虚拟内存 (Virtual Memory) ¶
前言 (page 1-3) ¶
本讲义深入探讨了计算机系统中的虚拟内存(Virtual Memory)概念及其在 Linux 系统中的实现细节。虚拟内存作为操作系统核心功能之一,旨在解决物理内存的限制、多进程隔离与共享、以及内存分配的灵活性问题。
历史回顾与引出 (page 2) ¶
在回顾部分,我们首先提及了以下几个核心概念:
- 逻辑地址与物理地址 (Logical vs physical address): 进程看到的是逻辑地址空间,而实际硬件访问的是物理地址空间。虚拟内存系统负责完成两者之间的转换。
- 内存分配 (Memory allocation):
- 连续分配 (Contiguous allocation): 包括首次适应 (first-fit)、最佳适应 (best-fit) 和最差适应 (worst-fit) 等策略。
- 碎片化 (Fragmentation): 连续分配容易导致内部碎片 (internal fragmentation) 和外部碎片 (external fragmentation)。
- 分页 (Paging): 将逻辑地址划分为页号 (page number) 和页内偏移 (page offset),将物理内存划分为大小相等的帧 (frame)。
- 页表结构: 层级页表 (hierarchical page table)、哈希页表 (hashed page table) 和倒排页表 (inverted page table)。
- 页表遍历 (Page table walk): 访问页表以完成地址转换的过程。
- 交换 (Swapping): 当物理内存不足时,将内存中的部分进程或页面暂时移到磁盘上。
- 内存管理单元 (MMU) (Memory Management Unit): 负责地址转换的硬件组件。
- 翻译后备缓冲区 (TLB) (Translation Lookaside Buffer): MMU 内部的缓存,用于加速地址转换。
章节大纲 (page 3) ¶
本次讨论将围绕以下主题展开:
- 请求调页 (Demand Paging)
- 写时复制 (Copy-on-write)
- 页面置换算法 (Page replacement algorithm)
- 帧分配 (Allocation of frames)
- 颠簸 (Thrashing)
- Linux 内存管理 (Linux memory management)
虚拟内存基础 (page 4-9, VM-2 page 6-11) ¶
引入背景 (page 4-5) ¶
程序的代码和数据通常只有一部分在执行时是活跃的。例如,错误处理代码、不常用的例程或大型数据结构可能很少被用到。如果一个程序必须完全加载到内存中才能执行,这将限制程序的规模,并导致内存资源的浪费。
虚拟内存的核心思想是将逻辑内存 (logical memory) 与物理内存 (physical memory) 分离。这种分离带来了以下优势:
- 部分加载程序: 程序无需完全加载即可执行,只需加载所需的部分。
- 更大的地址空间: 进程的逻辑地址空间可以远大于可用的物理地址空间。
- 并发运行更多程序: 减少了每个程序所需的物理内存,从而可以并发运行更多程序。
- 减少 I/O 操作: 仅在需要时才将页面加载到内存,减少了不必要的 I/O 和进程交换 (swapping) 开销。
- 内存共享: 允许内存区域(如共享库)在多个进程之间共享,提高了进程间通信(IPC)性能。
- 高效的进程创建: 支持写时复制 (Copy-on-Write) 机制,优化了
fork()操作的效率。
虚拟内存通常通过分页机制实现。
虚拟内存 (Virtual Memory)
虚拟内存是一种内存管理技术,它将进程的逻辑地址空间与物理地址空间解耦。它允许程序使用一个比实际物理内存大得多的地址空间,并使得多个程序可以共享同一物理内存而互不干扰。虚拟内存的实现依赖于硬件(MMU)和操作系统。
虚拟地址空间 (Virtual-address Space) (page 6-7, VM-2 page 10-11) ¶
虚拟地址空间是程序可以访问的一系列逻辑地址。它通常设计成:
- 栈 (Stack) 从逻辑地址的最大端开始向“下”增长。
- 堆 (Heap) 从较低地址开始向“上”增长。
两者之间存在一个“空洞”(hole
- 最大化了地址空间的利用率。
- 实现了稀疏地址空间 (sparse address spaces),为动态链接库等提供了增长空间。
- 允许多个进程共享系统库,通过将库映射到各自的虚拟地址空间实现。
- 在进程创建(如
fork())时,通过写时复制 (Copy-on-Write) 机制实现页面的共享,从而加快了进程创建速度。
共享库示例 (page 8-9)
在虚拟内存系统中,多个进程可以共享同一个物理内存区域(例如共享库
假设 Process 1 和 Process 2 都需要使用 shared library。在没有虚拟内存的情况下,每个进程都需要拥有 shared library 的独立副本。但在虚拟内存中:
shared library的代码和数据只存储在物理内存中的一组共享页面 (shared pages) 里。Process 1和Process 2的各自虚拟地址空间中,都有一个区域被映射到这些物理的共享页面。- 这样,即使在虚拟地址空间中
shared library可能位于不同的虚拟地址,它们实际都指向相同的物理内存。
这种机制显著减少了内存占用,并提高了系统效率。
内存管理单元 (MMU) (VM-2 page 12-14, 53-57) ¶
内存管理单元 (MMU) 是负责实现虚拟内存地址转换的硬件组件。它通常位于 CPU 核心和内存之间,或者集成在物理 CPU 本身。
内存管理单元 (MMU)
MMU 是一个硬件组件,用于在 CPU 访问内存时,将程序生成的虚拟地址 (virtual address) 实时翻译成对应的物理地址 (physical address)。它还负责处理内存访问权限和页错误。
MMU 的主要功能包括:
- 地址翻译: 将虚拟地址映射到物理 RAM 或内存映射的外设硬件(如 PCI 设备、GPU RAM、片上系统 IP 块
) 。 - 权限处理: 检查内存访问是否符合页表条目 (Page Table Entry, PTE) 中定义的权限(读、写、执行
) 。 - 异常生成: 当检测到无效内存访问(未映射地址或权限不足)时,生成一个页错误 (page fault) 异常。
翻译后备缓冲区 (TLB) (Translation Lookaside Buffer) (VM-2 page 14) ¶
MMU 内部包含一个高速缓存,称为翻译后备缓冲区 (TLB)。
