 。
页共享示例 (page 25):
- 三个进程 P1, P2, P3;假设
ed1是一些可重入的编辑器代码。- P1 的页表 :
ed1( 逻辑页 ) -> 物理帧 3 - P2 的页表 :
ed1( 逻辑页 ) -> 物理帧 3 - P3 的页表 :
ed1( 逻辑页 ) -> 物理帧 3
- P1 的页表 :
- 所有三个进程共享物理帧 3 中的
ed1代码。 - 它们各自有私有数据页,如 P1 的
data1映射到物理帧 1,P2 的data2映射到物理帧 7。
页表结构 (Structure of Page Table) (page 26) ¶
单级页表在现代系统中可能非常大,消耗大量内存。
- 例如:一个 32 位逻辑地址空间 (\(2^{32}\) 字节 ) 和 4KB (\(2^{12}\) 字节 ) 的页大小。
- 逻辑地址中,页号占 \(32 - 12 = 20\) 位。
- 这意味着页表需要有 \(2^{20}\) 个条目 ( 大约一百万个条目 )。
- 如果每个页表项 (PTE) 占 4 字节。
- 那么仅一个进程的页表就需要 \(2^{20} \times 4 \text{ Byte} = 1M \times 4 \text{ Byte} = 4 \text{ MB}\) 的内存。
- 每个进程都需要自己的页表。
- 在许多简单实现中,页表本身必须物理上连续存放,这使得分配如此大的连续内存块变得困难。
ELF 二进制基础与逻辑地址的“洞” (page 28):
查看进程的内存映射 ( /proc/self/maps ) 会发现,逻辑地址空间通常是稀疏的,存在大量未使用的“洞”(holes
最坏情况 (32 位单级页表 ) (page 29): 如果一个进程只访问了它的第一个页 (Page 0) 和最后一个页 (Page 0xfffff),单级页表仍然需要包含所有 \(2^{20}\) (0x100000) 个条目,占用 4MB 内存,并且这 4MB 需要物理连续。
- 1K = 1024 = 0x400
- 4K = 4096 = 0x1000
- 1M = 1024 x 1024 = 0x100000
如何解决大页表问题? (page 30-31)
- 问题:我们能把页表本身也分页吗
? (即,把页表拆分成页大小的块) - 如果页大小是 4KB,每个 PTE 是 4 字节,那么一个 4KB 的物理帧可以存放 \(4KB / 4B = 1024\) (1K) 个 PTE。
- 对于上述 32 位、4KB 页大小的例子,整个页表 (1M 个 PTE) 可以被划分为 \(1M / 1K = 1024\) 个“页表页”。
- 这些“页表页”本身可以像普通数据页一样被管理。
- 我们可以用另一个页表(称为外层页表或页目录)来索引这些“页表页”。
这就引出了分层页表 (Hierarchical Page Tables)。
分层页表 (Hierarchical Page Tables) (page 32) ¶
将逻辑地址空间划分为多个级别的页表。
- 例如,二级页表 (Two-level page table):
- 第一级页表 (Outer page table / Page directory):它的条目不直接指向数据帧,而是指向第二级页表的帧号。
- 第二级页表 (Inner page table / Page table page):它的条目才包含实际数据页对应的物理帧号。
- 本质上是对页表本身进行了“分页”。
为什么分层页表能节省内存? (page 32)
- 如果一个进程的逻辑地址空间很稀疏,只使用了少量区域,那么很多第二级页表可能根本不需要存在。
- 对于逻辑地址空间中大片未使用的区域,外层页表(页目录)中对应的条目可以为空(或标记为无效
) ,这样就不必为这些区域分配第二级页表,从而节省了大量内存。
二级页表示例 (page 33) ¶
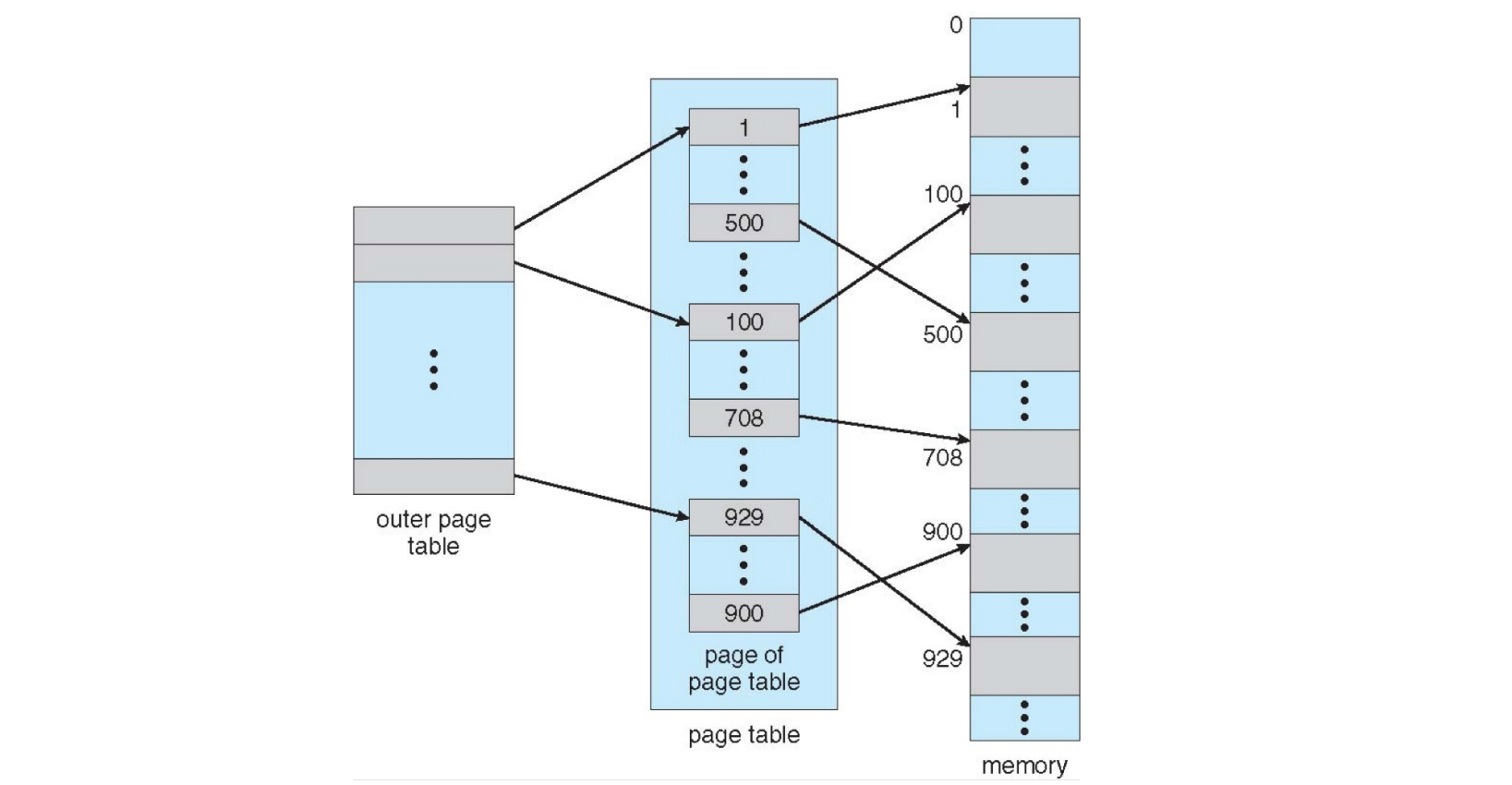
- 外层页表 (Outer page table / Page Directory):
- 它的每个条目指向一个第二级页表所在的物理帧。
- 页表页 (Page of page table / Second-level Page Table):
- 每个这样的页表页包含一组 PTE,这些 PTE 指向实际的数据 / 代码页所在的物理帧。
- 如果外层页表的某个条目为空,则对应的整个第二级页表(通常包含 1K 个 PTE,对应 4MB 的逻辑地址空间)就不需要分配。
二级分页地址划分 (32 位 Intel CPU 示例 ) (page 34) ¶
对于一个 32 位逻辑地址,4KB 页大小的系统 ( 如早期 IA-32 架构 ): - 逻辑地址 (32 位) 被划分为: - 页目录号 (Page directory number, \(p_1\)): 10 位。用于索引页目录。 - 页表号 (Page table number, \(p_2\)): 10 位。用于索引选定的二级页表。 - 页内偏移 (Page offset, \(d\)): 12 位 ( 因为 \(2^{12} = 4096 = 4KB\))。 - \(p_1\) (10位) \(\implies\) 页目录有 \(2^{10} = 1024\) 个条目。 - \(p_2\) (10位) \(\implies\) 每个二级页表有 \(2^{10} = 1024\) 个条目。 - 每个 PTE 为 4 字节。 - 因此,一个页目录正好占用 \(1024 \times 4B = 4KB\),可以放入一个物理帧。 - 每个二级页表也正好占用 \(1024 \times 4B = 4KB\),也可以放入一个物理帧。
| 页目录索引 \(p_1\) | 页表索引 \(p_2\) | 页内偏移 \(d\) |