翻译后备缓冲区 (TLB)
TLB 是 MMU 内部的一个硬件缓存,用于存储最近使用的虚拟地址到物理地址的映射关系(即页表条目
TLB 的特点:
- 存储映射: TLB 存储虚拟地址到物理地址的映射,并包含权限位。
- 加速访问: 当 CPU 访问一个虚拟地址时,MMU 首先查询 TLB。如果找到匹配项(TLB 命中
) ,则直接获取物理地址,无需访问主内存中的页表。 - 有限资源: TLB 的大小是有限的,它只能缓存部分页表条目。当所需映射不在 TLB 中时(TLB 缺失
) ,MMU 会执行页表遍历来获取映射,并可能将新映射加载到 TLB 中。
请求调页 (Demand Paging) (page 10-11, 20-29, VM-2 page 15-16, 58-64) ¶
请求调页原理 (page 10) ¶
请求调页 (Demand Paging) 是一种虚拟内存技术,它只在真正需要(被访问,即读或写)时才将页面从二级存储(通常是磁盘)加载到物理内存中。
- 按需加载: 当一个页面被“请求”时(即 CPU 尝试访问它
) ,它才会被加载。 - 无效页: 如果尝试访问的页面在页表中标记为无效 (invalid),通常会导致操作中止(错误
) 。 - 有效但未加载页: 如果页面有效但当前不在物理内存中(通过页表中的“有效 - 无效位” (valid-invalid bit) 判断
) ,则会触发页错误 (page fault)。- 页错误处理: 操作系统会将该页面从磁盘(对于已交换的页面)或通过文件映射(对于新页面)加载到物理内存中。
- 优点: 避免了不必要的 I/O,减少了内存需求,提高了系统能够运行的应用程序数量,但可能引入响应延迟。
页错误 (Page Fault) (page 11-14, 17-19, VM-2 page 15) ¶
页错误是一种 CPU 异常,发生在(用户态)程序尝试访问一个无效的虚拟地址时,由 MMU 发现并发出,由操作系统处理。主要有三种情况:
- 虚拟地址未映射: 进程请求的虚拟地址根本没有对应的页表映射。这通常是编程错误,例如访问了未分配的内存,MMU 检查其在
vm_area(虚拟内存区域)之外,会触发错误并可能终止进程。 - 权限不足: 进程对请求的地址没有足够的访问权限(例如,尝试写入只读页面
) 。 - 有效但未在物理内存中: 虚拟地址有效,但对应的页面当前不在物理内存中,而是被换出 (swapped out) 到磁盘上。这是最常见的页错误类型,也是请求调页的核心。
MMU 通过页表中的有效 - 无效(或存在)位 (valid-invalid/present bit) 来判断物理帧是否已映射。
v(valid) 表示帧已映射到物理内存。i(invalid) 表示帧未映射。- 初始时,所有页表条目的有效 - 无效位都设置为
i。 - 在地址转换过程中,如果 MMU 发现某个条目为
i,就会触发页错误。
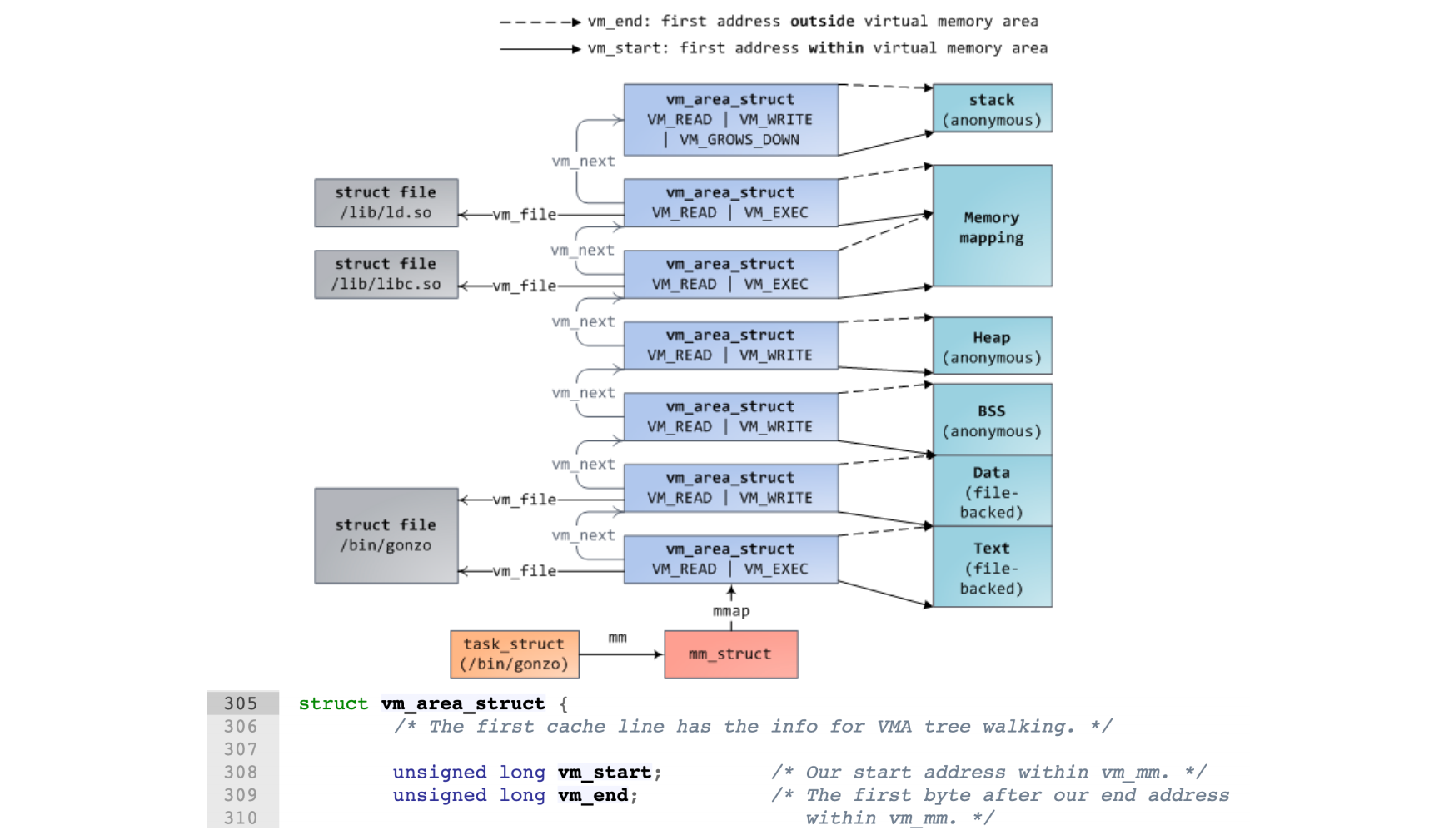
VM_Area¶
在 mm_struct 中储存一个 vma 链表头指针,链表存储着“承诺”分发给程序的地址范围。
页错误处理流程 (Page Fault Handling) (page 18-19, 23-25) ¶
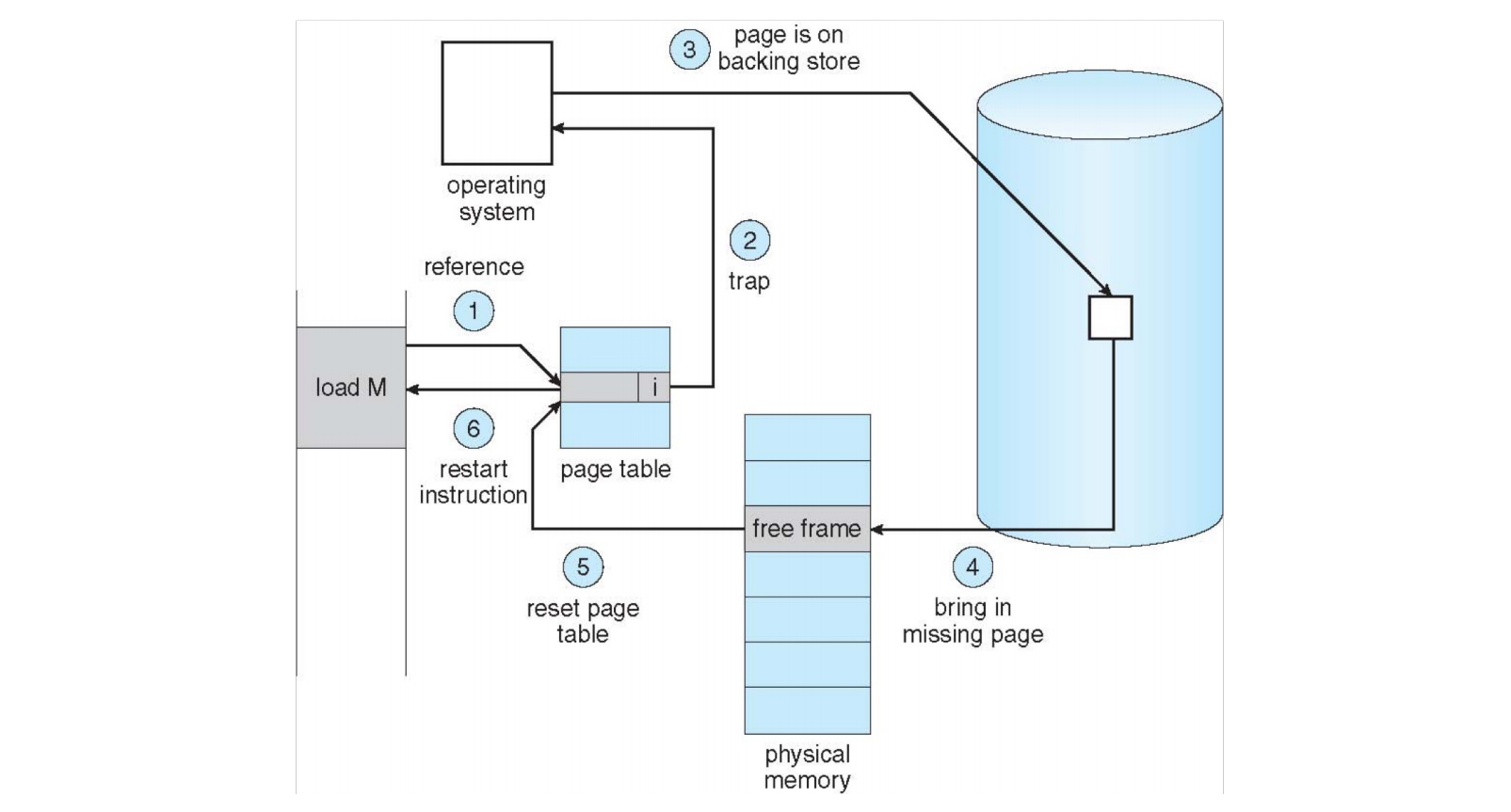
当发生页错误时,操作系统会接管处理 (page 23-34):
- 陷入操作系统 (Trap to the operating system)。
- 保存用户寄存器和进程状态 (Save user registers and process state)。
- 判断中断类型 (Determine that the interrupt was a page fault)。
- 检查页面引用是否合法(例如,地址是否在进程的虚拟内存区域
vm_area内) 。
- 检查页面引用是否合法(例如,地址是否在进程的虚拟内存区域
- 查找空闲帧 (Find a free frame, page 22)。
- 操作系统维护一个空闲帧列表 (free-frame list) 以满足此类请求。
- 如果列表为空,则需要执行页面置换 (page replacement) 来选择一个牺牲帧。
- 确定页面位置并发出 I/O 请求 (Determine the location of the page on the disk, issue a read from the disk to the free frame)。
- 等待设备队列,等待寻道 / 延迟时间。
- 开始将页面传输到空闲帧。
- CPU 分配给其他进程 (While waiting, allocate the CPU to other process)。在等待磁盘 I/O 完成期间,操作系统会将 CPU 分配给其他就绪进程,以提高 CPU 利用率。
- 接收 I/O 完成中断 (Receive an interrupt from the disk I/O subsystem)。
- 确认中断来自磁盘。
- 将页错误进程标记为就绪。
- 等待 CPU 再次分配给该进程 (Wait for the CPU to be allocated to this process again)。
- 保存其他进程的寄存器和状态。
- 进行上下文切换。
- 更新页表 (Correct the page table)。将新加载的页面映射到物理帧,并设置页表条目的有效 - 无效位为
v。 - 返回用户空间 (Return to user)。恢复用户寄存器、进程状态和新的页表,然后重新执行导致页错误的指令。
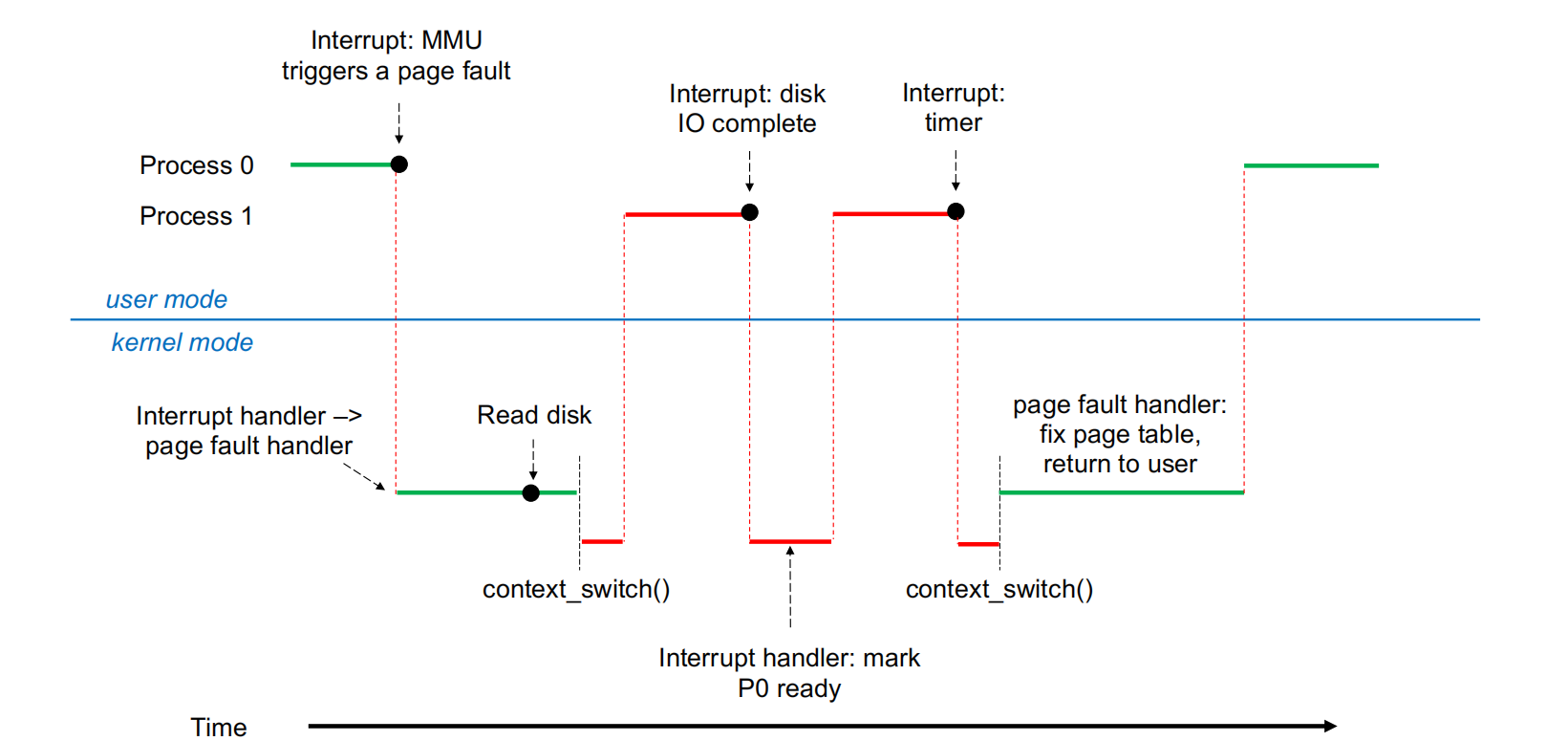
页错误处理时序 (page 25)
假设 Process 0 发生页错误:
- 在用户模式下,
Process 0运行,MMU 触发页错误。 - 系统进入内核模式,页错误处理程序开始执行。
- 页错误处理程序发出磁盘读取请求,将所需页面从磁盘加载到内存。
- 在等待磁盘 I/O 期间,操作系统进行上下文切换,将 CPU 分配给
Process 1。 Process 1运行,直到磁盘 I/O 完成并触发中断。- 系统再次进入内核模式,磁盘 I/O 完成中断处理程序标记
Process 0为就绪。 - 可能再次发生上下文切换,CPU 重新分配给
Process 0。 Process 0的页错误处理程序完成页表更新,然后将控制权返回给Process 0,并重新执行导致页错误的指令。
有效访问时间 (Effective Access Time, EAT) (page 26-27) ¶
页错误会显著增加内存访问时间。我们可以通过有效访问时间来量化其影响。