|---|---|---|
| 10 bits | 10 bits | 12 bits |
Linux 中的页表 ( 早期 32 位示例 ) (page 36) 此图展示了 Linux 在 32 位 x86 系统上如何使用二级页表。
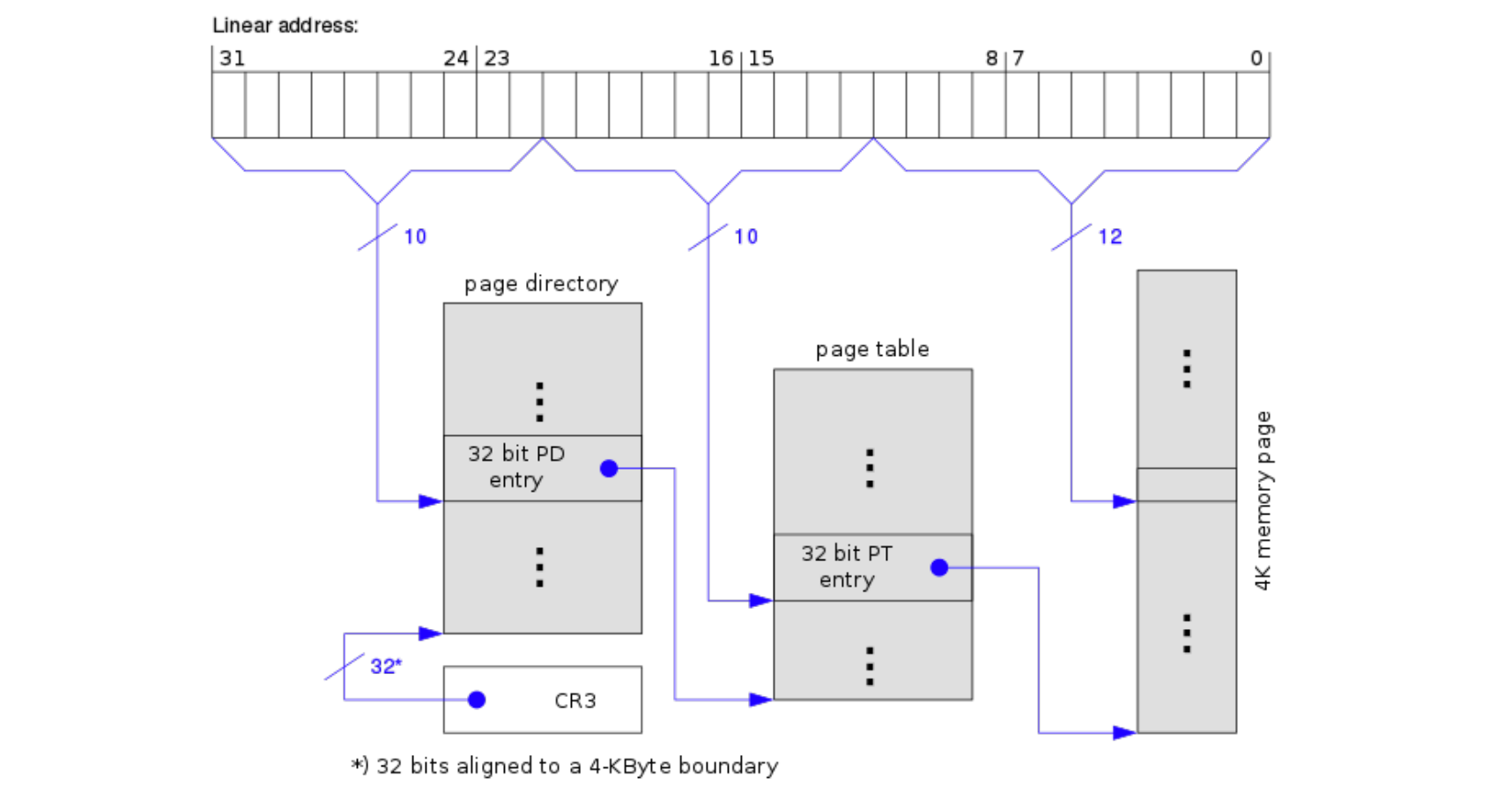
- 线性地址 ( 逻辑地址 ) 被分为 10 位页目录索引,10 位页表索引,12 位偏移。
- CR3 寄存器指向当前页目录的物理基地址(要求 4KB 对齐
) 。 - 页目录项 (PDE) 指向页表的物理基地址。
- 页表项 (PTE) 指向最终 4KB 物理页的基地址。
64 位逻辑地址空间 (page 37) ¶
64 位逻辑地址空间非常巨大,二级分页已不足够。 - 如果页大小仍为4KB (\(2^{12}\)),则页号部分为 \(64 - 12 = 52\) 位。 - 如果仍用 10 位索引页表,二级分页意味着: - \(p_1\) (外层页表索引) 需要 \(52 - 10 = 42\) 位。 - 即外层页表需要 \(2^{42}\) 个条目,这本身就太大了 (\(2^{42} \times 4B = 16TB\))。 - 解决方案:增加更多级别的页表。 - 例如,三级分页:第一级页表的条目大小为 \(2^{32}\) 字节,仍然太大。 - 实际中可能需要三级、四级甚至五级分页。 - 多级分页会导致多次内存访问才能完成一次地址翻译(TLB 未命中时),例如四级分页可能需要 4 次内存访问页表 + 1 次访问数据。 - 实践中的 64 位系统: - 通常不真正支持完整的 64 位虚拟地址空间。CPU 硬件可能只实现较少的地址位。 - AMD64 (x86-64) 架构目前支持 48 位虚拟地址。 - ARM64 架构支持 39 位或 48 位虚拟地址。
ARM64 39 位虚拟地址分页 (page 38-39) ¶
对于 39 位虚拟地址和 4KB 页大小:\(39 = 9+9+9+12\)。这对应三级分页。
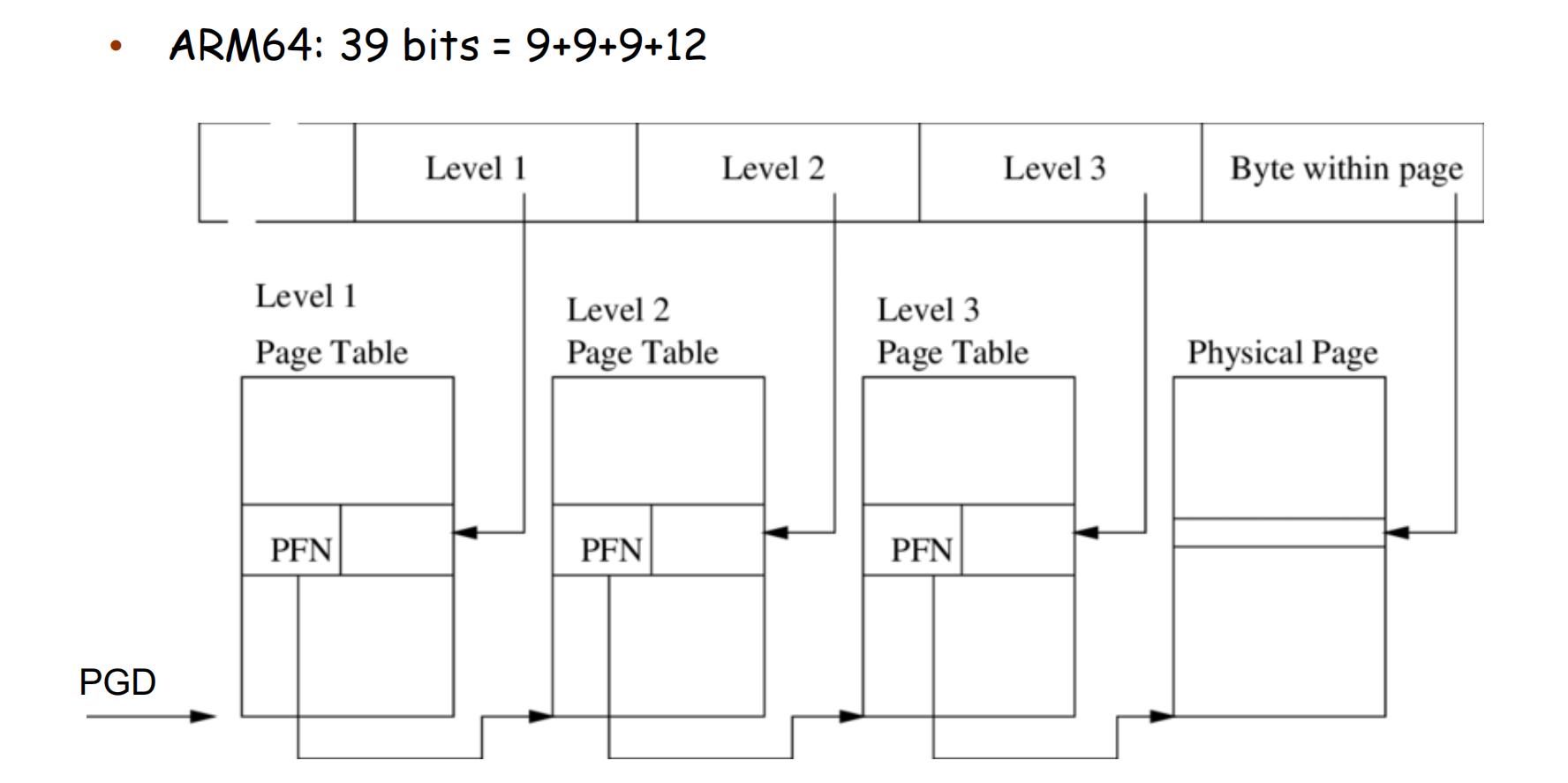
- VA[38:30] (9 bits): Level 1 Page Table (PGD - Page Global Directory) index.
- VA[29:21] (9 bits): Level 2 Page Table (PUD - Page Upper Directory, or PMD - Page Middle Directory in Linux) index.
- VA[20:12] (9 bits): Level 3 Page Table (PTE - Page Table Entry level) index.
- VA[11:0] (12 bits): Offset within the 4KB page.
ARM64 48 位虚拟地址分页 (page 61, 66, 67)¶
对于 48 位虚拟地址和 4KB 页大小:\(48 = 9+9+9+9+12\)。这对应四级分页。
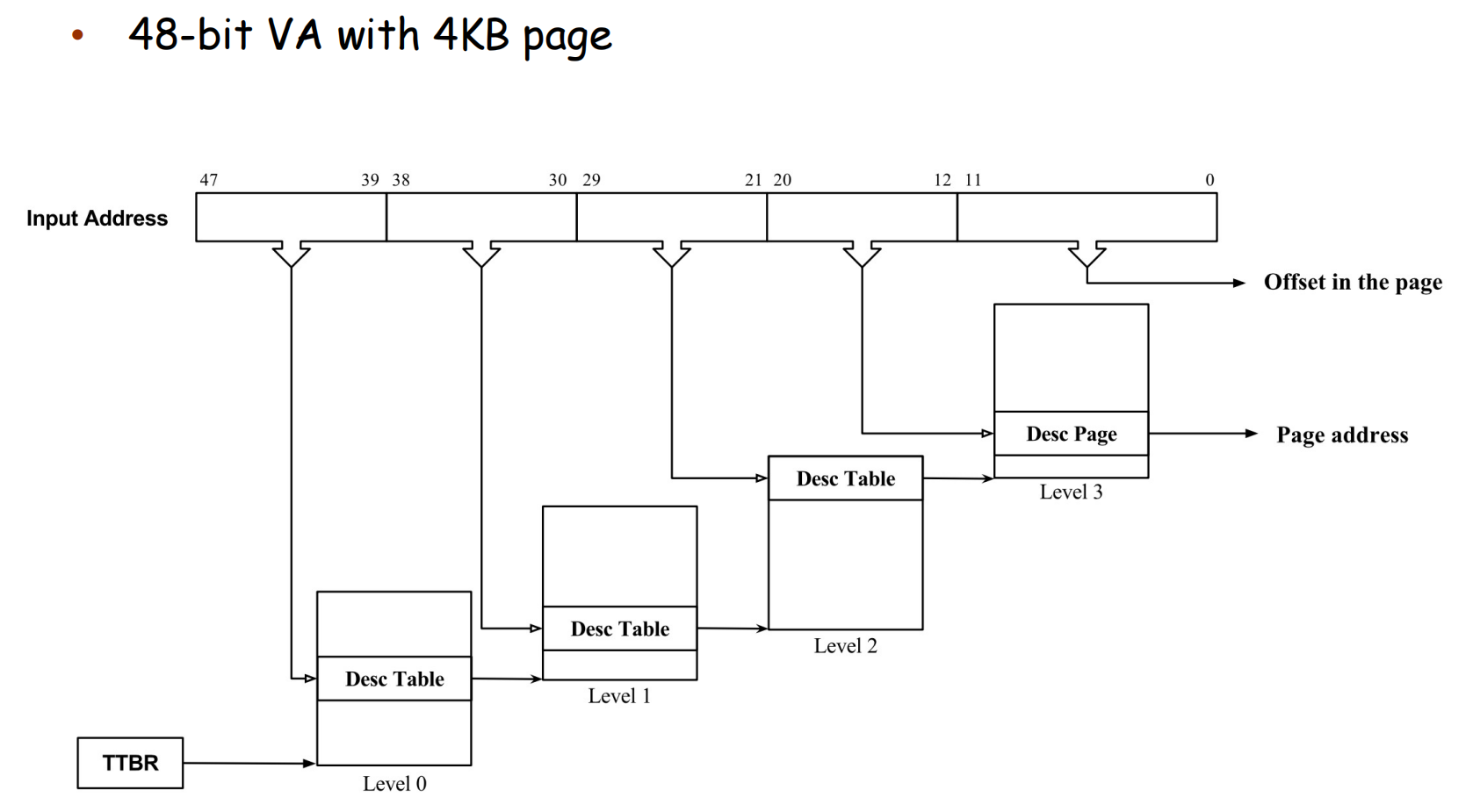
- VA[47:39] (9 bits): Level 0 (or L1 in some nomenclatures) index.
- VA[38:30] (9 bits): Level 1 (or L2) index.
- VA[29:21] (9 bits): Level 2 (or L3) index.
- VA[20:12] (9 bits): Level 3 (or L4, PTE level) index.
- VA[11:0] (12 bits): Offset.

48-bit VA with 64KB page (page 67)
- TTBR 指向 Level 1 描述符表 ( 这里层级命名与上一图不同,注意相对关系 )。
- VA[47:42] (6 bits) -> Index for Level 1 Table. Output: Base of Level 2 Table.
- VA[41:29] (13 bits) -> Index for Level 2 Table. Output: Base of Level 3 Table (Desc Page).
- VA[28:16] (13 bits) -> Index for Level 3 Table. Output: Page Address (Frame Number).
- VA[15:0] (16 bits) -> Offset in the page.
- Result: Physical Address = (Page Address << 16) | Offset.
- This is a three-level page table.
关于 ARM 页表级别命名的说明
ARM 架构的文档中,页表级别(Level 0, 1, 2, 3)的划分和命名可能根据地址位数(39 位、48 位、52 位)和页大小(Granule size: 4KB, 16KB, 64KB)而有所不同。关键在于理解其分层查找的思想:每一级页表的条目指向下一级页表的基址,或者在最后一级(或大页情况下)直接指向物理帧。所使用的虚拟地址位数和页大小决定了总共需要多少位用于页号索引,这些索引位再分配到各个层级。
哈希页表 (Hashed Page Tables) (page 40-41) ¶
- 虚拟页号 (virtual page number, VPN) 通过哈希函数 (hash function) 计算出一个哈希值,这个值用作哈希表 (hash table) (用于处理大于 32 位的地址空间)的索引。
- 哈希表中的每个条目指向一个链表 (linked list) 的头。这个链表包含了所有哈希到同一位置的元素。
- 链表中的每个元素通常包含:
- 虚拟页号 (VPN)
- 对应的物理帧号 (PFN)