有效访问时间 (Effective Access Time, EAT)
EAT 是指在考虑页错误开销的情况下,平均一次内存访问所需的时间。它反映了虚拟内存系统(特别是请求调页)的性能。
公式: $\(EAT = (1 - p) \times \text{memory access} + p \times (\text{page fault overhead} + \text{swap page out} + \text{swap page in} + \text{instruction restart overhead})\)$
其中:
- \(p\): 页错误率 (page fault rate),\(0 \le p \le 1\)。
- \(p = 0\): 无页错误。
- \(p = 1\): 每次访问都发生页错误。
- memory access: 正常内存访问时间。
- page fault overhead: 页错误处理的纯开销(如中断处理、页表查找)。
- swap page out: 如果需要置换出脏页,将其写回磁盘的时间。
- swap page in: 将所需页面从磁盘读入内存的时间。
- instruction restart overhead: 重新执行导致页错误指令的开销。
EAT 计算示例 (page 27)
假设: - 内存访问时间:200 纳秒 (ns) - 平均页错误服务时间:8 毫秒 (ms) = 8,000,000 ns
\(EAT = (1 - p) \times 200 + p \times 8,000,000\) \(EAT = 200 - 200p + 8,000,000p\) \(EAT = 200 + 7,999,800p\)
如果每 1,000 次访问中发生一次页错误,即 \(p = 1/1,000 = 0.001\): \(EAT = 200 + 7,999,800 \times 0.001 = 200 + 7999.8 = 8199.8 \text{ ns} \approx 8.2 \text{ 微秒} (\mu s)\)
性能影响: 正常内存访问时间是 0.2 微秒,而发生页错误后是 8.2 微秒,导致性能下降了 \(8.2 / 0.2 = 41,000\) 倍!这表明即使是很低的页错误率也会对系统性能产生巨大影响。
如果我们希望性能下降不超过 10%(即 EAT 小于 \(200 \times 1.1 = 220 \text{ ns}\)
这意味着,为了维持可接受的性能,每 400,000 次内存访问中发生页错误的次数必须少于 1 次。
请求调页优化 (page 28-29) ¶
为了优化请求调页的性能:
- 交换空间 I/O 优化: 交换空间(swap space)的 I/O 通常比文件系统 I/O 更快,即使它们位于同一设备上。这是因为交换空间通常以更大的块进行分配,且管理开销较少。在一些旧的 BSD Unix 系统中,整个进程镜像在加载时就会被复制到交换空间,后续的页面置换都在交换空间中进行。
- 页面丢弃 (Discarding Pages):
- 对于从程序二进制文件(可执行文件)中请求调入的页面,当其帧被释放时,可以直接丢弃 (discard) 而不是写回交换空间。因为这些页面是程序的原始代码或数据,其副本仍然存在于文件系统中,下次需要时可以重新从文件系统加载。
- 但以下情况仍需要写回交换空间:
- 与文件无关的页面(如栈和堆
) ,被称为匿名内存 (anonymous memory)。 - 在内存中被修改但尚未写回文件系统的页面(即脏页 (dirty pages)
) 。
- 与文件无关的页面(如栈和堆
- 移动系统中的页面管理: 移动系统通常不支持交换,而是直接从文件系统请求调页,并回收只读页面(如代码
) 。
写时复制 (Copy-on-Write, COW) (page 30-32) ¶
写时复制 (COW) 是一种优化进程创建(尤其是 fork() 系统调用)的机制。
写时复制 (Copy-on-Write, COW)
写时复制允许父进程和子进程在初始阶段共享相同的内存页面。只要这些页面未被修改,它们就保持共享。只有当其中任何一个进程试图修改共享页面时,操作系统才会为该进程创建一份该页面的独立副本,从而实现了“写时复制”的效果。
COW 的优势:
- 高效的进程创建: 避免了在
fork()时复制整个父进程的内存,大大减少了进程创建的开销。只有被修改的内存才会被复制。 - 延迟复制: 页面复制被延迟到实际写入操作发生时。
vfork 系统调用 (page 30)
vfork 是一个历史悠久的系统调用,旨在优化子进程立即调用 exec() 的情况。
- 父进程会被挂起,直到子进程退出或调用 exec()。
- 子进程与父进程共享资源,包括堆和栈。
- 子进程不能从函数返回或调用 exit(),而应该调用 _exit()。
- vfork 可能会带来一些脆弱性问题,它是在 COW 尚未普遍实现时发明的一种优化手段。在现代系统中,由于 COW 的高效性,vfork 的使用已经减少。
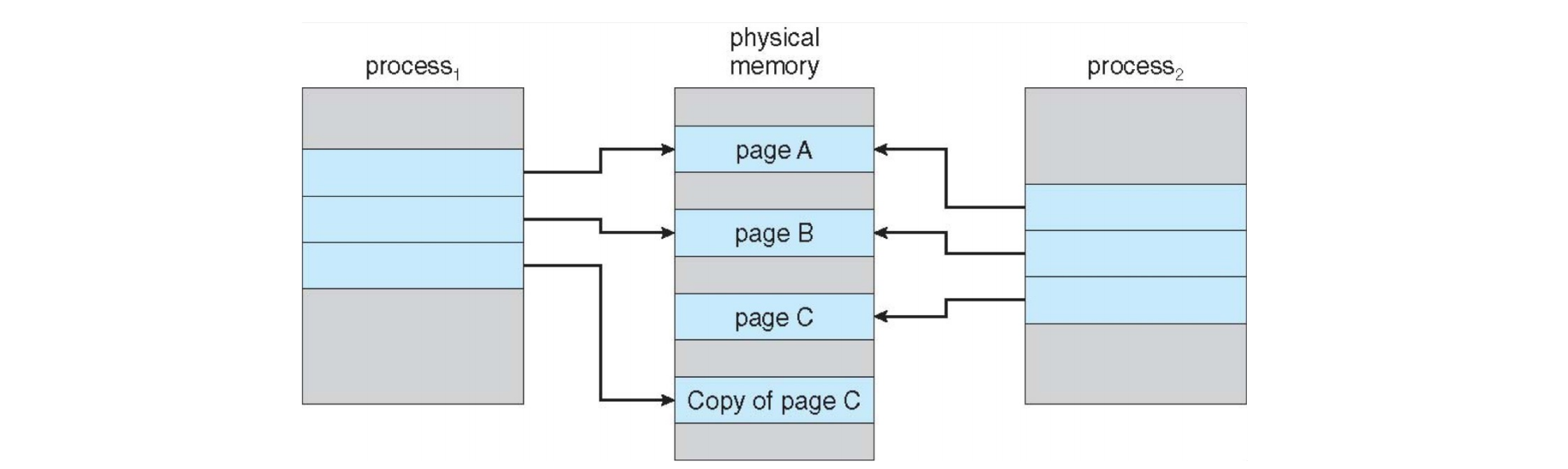
COW 示例 (page 31-32)
-
复制前 (Before Process 1 Modifies Page C) (page 31):
Process 1和Process 2都共享physical memory中的page A、page B和page C。它们的页表都指向相同的物理帧。
-
复制后 (After Process 1 Modifies Page C) (page 32):
- 当
Process 1尝试修改page C时,MMU 会检测到这是一个共享页面且正要被写入。 - 操作系统介入,为
Process 1创建一个page C的副本 (Copy of page C) 到一个新的物理帧。 Process 1的页表条目被更新,指向这个新的副本。Process 2的页表条目仍指向原始的page C物理帧,不受影响。- 现在,
Process 1可以在其私有副本上进行修改,而Process 2仍然访问原始的共享数据。
- 当
页面置换 (Page Replacement) (page 33-54) ¶
页面置换的必要性 (page 33-34) ¶
当系统物理内存(帧)不足以满足新页面请求时,需要执行页面置换 (page replacement),通常是 page fault handler 的一部分。
- 问题: 进程页面、内核需求、I/O 缓冲区等都会占用内存。当没有足够的空闲帧时,操作系统必须从内存中选择一个页面“牺牲”,将其移出内存,为新页面腾出空间。
- 挑战: 如何选择牺牲页面?是终止进程还是将页面换出?