- 指向链表中下一个元素的指针 ( 用于解决哈希冲突 , resolving conflict)。
- 查找过程:
- 计算 VPN 的哈希值,得到哈希表索引。
- 遍历对应索引处的链表,将请求的 VPN 与链表每个元素的 VPN 进行比较。
- 如果找到匹配,返回对应的 PFN。
- 如果未找到(遍历完链表
) ,则发生缺页。
- 变体:簇状页表 (Clustered page tables):哈希表的每个条目不只对应一个页,而是对应多个相邻的页(一个簇
) 。这对于空间局部性较好的程序有益。
哈希页表示意图 (page 41):
逻辑地址 (p, d) -> p 输入哈希函数 -> 索引哈希表 -> 得到链表头 -> 遍历链表比较 p -> 找到匹配项 (p, r) -> r 是帧号 -> 物理地址 (r, d)。
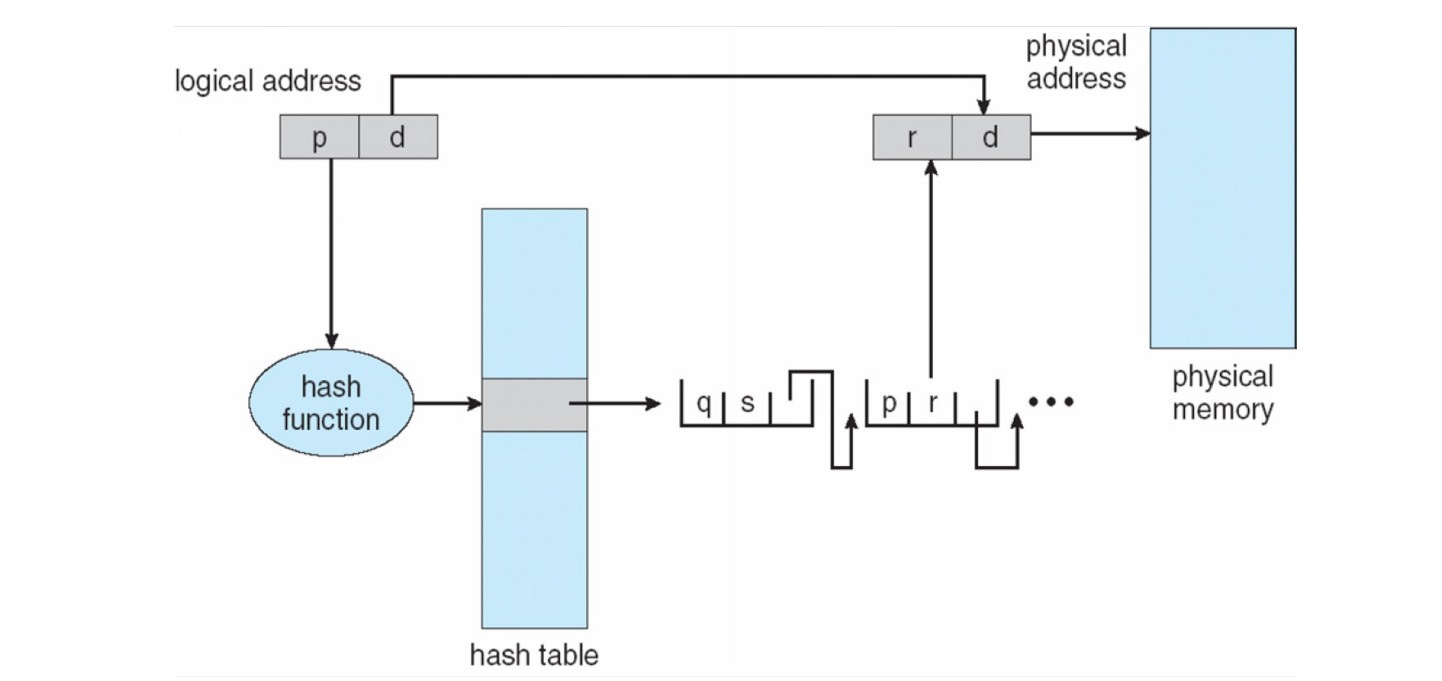
哈希表的大小抉择
- 如果 hash table 太小,哈希碰撞将会太多,效率过低;
- 如果 hash table 太大,占用空间过多(且 hash table 需要是连续的)
所以实际并没有使用,只是作为一个设计原型。
反向页表 (Inverted Page Table) (page 42-43) ¶
传统页表是每个进程一个,页表大小与进程的逻辑地址空间大小成正比。反向页表则不同:
- 系统中只有一个反向页表。
- 表中的每个条目对应一个物理帧 (physical frame),而不是逻辑页。
- 因此,反向页表的大小与物理内存大小成正比,而不是与所有进程的虚拟地址空间总和成正比。
- 物理内存通常远小于总的虚拟地址空间,所以反向页表可以更小。
- 每个条目包含:
- 进程 ID (process ID, PID):占用此帧的进程。
- 页号 (page number, p):此帧中存储的该进程的逻辑页号。 (以及其他控制位)
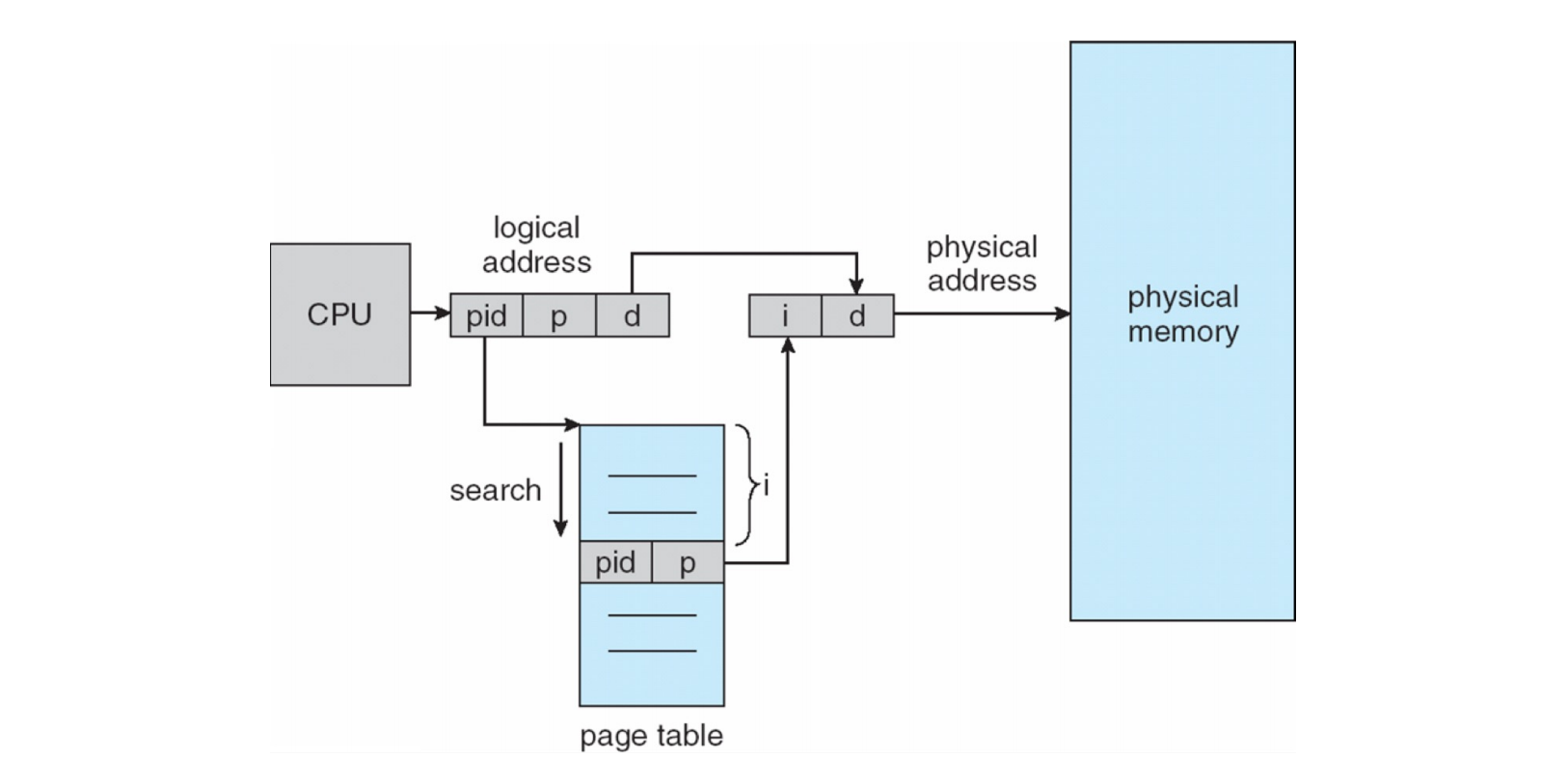
地址转换过程: CPU 发出<pid, p, d> -> 在反向页表中搜索(pid, p) -> 若第 i 个条目匹配 -> i就是帧号 -> 物理地址 (i, d)。
- CPU 生成逻辑地址
<PID, p, d>(PID 是隐式的,代表当前进程 )。 - MMU 需要在整个反向页表中搜索匹配
<PID, p>的条目。 - 如果找到一个条目
<PID, p>,其在反向页表中的索引i本身就是物理帧号。 - 物理地址为
<i, d>。 - 如果未找到,则发生缺页。
优点: - 大大减少了页表所需的总内存量,因为页表大小固定,与物理内存大小相关。
缺点:
- 搜索开销大: 每次地址转换(TLB 未命中时)都需要搜索整个反向页表。虽然可以使用哈希技术来加速搜索,但仍然比直接索引慢。
- TLB 未命中代价高: 因为搜索可能很慢。
- 实现共享内存困难:
- 一个物理帧在反向页表中只有一个条目。
- 如果多个进程共享一个物理帧,那么该帧条目中的 <PID, p> 如何表示这种多对一的映射?
- 标准反向页表结构中,一个物理帧只能映射到一个进程的一个虚拟页。因为一个物理内存页不能有多个虚拟页条目指向它。
- 需要额外的复杂机制来处理共享页。
交换 (Swapping) (page 44-45) ¶
交换是一种允许系统物理内存看起来比实际更大的技术,通过使用后备存储 (backing store) ( 通常是快速磁盘 ) 来临时存放不活动的进程或页。
- 一个进程(或其部分)可以被暂时从主存中换出 (swap out) 到后备存储。
- 当需要再次运行时,它会被换回 (swap in) 到主存中继续执行。
- 问题:进程换回时是否需要放回原来的物理地址?
- 如果使用动态地址绑定(如分页或分段
) ,则不需要。它可以被加载到任何可用的物理帧 / 分区。
- 如果使用动态地址绑定(如分页或分段
- 问题:进程换回时是否需要放回原来的物理地址?
- 交换通常只在内存压力较大时启动(例如,没有足够的空闲帧来满足请求
) 。 - 上下文切换时间可能非常高:
- 如果下一个要运行的进程不在内存中,操作系统需要将其从磁盘换入。这涉及磁盘 I/O,延迟很高。
- 同时,可能需要将当前内存中的某个进程换出来腾出空间。
包含交换的上下文切换时间 (page 46) ¶
- 如果下一个要调度的进程不在内存中,就需要换出一个当前进程,并换入目标进程。
- 这会导致上下文切换时间非常高。
- 示例:
- 假设要交换一个 100MB 的进程。
- 磁盘传输速率为 50MB/ 秒。
- 换出时间 = \(100MB / 50MB/s = 2 \text{ 秒} = 2000 \text{ ms}\)。
- 换入同样大小的进程也需要 2000 ms。
- 总的由交换引起的上下文切换时间增加为 \(4000 \text{ ms}\) (4 秒 )!这是非常巨大的开销。
- 优化: 可以通过只交换进程实际使用的内存部分(而不是整个进程映像)来减少交换量。这通常通过按需分页 (demand paging) 和页交换 (swapping pages) 实现。
页交换 (Swapping with Paging) (page 47) ¶
现代系统通常不交换整个进程,而是交换单独的页。
- 当需要空闲帧时,选择一些不常用的页换出到后备存储。
- 当访问一个已被换出的页时,发生缺页中断,操作系统负责将该页从后备存储换回到某个空闲帧。
- 这比交换整个进程更灵活,开销也更小。
图中显示了进程 A 的某些页被换出,进程 B 的某些页被换入。
移动系统上的交换 (page 48) ¶
- 在移动设备(如智能手机、平板电脑)上,传统的磁盘交换通常不受支持。
- 原因:
- 闪存 (Flash memory):移动设备通常使用闪存作为存储。
- 空间相对较小。
- 有限的写周期 (Limited number of write cycles):频繁交换会缩短闪存寿命。
- 在移动平台上,闪存与 CPU 之间的吞吐量可能较差。
- 闪存 (Flash memory):移动设备通常使用闪存作为存储。
- 替代方法释放内存:
- iOS: 要求应用程序在内存不足时自愿放弃 (voluntarily relinquish) 已分配的内存。
- 只读数据(如代码)可以直接丢弃,需要时从闪存重新加载。
- 如果应用未能释放足够内存,可能被系统终止。
- Android: 在低内存情况下,会终止不活动的应用程序。
- 在终止前,通常会将应用程序的状态 (application state) 写入闪存,以便快速重启。
- iOS: 要求应用程序在内存不足时自愿放弃 (voluntarily relinquish) 已分配的内存。
架构示例:Intel 32 位和 64 位 (page 49) ¶
- IA-32 (Intel Architecture, 32-bit):Pentium 系列 CPU 采用的 32 位架构。
- IA-64 (Intel Architecture, 64-bit):常见的 64 位 Intel 架构是x86-64
Intel IA-32 架构 (page 50-51) ¶
IA-32 支持分段 (segmentation) 和带分页的分段 (segmentation with paging)。
分段特性:
- 每个段最大可以是 4 GB。
- 每个进程最多可以有 16K (\(2^{14}\)) 个段。
- 这些段分为两个分区:
- LDT (Local Descriptor Table) 分区: 最多 8K (\(2^{13}\)) 个段,是进程私有的。LDT 描述这些私有段。
- GDT (Global Descriptor Table) 分区: 最多 8K (\(2^{13}\)) 个段,可由所有进程共享。GDT 描述这些共享段(如内核代码段、数据段
) 。
- 逻辑地址到线性地址的转换 (page 51-52):
- CPU 生成的逻辑地址包含一个选择子 (selector) 和一个偏移 (offset)。
- 选择子 (16 位 ) 的结构:
- Index (13 位 ): 指向 GDT 或 LDT 中的描述符条目。
- TI (Table Indicator, 1 位 ): 0=GDT, 1=LDT。
- RPL (Requested Privilege Level, 2 位 ): 请求特权级。
- 选择子被送到分段单元。
- 分段单元使用选择子从 GDT 或 LDT(基地址分别在 GDTR 和 LDTR 寄存器中)中获取段描述符 (segment descriptor)。
- 段描述符包含段的基址 (base address)、界限 (limit)、类型、权限等信息。
- 线性地址 (Linear Address) = 段基址 + 偏移量。
- 同时进行界限检查和权限检查。
- 常用的段寄存器:CS (Code Segment), DS (Data Segment), SS (Stack Segment), ES, FS, GS。CS 指向当前执行指令的代码段。DS 通常指向数据段。
- 线性地址到物理地址的转换 ( 分页 ) (page 53-55):
- 分段单元产生的线性地址 (32 位 ) 会被送到分页单元 ( 如果分页被启用 )。
- 分页单元将线性地址转换为物理地址。
- 分页单元相当于 MMU 的核心功能。
- IA-32 支持的页大小可以是 4 KB 或 4 MB ( 大页 )。
- 4KB 页,二级分页:
- 线性地址 (32 位 ) -> 10 位页目录索引 (PDE) | 10 位页表索引 (PTE) | 12 位页内偏移。
- CR3 寄存器指向当前页目录的物理基地址。
- 4MB 页,一级分页 ( 实际是页目录直接映射大页 ):
- 线性地址 (32 位 ) -> 10 位页目录索引 (PDE) | 22 位页内偏移。
- 页目录项 (PDE) 中的一个特殊位指示它映射的是一个 4MB 的页还是一个页表。
逻辑地址到物理地址的完整翻译流程 (IA-32) (page 54): CPU (逻辑地址) -> Segmentation Unit (线性地址) -> Paging Unit (物理地址) -> 物理内存
IA-32 分页架构图 (page 55):
- CR3 寄存器指向页目录。
- 线性地址的高 10 位索引页目录,找到一个页目录项 (PDE)。
- 如果 PDE 指向一个页表(对于 4KB 页
) :- 线性地址的中间 10 位索引该页表,找到一个页表项 (PTE)。
- PTE 包含 4KB 数据页的物理帧基地址。
- 线性地址的低 12 位是页内偏移。
- 如果 PDE 指向一个 4MB 页:
- PDE 本身包含 4MB 数据页的物理帧基地址。