- 目标: 页面置换算法的目标是最大程度地减少页错误数量。
- 脏位 (Dirty Bit): 操作系统通常使用修改位(脏位) (modified/dirty bit) 来优化置换。只有被修改过的页面才需要写回磁盘,干净页面可以直接丢弃。
- 意义: 页面置换是实现逻辑内存与物理内存分离的关键机制,它使得大型虚拟内存可以在较小的物理内存上运行。
页面置换流程 (page 35-37)
- 页错误发生: 进程访问的页面不在内存中(页表中的
valid-invalid bit为i) 。 - 查找空闲帧: 操作系统尝试从空闲帧列表中获取一个空闲帧。
- 选择牺牲页面: 如果没有空闲帧,则根据页面置换算法选择一个牺牲页面。
- 如果牺牲页面是“脏的”(已被修改
) ,则需要将其写回磁盘(swap out victim page) ,并将其页表条目标记为无效 (change to invalid)。
- 如果牺牲页面是“脏的”(已被修改
- 加载新页面: 将发生页错误的所需页面从后备存储(backing store)读入选定的物理帧(
bring in missing page) 。 - 更新页表: 更新页表条目,将其标记为有效 (
v),并指向新的物理帧。 - 重新执行指令: 重新执行导致页错误的指令。
注意: 如果涉及牺牲脏页,一次页错误可能导致两次 I/O 操作(写出牺牲页,读入新页
页面置换算法 (Page Replacement Algorithms) (page 38) ¶
页面置换算法的目标是在第一次访问和后续访问时都具有最低的页错误率。评估算法时,需要给定一个内存引用串 (reference string)(一系列页面号
内存引用串示例 (page 38)
本讲义中的示例内存引用串:7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
1. 先进先出 (First-In-First-Out, FIFO) (page 40-42) ¶
FIFO 算法替换最先加载到内存中的页面。
- 工作原理: 像一个队列,新页面加入队尾,当需要替换时,移除队头页面。
- 优点: 实现简单。
- 缺点: 性能可能不佳,因为最老的页面可能是最常用的页面。
FIFO 算法示例 (page 40)
引用串:7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1,分配 3 个帧。
7:[7, -, -]-> Page Fault (PF)0:[7, 0, -]-> PF1:[7, 0, 1]-> PF2:[2, 0, 1](7 replaced) -> PF0:[2, 0, 1]-> Hit3:[2, 3, 1](0 replaced) -> PF0:[2, 3, 0](1 replaced) -> PF4:[4, 3, 0](2 replaced) -> PF2:[4, 2, 0](3 replaced) -> PF3:[4, 2, 3](0 replaced) -> PF0:[0, 2, 3](4 replaced) -> PF3:[0, 2, 3]-> Hit0:[0, 2, 3]-> Hit3:[0, 2, 3]-> Hit2:[0, 2, 3]-> Hit1:[0, 1, 3](2 replaced) -> PF2:[0, 1, 2](3 replaced) -> PF0:[0, 1, 2]-> Hit1:[0, 1, 2]-> Hit7:[7, 1, 2](0 replaced) -> PF0:[7, 0, 2](1 replaced) -> PF1:[7, 0, 1](2 replaced) -> PF
总共 15 次页错误。
Belady 现象 (Belady's Anomaly) (page 40-42)
对于 FIFO 算法,增加可用的物理帧数量有时会导致更多的页错误。这种反常现象被称为 Belady 现象。
示例 (page 42):引用串 1,2,3,4,1,2,5,1,2,3,4,5
- 分配 3 个帧时,产生 9 次页错误。
- 分配 4 个帧时,产生 10 次页错误。
Belady 现象说明 FIFO 算法并非总是最优的,其性能可能因内存帧数量的变化而恶化。
2. 最优算法 (Optimal Algorithm) (page 43) ¶
最优页面置换算法 (Optimal Page Replacement Algorithm) 替换在未来最长时间内不会被使用的页面。
- 工作原理: 理想情况下,选择未来最久不用的页面进行置换。
- 考虑一个队列
- 优点: 保证最低的页错误率。
- 缺点: 无法实现。因为它需要预知未来的内存引用,这在实际系统中是不可能的。
- 用途: 作为评估其他算法性能的基准(上限
) 。
最优算法示例 (page 43)
引用串:7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1,分配 3 个帧。
7:[7, -, -]-> PF0:[7, 0, -]-> PF1:[7, 0, 1]-> PF2:[7, 0, 2](1 replaced, 1 是未来最久不用的 ) -> PF0:[7, 0, 2]-> Hit3:[3, 0, 2](7 replaced, 7 是未来最久不用的 ) -> PF0:[3, 0, 2]-> Hit4:[3, 0, 4](2 replaced, 2 是未来最久不用的 ) -> PF2:[2, 0, 4](3 replaced, 3 是未来最久不用的 ) -> PF3:[2, 0, 3](4 replaced, 4 是未来最久不用的 ) -> PF0:[2, 0, 3]-> Hit3:[2, 0, 3]-> Hit0:[2, 0, 3]-> Hit3:[2, 0, 3]-> Hit2:[2, 0, 3]-> Hit1:[2, 0, 1](3 replaced, 3 是未来最久不用的 ) -> PF2:[2, 0, 1]-> Hit0:[2, 0, 1]-> Hit1:[2, 0, 1]-> Hit7:[7, 0, 1](2 replaced, 2 是未来最久不用的 ) -> PF0:[7, 0, 1]-> Hit1:[7, 0, 1]-> Hit
总共 9 次页错误。这个结果比 FIFO (15 次 ) 少,且对于给定引用串,最优算法产生的页错误次数是最少的。
3. 最近最少使用 (Least Recently Used, LRU) (page 44-46) ¶
LRU 算法替换最长时间未被使用的页面。
- 工作原理: 基于历史数据预测未来,认为过去最久未使用的页面,未来也很可能不会被使用。
- 和 FIFO 差不多,但是在如果 hit ,需要将该页放到队列末尾去
- 优点: 通常是效果较好的算法,并且不具有 Belady 现象。
- 缺点: 实现复杂,需要维护页面使用的时间戳或访问顺序。
LRU 算法示例 (page 44)
引用串:7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1,分配 3 个帧。
7:[7, -, -]-> PF ( 最近使用 : 7)0:[7, 0, -]-> PF ( 最近使用 : 0)1:[7, 0, 1]-> PF ( 最近使用 : 1)2:[2, 0, 1](7 replaced, 7 最久未使用 ) -> PF ( 最近使用 : 2)0:[2, 0, 1](0 被访问,0 是最近使用 ) -> Hit ( 最近使用 : 0)3:[2, 3, 1](0 replaced, 0 最久未使用 , 但 0 被访问了,现在最久未使用是 1) -> PF ( 最近使用 : 3) - 这里需要注意 LRU 的实际实现:如果 0 被访问了,它会成为最近使用的。此时帧里是[2, 0, 1],最近使用顺序0-2-1。要置换,应该置换 1。所以是[2, 0, 3]。 - 重新追溯:7:[7, -, -](7) -> PF0:[7, 0, -](0) -> PF1:[7, 0, 1](1) -> PF2:[2, 0, 1](2) -> PF (7 被替换 )0:[2, 0, 1](0) -> Hit (0 最近使用 )3:[2, 0, 3](3) -> PF (1 被替换 )0:[2, 0, 3](0) -> Hit (0 最近使用 )4:[4, 0, 3](4) -> PF (2 被替换 )2:[4, 2, 3](2) -> PF (0 被替换 )3:[4, 2, 3](3) -> Hit (3 最近使用 )0:[0, 2, 3](0) -> PF (4 被替换 )3:[0, 2, 3](3) -> Hit0:[0, 2, 3](0) -> Hit3:[0, 2, 3](3) -> Hit2:[0, 2, 3](2) -> Hit1:[0, 1, 3](1) -> PF (2 被替换 )2:[0, 1, 2](2) -> PF (3 被替换 )0:[0, 1, 2](0) -> Hit1:[0, 1, 2](1) -> Hit7:[7, 1, 2](7) -> PF (0 被替换 )0:[7, 0, 2](0) -> PF (1 被替换 )1:[7, 0, 1](1) -> PF (2 被替换 )
总共 12 次页错误。比 FIFO 少,但比最优算法多。
LRU 的实现方式:
- 基于计数器 (Counter-based) (page 45):
- 每个页表条目 (PTE) 包含一个计数器。
- 每次页面被引用时,将系统时钟的当前值复制到该计数器。
- 需要替换页面时,查找计数器值最小的页面(最早被访问
) 。 - 可以使用最小堆 (min-heap) 优化查找。
- 基于栈 (Stack-based) (page 45-46):
- 维护一个页面号的栈(通常是双向链表
) 。 - 当页面被引用时,将其从栈中移除并移动到栈顶。
- 需要替换页面时,选择栈底的页面(最久未使用的
) 。 - 每次更新更昂贵(需要链表操作
) ,但无需搜索即可找到牺牲页面。
- 维护一个页面号的栈(通常是双向链表
4. LRU 近似算法 (LRU Approximation Implementations) (page 47-51) ¶
由于精确实现 LRU(无论是基于计数器还是栈)的开销很高,硬件通常提供引用位 (reference bit) 来近似实现 LRU。
-
引用位算法:
- 每个页面关联一个引用位,初始为 0。
- 当页面被硬件引用时,硬件将引用位设置为 1。
- 当需要替换页面时,查找引用位为 0 的页面。如果存在,就替换它。
- 缺点: 无法知道引用位为 0 的页面中,哪个是最久未使用的。它只能告诉我们页面最近是否被使用过。
-
附加引用位算法 (Additional-Reference-Bits Algorithm) (page 48):
- 对每个页面维护一个 8 位字节(或更多位)作为使用历史。
- 每隔一个固定的时间间隔(例如 100 毫秒
) ,操作系统会:- 将该字节右移 1 位(丢弃最低位
) 。 - 将当前引用位(由硬件设置)的值设置到最高位。
- 将该字节右移 1 位(丢弃最低位
- 这样,该字节就存储了页面在最近 8 个时间间隔内的使用模式。
- 判断最近使用: 比较两个字节的数值,数值越大表示最近被使用得越多。例如,
01110111比11000100更久未被使用(因为它的高位1出现得更早,后续又长期未被引用导致右移) 。
-
二次机会算法 (Second-chance / Clock replacement Algorithm) (page 49-50):
- 它是 FIFO 的一种改进,结合了引用位。
- 将所有页面组织成一个循环队列 (circular queue),并维护一个指针
next victim指向下一个可能被替换的页面。 - 当需要替换页面时,检查
next victim指向页面的引用位:- 如果引用位为 0,则替换该页面。
- 如果引用位为 1,则将引用位清零,然后移动指针到下一个页面,重复上述过程。这个页面获得了“二次机会”,因为其近期被使用过。
-
增强型二次机会算法 (Enhanced Second-Chance Algorithm) (page 51):
- 该算法结合了引用位和修改位 (modified bit) 来做出更明智的置换决策。
- 将页面的状态分为四类有序对
(reference, modify):(0, 0): 未被使用且未被修改——最佳替换页面。(0, 1): 未被使用但已被修改——不那么好,需要写回磁盘,但至少近期未被使用。(1, 0): 最近被使用但未被修改——可能很快再次使用,且不需要写回。(1, 1): 最近被使用且已被修改——最差的替换页面,可能很快再次使用且需要写回。
- 置换时,按照
(0,0) -> (0,1) -> (1,0) -> (1,1)的优先级顺序寻找最低优先级的非空类中的页面进行替换。可能需要多次遍历循环队列。
5. 基于计数器的页面置换 (Counting-based Page Replacement) (page 52) ¶
- 最不常用 (Least Frequently Used, LFU): 替换访问计数器最小的页面。
- 问题: 页面在初始化阶段可能被大量访问,然后不再使用,但由于其高计数器值而不会被置换。
- 最常用 (Most Frequently Used, MFU): 替换访问计数器最大的页面。
- 理由: 基于“计数最小的页面很可能是刚加载的,还没来得及被使用”的假设。
- 问题: 实际效果通常不佳。
- LFU 和 MFU 在实际系统中不常用。
页面缓冲算法 (Page-Buffering Algorithms) (page 53) ¶
为了进一步优化页错误处理和页面置换,可以使用页面缓冲算法:
- 空闲帧池 (Pool of Free Frames):
- 操作系统维护一个始终有空闲帧的池。
- 当发生页错误时,可以直接从池中获取帧,无需等待牺牲页面被写回磁盘。
- 这使得页面可以尽快读入内存,并立即恢复指令。
- 被选中的牺牲页面在方便时(例如,磁盘空闲时)才被写出。
- 修改页面列表 (List of Modified Pages):
- 维护一个被修改但尚未写回磁盘的页面列表。
- 当磁盘空闲时,这些脏页可以被异步写回磁盘,并被标记为干净。这样,当它们成为牺牲页面时,就无需额外的写出 I/O。
- 保留空闲帧内容 (Keep Free Frame Contents Intact):
- 已置换出内存的帧(特别是干净的帧)内容可能不立即清零。
- 如果该页面在帧被重新分配给其他用途之前再次被引用,则无需重新从磁盘加载,直接“缓存命中”即可。
双重缓冲 (Double Buffering) (page 54)
内存密集型应用程序有时会因为操作系统和应用程序都进行缓冲而导致双重缓冲 (double buffering),造成内存浪费。 - 操作系统将页面副本保留在 I/O 缓冲区中。 - 应用程序也为自己的工作保留页面的副本。 某些情况下,操作系统可以提供直接访问磁盘的裸磁盘模式 (Raw disk mode),绕过内核缓冲和锁定,减少了这种浪费。
帧分配 (Allocation of Frames) (page 55-57) ¶
每个进程都需要分配一定数量的物理内存帧。
最小与最大帧数 (Minimum and Maximum Frames) (page 55) ¶
- 最小帧数: 每个进程都需要一个最小数量的帧来执行其指令,这取决于指令语义。例如,IBM 370 的 SS MOVE 指令可能需要 6 页(指令本身可能跨 2 页,源和目标各 2 页
) 。 - 最大帧数: 系统的总帧数是上限。
分配方案 (Allocation Schemes) (page 55-56) ¶
- 等量分配 (Equal Allocation):
- 将所有可用帧平均分配给每个进程。
- 例如,100 个帧(除操作系统外
) ,5 个进程,每个进程分 20 个帧。 - 通常会预留一些帧作为空闲帧缓冲区。
- 比例分配 (Proportional Allocation):
- 根据每个进程的大小按比例分配帧。
- 较大的进程获得更多的帧,较小的进程获得较少的帧。
- 会根据多道程序的程度和进程大小动态调整分配。
比例分配公式 (page 56)
假设系统总帧数 \(m\),进程总数 \(n\),进程 \(p_i\) 的大小为 \(s_i\)。
\(S = \sum s_j\) (所有进程的总大小)
分配给进程 \(p_i\) 的帧数 \(a_i = \frac{s_i}{S} \times m\)
示例 : \(m = 62\) 帧,进程 \(p_1\) 大小 \(s_1 = 10\),进程 \(p_2\) 大小 \(s_2 = 127\)。 \(S = 10 + 127 = 137\) \(a_1 = \frac{10}{137} \times 62 \approx 4.5\), 四舍五入为 4 帧。 \(a_2 = \frac{127}{137} \times 62 \approx 57.5\), 四舍五入为 58 帧。
全局置换与局部置换 (Global vs. Local Allocation) (page 57) ¶
- 全局置换 (Global Replacement):
- 进程可以从所有可用帧中选择一个牺牲帧,即使该帧属于另一个进程。
- 优点: 整体吞吐量可能更高,系统资源利用率更灵活。
- 缺点: 单个进程的执行时间可能波动很大,因为它受到其他进程行为的影响。
- 局部置换 (Local Replacement):
- 每个进程只能从其自身分配的帧集中选择牺牲帧。
- 优点: 为每个进程提供更一致的性能。
- 缺点: 可能会导致内存利用率低下(例如,某个进程有很多空闲帧但不能被其他需要内存的进程使用
) 。
页面回收 (Reclaiming Pages) (page 58-60) ¶
为了实现全局页面置换策略,并确保系统始终有足够的空闲内存来满足新请求,操作系统会采取页面回收策略:
- 阈值触发: 当空闲帧列表的数量低于某个阈值 (threshold) 时,就会触发页面置换机制。
- 激进回收: 如果内存低于最小阈值,操作系统可能会激进地回收页面,甚至杀死一些进程(根据 OOM score (Out Of Memory score) 决定哪个进程最有可能被终止
) 。
页面回收示例 (page 59)
自由内存量随着时间波动。 - 当自由内存低于“最低阈值”时,内核开始激进地回收页面 (reclaiming pages)。 - 自由内存量开始回升。 - 当自由内存达到“最高阈值”时,内核暂停页面回收。 - 自由内存量再次下降,循环往复。
主要和次要页错误 (Major and Minor Page Faults) (page 61) ¶
- 主要页错误 (Major Page Fault): 页面被引用,但当前不在内存中,需要从磁盘加载。这是开销最大的页错误。
- 次要页错误 (Minor Page Fault): 页面被引用,但虽然没有对应的页表映射,页面实际上已经在内存中(例如,已加载的共享库页面,或者之前被换出但仍在缓存中的页面
) 。无需磁盘 I/O,只需更新页表。do_anonymous_page(分配匿名内存的机制)通常不被视为主要页错误,因为它通常不涉及从磁盘读取预存在的数据。
共享库的优势 (page 61)
共享库的机制使得即使一个进程的映射不存在,页面也可能已经在内存中(被其他进程使用过或未被完全释放
颠簸 (Thrashing) (page 64-68) ¶
颠簸的定义与原因 (page 64-66) ¶
颠簸 (Thrashing) 是一种严重的性能下降现象,发生在进程的页错误率非常高,导致系统大部分时间都忙于在内存和磁盘之间交换页面,而不是执行有用功。
- 原因: 如果一个进程没有获得“足够”的物理内存帧,它将频繁地发生页错误。
- 每次页错误,它会尝试获取一个新页面,并可能置换出另一个现有页面。
- 但由于分配的帧太少,它很快又会需要之前被置换出去的页面,导致频繁地“换入 - 换出”页面。
- 恶性循环: 低 CPU 利用率 -> 内核认为需要增加多道程序度 (degree of multiprogramming) -> 更多进程加入系统 -> 争用内存更严重 -> 页错误率更高 -> CPU 利用率更低 -> 进一步增加多道程序度 ... 最终系统陷入颠簸状态。
颠簸现象 (page 65)
CPU 利用率随多道程序度的增加而变化。
- 开始时,CPU 利用率随着更多进程的加入而提高。
- 达到某个点后,由于内存争用加剧,页错误率急剧上升,系统开始颠簸。
- 颠簸时,CPU 利用率急剧下降,因为 CPU 大部分时间都在等待 I/O。
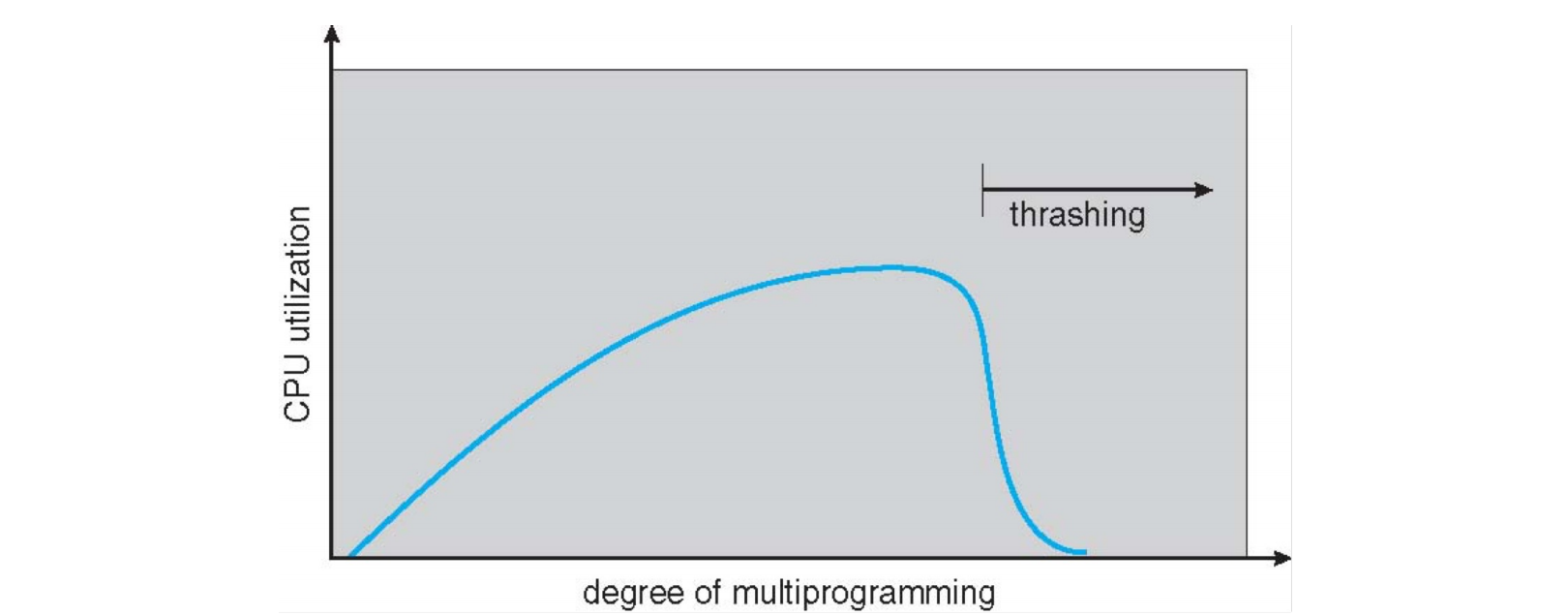
解决颠簸 (Resolve Thrashing) (page 67-68) ¶
解决颠簸的方法通常是确保进程获得足够的帧来满足其局部性 (locality) 需求。
- 使用局部页面置换策略 (Option I) (page 67):
- 限制颠簸的影响范围,一个进程的颠簸不会直接影响其他进程。
- 选择牺牲页面时,只从该进程自身分配的帧中选择。
- 为进程提供足够多的帧 (Option II) (page 68):
- 目标是为进程提供其工作集 (working set) 所需的帧。
- 这意味着操作系统需要追踪进程的内存访问模式。
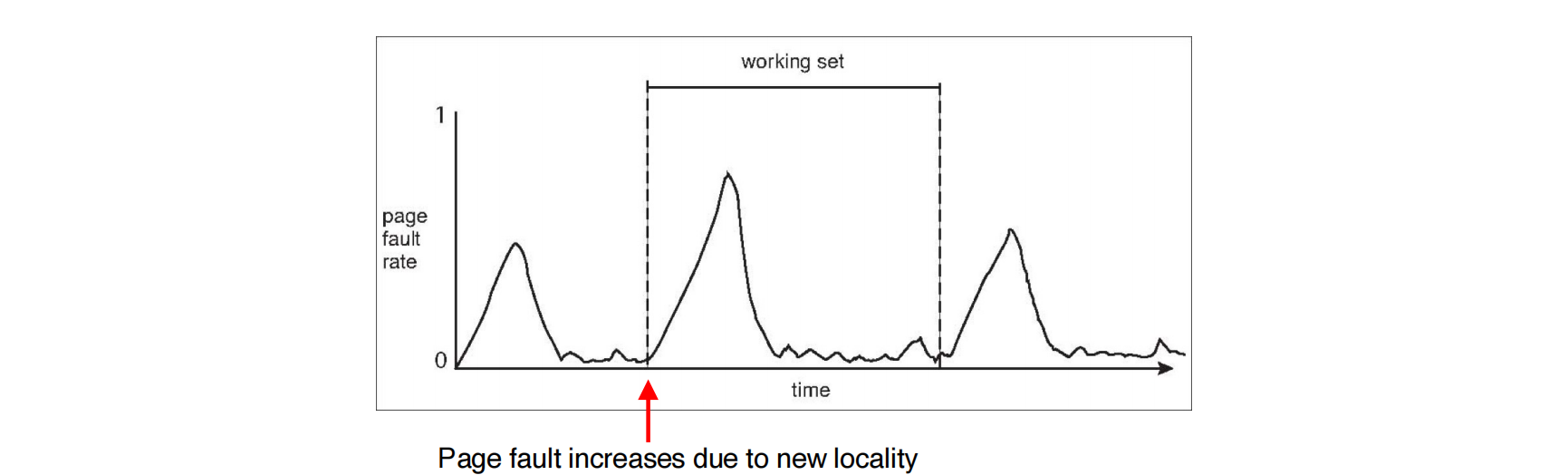
工作集模型 (Working-Set Model) (page 69-70) ¶
工作集模型基于进程的局部性原理 (Principle of Locality),即进程在某个时间段内会频繁访问一部分页面。
工作集 (Working Set)
进程 \(p_i\) 的工作集 \(WSS_i\) 是指在最近 \(\Delta\) 个内存引用中,该进程所引用到的所有唯一页面的集合。
- \(\Delta\) ( 工作集窗口 , working-set window) 是一个固定的时间间隔或页面引用数量。
- 如果 \(\Delta\) 太小,可能无法包含整个局部性集合。
- 如果 \(\Delta\) 太大,可能包含多个局部性集合,甚至整个程序。
- 如果 \(\Delta = \infty\),则包含整个程序。
总工作集: \(D = \sum WSS_i\) 是所有进程当前工作集大小的总和。
- 颠簸的预警: 如果 \(D > m\)(总工作集大小大于可用物理帧数
) ,则存在颠簸的可能性。 - 避免颠簸: 为避免颠簸,如果 \(D > m\),操作系统应该挂起 (suspend) 或换出 (swap out) 某些进程,直到 \(D \le m\)。
工作集模型示例 (page 70)
内存引用串:...,2,6,1,5,7,7,7,5,1,6,2,3,4,1,2,3,4,4,3,4,4,1,3,2,3,4,4,4,3,4,4,...
假设工作集窗口 \(\Delta = 10\)。
- 在时间 \(t_1\) 处,最近 10 次引用是
6,1,5,7,7,7,5,1,6,2。- \(WS(t_1) = \{1,2,5,6,7\}\) (唯一页面
) 。
- \(WS(t_1) = \{1,2,5,6,7\}\) (唯一页面
- 在时间 \(t_2\) 处,最近 10 次引用是
3,4,4,4,3,4,3,4,4,4。- \(WS(t_2) = \{3,4\}\) (唯一页面
) 。
- \(WS(t_2) = \{3,4\}\) (唯一页面
工作集是动态变化的,反映了程序在不同执行阶段的局部性行为。
跟踪工作集的挑战 (page 71) ¶
精确跟踪工作集非常困难。近似方法通常使用间隔计时器和引用位:
- 方法:
- 硬件在页面被访问时设置引用位为 1。
- 操作系统设置一个定时器,每隔 \(\Delta'\) 时间(例如 5000 个时间单位)中断一次。
- 每次中断时,操作系统将每个页面的当前引用位复制到内存中的一个(或多个)专用位中,然后将引用位清零。
- 例如,如果为每个页面保留 2 个内存位 (
bits[0],bits[1]):- 中断时,
bits[1] = bits[0],bits[0] = reference_bit,reference_bit = 0。 - 如果任何一个内存位为 1,则认为页面在工作集中。
- 中断时,
- 不准确性: 这种方法不完全精确,因为它只能记录页面在特定时间间隔内是否被访问过,无法精确判断何时被访问(在 \(\Delta'\) 时间间隔内的哪个时刻
) 。 - 改进: 使用更多的位(例如 10 位)和更频繁的计时器中断(例如每 1000 个时间单位中断一次
) ,可以提供更精细的访问历史,从而更精确地近似 LRU。
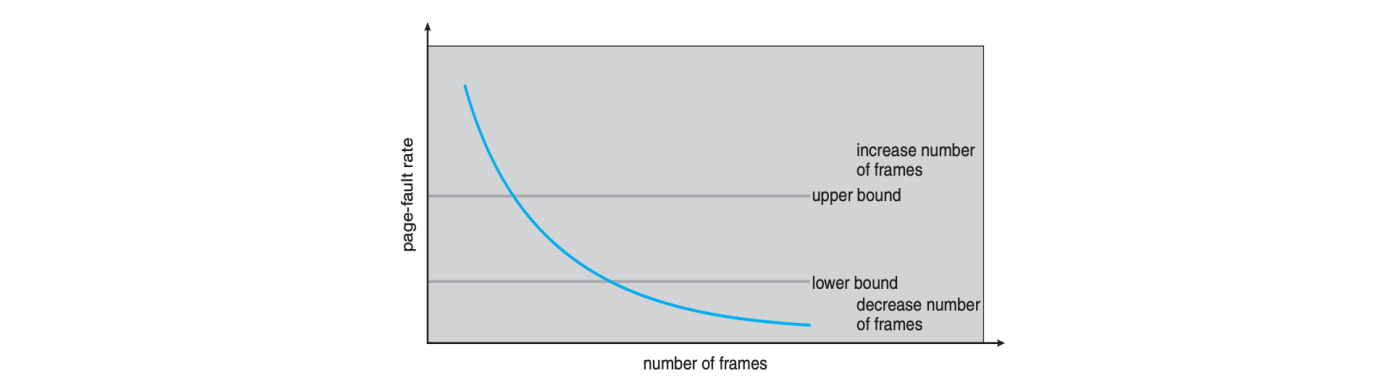
页错误频率 (Page-Fault Rate, PFR) (page 72-73) ¶
页错误频率是比工作集模型更直接的颠簸控制方法。
页错误频率 (Page-Fault Rate, PFR)
页错误频率 PFR 模型通过直接监控进程的页错误率来控制颠簸。操作系统为每个进程设定一个可接受的页错误率范围。
- 如果实际页错误率过低,说明进程分配了过多的帧,可以将其帧数减少。
- 如果实际页错误率过高,说明进程分配的帧太少,需要增加其帧数。
- 如果即使增加了帧数,页错误率仍然居高不下,且没有空闲帧可供分配,则可能需要换出 (swap out) 整个进程。
PFF 模型通过动态调整进程的帧分配来优化系统性能和避免颠簸。
PFR vs. Time
PFR vs. #frame
其他考虑 (Other Considerations) (page 75-80) ¶
预调页 (Prepaging) (page 76) ¶
- 目的: 减少进程启动时大量页错误造成的开销。
- 原理: 在进程需要之前,预先将它可能用到的一些页面(或全部页面)加载到内存中。
- 权衡: 如果预调入的页面最终未被使用,则浪费了 I/O 和内存资源。
- 假设预调入 \(s\) 个页面,其中只有 \(\alpha\) 部分被使用。
- 代价: \(s \times (1 - \alpha)\) 个不必要的页面被加载。
- 如果 \(\alpha\) 接近于零(大部分预调入页面未被使用
) ,则预调页弊大于利。
页大小 (Page Size) (page 77) ¶
操作系统设计者需要根据多种因素选择合适的页大小:
- 碎片:
- 小页可能导致更多的页表条目 (PTE),增加页表大小,并可能导致外部碎片。
- 大页可能导致更多的内部碎片 (internal fragmentation)(如果进程只使用页面的小部分
) 。
- 页表大小: 大页可以减少页表中的条目数量,从而减小页表所需内存。
- 解析度 (Resolution): 小页提供更高的内存分配粒度。
- I/O 开销: 大页可以减少 I/O 操作次数(每次 I/O 传输更多数据
) ,但每次 I/O 的延迟可能更高。 - 页错误次数: 大页可能导致更少的页错误(因为一次加载更多相关数据
) 。 - 局部性: 小页更适合细粒度的局部性,而大页可能将不常用的数据也带入内存。
-
TLB 大小和效率: TLB 的条目数量有限,大页可以提高 TLB 的覆盖范围 (TLB reach),减少 TLB 缺失。
-
实际情况: 页大小通常是 2 的幂次方,范围从 \(2^{12}\) (4KB) 到 \(2^{22}\) (4MB),且平均大小随着时间有增大的趋势。
TLB 覆盖范围 (TLB Reach) (page 78) ¶
TLB 覆盖范围是指 TLB 可以直接访问的内存总量。
- 计算公式:
TLB reach = TLB size × page size - 理想情况: 每个进程的工作集最好能完全存储在 TLB 中,否则会频繁发生 TLB 缺失。
- 优化: 增加页大小可以增大 TLB 覆盖范围,从而减少 TLB 缺失。
- 缺点: 增加页大小可能导致碎片化增加,因为并非所有应用程序都需要大页。
- 解决方案: 允许多种页大小 (multiple page sizes),应用程序可以根据需求选择,既能利用大页减少 TLB 压力,又能避免不必要的碎片。
程序结构 (Program Structure) (page 79) ¶
程序的数据访问模式对页错误数量有显著影响。
程序结构对页错误的影响 (page 79)
考虑一个 int data[128][128] 的二维数组。假设页大小为 512B,且每行数据(128 个整数,每个 4B,共 512B)恰好存储在一个页面中。系统可用物理帧少于 127 个。
程序 1 ( 列优先访问 ):
每次内层循环 i 迭代时,data[i][j] 会访问不同行(不同页面
程序 2 ( 行优先访问 ):
每次外层循环 i 迭代时,内层循环 j 访问的是同一行(同一页面)内的所有元素。因此,每行只需一次页错误即可将整个页面加载到内存。
结果:128 次页错误(每次外层循环仅发生一次页错误)。
这个例子清晰地说明了局部性和程序数据访问模式对页错误性能的巨大影响。
I/O 互锁和页面锁定 (I/O Interlock and Page Locking) (page 80) ¶
在某些情况下,内存页面必须被锁定 (locked) 在内存中,不能被页面置换算法选中并换出。这被称为 I/O 互锁 (I/O Interlock) 或页面锁定 (page locking)。
- 场景: 当进行 I/O 操作(如将文件从设备复制到内存缓冲区)时,涉及的页面必须保持在物理内存中。如果这些页面在 I/O 期间被置换出去,会导致数据损坏或 I/O 失败。
- 机制: 操作系统会暂时禁用这些页面的页面置换,直到 I/O 操作完成。
Linux 内存管理 (Linux Memory Management) (page 82-90, VM-2 page 17-52, 65-68) ¶
Linux 中的虚拟地址 (Virtual Addresses in Linux) (VM-2 page 17-23, 34-39) ¶
Linux 系统中的虚拟地址空间被划分为两个主要部分:
- 用户空间 (User Space): 供用户进程使用。
- 内核空间 (Kernel Space): 供操作系统内核使用。
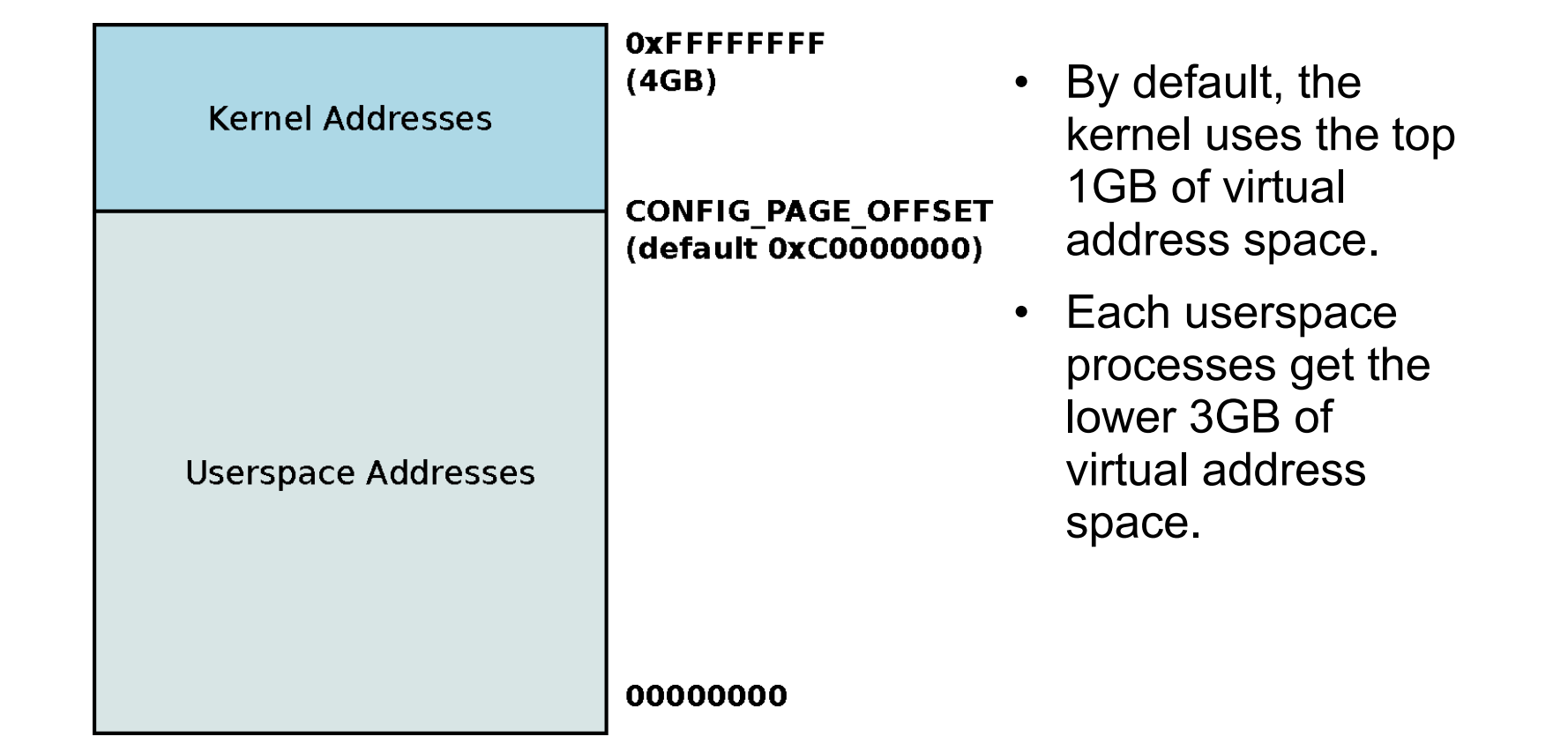
32 位系统 (VM-2 page 17-19) ¶
- 地址分割: 默认情况下,在 32 位 Linux 系统中,虚拟地址空间在
0xC0000000处分割(即 3GB 标记) 。- 用户虚拟地址: 下方 3GB (
0x00000000到0xBFFFFFFF) 分配给用户进程。每个进程都有自己独立的 3GB 虚拟地址空间映射,并在上下文切换时改变。 - 内核地址: 上方 1GB (
0xC0000000到0xFFFFFFFF) 供内核使用。
- 用户虚拟地址: 下方 3GB (
64 位系统 (VM-2 page 21-23) ¶
- 更大的地址空间: 在 64 位系统上,内核地址空间远大于物理内存,因此不再存在 32 位系统中物理内存大于内核线性映射地址空间的问题。
- 配置:
- ARM64: 通常使用 48 位页表,支持 4 级页表(9+9+9+9+12 位
) ,可映射高达 256TB 的虚拟地址空间。 - x86_64: 同样使用 4 级页表,虚拟地址范围从
0xffff000000000000开始。
- ARM64: 通常使用 48 位页表,支持 4 级页表(9+9+9+9+12 位
- 页面配置:
- Linux 支持 4KB、2MB、1GB 等不同大小的页面(
pgtable-nopud.h) 。
- Linux 支持 4KB、2MB、1GB 等不同大小的页面(
Linux 中的物理 RAM 映射 (VM-2 page 24-32) ¶
内核需要管理物理 RAM,包括为用户进程分配物理帧。为此,内核必须将物理 RAM 映射到自己的地址空间。
内核逻辑地址 (Kernel Logical Addresses) (VM-2 page 26-28) ¶
- 线性映射: 内核逻辑地址是直接线性映射到物理地址的虚拟地址。
- 在 32 位系统中,这部分地址从
PAGE_OFFSET(默认0xC0000000)开始,线性映射物理内存。通常是前 896MB 的物理 RAM。 - 这种线性偏移映射使得物理地址和虚拟地址之间的转换非常容易,通过简单的加减操作即可完成(例如
__pa(x)和__va(x)宏) 。
- 在 32 位系统中,这部分地址从
- 适用性: 对于物理 RAM 较小的系统(低于 1GB
) ,这部分线性映射足以覆盖所有物理内存。
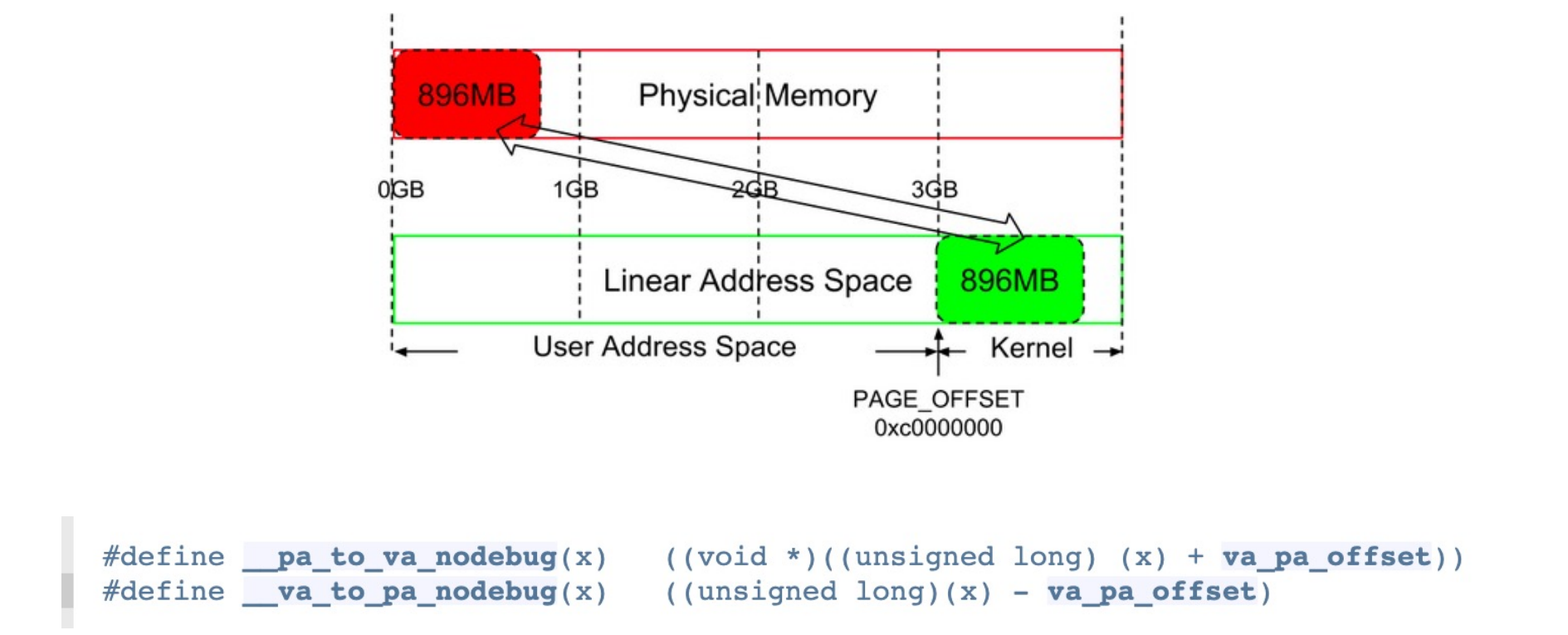
大型物理 RAM 的处理 (VM-2 page 29-32) ¶
- 非线性映射: 对于大型内存系统(超过 1GB
) ,并非所有的物理 RAM 都能被线性映射到内核逻辑地址空间中。 - 内核虚拟地址 (Kernel Virtual Addresses):
- 为了访问这些不能线性映射的物理内存,内核使用了内核虚拟地址。这部分地址位于内核逻辑地址映射区域之上。
- 这些地址用于非连续内存映射 (non-contiguous memory mappings),例如大型缓冲区,这些缓冲区可能无法获得物理连续的内存区域。
- 这部分区域也常被称为
vmalloc()区域,因为vmalloc()函数用于分配这样的非连续内核内存。
- 64 位系统: 在 64 位系统中,由于内核虚拟地址空间足够大(ARM 64 位系统可达 512GB 甚至 256TB
) ,物理 RAM 通常远小于内核虚拟地址空间,因此不再需要区分“高端内存”的概念,所有物理内存都可以被内核直接映射。
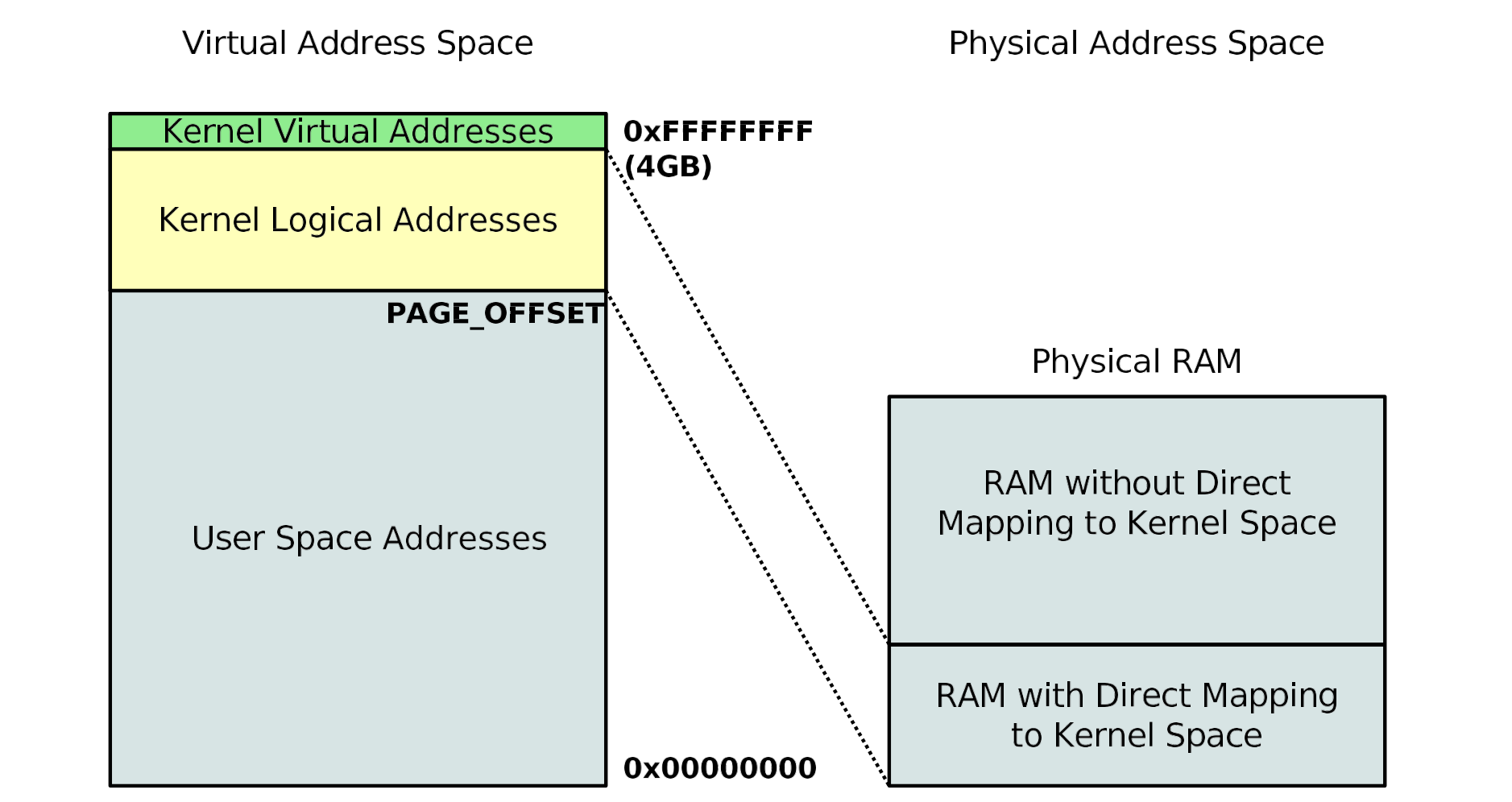
Linux 内存管理概览 (VM-2 page 35-39) ¶
Linux 内存管理涉及到三种主要虚拟地址:
- 用户虚拟地址 (User virtual address): 每个用户进程拥有独立的虚拟地址空间,虚拟上连续但物理上不连续。
- 内核逻辑地址 (Kernel logical address): 虚拟上和物理上都连续的地址。
- 内核虚拟地址 (Kernel virtual address): 虚拟上连续但物理上不连续的地址(例如
vmalloc区域) 。
Linux 虚拟地址类型
| 地址类型 | 虚拟上连续性 | 物理上连续性 | 用途 |
|---|---|---|---|
| 用户虚拟地址 | 是 | 否 | 用户进程的内存空间 |
| 内核逻辑地址 | 是 | 是 | 内核直接线性映射的物理内存 |
| 内核虚拟地址 | 是 | 否 | 内核非连续分配,如大缓冲区 |
Linux 惰性分配 (Lazy Allocation) (VM-2 page 59-61, 64) ¶
Linux 内核采用惰性分配 (Lazy Allocation) 策略来分配物理内存:
- 延迟分配: 当用户空间程序请求内存时(例如通过
malloc()或sbrk()扩展堆) ,内核并不会立即分配物理帧并更新 TLB。 - 仅创建记录: 内核只会创建该请求的记录,并快速返回给进程。
- 页错误触发实际分配: 只有当该进程实际触及 (touch) 这些新分配的虚拟地址时,CPU 才会触发页错误。
- 页错误处理: 在页错误处理程序中,内核会判断该访问是否合法,然后分配物理帧,更新页表,并返回控制权给用户程序,让其重新执行指令。
- 优化: 这种优化特别适用于那些分配了大量内存但实际只使用其中一小部分的程序(例如缓冲区
) ,避免了不必要的物理内存分配。
预触页 (Pre-faulting) (VM-2 page 64)
对于时间敏感的进程,可能需要在程序启动时就将数据预触页 (pre-faulted) 或加载到内存中,以避免运行时的页错误延迟。可以使用 mlock() 和 mlockall() 等系统调用来实现。
Linux 内存分配器 (Linux Memory Allocators) (page 84-90) ¶
Linux 内核为了高效管理不同大小的内存请求,使用了多种内存分配器:
1. Buddy System ( 伙伴系统 ) (page 84-85) ¶
- 原理: 一种基于 2 的幂次方块的内存分配器。
- 分配过程: 当请求到来时,如果可用块的大小不匹配,则将大块内存递归地分裂成两个“伙伴”块,直到找到合适大小的块。
- 回收过程: 当块被释放时,它会检查其伙伴块是否也空闲。如果空闲,则合并成更大的块,以减少外部碎片。
- 优点: 快速合并空闲块,减少外部碎片。
- 缺点: 内部碎片 (internal fragmentation)。例如,请求 21KB,分配 32KB 的块,浪费 11KB。
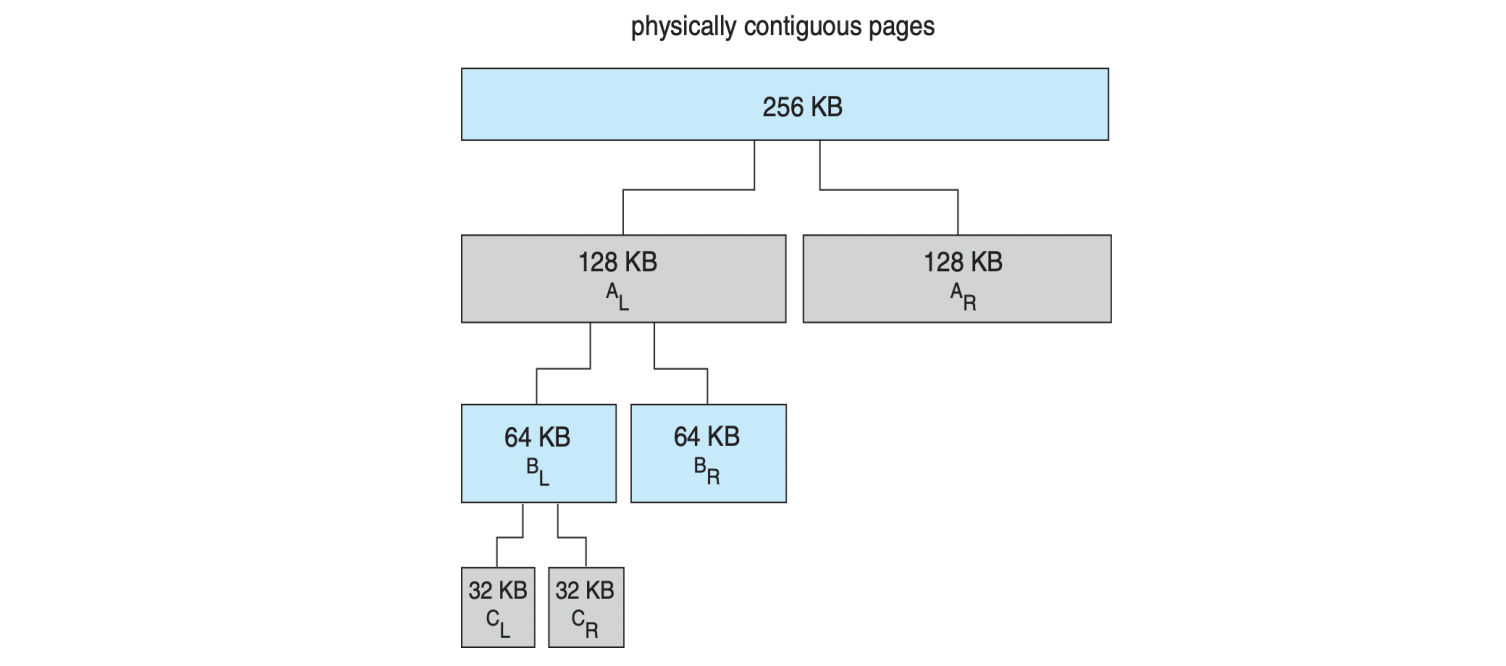
Buddy System 示例 (page 84-85)
假设请求 21KB 内存,只有一个 256KB 的物理连续块可用:
- 将 256KB 分裂为两个 128KB 的伙伴 (A_L, A_R)。
- 选择其中一个 128KB 块(例如 A_L
) ,将其分裂为两个 64KB 的伙伴 (B_L, B_R)。 - 选择其中一个 64KB 块(例如 B_L
) ,将其分裂为两个 32KB 的伙伴 (C_L, C_R)。 - 将其中一个 32KB 块(例如 C_L)分配给 21KB 的请求。
释放时,如果 C_L 释放,会检查 C_R 是否空闲。如果 C_R 也空闲,两者合并回 64KB 的 B_L。B_L 再检查 B_R,以此类推。
2. Slab Allocator (Slab 分配器 ) (page 86-89) [todo] ¶
- 目的: 解决伙伴系统在频繁分配和释放小对象(如内核数据结构)时造成的内部碎片和性能开销。
- 原理: 为每种独特的内核数据结构(例如
struct task_struct)维护一个独立的缓存 (cache)。- 一个缓存由一个或多个Slab组成。
- 一个 Slab 包含一个或多个物理连续的页面,这些页面被划分为等大小的对象 (objects)。
- 内核数据结构的实例就是从这些 Slab 的空闲对象中分配。
- 优点:
- 无碎片: 避免了内部碎片,因为对象大小与分配单元精确匹配。
- 快速分配: 直接从预分配的对象池中获取,避免了伙伴系统的分裂 / 合并操作。
- 对象重用: 释放的对象可以被重用,无需重新初始化部分字段。
Slab Allocation 示例 (page 87)
假设需要分配 3KB 的对象。一个 12KB 的 Slab ( 由 3 个 4KB 页面组成 ) 可以存储 4 个 3KB 对象。
Slab 的状态: - Full: 所有对象都被使用。 - Empty: 所有对象都空闲。 - Partial: 部分对象被使用,部分空闲。
分配请求: 1. Slab 分配器首先在 Partial 状态的 Slab 中查找空闲对象。 2. 如果 Partial Slab 中没有空闲对象,则从 Empty Slab 中获取。 3. 如果也没有 Empty Slab,则创建新的空 Slab(从伙伴系统获取页面)。
Linux Slab 分配器演进 (page 90) ¶
- Slab 分配器最初由 Solaris 引入,现在广泛用于各种操作系统的内核和用户空间内存管理。
- Linux 早期版本(2.2)使用了 SLAB,现在同时支持 SLOB 和 SLUB。
- SLOB: 针对内存受限系统,维护三个链表用于小、中、大对象。
- SLUB: 性能优化的 SLAB 版本,移除了每 CPU 队列,并尽可能将元数据存储在页面结构本身,减少了内存开销和锁争用。
总结 (Summary) (page 91-92) ¶
本讲义全面回顾了虚拟内存的核心概念和技术:
- 页错误: 当访问的虚拟地址未映射或页面不在物理内存中时触发的异常。
- 页面置换: 在内存不足时,选择牺牲页面并将其移出内存的机制。
- FIFO: 先进先出,可能存在 Belady 现象。
- Optimal: 最优,理论基准,无法实现。
- LRU: 最近最少使用,常用且性能较好,无 Belady 现象。
- Second-chance: 二次机会算法,LRU 的近似实现。
- 颠簸: 进程因频繁页错误而导致系统性能急剧下降的现象。
- 工作集: 进程在特定时间窗口内活跃访问的页面集合,用于避免颠簸。
- 伙伴系统: 一种基于 2 的幂次方块的物理内存分配器,用于管理大块内存。
- Slab 分配器: 为内核对象提供高效、无碎片的内存分配机制,通过缓存预分配的对象。
通过这些机制,虚拟内存使得操作系统能够高效地管理内存资源,支持多任务并发,并为应用程序提供一个独立、庞大且受保护的地址空间。