- 线性地址的低 22 位是页内偏移。
Intel IA-32 物理地址扩展 (PAE) (page 56) ¶
由于 32 位线性地址最多只能寻址 4GB 物理内存,为了让 32 位应用程序能够访问超过 4GB 的物理内存,Intel 引入了 PAE。
- PAE (Physical Address Extension):
- 允许系统支持高达 \(2^{36}\) 字节 (64GB) 的物理内存。
- 虚拟地址空间(线性地址空间)对每个进程来说仍然是 32 位 (4GB)。
- 页目录项 (PDE) 和页表项 (PTE) 的大小从 4 字节增加到 8 字节 (64 位 )。这使得它们可以存储 36 位的物理帧号。
- 分页变为三级结构:
- CR3 指向一个页目录指针表 (Page Directory Pointer Table, PDPT)。PDPT 有 4 个 64 位条目。
- 线性地址的高 2 位 (bits 31-30) 用于索引 PDPT,选择一个页目录。
- PDPT 条目指向一个页目录 (Page Directory)。
- 线性地址的接下来 9 位 (bits 29-21) 索引页目录,得到一个 PDE。
- PDE 指向一个页表 (Page Table)。
- 线性地址的再接下来 9 位 (bits 20-12) 索引页表,得到一个 PTE。
- PTE 包含 36 位物理帧号(对于 4KB 页
) 。 - 低 12 位是偏移。
- (PAE 也支持 2MB 大页,此时 PDE 直接指向 2MB 物理帧,中间的页表级被跳过 )。
PAE 地址划分 (4KB 页 ):
| PDPT Index (2b) | PD Index (9b) | PT Index (9b) | Offset (12b) |
|---|---|---|---|
| 31-30 | 29-21 | 20-12 | 11-0 |
Linux 对 Intel Pentium 的支持 (page 57) ¶
- 分段使用简化: Linux 主要依赖分页进行内存管理,但不能完全禁用 x86 的分段机制。
- Linux 只使用了 6 个段描述符(通常 GDT 中
) :- 内核代码段、内核数据段
- 用户代码段、用户数据段
- 任务状态段 (Task-State Segment, TSS)
- 默认 LDT 段(通常不用)
- 这些段的基址通常都设为 0,界限设为最大 (4GB),使得分段机制几乎是“平坦的”,逻辑地址等于线性地址。
- Linux 只使用了 6 个段描述符(通常 GDT 中
- 特权级: Linux 只使用 x86 的 4 个特权级(Ring 0-3)中的两个:
- 内核运行在 Ring 0 ( 最高特权 )。
- 用户空间运行在 Ring 3 ( 最低特权 )。
- 分页模型:
- Linux 为 32 位和 64 位系统使用通用的四级分页模型(逻辑上
) 。 - 在 32 位系统上,如果未使用 PAE,实际上是二级分页(页全局目录 PGD, 页中间目录 PMD 被省略,PUD 被省略,PTE
) 。 - 在 32 位系统上如果使用 PAE,是三级分页 (PGD, PUD/PMD, PTE)。
- (Page 58 的三级分页图更像是 PAE 或早期 64 位模型的简化
) 。
- Linux 为 32 位和 64 位系统使用通用的四级分页模型(逻辑上
三级分页在 Linux 中的示意图 (page 58): 线性地址被划分为:全局目录索引 (Global Directory),中间目录索引 (Middle Directory),页表索引 (Page Table),偏移 (Offset)。 CR3 指向全局目录。
Intel x86-64 (page 59)¶
- 当前主流的 Intel 64 位架构。
- 理论上支持 64 位地址(> 16 EB,艾字节
) ,但实际硬件通常只实现 48 位虚拟地址寻址。 - 页大小: 支持 4KB, 2MB ( 大页 ), 1GB ( 巨页 )。
- 分页层次: 通常是四级分页 ( 对应 48 位虚拟地址和 4KB 页大小 )。
- 48 位虚拟地址 - 12 位偏移 = 36 位页号部分。
- \(36 / 4 \text{ 级} = 9\) 位索引每级。
- 9 (PML4) + 9 (PDPT) + 9 (PD) + 9 (PTE) + 12 (Offset) = 48 bits.
- PML4: Page Map Level 4 Table
- PDPT: Page Directory Pointer Table
- PD: Page Directory
- PTE: Page Table (entries)
- 也可以使用 PAE(但这里 PAE 的含义可能与 32 位不同,主要是指物理地址可以比虚拟地址位数更多,例如 52 位物理地址
) 。不过,48 位虚拟地址通常已足够,且当前物理内存容量远未达到 \(2^{48}\) 字节。
x86-64 48 位虚拟地址格式 (4KB 页 ) (page 59 bottom)
| Unused (16b) | PML4 Index (9b) | PDPT Index (9b) | PD Index (9b) | PT Index (9b) | Offset (12b) |
|---|---|---|---|---|---|
| 63-48 | 47-39 | 38-30 | 29-21 | 20-12 | 11-0 |
架构示例:ARM32 (page 60)¶
- 节能高效的 32 位 CPU,广泛用于嵌入式和早期移动设备。
- 页大小:
- 小页:4KB, 16KB ( 还有 1KB,但不常用 )
- 段 / 节 (Sections) 或大页:1MB, 16MB (Supersections)。
- 分页结构:
- 对于段 / 节 (1MB/16MB):使用一级页表 ( 称为翻译表 , Translation Table)。页目录项直接包含物理地址。
- 对于小页 (4KB/16KB):使用二级页表。第一级表项指向第二级表的基址。
- TLB 结构: 通常有两级 TLB。
- 外层 (L1 TLB): 通常分为独立的指令 TLB (I-TLB) 和数据 TLB (D-TLB),称为微 TLB (micro TLBs)。
- 内层 (L2 TLB): 一个统一的主 TLB (Main TLB),更大。
- 查找顺序:先查微 TLB,若未命中,再查主 TLB。若主 TLB 也未命中,则由硬件(或软件,取决于 ARM 版本和配置)进行页表遍历 (page table walk)。
ARM32 地址翻译示意图 ( 二级分页 ) (page 60 right):
32 位虚拟地址被分为:一级索引 (Outer page),二级索引 (Inner page),偏移 (Offset)。 TTBR (Translation Table Base Register) 指向一级翻译表。
架构示例:ARM64 (page 61)¶
- 主导移动平台的高性能芯片(如苹果 iOS 设备、许多高端安卓设备
) 。 - 寻址支持:
- 39 位虚拟地址: \(9+9+9+12\) (3 级页表,4KB 页 )。
- 48 位虚拟地址: \(9+9+9+9+12\) (4 级页表,4KB 页 )。
- 图示为 3 级分页系统 ( 对应 39 位 VA 或 48 位 VA 的部分实现,取决于 TTBR 配置和地址高位是否使用 )。
- Virtual Address -> Level 1 Table -> Level 2 Table -> Level 3 Table -> (Frame | Offset) = Physical Address.
- PTBR ( 实际是 TTBR0_EL1 或 TTBR1_EL1 等 ) 指向第一级页表的基址。
总结与回顾 (Takeaway) (page 62) ¶
- 连续分配:
- 固定分区、可变分区
- 分段 ( 每个段内部是连续的 )
- 碎片:
- 内部碎片 ( 分页和固定分区 )
- 外部碎片 ( 分段和可变分区 )
- MMU: 硬件,负责地址转换和保护。
- 分页:
- 将逻辑和物理内存划分为固定大小的页和帧。
- 页表: 存储逻辑页到物理帧的映射。
- 分层页表 (Hierarchical): 如二级、三级、四级页表,用于管理大地址空间并节省页表本身的空间。
- 哈希页表 (Hashed page table): 用于非常大的地址空间,通过哈希函数查找。
- 反向页表 (Inverted page table): 页表大小与物理内存成正比,而不是虚拟空间。
- 支持 32 位和 64 位架构。
分段 vs. 分页 (page 63) ¶
- 提出时间:
- 内存分段 (Memory Segmentation): 约 1961 年被提出并实现,如 Burroughs B5000 系统。
- 内存分页 (Memory Paging): 约 1962 年被提出并首次用于曼彻斯特大学的 Atlas 计算机。
- 为什么分段比分页实现得早?
- 硬件复杂性和成本: 分页通常需要更复杂的 MMU 硬件(尤其是 TLB 和多级页表遍历逻辑
) 。分段的硬件相对简单(段表、比较器、加法器) 。 - 操作系统管理: 早期的分段管理相对简单,操作系统不需要复杂的内存管理算法(如页面替换
) 。 - 理解程度: 分段的概念(将程序划分为逻辑单元)对程序员来说更自然,更容易理解和实现。
- 硬件复杂性和成本: 分页通常需要更复杂的 MMU 硬件(尤其是 TLB 和多级页表遍历逻辑
页表测验 (page table quiz) (page 64-65) ¶
如何手动进行 walk page table
问题 1: 32 位架构,单级页表,整个页表多大? ( 假设 4KB 页,4B/PTE)
- 页号位数 = \(32 - 12 (\text{for 4KB offset}) = 20\) bits.
- PTE 数量 = \(2^{20} = 1M\).
- 页表大小 = \(1M \times 4B = 4MB\).
问题 2: 32 位架构,二级页表,页表多大? (4KB 页 , 4B/PTE, 10+10+12 划分 )
- 第一级页表 ( 页目录 ): \(2^{10}\) 个条目 \(\times\) 4B/ 条目 = \(1K \times 4B = 4KB\).
- 第二级页表:
- 每个二级页表也是 \(2^{10}\) 个条目 \(\times\) 4B/ 条目 = \(4KB\).
- 最多可以有 \(2^{10}\) 个二级页表(如果整个 4GB 空间都被密集使用
) 。 - 总大小 = \(4KB (\text{页目录}) + N \times 4KB (\text{二级页表})\),其中 \(N\) 是实际使用的二级页表的数量。
- 最坏情况 ( 密集使用 ):\(4KB + 2^{10} \times 4KB = 4KB + 1024 \times 4KB = 4KB + 4MB \approx 4MB\).
问题 3: 为什么二级页表能节省内存?
- 对于稀疏地址空间,如果一级页表(页目录)中的某个条目指示对应的地址范围未使用,则该条目可以为空,相应的二级页表就不必创建,从而节省了该二级页表所需的 4KB 空间。
问题 4: 二级页表遍历示例 ( 假设 10+10+12 划分 , 4B/PTE)
-
PTBR (CR3) =
0x00619000, VA =0xf2015202- VA =
1111 0010 00 | 00 0001 0101 | 0010 0000 0010 - \(p_1\) ( 页目录索引 ) =
1111001000(binary) =0x3C8 - \(p_2\) ( 页表索引 ) =
0000010101(binary) =0x015 - \(d\) ( 偏移 ) =
001000000010(binary) =0x202 - PDE 地址 = PTBR + \(p_1 \times 4 = 0x00619000 + 0x3c8 \times 4 = 0x00619000 + 0xf20 = 0x00619f20\).
- 假设从
0x00619F20读出的 PDE 内容(取物理地址部分)为Entry_PDE( 这是二级页表的基址 )。
- 假设从
- PTE 地址 = (Entry_PDE & PageMask) + \(p_2 \times 4\).
- 假设从该地址读出的 PTE 内容为
Entry_PTE( 这是数据帧的基址 )。
- 假设从该地址读出的 PTE 内容为
- 物理地址 = (Entry_PTE & PageMask) + \(d\).
- VA =
-
PTBR =
0x10514000, VA =0x21907010- VA =
0010 0001 10 | 01 0000 0111 | 0000 0001 0000 - \(p_1\) =
0010000110(binary) =0x086 - \(p_2\) =
0100000111(binary) =0x107 - \(d\) =
000000010000(binary) =0x010 - 后续计算同上。
- VA =
如果页大小是 64KB
- 页大小 = 64KB = \(2^{16}\) 字节。所以偏移量占 16 位。
- 32 位虚拟地址:
- 页号位数 = \(32 - 16 = 16\) 位。
- 格式:
16-bit Page Number | 16-bit Offset. ( 单级页表 ) - 如果使用多级,需要进一步划分这 16 位页号;每页最多存放 \(\frac{2^{16}}{4} = 2^{14}\) 条 PTE,则为两级:
2-bit L1 Index | 14-bit L2 Index | 16-bit Offset.
- 64 位虚拟地址:
- 实际实现的位数,如 39 位或 48 位。
- 39-bit VA: 页号位数 = \(39 - 16 = 23\) 位。
- 每页最多存放 \(\frac{2^{16}}{8}=2^{13}\) 条 PTE,
- 如用两级:
10-bit L1 | 13-bit L2 | 16-bit Offset.
- 48-bit VA: 页号位数 = \(48 - 16 = 32\) 位。
- ARM64 (page 67) for 48-bit VA with 64KB page shows:
6 (L1) | 13 (L2) | 13 (L3) | 16 (Offset).
- ARM64 (page 67) for 48-bit VA with 64KB page shows: