文件系统 (File System) ¶
本文档将深入探讨文件系统的概念、接口、访问方法、目录结构、保护机制及其底层实现细节,涵盖文件系统的历史演进、数据结构、块分配策略、空闲空间管理以及性能优化和恢复机制。
文件系统接口 (File System Interface) ¶
复习 (Review) (page 2-7)
在深入文件系统之前,我们简要回顾一下操作系统的基础概念,特别是关于存储和输入 / 输出 (I/O) 的知识:
- 大容量存储器 (Mass storage):硬盘、固态硬盘等非易失性存储设备。
- 磁盘结构 (Disk structure):物理组成部分,如盘片、磁道、扇区等。
- 磁盘调度 (Disk scheduling):优化磁盘读写请求顺序的算法,包括先来先服务 (FCFS)、最短寻道时间优先 (SSTF)、扫描 (SCAN)、循环扫描 (C-SCAN)、查找 (LOOK) 和循环查找 (C-LOOK) 等。
- I/O 硬件 (IO hardware):连接到系统总线上的各种输入 / 输出设备。
- I/O 访问 (IO access):设备访问方式,如轮询 (polling) 和中断 (interrupt)。
- 设备类型 (Device types):不同类型的硬件设备及其特性。
- 内核 I/O 子系统 (Kernel IO subsystem):操作系统内核中负责管理 I/O 操作的部分。
我们已经有了大容量存储和 I/O 机制,但如何有效地使用它们呢?早期计算机科学家在 1950 年代可能会直接使用磁盘。然而,直接使用磁盘(例如,按磁道 / 扇区寻址)对于用户和应用程序来说过于复杂和不便。
文件系统 (File System) 的引入解决了这一问题,它为用户进程提供了磁盘的抽象 (abstraction):
- 文件系统提供了对磁盘的抽象视图,将物理存储单元(磁道 / 扇区)抽象为逻辑存储单元——文件 (File)。
- 对于用户进程而言,文件系统提供了一个连贯的、统一的文件集合视图。
- 在 Unix 系统中,文件通常被视为一个连续的字节块 (contiguous block of bytes)。
- 文件系统还提供了保护 (protection) 机制,以控制对文件的访问权限。
抽象 (Abstraction, page 6)
抽象是计算机科学中的一个核心概念,旨在隐藏复杂性并提供更简洁、更易于理解的接口。在文件系统中,它将底层复杂的磁盘物理存储细节(如磁道、扇区、物理地址)抽象为用户友好的文件和目录概念。
类似的抽象在计算机系统中无处不在:
- 中央处理器 (CPU) 被抽象为进程 (Process) 或线程 (Thread)。
- 内存 (Memory) 被抽象为地址空间 (Address Space)。
- 存储 (Storage) 被抽象为文件 (File)。
文件概念 (File Concept) (page 8) ¶
文件 (File)
文件是用于存储信息的连续逻辑空间 (contiguous logical space),可以是数据库、音频、视频、网页等任何类型的信息。
文件可以分为不同的类型:
- 数据文件 (Data files):
- 字符 (character):例如文本文件。
- 二进制 (binary):例如编译后的程序、图片等。
- 应用程序特定 (application-specific):由特定应用程序定义和使用的数据格式。
- 程序文件 (Program files):可执行代码。
- 特殊文件 (Special files):例如
/proc文件系统,它通过文件系统接口来检索系统信息,但其内容并不存储在磁盘上,而是由内核动态生成。
文件属性 (File Attributes) (page 9) ¶
文件通常具有以下属性,这些信息保存在目录结构中并由磁盘维护:
- 名称 (Name):唯一的用户可读名称。
- 标识符 (Identifier):文件系统内识别文件的唯一标签(数字
) 。 - 类型 (Type):在支持不同文件类型的系统中用于区分文件。
- 位置 (Location):指向设备上文件位置的指针。
- 大小 (Size):当前文件大小。
- 保护 (Protection):控制谁可以进行读、写、执行等操作。
- 时间、日期和用户标识 (Time, date, and user identification):用于保护、安全和使用监控的数据(例如,文件创建时间、最后修改时间、最后访问时间、所有者、所属组等
) 。
Linux 上的文件信息 (page 10)
在 Linux 中,可以使用 ls -l 命令查看文件的详细信息,这些信息正是文件的属性。
wenbo@wenbo-Virtual :~/os-course$ ls main.c
main.c: C source, ASCII text
wenbo@wenbo-Virtual :~/os-course$ file a.out
a.out: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=e8385a23e08804a95f2d49dee91d6de43407ffdc, for GNU/Linux 3.2.0, not stripped
wenbo@wenbo-Virtual :~/os-course$ stat a.out
File: a.out
Size: 15960 Blocks: 32 IO Block: 4096 regular file
Device: 803h/2051d Inode: 3670041 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1000/ wenbo) Gid: ( 1000/ wenbo)
Access: 2022-12-15 11:29:38.536299736 +0800
Modify: 2022-11-24 14:35:14.406255682 +0800
Change: 2022-11-24 14:35:14.406255682 +0800
Birth: 2022-11-24 14:35:14.390247501 +0800
从上述输出中,我们可以看到:
- File: a.out:文件名。
- Size: 15960:文件大小(字节)。
- Blocks: 32:文件占用的块数。
- IO Block: 4096:I/O 块大小,通常与文件系统块大小一致(4KB)。
- regular file:文件类型。
- Device: 803h/2051d:文件所在设备号。
- Inode: 3670041:文件的 i-node 编号,文件在文件系统中的唯一标识。
- Links: 1:硬链接数。
- Access: (0775/-rwxrwxr-x):文件权限,八进制表示为 0775,对应符号表示为 -rwxrwxr-x。
- Uid: ( 1000/ wenbo) 和 Gid: ( 1000/ wenbo):文件所有者 ID 和所属组 ID。
- Access, Modify, Change, Birth:文件的各种时间戳,包括最后访问时间、最后修改时间、i-node 状态改变时间以及创建时间。
这些属性提供了关于文件内容的元数据 (metadata),而不是文件内容本身。
文件操作 (File Operations) (page 11) ¶
操作系统提供了一系列文件操作的系统调用 (system calls),以便应用程序能够管理文件:
- 创建 (create):
- 在文件系统中找到可用的空间。
- 在目录中分配一个条目。
- 打开 (open):
- 大多数文件操作都需要先打开文件。
- 返回一个文件句柄 (handler) 或文件描述符 (file descriptor),用于后续操作。
- 读 / 写 (read/write):
- 需要维护一个文件指针 (file pointer) 来指示当前读写位置。
- 重定位 (reposition) / 寻道 (seek):
- 改变文件指针在文件内的位置。
- 关闭 (close):
- 释放文件占用的资源。
- 删除 (delete):
- 释放文件占用的磁盘空间。
- 对于硬链接 (hardlink) 的文件,系统会维护一个引用计数 (reference count),只有当所有硬链接都被删除且引用计数为零时,文件才会被物理删除。
- 截断 (truncate):
- 清空文件内容,但保留其属性。
其他一些文件操作可以通过上述基本操作组合实现,例如:
- 复制 (Copying):通过
create一个新文件,然后read源文件并write到新文件来实现。
打开文件管理 (Open Files) (page 12) ¶
为了管理当前打开的文件,操作系统需要维护一些数据结构:
- 打开文件表 (Open-file table):跟踪所有当前打开的文件。这是一个系统范围的表。
- 文件指针 (File pointer):每个进程都有一个独立的文件指针,记录该进程上次读写操作的位置。这样,多个进程可以独立地读写同一个文件。
- 文件打开计数 (File-open count):一个计数器,记录文件被打开的次数。当这个计数器变为零时,表示没有进程再使用该文件,此时可以将其从系统范围的打开文件表中移除。
- 文件磁盘位置 (Disk location of the file):包含数据访问信息的缓存,用于快速定位文件块。
- 访问权限 (Access rights):每个进程打开文件时的访问模式信息,例如只读、读写等。
文件锁 (File Locks) (page 13) ¶
一些文件系统提供文件锁 (file lock) 机制,用于协调对文件的并发访问:
- 锁的类型 (Two types of lock):
- 共享锁 (Shared lock):多个进程可以并发获取共享锁,允许同时进行读操作。
- 排他锁 (Exclusive lock):只有一个进程可以获取排他锁,用于写操作,防止其他进程同时读写。
- 锁机制 (Two locking mechanisms):
- 强制锁 (Mandatory lock):系统强制执行锁,如果进程违反锁规则,访问将被拒绝。
- 建议锁 (Advisory lock):进程可以检查锁的状态,并根据建议自行决定是否访问。系统不强制执行,依赖于应用程序的协作。
文件类型 (File Types) (page 14) ¶
文件类型通常通过以下两种方式识别:
- 文件扩展名 (file extension):作为文件名的一部分,例如
.txt、.docx、.jpg等。这是操作系统和用户识别文件类型最常见的方式。 - 文件魔数 (magic number of the file):文件开头的一小段特定字节序列,用于标识文件格式。例如,可执行文件 (ELF, Executable and Linkable Format) 通常有特定的魔数。这种方式比扩展名更可靠,因为扩展名可以随意更改。
常见文件类型及其功能 (page 14)
| 文件类型 | 常见扩展名 | 功能 |
|---|---|---|
| executable | exe, com, bin 或 none | 准备运行的机器语言程序 |
| object | obj, o | 编译后的机器语言,未链接 |
| source code | c, cc, java, pas, asm, a | 各种语言的源代码 |
| batch | bat, sh | 命令解释器的命令 |
| text | txt, doc | 文本数据,文档 |
| word processor | wp, tex, rtf, doc | 各种文字处理格式 |
| library | lib, a, so, dll | 程序员的例程库 |
| print or view | ps, pdf, jpg | 用于打印或查看的 ASCII 或二进制文件格式 |
| archive | arc, zip, tar | 分组到单个文件中的相关文件,有时压缩或存储 |
| multimedia | mpeg, mov, rm, mp3, avi | 包含音频或 A/V 信息的二进制文件 |
文件结构 (File Structure) (page 15) ¶
文件可以有不同的内部结构,这通常由操作系统或程序决定:
- 无结构 (No structure):
- 文件被视为一个字节或字的流。
- 例如,Linux 中的
dump文件。 - 这种是最灵活的,应用程序自行解释文件内容。
- 简单记录结构 (Simple record structure):
- 文件由一系列记录组成,记录可以是固定长度或可变长度。
- 例如,数据库文件。
- 复杂结构 (Complex structures):
- 例如,Word 文档或可重定位程序文件。这些文件内部有复杂的布局和元数据。
通常,用户程序 (user programs) 负责识别和解释文件的内部结构。操作系统提供的是一个通用的字节流接口,而不关心字节流的具体含义。
访问方法 (Access Methods) (page 17) ¶
文件内容可以通过不同的方式进行访问:
- 顺序访问 (Sequential access):
- 按预定的顺序访问元素。
- 对于某些媒体类型,如磁带 (tape),这是唯一的访问模式。
- 通常的操作包括
read_next和write_next。文件指针 (current position,cp) 会自动前进。 - 可以通过
reset操作将文件指针重置到文件开头。- 直接访问 (Direct acc- 以大致相等的时间访问序列中的任意位置的元素,访问时间与
- 也称为随机访问 (random a- 虽然可以通过倒带和快进来模拟磁带上的随机访问,但访问时间会因位置而异。
- 其他方法 (Other methods) (page
- 基于直接访问方法,可以使用索引 (index) 来指向文件的各个块 (bloc- 要查找文件中的记录,首先搜索索引,然后使用指针访问相 - 可能使用多层索引 (multiple layers of index) 来支持更大的文件和更快的查找。
- 直接访问 (Direct acc- 以大致相等的时间访问序列中的任意位置的元素,访问时间与
在直接访问文件上模拟顺序访问 (page 19)
即使是直接访问文件,也可以通过内部维护一个当前指针 (current position, cp ) 来模拟顺序访问:
| 顺序访问操作 | 直接访问实现 (Current Positioncp ) |
|---|---|
reset |
cp = 0; |
read next |
read cp; cp = cp + 1; |
write next |
write cp; cp = cp + 1; |
目录结构 (Directory Structure) ¶
磁盘与文件系统 (Disk and file system) (page 22) ¶
磁盘可以被划分为多个分区 (partitions),分区也称为小型磁盘 (minidisks) 或切片 (slices)。
- 不同的分区可以拥有不同的文件系统。
- 包含文件系统的分区被称为卷 (volume)。每个卷都维护一个包含文件系统信息的内容表 (table of contents)。
- 文件系统可以是通用目的的,也可以是特殊目的的。
- 磁盘或分区也可以被原始使用 (raw),即不包含文件系统。某些应用程序(如数据库)更倾向于直接访问原始磁盘,以获得更好的性能控制。
典型文件系统组织 (page 23)
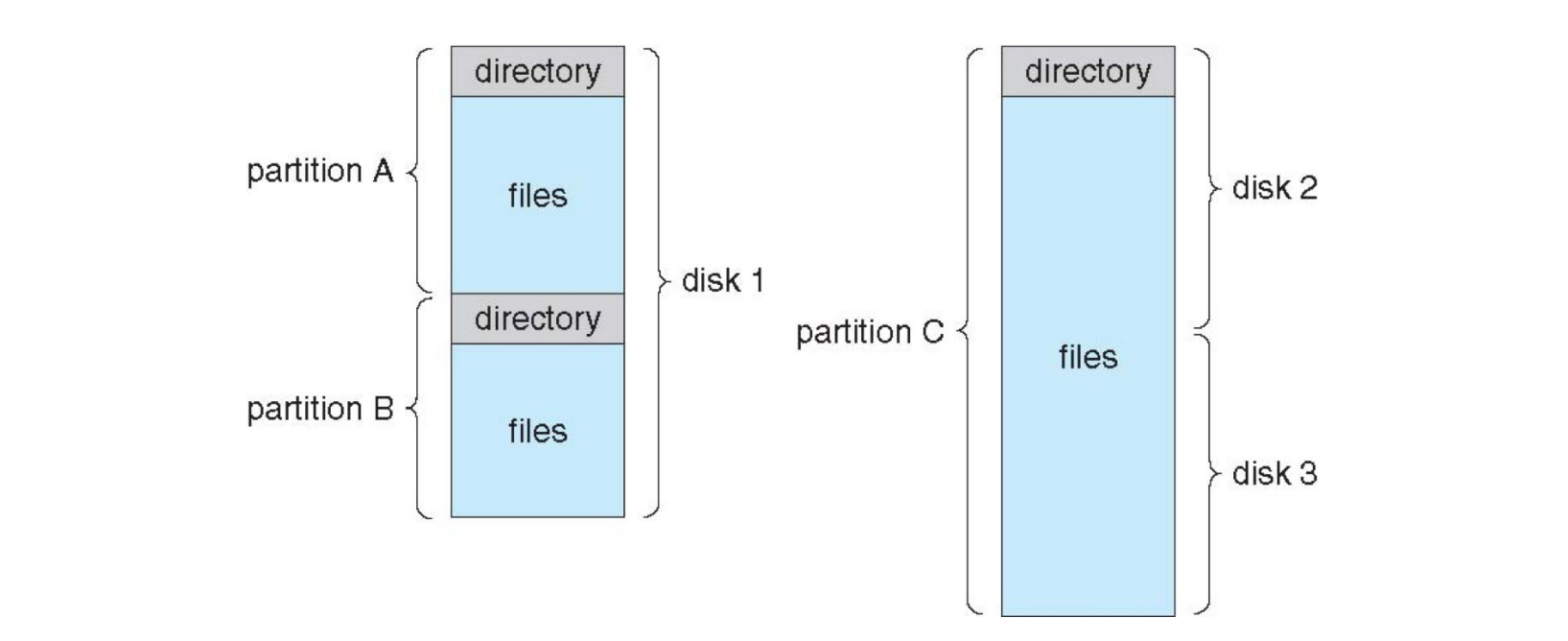
上图展示了典型的文件系统组织方式: - Disk 1 被划分为
partition A和partition B。每个分区都有自己的directory和files。 - Disk 2 和 Disk 3作为一个整体的partition C,也包含一个directory和files。这意味着一个物理磁盘可以包含多个独立的文件系统,或者一个文件系统可以横跨整个物理磁盘。
目录结构概述 (Directory Structure Overview) (page 24) ¶
目录 (Directory)
目录是包含所有文件信息的节点的集合。
目录结构和文件本身都存储在磁盘上。目录条目通常包含文件名和指向文件实际数据的指针(或文件标识符,如 i-node 编号
目录操作 (Operations Performed on Directory) (page 25) ¶
对目录进行的操作通常包括:
- 创建文件 (Create a file):在新创建文件时,需要在目录中为其分配一个条目。
- 删除文件 (Delete a file):从目录中移除文件条目。
- 列出目录 (List a directory):列出目录中包含的所有文件和子目录。
- 搜索文件 (Search for a file):在目录中按文件名模式匹配查找文件。
- 遍历文件系统 (Traverse the file system):访问目录中的所有文件和子目录。
目录组织 (Directory Organization) (page 26) ¶
组织目录结构主要有两个目标:
- 效率 (Efficiency):快速定位文件。
- 命名 (Naming):提供方便用户的文件命名和组织方式
- 两个用户可以拥有同名的不同文件
- 同一个文件可以拥有多个不同的名称(通过链接实现
) 。
单级目录 (Single-Level Directory) (page 27) ¶
单级目录 (Single-Level Directory)
单级目录是所有用户共享一个唯一的目录,所有文件都存储在这个目录中。
问题 (Problems):
- 命名冲突 (Naming problems):不同用户可能想要使用相同的文件名,导致冲突。
- 分组问题 (Grouping problems):所有文件都在同一个目录下,难以进行逻辑分组和管理。
两级目录 (Two-Level Directory) (page 28) ¶
两级目录 (Two-Level Directory)
两级目录为每个用户创建一个独立的目录。顶层是主文件目录 (Master File Directory, MFD),它包含用户文件名到用户文件目录 (User File Directory, UFD) 的映射;每个 UFD 包含该用户的文件。
特点 (Features):
- 为每个用户提供单独的目录。
- 不同用户可以拥有同名的不同文件,解决了命名冲突问题。
- 搜索效率更高,因为只需要在用户自己的 UFD 中搜索。
挑战 (Challenge):
- 如何实现不同用户之间文件的共享?这引出了“路径概念”的需求。
树形结构目录 (Tree-Structured Directories) (page 29-31) ¶
树形结构目录 (Tree-Structured Directories)
树形结构目录将文件组织成树状结构,根目录为树的根,子目录和文件为节点。
优点 (Advantages):
- 高效搜索 (efficient in searching):通过目录路径可以快速定位文件。
- 文件分组 (can group files):逻辑上相关的子目录可以包含在一起。
- 方便命名 (convenient naming):允许文件在不同子目录中拥有相同的文件名。
路径名 (Path names):
- 绝对路径名 (absolute path name):从根目录 (
/) 开始的完整路径,例如/home/alice/mail/count。 - 相对路径名 (relative path name):相对于当前工作目录 (current directory,
pwd) 的路径。
操作 (Operations):
- 创建新文件 (Creating a new file):
touch <file-name> - 删除文件 (Delete a file):
rm <file-name> - 创建新子目录 (Creating a new subdirectory):
mkdir <directory-name>- 例如,如果在
/mail目录下执行mkdir count,将创建/mail/count目录。
- 例如,如果在
- 删除目录 (Delete directory):
- 如果目录是空的,删除很简单。
- 如果目录不为空,则有两种处理选项:
- 选项 I:只有当目录为空时才能删除。
- 选项 II:删除目录及其包含的所有文件和子目录(例如
sudo rm -rf /,这是一个危险的命令,会递归删除根目录下所有内容) 。
文件共享 (File Sharing):
- 在纯树形结构中,文件共享是不允许的 (not allowed)。一个文件只能属于一个目录。为了实现共享,需要引入链接 (links)。
非循环图目录 (Acyclic-Graph Directories) (page 32-33) ¶
非循环图目录 (Acyclic-Graph Directories)
非循环图目录允许目录条目 / 文件之间存在链接,从而实现别名 (aliasing)(一个文件有多个名称
问题 (Problem):
- 悬空指针 (Dangling pointer problem):如果原始文件被删除,而其他链接仍然存在,这些链接就变成了悬空指针,指向不再存在的数据。
- 例如,如果
/dict/all被删除,那么/dict/w/list和/spell/words/list可能会成为悬空指针。
- 例如,如果
解决方案 (Solution):
- 反向指针 (back pointers):记录所有指向该实体 (entity) 的指针,这需要一个可变大小的记录来存储。
- 引用计数 (reference counter):记录指向文件或目录的链接数量。只有当引用计数为零时,文件才会被物理删除。
文件共享机制 (Share files):
- 硬链接 (Hardlink):
- 硬链接是目录中的一个条目,它直接关联一个文件。多个硬链接指向同一个 i-node ( 索引节点 ) 。
- 在同一个文件系统内,一个文件可以有多个名称。
- 删除硬链接时,文件本身的引用计数会减少,只有当引用计数减为零时,文件才会被物理删除。
- 软链接 (Softlink) / 符号链接 (Symbolic link / symlink):
- 软链接是一个特殊的文件,其内容是另一个文件的路径名 (path name)。
- 软链接可以指向文件或目录,并且可以跨文件系统边界。
- 软链接的删除不会影响目标文件的引用计数。如果目标文件被删除,软链接会变成悬空链接。
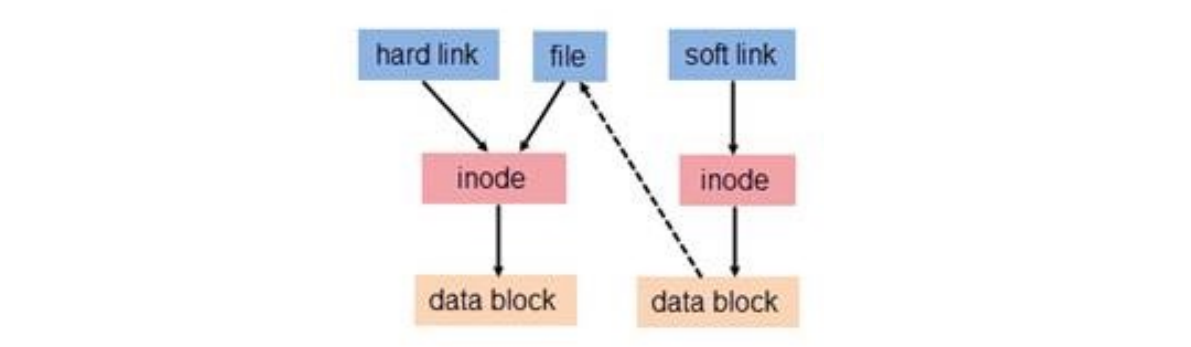
通用图目录 (General Graph Directory) (page 34) ¶
通用图目录 (General Graph Directory)
通用图目录允许任意链接 (arbitrary links),这可能在目录结构中生成循环 (cycles)。
解决方案 (Solution):
- 允许循环存在,但需要使用垃圾回收 (garbage collection) 机制来回收磁盘空间。
- 每次添加新链接时,可以使用循环检测算法 (cycle detection algorithm) 来识别和处理循环。
文件系统挂载 (File System Mounting) (page 35-37) ¶
挂载 (Mounting)
挂载是将一个文件系统附加到系统目录树上的过程,使其内容可被访问。通常,这会形成一个单一的命名空间 (single name space)。
- 挂载点 (mount point):被挂载的文件系统所放置的位置。
- 当文件系统被挂载时,原先存在于挂载点处的目录内容会被覆盖,变得不可见 (invisible),直到该文件系统被卸载。
文件系统挂载示例 (page 36-37)
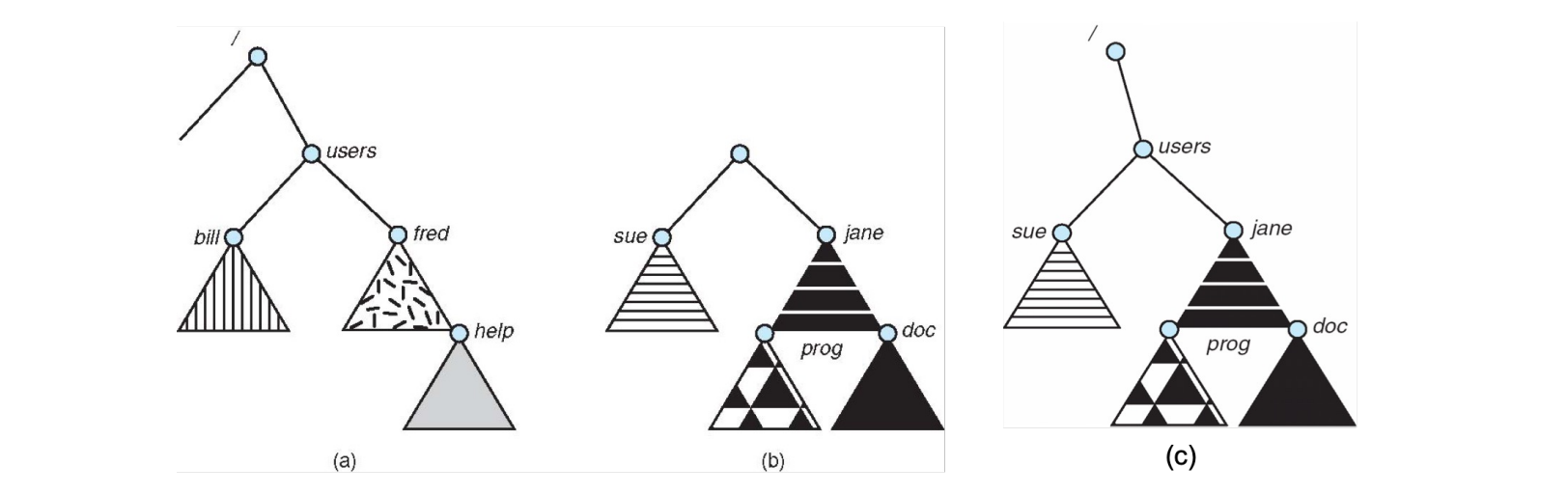
上图展示了文件系统挂载的过程: - (a) 现有文件系统 (existing file system):显示了一个包含
/users目录的现有文件系统。 - (b) 未挂载的分区 (an unmounted partition):一个独立的磁盘分区,包含它自己的根目录 (/) 以及doc和prog子目录。 - (c) 分区挂载到/users(the partition mounted at /users):未挂载的分区现在被挂载到了现有文件系统的/users目录下。此时,访问/users将会看到被挂载分区的内容(doc和prog) ,而原先/users目录下的内容(bill,fred,sue,jane以及help)则被隐藏起来,暂时无法直接访问。这是一个实际的 Linux
mount命令输出示例:Bashos@os :~/temp/foo$ mount sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) udev on /dev type devtmpfs (rw,nosuid,relatime,size=475364k,nr_inodes=118841,mode=755) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000) tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=100384k,mode=755) /dev/sda1 on / type ext4 (rw,relatime,errors=remount-ro,data=ordered) securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev) tmpfs on /run/lock type tmpfs (rw,nosuid,nodev,noexec,relatime,size=5120k)其中
/dev/sda1 on / type ext4 (rw,relatime,errors=remount-ro,data=ordered)这一行表示/dev/sda1设备(一个分区)以ext4文件系统类型挂载到根目录/。
文件共享 (File Sharing) (page 38) ¶
在多用户系统中,文件共享是十分重要的特性。文件共享必须通过一种保护机制 (protection scheme) 来实现:
- 用户 ID (User IDs):标识用户,允许实现基于用户的保护。
- 组 ID (Group IDs):允许用户分组,实现基于组的访问权限。
在分布式系统 (distributed systems) 中,文件可以通过网络进行共享。网络文件系统 (Network File System, NFS) 是一种常见的分布式文件共享方法。
远程文件共享 (Remote File Sharing) (page 39) ¶
远程文件共享通过网络实现系统间的文件系统访问:
- 手动方式 (Manually):通过 FTP (File Transfer Protocol) 等程序手动传输文件。
- 自动 / 无缝方式 (Automatically, seamlessly):使用分布式文件系统,用户感知不到文件在远程存储。
- 半自动方式 (Semi automatically):通过万维网 (world wide web) 访问。
客户端 - 服务器模型 (Client-server model) 允许客户端从服务器挂载远程文件系统:
- 一个服务器可以服务多个客户端。
- 客户端和客户端用户的身份识别复杂,服务器不能假定客户端是可信的。
- 标准操作系统文件调用 (Standard OS file calls) 会被翻译成远程调用。
- NFS 是标准的 Unix 文件共享协议。
- CIFS (Common Internet File System) 是 Windows 的标准文件共享协议。
保护 (Protection) (page 41) ¶
文件所有者 / 创建者应该能够控制:
- 什么可以被执行 (what can be done):定义允许的操作类型。
- 谁可以执行 (by whom):定义哪些用户或组具有执行权限。
访问类型 (Types of access) 包括:
- 读 (read)
- 写 (write)
- 追加 (append)
- 执行 (execute)
- 删除 (delete)
- 列出 (list) ( 针对目录 )
访问控制列表 (Access Control List, ACL) (page 42) ¶
访问控制列表 (ACL)
ACL 是一个列表,它为每个文件和目录分配了特定的用户或组的访问权限。
- 优点 (Advantages):提供细粒度 (fine-grained) 的控制,可以为每个用户或组指定精确的权限。
- 缺点 (Disadvantages):
- 如何构建这个列表?可能很复杂。
- 如何在目录中存储这个列表?如果用户数量庞大,列表会非常大。
Unix 访问控制 (Unix Access Control) (page 43) ¶
Unix 系统使用一种简洁的权限模型:
-
三类访问模式 (Three modes of access):
- 读 (read, r):读取文件内容或列出目录内容。
- 写 (write, w):修改文件内容或在目录中创建、删除文件。
- 执行 (execute, x):运行可执行文件或进入目录。
这些模式通常编码为三位二进制数,例如
rwx对应111。
-
三类用户 (Three classes of users):
- 所有者 (owner):文件的创建者或所有者。
- 组 (group):文件所属的用户组。
- 其他 (others):所有不属于所有者或所属组的用户。
Unix 权限控制 (page 43)
Unix 权限通常用三位八进制数表示,每位对应owner , group , others的 rwx 权限:
| 权限位 | 读 (r) | 写 (w) | 执行 (x) | 二进制 | 八进制 |
|---|---|---|---|---|---|
| rwx | 1 | 1 | 1 | 111 | 7 |
| rw- | 1 | 1 | 0 | 110 | 6 |
| r-- | 1 | 0 | 0 | 100 | 4 |
| --x | 0 | 0 | 1 | 001 | 1 |
结合三类用户,我们可以看到:
- a) owner access: 7 (111):所有者具有读、写、执行权限。
- b) group access: 6 (110):组用户具有读、写权限。
- c) others access: 1 (001):其他用户只具有执行权限。
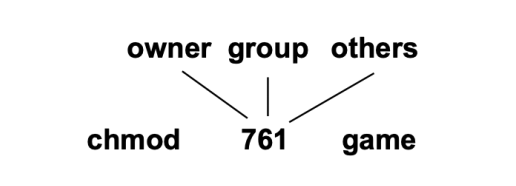
在 Linux 中,可以使用
chmod命令修改文件权限,使用chgrp命令修改文件所属组。[!example]- 常见 Unix 目录列表权限分析 (page 45)
Text Only-rw-rw-r-- 1 pbg staff 31200 Sep 3 08:30 intro.ps drwx------ 5 pbg staff 512 Jul 8 09:33 private/ drwxrwxr-x 2 pbg staff 512 Jul 8 09:35 doc/ drwxrwx--- 2 pbg student 512 Aug 3 14:13 student-proj/ -rw-r--r-- 1 pbg staff 9423 Feb 24 2003 program.c -rwxr-xr-x 1 pbg staff 20471 Feb 24 2003 program drwx--x--x 4 pbg faculty 512 Jul 31 10:31 lib/ drwx------ 3 pbg staff 1024 Aug 29 06:52 mail/ drwxrwxrwx 3 pbg staff 512 Jul 8 09:35 test/以第一行为例:
-rw-rw-r-- 1 pbg staff 31200 Sep 3 08:30 intro.ps- 第一个字符-表示这是一个普通文件 (d表示目录)。 - 接下来的三组字符rw-、rw-、r--分别对应所有者、组、其他用户的权限: -rw-(所有者):读、写权限。 -rw-(组):读、写权限。 -r--(其他):只读权限。旁边的数字
1表示硬链接数。pbg是所有者用户名,staff是所属组名。31200是文件大小(字节) 。Sep 3 08:30是文件最后修改时间。intro.ps是文件名。
Windows 文件访问控制 (Windows 8 File Access-Control) (page 44)
Windows 系统也提供文件访问控制,通常通过图形用户界面 (GUI) 进行配置。它提供比 Unix 更细粒度的权限设置,基于安全标识符 (Security Identifier, SID) 和权限继承机制。
ACL 实践 (ACL in practice) (page 46) ¶
在 Linux 中,除了传统的 Unix 权限外,还可以使用扩展的 ACL。getfacl 命令用于获取文件的 ACL 信息,setfacl 命令用于设置 ACL。
Linux ACL 示例 (page 46)
os@os2018fall /test$ ls -l
total 0
-rw-rw-r-- 1 os os 0 Dec 18 23:21 testacl
os@os2018fall /test$ getfacl testacl
# file: testacl
# owner: os
# group: os
user::rw-
group::rw-
other::r--
os@os2018fall /test$ setfacl -m u:test:rw testacl
os@os2018fall /test$ getfacl testacl
# file: testacl
# owner: os
# group: os
user::rw-
user:test:rw-
group::rw-
mask::rw-
other::r--
初始状态下,testacl 文件的权限是 -rw-rw-r--。
通过 setfacl -m u:test:rw testacl 命令,为用户 test 添加了读写权限。再次使用 getfacl testacl,可以看到 user:test:rw- 这一行,表示用户 test 对 testacl 文件拥有读写权限,这超越了传统的 Unix 权限模型。
总结 (Takeaway) (page 47) ¶
文件系统接口部分的要点包括:
- 文件系统 (File system):提供对磁盘的抽象。
- 文件操作 (File operations):创建、打开、读 / 写、关闭等。
- 文件类型 (File type):数据、程序、特殊文件等。
- 文件结构 (File structure):无结构、简单记录、复杂结构。
- 文件访问 (File access):顺序访问、直接访问、索引访问。
- 目录结构 (Directory structure):单级、两级、树形、非循环图、通用图。
- 保护 (Protection):ACL,Unix 权限模型。
二、文件系统实现 (File System Implementation) ¶
文件系统历史 (File System History) (page 4-5)
文件系统经历了多个发展阶段:
- 早期文件系统 (Early File Systems) (1950s-1970s):
- 主要用于科学研究和大型商业计算机。
- 通常比较基础,常常是为特定操作系统甚至特定计算机型号定制的。
- 例如,IBM 的早期大型机有其自己的文件系统。
- 分层文件系统 (Hierarchical File Systems) (1970s-1980s):
- 允许文件被组织到目录中。
- 典型例子包括 Unix 文件系统和 Microsoft 的 FAT (File Allocation Table) 系统。
- 网络文件系统 (Network File Systems) (1980s-1990s):
- 支持通过网络访问的文件系统出现,如 NFS (Network File System)。
- 日志文件系统 (Journaling File Systems) (1990s-2000s):
- 引入了日志机制,如 ext3, ext4, NTFS。
- 在操作前记录更改,允许系统崩溃后恢复,提高了性能和可靠性。
- 现代文件系统 (Modern File Systems) (2000s- 至今 ):
- 引入了高级功能,如 ZFS 和 Btrfs,支持快照 (snapshots)、动态卷管理 (dynamic volume management) 和数据完整性检查 (data integrity checks)。
- 分布式文件系统 (Distributed file systems) 变得更加普遍,如 Google 的 GFS (Google File System) 和 Amazon 的 S3 (Simple Storage Service),它们旨在实现大规模数据存储和高可靠性。
文件系统结构 (File-System Structure) (page 6) ¶
- 文件是一个逻辑存储单元 (logical storage unit),用于存储相关信息的集合。
- 操作系统通常可以同时支持多个文件系统,例如 Linux 支持 ext2/3/4, reiser FS/4, btrfs 等,Windows 支持 FAT, FAT32, NTFS 等。新的文件系统如 ZFS, googlefs, oracle ASM, FUSE 也在不断涌现。
- 文件系统驻留在辅助存储器 (secondary storage)(如磁盘)上。
- 磁盘驱动器提供读写磁盘块的接口。
- 文件系统为用户 / 程序提供了存储接口,将逻辑地址映射到物理地址 (mapping logical to physical)。
- 文件控制块 (File control block, FCB) 是一种存储结构,包含文件的相关信息。
- 文件系统通常以分层 (layers) 的方式实现和组织。
分层文件系统 (Layered File System) (page 7-12) ¶
文件系统通常被组织成多个层次,每个层次负责特定的功能。这种分层设计有助于降低复杂性 (reducing complexity) 和减少冗余 (redundancy),但可能增加开销 (overhead) 并降低性能 (decrease performance)。
Translates file name into file number, file handle, location by maintaining file control blocks (inodes in UNIX)
文件系统层次结构
层次结构通常包括:
- 应用程序 (application programs):用户程序通过文件系统接口与文件系统交互。
- 逻辑文件系统 (logical file system):
- 管理文件系统所需的元数据 (meta-data)(除了文件内容之外的所有信息
) 。 - 存储目录结构。
- 存储文件控制块 (FCB),其中包含文件的描述信息(名称、所有权、权限、引用计数、时间戳、指向数据块的指针
) 。 - 将文件路径名 (filepath) 转换为逻辑块地址。
- 接收来自上层 ( 应用程序 ) 的
open/read/write filepath请求。 - 向下一层输出逻辑块读写请求。
- 管理文件系统所需的元数据 (meta-data)(除了文件内容之外的所有信息
- 文件组织模块 (file-organization module):
- 了解文件的逻辑文件块(从 0 到 N)及其对应的物理文件块。
- 执行逻辑到物理的地址转换 (translation)。
- 管理空闲空间 (free space)。
- 接收来自逻辑文件系统的
read logical block X或write logical block Y请求。 - 向下一层输出物理块读写请求。
- 了解文件的逻辑文件块(从 0 到 N)及其对应的物理文件块。
- 基本文件系统 (basic file system):
- 在 Linux 中通常被称为“块 I/O 子系统 (block I/O subsystem)”。
- 分配和维护各种缓冲区 (buffers),这些缓冲区包含文件系统、目录和数据块。这些缓冲区作为缓存 (caches) 使用,以提高性能。
- 接收来自文件组织模块的
read physical block X或write physical block Y请求。 - 向下一层输出物理块读写请求。
- I/O 控制 (I/O control):
- 包含设备驱动程序 (device drivers) 和中断处理程序 (interrupt handlers)。
- 将读写请求写入设备控制器 (device controller) 的内存中,以执行磁盘读写操作。
- 响应相关的中断。
- 设备 (devices):底层的物理存储设备,如磁盘。
文件系统数据结构 (File System Data Structures) (page 14) ¶
文件系统包含两种主要的数据结构:磁盘上的结构和内存中的结构。
磁盘上的结构 (On-disk structures):
- 可选的引导控制块 (boot control block):卷的第一个块,存储操作系统。
- 在 UFS (Unix File System) 中是引导块 (boot block)。
- 在 NTFS (New Technology File System) 中是分区引导扇区 (partition boot sector)。
- 卷控制块 (volume control block):
- 包含卷中的块数、块大小、空闲块计数、空闲块指针、空闲 FCB 计数和 FCB 指针。
- 在 UFS 中是超级块 (superblock)。
- 在 NTFS 中是主文件表 (master file table)。
- 目录 (directory):
- 文件名称与 ID ( 如 i-node 编号 ) 相关联,包含 FCB 指针。
- 每个文件的文件控制块 (per-file File Control Block, FCB):
- 包含文件的所有重要信息。
- 在 NTFS 中,FCB 是关系数据库中的一行。
内存中的结构 (In-memory structures):
- 挂载表 (mount table):每个挂载的卷有一个条目。
- 目录缓存 (directory cache):用于快速路径转换 (fast path translation),提高性能。
- 全局打开文件表 (global open-file table):系统范围内所有打开文件的信息。
- 每个进程的打开文件表 (per-process open-file table):每个进程维护自己的打开文件列表。
- 各种缓冲区 (various buffers):用于在传输过程中持有磁盘块,提高性能。
文件控制块 (File Control Block, FCB) (page 15) ¶
FCB 是操作系统用于存储文件元数据的结构。它通常包含以下信息:
- 文件权限 (file permissions)
- 文件日期 (file dates) ( 创建、访问、写入 )
- 文件所有者、组、ACL (file owner, group, ACL)
- 文件大小 (file size)
- 文件数据块或指向文件数据块的指针 (file data blocks or pointers to file data blocks)
ext2 文件系统的 i-node 结构 (ext2_inode) (page 16, 27)
在 Unix 及其派生文件系统(如 ext2)中,文件控制块通常被称为索引节点 (inode)。i-node 包含了文件的所有元数据,但不包括文件名本身。文件名存储在目录条目中,并指向对应的 i-node。
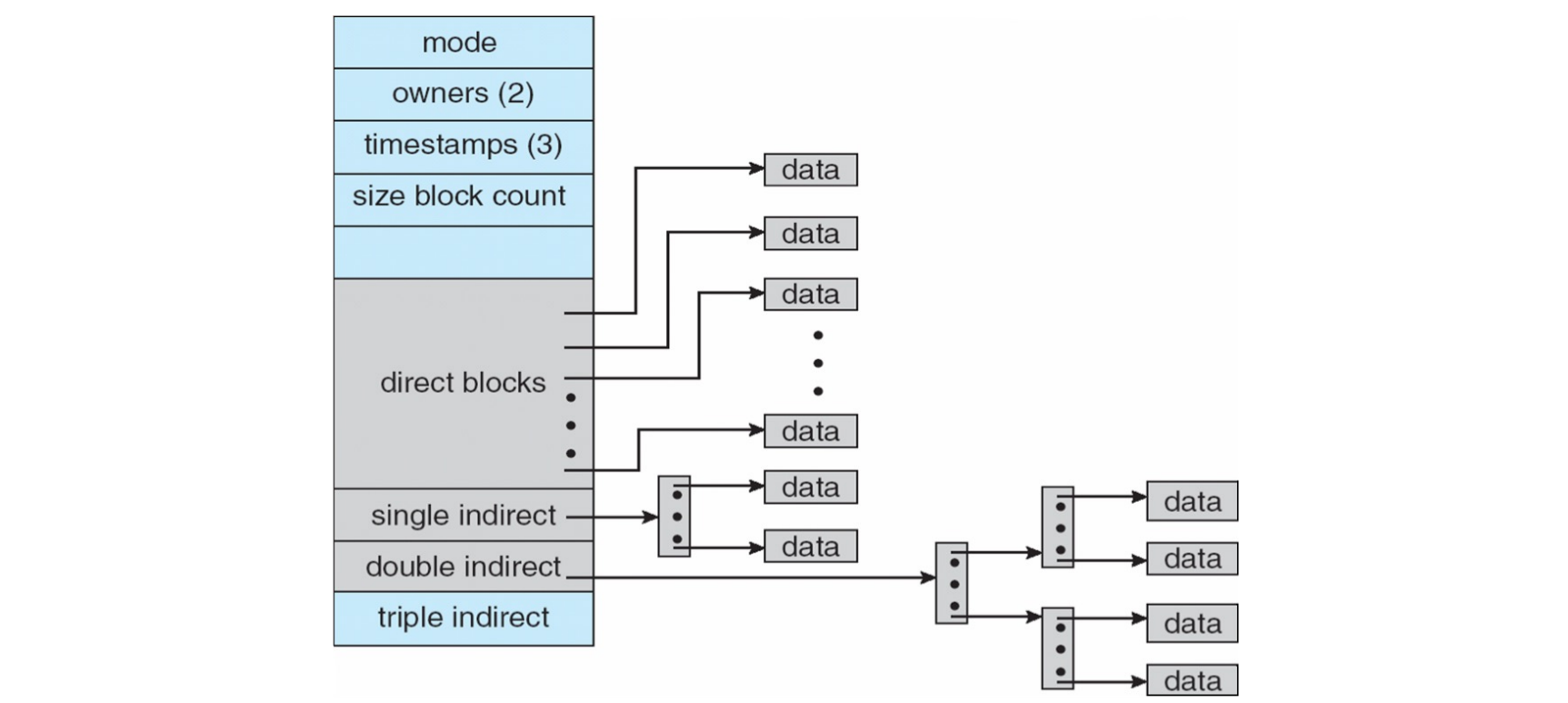
ext2 的 i-node 结构包含多个字段,提供文件的详细信息:(fs_in_practice: page 27)
Size ( 字节 ) Name What is this inode field for? 2 mode 文件模式 ( 权限、类型等 ) 2 uid 拥有此文件的用户 ID 4 size 文件大小 ( 字节 ) 4 time 文件最后访问时间 4 ctime 文件创建时间 4 mtime 文件最后修改时间 4 dtime i-node 删除时间 2 gid 文件所属组 ID 2 links_count 指向此文件的硬链接数 4 blocks 已分配给此文件的块数 4 flags ext2 如何使用此 i-node 的标志 4 osd1 OS 依赖字段 60 block 磁盘块指针 ( 共 15 个,直接 / 间接 ) 4 generation 文件版本 (NFS 使用 ) 4 file_acl 新权限模型 beyond mode bits ( 访问控制列表 ) 4 dir_acl 目录 ACL 值得注意的是,
block字段包含指向文件数据块的指针。通常,前 12 个指针是直接块指针 (direct blocks),指向文件的前 12 个数据块。之后是指向间接块 (indirect blocks) 的指针,用于支持更大的文件。
文件创建操作 (File Creation) (page 17) ¶
当应用程序进程请求创建一个新文件时,文件系统会执行以下步骤:
- 逻辑文件系统 (Logical file system) 分配一个新的文件控制块 (FCB),例如在 Unix 中分配一个 i-node 结构。
- 合适的目录 (Appropriate directory) 被更新,其中添加了新的文件名和指向新分配的 FCB 的指针。
文件打开操作 (Operations - open()) (page 18-19) ¶
open() 系统调用是文件操作的关键步骤。它将文件的元数据从磁盘加载到内存中,并建立进程与文件之间的关联。
- 搜索系统范围的打开文件表 (Search system-wide open-file table):
- 检查文件是否已被其他进程打开。
- 如果已在用:在每个进程的打开文件表 (per-process open-file table) 中创建一个条目,该条目指向系统范围打开文件表中现有文件的条目。
- 如果未在用:
- 搜索目录结构以查找文件名。
- 找到文件后,将文件的 FCB ( 例如 i-node) 从磁盘加载到内存中,并将其放置在系统范围的打开文件表中。
- 创建每个进程的打开文件表条目 (Make an entry in the per-process open-file table):
- 此条目包含指向系统范围打开文件表中相应条目的指针。
- 还包含其他字段,如当前读写位置 (file pointer) 和文件打开时的访问模式。
- 增加文件打开计数 (Increment the open count):
- 系统范围打开文件表中的文件打开计数器会增加。
- 返回指针 (Returns a pointer):
open()调用返回一个文件描述符 (file descriptor),该描述符是指向每个进程打开文件表中相应条目的指针。所有后续操作都使用这个文件描述符。
文件关闭操作 (Process closes file):
- 移除每个进程的打开文件表条目 (per-process open-file table entry is removed)。
- 减少文件打开计数 (open count decremented)。
- 如果所有进程都关闭了文件 (All processes close file):
- 内存中的目录信息(如修改时间、大小等)被复制回磁盘。
- 系统范围打开文件表中的相应条目被移除。
Unix 文件系统 (Unix (UFS)) (page 20) ¶
- 系统范围的打开文件表 (System-Wide Open-File Table) 包含文件的 i-node(索引节点
) 、目录、设备和网络连接等信息。 - i-node 编号系统只在给定文件系统内部是唯一的。
挂载文件系统 (Mounting File Systems) (page 21) ¶
除了用户接口部分提到的概念,文件系统挂载在实现层面涉及以下数据结构:
- 引导块 (Boot Block):
- 一系列连续的块,包含引导加载器 (boot loader) 的内存映像。
- 引导加载器负责定位和挂载根分区 (root partition)。
- 根分区包含内核,引导加载器加载并启动内核执行。
- 内存中的挂载表 (In-memory mount table):
- 外部文件系统必须挂载到设备上。
- 挂载表记录挂载点 (mount points)、挂载的文件系统类型以及访问所需文件系统的路径。
- Unix 中的超级块 (Unix - the superblock):
- Unix 的内存挂载表包含指向设备上文件系统超级块 (superblock) 的指针。
虚拟文件系统 (Virtual File Systems, VFS) (page 22-25) ¶
David Wheeler 的名言 (page 23)
“计算机科学中的所有问题都可以通过增加一个间接层来解决,除了间接层过多的问题
这句话精辟地概括了 VFS 的设计哲学和潜在弊端。VFS 通过引入一个统一的抽象层来解决多种文件系统的兼容性问题,但同时也增加了系统的复杂性。
操作系统如何处理不同类型的文件系统(如 ext4, NTFS, FAT, NFS 等
虚拟文件系统 (VFS)
VFS 提供了一种面向对象 (object-oriented) 的方式来实现文件系统。它定义了一个公共接口 (common interface),所有文件系统都必须实现这个接口。这允许使用相同的系统调用 API (syscall API) 来操作不同类型的文件系统。
VFS 的作用 (Role of VFS):
- VFS 将文件系统的通用操作与具体的实现细节分离开来。
- 具体的实现可以是多种文件系统类型之一,也可以是网络文件系统。
- 操作系统可以将系统调用分派给适当的文件系统实现例程 (implementation routines)。
虚拟文件系统结构示例 (page 24)
(page 24) 图展示了 VFS 如何在不同的文件系统之间提供统一接口: - 顶层是统一的文件系统接口 (file-system interface),应用程序通过这个接口进行文件操作。 - VFS 层将这些通用请求分派给底层的具体文件系统实现。 - 底层可以是多种本地文件系统 (local file system type 1, type 2),它们通过磁盘进行数据存储。 - 也可以是远程文件系统 (remote file system type 1),它通过网络进行数据存储。
Linux VFS 对象类型 (Linux defines four VFS object types) (page 26) ¶
Linux 内核定义了四种主要的 VFS 对象类型,它们是 VFS 抽象层的基础:
- 超级块 (superblock):定义文件系统类型、大小、状态及其他元数据。
- 索引节点 (inode):包含文件的元数据(位置、访问模式、所有者等
) 。 - 目录项 (dentry):关联文件名与 i-node,并表示目录的布局。
- 文件 (file):表示实际的文件数据。
VFS 实现 (VFS Implementation) (page 27-28) ¶
VFS 通过定义一组必须实现的对象操作来工作。这些操作被保存在一个函数表 (function table) 中。
vfs_write 系统调用路径 (page 28)
当一个用户程序调用 write() 系统调用时,其调用路径大致如下:
write syscall -> vfs_write-> indirect call-> ext4_file_write_iter( 如果文件在 ext4 文件系统上 )
这是一个间接调用链的例子。vfs_write 是一个通用的 VFS 函数,它不直接处理文件写入,而是通过一个函数指针(或函数表)调用文件系统特定的写入函数(例如 ext4_file_write_iter
- 当写入 NFS 文件时,调用路径是什么?
write syscall->vfs_write->indirect call->nfs_file_write_iter(因为 NFS 也是一种文件系统,它也实现了 VFS 接口)。 file->f_op何时设置?file->f_op(文件操作结构体指针) 在文件被open()时设置。当文件被打开时,文件系统会根据其类型(例如 ext4, NFS 等)填充file结构体的f_op字段,使其指向相应文件系统的操作函数集。
目录实现 (Directory Implementation) (page 29) ¶
在实现层面,目录被视为一种特殊的文件。它存储文件名到 i-node 编号的映射。
目录结构与ext2_dir_entry (page 30-31)
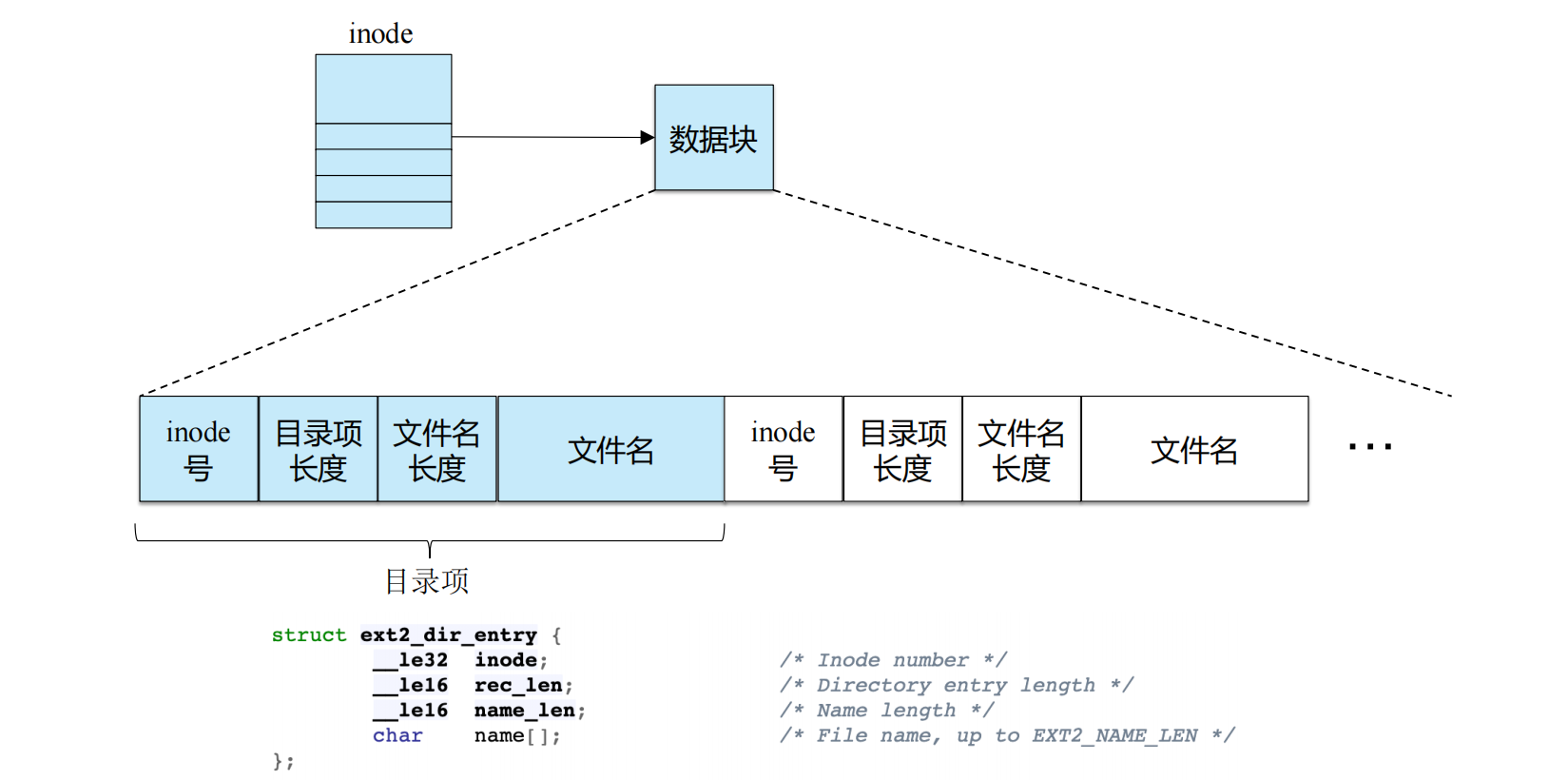
上图展示了目录作为文件存储其内容的方式。目录文件本身包含一系列的目录项 (directory entries)。每个目录项包含: -
inode编号:指向文件或子目录的 i-node。 -reclen(记录长度):当前目录项的长度。 -name_len(名称长度):文件名的长度。 -name(名称):文件名本身。假设一个目录 (i-node 编号 5) 有三个文件:
foo,bar,foobar_is_a_pretty_longname。
inum reclen strlen name 5 12 2 .. 2 12 3 foo 12 12 4 bar 13 12 4 bar 24 36 28 foobar_is_a_pretty_longname 这里
reclen是目录项的实际存储长度,通常是 4 的倍数,以便于对齐和复用目录项空间。strlen是文件名的实际长度。
目录实现方法 (Directory Implementation Methods) (page 32) ¶
实现目录主要有两种策略:
- 文件名的线性列表 (Linear list of file names):
- 每个目录项是一个文件名及其指向文件元数据(如 i-node)的指针。
- 优点:编程简单。
- 缺点:搜索文件时需要线性搜索 (linear search),非常耗时 (time-consuming)。可以通过维护按字母顺序排列的链表或使用 B+ 树来改进搜索效率。
- 哈希表 (Hash table):
- 将文件名哈希到哈希表中的一个位置,以减少搜索时间。
- 优点:搜索效率更高。
- 缺点:可能发生哈希冲突 (collisions),即两个或更多文件名哈希到同一位置。
Unix 与 Windows 目录实现的差异:
- Unix:将目录视为包含特殊数据的普通文件。这意味着可以使用与文件相同的系统调用来操作目录(如读目录内容
) 。 - Windows:目录与文件处理方式不同。它们需要一套单独的系统调用来创建、操作等。
文件打开 / 读取过程再探 (Directory - file open/read revisit) (page 33) [todo] ¶
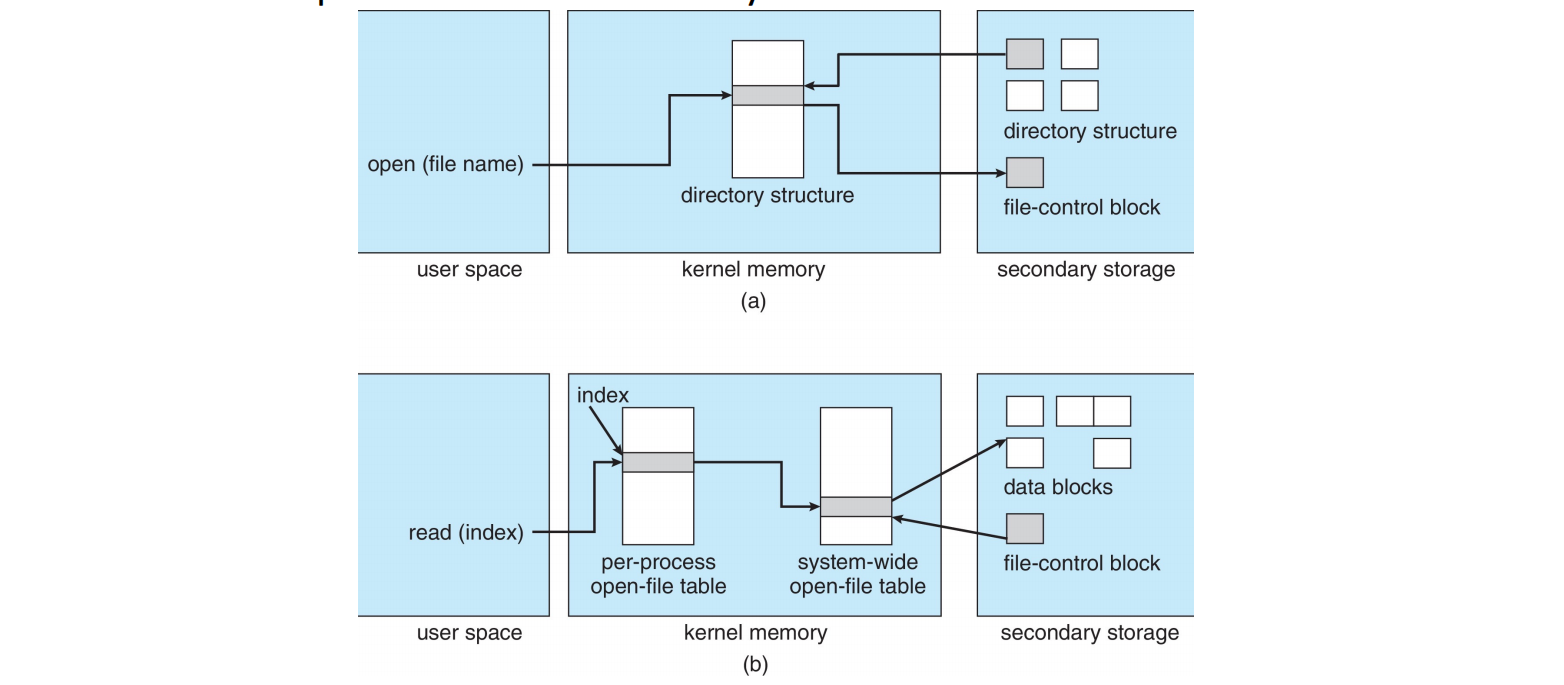
上图详细描绘了 open() 系统调用如何将文件名转换为实际可操作的文件。
步骤分解:
上半部分 (a) - 打开文件 (open file):
- 用户进程发出
open(file name)请求。 - 内核 (kernel memory) 首先检查系统范围打开文件表 (system-wide open-file table)。
- 如果文件已打开:在每个进程的打开文件表中创建指向现有条目的指针。
- 如果文件未打开:
- 内核根据文件名在目录结构 (directory structure) 中查找。
- 找到文件后,其 FCB ( 文件控制块 ) 从辅助存储 (secondary storage) 加载到内核内存中的文件控制块 (file-control block) 区域,并复制到系统范围打开文件表中。
- 然后,在用户内存 (user space) 中创建一个每个进程的打开文件表 (per-process open-file table) 条目,并指向系统范围打开文件表中的相应 FCB 条目。
- 最终,
open()返回一个文件描述符 (file descriptor) 给用户进程,指向这个每进程条目。
下半部分 (b) - 读取文件 (read file):
- 用户进程发出
read(index)请求,这里的index是文件描述符。 - 内核使用文件描述符查找每个进程的打开文件表,进而找到系统范围打开文件表中对应的 FCB。
- FCB 包含文件在磁盘上的物理位置信息。
- 内核通过文件系统层次结构(文件组织模块、基本文件系统、I/O 控制)将逻辑读请求转换为物理磁盘读请求。
- 数据块从辅助存储的数据块 (data blocks) 区域读入内核内存,并通过文件描述符返回给用户进程。
创建新文件步骤 (How about create a new file?) (page 34) ¶
创建新文件时,需要考虑以下步骤:
- 目录 (Directory):需要在目标目录中创建一个新的目录条目,将文件名与新文件的 FCB(i-node)关联起来。
- FCB (File Control Block):需要分配一个新的 FCB,并填充其元数据(权限、所有者、时间戳等
) 。
读写文件 /foo/bar 的例子 (Read /foo/bar and Write to Disk: /foo/bar) (fs_in_practice: page 30-31) ¶
这些表格展示了访问 /foo/bar 文件时,不同层级的文件系统结构如何被访问和更新。假设 foo 是一个目录,bar 是其中的一个文件。
读取 /foo/bar 过程 (Read /foo/bar):
| 操作 | data bitmap | inode bitmap | root inode read | foo inode read | bar inode read | data[0] read | data[1] read | data[2] read |
|---|---|---|---|---|---|---|---|---|
open(bar) |
read | Read dir entry of foo | ||||||
| read | Read dir entry of bar | |||||||
read() |
read | |||||||
| read | ||||||||
read() |
read | Update access time | ||||||
| read | ||||||||
read() |
read | |||||||
| read |
分析 (Analysis):
open(bar):- 为了找到
/foo/bar,系统首先需要读取根目录 (root) 的 i-node,从中获取其目录条目信息。 - 然后,它会在根目录的目录项中读取
foo的目录条目,以找到foo目录的 i-node。 - 接着,系统会读取
foo目录的 i-node,并从中找到bar的目录条目,从而获取bar文件的 i-node。 - 最后,读取
bar文件的 i-node,将其加载到内存中,完成open操作。 - 这个过程涉及到多次磁盘读操作,以遍历目录路径并获取文件的元数据。
- 为了找到
read():- 一旦文件被打开(其 i-node 已在内存中
) ,后续的read()操作将根据 i-node 中的指针直接读取文件的数据块。 - 每次读取数据块时,可能需要更新文件的访问时间 (access time) 属性。
- 一旦文件被打开(其 i-node 已在内存中
写入磁盘 /foo/bar 过程 (Write to Disk: /foo/bar):
| 操作 | data bitmap | inode bitmap | root inode read | foo inode read | bar inode write | data[0] write | data[1] write | data[2] write |
|---|---|---|---|---|---|---|---|---|
create(/foo/bar) |
read | Find bar not exist | ||||||
| read | Write dir entry of bar to foo | |||||||
write() |
write | Update metadata, such as count, access time | ||||||
| write | ||||||||
write() |
write | |||||||
| write | ||||||||
write() |
write | |||||||
| write |
分析 (Analysis):
create(/foo/bar):- 与
open类似,需要读取根目录的 i-node和foo目录的 i-node。 - 在
foo目录中查找bar是否存在。如果不存在,则在foo目录中写入bar的目录条目(包含新的 i-node 编号) 。 - 需要更新i-node 位图 (inode bitmap) 以标记新的 i-node 已被分配,并写入新的
bar的 i-node。
- 与
write():- 每次写入数据时,可能需要分配新的数据块。这涉及到更新数据位图 (data bitmap)。
- 写入文件数据块。
- 写入
bar文件的 i-node,更新其元数据,如文件大小、块计数、修改时间等。 - 这些操作可能不会立即同步到磁盘,而是会先写入缓存 (cache)。
磁盘块分配 (Disk Block Allocation) (page 35) ¶
文件需要被分配到磁盘块中以存储数据。不同的分配策略具有不同的复杂性和性能特点。主要有以下几种策略:
- 连续分配 (Contiguous)
- 链式分配 (Linked)
- 索引分配 (Indexed)
连续分配 (Contiguous Allocation) (page 36-37) ¶
连续分配 (Contiguous Allocation)
连续分配意味着每个文件都存储在一组连续的磁盘块中。目录维护文件的起始块地址和长度。
优点 (Pros):
- 高效的顺序访问 (Good because sequential access):由于块是连续的,磁盘磁头移动少,寻道时间 (seek times) 短。
- 高效的随机访问 (Good for random access):给定起始块和偏移量,可以立即计算出物理地址。
缺点 (Cons):
- 难以找到空闲空间 (Can be difficult to find free space):需要找到足够大的连续空闲块。这涉及到“最佳适应 (Best Fit)”
、 “首次适应 (First Fit)”等算法。 - 外部碎片 (External fragmentation):磁盘中散布着许多小的、不连续的空闲块,这些块的总和可能很大,但无法满足大文件的连续分配需求。
- 需要进行磁盘碎片整理 (Compaction/defrag),将零散的空闲块合并成更大的连续空闲区域,但这是一个昂贵且耗时的操作。
- 文件难以增长 (Difficult to have files grow):如果文件需要增长,而其后面没有足够的连续空间,则需要将整个文件复制到更大的连续空闲区域,这会导致高开销。
- 可能需要用户在创建文件时指定最大文件大小,但这很不方便。
- 内部碎片 (High internal fragmentation):如果文件大小不是块大小的整数倍,最后一个块会有未使用的空间。
- 可以通过创建文件块的链表来改进,这被称为扩展 (extent)。
链式分配 (Linked Allocation) (page 38-40) ¶
链式分配 (Linked Allocation)
链式分配将文件视为一个磁盘块的链表。每个块包含指向下一个块的指针,文件以空 (nil) 指针结束。
优点 (Pros):
- 无外部碎片 (no external fragmentation):块可以分散在磁盘的任何位置。
- 无需碎片整理 (no compaction):文件可以自由增长,只需找到下一个空闲块即可。
- 不浪费空间 (No waste of space for pointers):指针直接存储在数据块内部。
缺点 (Disadvantages):
- 查找耗时 (Locating a file block can take many I/Os and disk seeks):随机访问效率低,需要从头开始遍历链表以找到特定块。
- 指针占用空间 (Pointer size):每个块的一部分空间用于存储指针(例如,512 字节的块中 4 字节用于指针,浪费 0.78% 的空间
) 。 - 可靠性问题 (Reliability):如果指针损坏,整个文件链可能会中断,导致数据丢失。
改进 (Improvements):
- 块簇 (cluster the blocks):将多个块组合成一个簇,以减少 I/O 次数。但这会导致内部碎片。
- 文件分配表 (File-Allocation Table, FAT):MS-DOS 使用的 FAT 是一种特殊的链式分配方法。FAT 是一个单独的表,存储在磁盘开头,其中包含每个文件所有块的链表信息,而不是将指针存储在每个数据块中。
FAT 示例 (page 40)
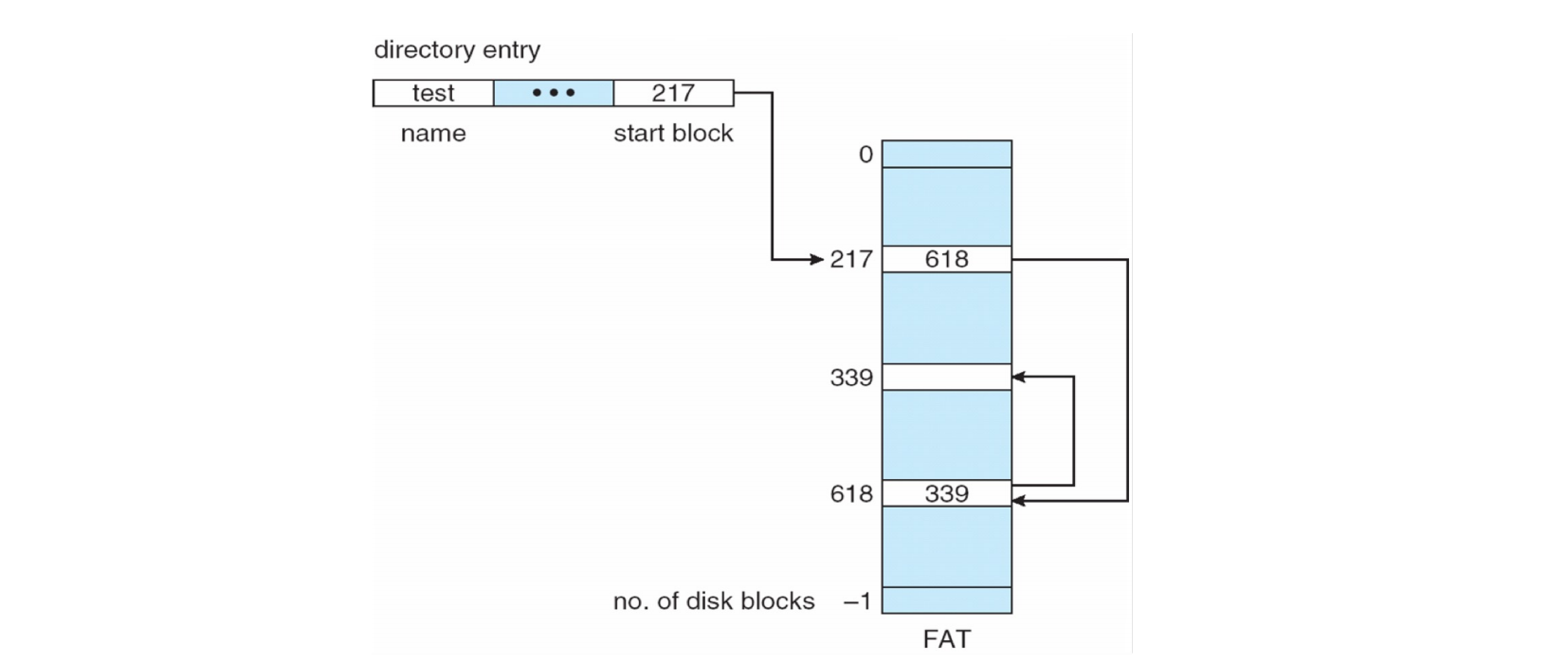
FAT 是一个全局表,每个文件都有一个入口指向其第一个数据块。该数据块的条目在 FAT 中指向下一个数据块,以此类推,直到文件结束标记。这样做的好处是,所有的指针都集中在 FAT 中,避免了在每个数据块中存储指针的开销,也方便了对文件的随机访问(但仍然需要遍历 FAT 表
) 。
索引分配 (Indexed Allocation) (page 41-44) ¶
索引分配 (Indexed Allocation)
索引分配为每个文件分配一个特殊的索引块 (index block),其中包含指向文件所有数据块的指针。
优点 (Pros):
- 随机 / 直接访问 (random/direct access):索引表提供了对文件数据块的快速随机访问。
- 无外部碎片 (No external fragmentation):数据块可以分散在磁盘的任何位置。
- 允许文件有空洞 (Allows holes in the file):文件可以不连续,中间有空闲块。
缺点 (Cons):
- 索引块的开销 (overhead of index blocks):每个文件都需要一个额外的索引块来存储指针。
- 小文件浪费空间 (waste for small files):即使文件很小,也需要分配一个完整的索引块,可能导致空间浪费。
多级索引 (Multiple-level index blocks):
- 为了支持更大的文件,单个索引块可能不够用。可以采用多级索引结构。
- 链式索引块 (Linked index blocks):链接多个索引块以支持巨型文件。
- 多级索引块 (Multiple-level index blocks):例如,2 级索引块,其中一个索引块指向其他索引块。
Unix 的组合方案 (Combined scheme) (page 44)
Unix 的 FCB (i-node) 采用了一种组合分配方案,以平衡不同文件大小的性能需求。i-node 中包含:
- 直接块 (Direct blocks):前 12 个指针直接指向文件的前 12 个数据块。这对于小文件非常高效。
- 单级间接块 (Single indirect block):一个指针指向一个额外的索引块,该索引块包含了更多数据块的指针。
- 双级间接块 (Double indirect block):一个指针指向一个索引块,该索引块的每个条目又指向另一个索引块(单级间接块
) 。 - 三级间接块 (Triple indirect block):一个指针指向一个索引块,该索引块的每个条目又指向一个双级间接块。
假设: - 块大小 = 512 字节 - 指针大小 = 4 字节 - 每个块可以存储 512 / 4 = 128 个指针。
最大文件大小计算:
- 直接块:\(12 * 512 字节 = 6 KB\)
- 单级间接块:\(1 * 128 * 512 字节 = 64 KB\)
- 双级间接块:\(1 * 128 * 128 * 512 字节 = 8 MB\)
- 三级间接块:\(1 * 128 * 128 * 128 * 512 字节 = 1 GB\)
- 总最大文件大小 = \(6KB + 64KB + 8MB + 1GB ≈ 1 GB\)
如果块大小是 4KB?
- 每个块可以存储 \(4096 / 4 = 1024\) 个指针。
- 直接块:\(12 * 4 KB = 48 KB\)
- 单级间接块:\(1 * 1024 * 4 KB = 4 MB\)
- 双级间接块:\(1 * 1024 * 1024 * 4 KB = 4 GB\)
- 三级间接块:\(1 * 1024 * 1024 * 1024 * 4 KB = 4 TB\)
- 总最大文件大小 ≈ 4 TB。
这种组合方案能够有效地支持从极小文件到超大文件的存储需求。
分配方法总结 (Allocation Methods Summary) (page 45) ¶
最佳分配方法取决于文件访问类型:
- 连续分配 (Contiguous):非常适合顺序访问和随机访问。
- 链式分配 (Linked):适合顺序访问,不适合随机访问。
- 索引分配 (Indexed):更复杂,但提供了良好的随机访问能力,且无外部碎片。
- 单块访问可能需要两次索引块读取,然后一次数据块读取。
- 聚簇 (Clustering) 可以帮助提高吞吐量,减少 CPU 开销。一个簇是一组连续的块。
磁盘 I/O 速度与 CPU 速度的对比 (page 45)
磁盘 I/O 是非常慢的,需要尽可能减少磁盘 I/O 次数。
- Intel Core i7 Extreme Edition 990x (2011 年 ) 3.46GHz = 159,000 MIPS (Million Instructions Per Second)。
- 典型磁盘驱动器每秒 250 次 I/O (I/Os per second)。
- 这意味着在一次磁盘 I/O 期间,CPU 可以执行 159,000 MIPS / 250 I/Os = 630 百万条指令。
- 高速 SSD (Solid State Drive) 驱动器每秒提供 60,000 IOPS。
- 这意味着在一次 SSD I/O 期间,CPU 仍然可以执行 159,000 MIPS / 60,000 IOPS = 2.65 百万条指令。
这个对比强调了磁盘 I/O 是一个严重的性能瓶颈,文件系统设计必须优先考虑如何减少和优化磁盘访问。
空闲空间管理 (Free-Space Management) (page 46) ¶
文件系统需要维护一个空闲空间列表 (free-space list) 来跟踪可用的块 / 簇,并回收已删除文件所占用的空间。
主要的空闲空间管理方法包括:
- 位向量 / 位图 (Bit vector or bit map)
- 链式空闲空间 (Linked free space)
- 分组 (Grouping)
- 计数 (Counting)
位图空闲空间管理 (Bitmap Free-Space Management) (page 47) ¶
位图 (Bitmap)
位图使用一个位 (bit) 来表示一个磁盘块的分配状态(1 表示已分配,0 表示空闲
优点 (Pros):
- 查找连续块相对容易 (relatively easy to find contiguous blocks):可以高效地扫描位图来查找连续的空闲区域,这对于连续分配的文件很有用。
缺点 (Cons):
- 需要额外空间 (requires extra space):位图本身需要占用内存或磁盘空间。
位图空间计算 (page 47)
假设: - 块大小 = 4KB = \(2^{12}\) 字节 - 磁盘大小 = 1 TB = \(2^{40}\) 字节
磁盘上的总块数n = \(2^{40} / 2^{12} = 2^{28}\) 块。
那么位图需要 \(2^{28}\) 位来表示,即 256 兆位 (M bits),或者 32 兆字节 (M bytes)。
如果使用 4 个块的簇 (cluster),则内存中需要 64 兆位 (M bits) 来表示。
链式空闲空间 (Linked Free Space) (page 48-49) ¶
链式空闲空间 (Linked Free Space)
链式空闲空间通过将所有空闲块连接成一个链表来管理空闲空间。每个空闲块包含指向下一个空闲块的指针。
优点 (Pros):
- 不浪费额外空间 (No waste of space):指针直接存储在空闲块本身中。
缺点 (Cons):
- 难以获取连续空间 (Cannot get contiguous space easily):查找连续空闲块需要遍历链表,效率低下。
- 通常不需要遍历整个列表:只需返回第一个可用的空闲块即可。
分组和计数 (Grouping and Counting) (page 50) ¶
这是对链式空闲空间管理的改进:
- 分组 (Grouping):
- 在第一个空闲块中存储
n-1个空闲块的地址,并包含一个指向下一个索引块的指针。 - 这使得一次可以分配多个空闲块,而不需要遍历整个列表。
- 在第一个空闲块中存储
- 计数 (Counting):
- 存储一系列簇的链接,每个链接包含一个起始块地址和该起始块后连续空闲块的数量。
- 这种方法利用了空间通常是连续分配和释放的特性。
- 在链接节点中,保存第一个空闲块的地址和其后连续空闲块的数量。
文件系统性能 (File System Performance) (page 51) ¶
文件系统效率和性能取决于多个因素:
- 磁盘分配和目录算法 (Disk allocation and directory algorithms):例如,连续分配、链式分配、索引分配以及目录的哈希表或 B+ 树实现。
- 文件目录条目中保留的数据类型 (Types of data kept in file’s directory entry):元数据量会影响性能。
- 元数据结构的预分配或按需分配 (Pre-allocation or as-needed allocation of metadata structures):预分配可以减少运行时开销,但可能浪费空间。
- 固定大小或可变大小的数据结构 (Fixed-size or varying-size data structures):固定大小通常更简单高效,但可能导致空间浪费或限制。
提高文件系统性能 (To improve file system performance) (page 52) ¶
- 将数据和元数据紧密放置 (Keeping data and metadata close together):例如,将文件的 i-node 和其数据块放置在磁盘的相近位置,以减少寻道时间。
- 使用缓存 (Use cache):将主内存中的独立区域用于频繁使用的块。
- 使用异步写入 (Use asynchronous writes):
- 写入操作可以被缓冲 (buffered) 或缓存 (cached),然后稍后写入磁盘,从而更快地返回控制权。
- 但同步写入 (synchronous write) 不能缓存,必须在返回前写入磁盘。某些应用程序或操作系统需要同步写入以确保数据一致性。
- 先释放后读取 (Free-behind) 和预读取 (read-ahead):
- 优化顺序访问的技术。
- Free-behind:当顺序读取数据时,将已经读取过的页面从缓冲区中移除。
- Read-ahead:预测用户将要读取的数据,提前将多个页面读入缓冲区。
- 读取通常比写入慢 (Reads frequently slower than write: really?):
- 这是一个值得思考的问题。理论上,写入可以通过缓冲和异步操作来隐藏延迟,而读取通常需要等待实际的磁盘 I/O 完成。然而,这取决于具体的缓存策略、工作负载和磁盘硬件。
页面缓存 (Page Cache) (page 53) ¶
操作系统具有不同级别的缓存来优化 I/O 性能:
- 页面缓存 (page cache):缓存用于内存映射 I/O (MMIO) 的页面,例如内存映射文件 (memory mapped files)。
- 缓冲区 / 磁盘缓存 (buffer/disk cache):文件系统使用的缓存,用于磁盘 I/O。
统一缓冲区缓存 (Unified Buffer Cache)
传统的系统可能存在双重缓存 (double caching) 问题,即内存映射 I/O 和磁盘 I/O 都被缓存两次,导致内存浪费和一致性问题。现代操作系统通常采用统一缓冲区缓存 (unified buffer cache),它使用相同的页面缓存来缓存内存映射页面和磁盘 I/O,从而避免了双重缓存。
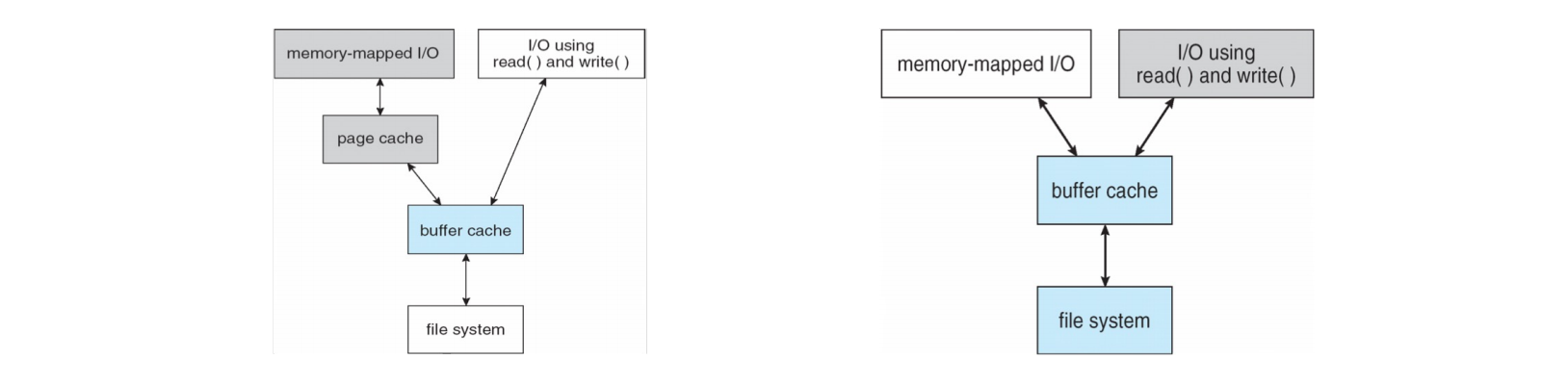
左侧图显示了分离的页面缓存和缓冲区缓存,可能导致双重缓存。右侧图展示了统一缓冲区缓存,所有数据都通过一个缓存层。
恢复 (Recovery) (page 54) ¶
文件系统需要进行一致性检查 (consistency checking) 以确保数据一致性。这包括比较目录中的数据和磁盘上的一些元数据。文件系统恢复可能很慢,有时会失败。
文件系统恢复方法:
- 备份 (Backup):定期将文件系统数据复制到其他存储介质。
- 日志结构文件系统 (Log-structured file system, LSFS):
日志结构文件系统 (Log Structured File Systems) (page 55) ¶
日志结构文件系统 (LSFS)
在 LSFS 中,所有元数据更新都顺序地写入一个循环日志 (circular log)。这使得写入操作非常快。
工作原理 (How it works):
- 一旦更改写入到日志,就被视为已提交 (committed),系统调用可以返回。日志可以位于不同的磁盘 / 分区上。
- 同时,日志条目会在后台被重放 (replayed) 到文件系统,以实际更新文件系统中的数据。
- 当一个事务被重放后,它会从日志中移除。
- 日志是循环的,但未重放的条目不会被覆盖。
- 垃圾回收 (Garbage collection) 机制可以回收 / 压缩日志条目中的空间。
- 在系统崩溃时,只需要重放日志中存在的事务,从而实现快速恢复。
总结 (Takeaway) (page 56) ¶
文件系统实现部分的要点包括:
- 文件系统层次 (File system layers):应用程序、逻辑文件系统、文件组织模块、基本文件系统、I/O 控制、设备。
- 文件系统实现 (File system implementation):包括磁盘上结构和内存中结构。
- 索引节点 (inode):核心的元数据结构。
- 文件创建和打开 (File creation(), open()):关键的文件操作流程。
- 虚拟文件系统 (VFS):提供统一的文件系统接口。
- 目录实现 (Directory Implementation):将目录视为特殊文件,以及其内部映射结构。
- 分配方法 (Allocation Methods):连续、链式、索引。
- 空闲空间管理 (Free-Space Management):位图、链式、分组、计数。
三、文件和目录实践 (File and Directory in Practice) ¶
两个关键抽象 (Two Key Abstractions) (page 2-3) ¶
文件系统中最核心的两个抽象概念是文件和目录:
- 文件 (File):
- 一个线性的字节数组,可以对其进行读 / 写操作。
- 它有一个低级名称(用户通常不知道
) ,即 i-node 编号 (inode number)。 - 通常操作系统不了解文件的确切类型,文件的类型由应用程序解释。
- 外部名称 (External name):用户可见的名称,必须是符号性的。在分层文件系统中,外部名称是路径名 (pathnames),从根目录到文件的路径。
- 内部名称 (Internal names):低级名称,如 Unix 中的 i-node。i-node 存储文件系统对象(文件、目录、socket 等)的信息,并且是卷中文件描述符 / 头部的索引。
- 目录 (Directory):
- 它有一个低级名称(即 i-node number
) 。 - 其内容非常特殊:包含用户可读名称到低级名称的列表。例如,
("foo", inode number 10)。 - 每个目录条目要么指向文件,要么指向另一个目录。
- 目录的主要功能是将外部名称翻译 (translation) 成内部名称。
- 它有一个低级名称(即 i-node number
文件系统接口细节 (File System Interface Details) (page 4) ¶
创建文件的一个典型系统调用是 open(),它接受文件名和一系列标志作为参数。
open() 系统调用示例 (page 4)
O_CREAT:如果文件不存在则创建文件。O_WRONLY:以只写模式打开文件。O_TRUNC:如果文件存在,则将其截断为零字节(清空内容) 。
open() 的返回值是一个文件描述符 (file descriptor),这是一个小型的非负整数。
文件描述符 (File Descriptor) (page 5) ¶
文件描述符 (File Descriptor)
文件描述符是一个整数,用于指代用户空间中进程的文件对象。它在每个进程的文件描述符表中作为对文件表的索引。
文件描述符表通常与以下数据结构相关联:
- 每个进程的文件描述符表 (per-process file descriptor table):存储文件描述符到文件表的映射。
- 文件表 (file table):存储打开文件的信息,如文件指针、访问模式等。
- i-node 表 (i-node table):存储文件的元数据(i-node
) 。
A BSD lock and an Open file description lock is associated with a file object, while a POSIX record lock is associated with an [i-node, pid] pair.
write 和fsync (page 8) ¶
write():- 将数据写入持久存储,但这可能不会立即发生。
- 出于性能原因,文件系统会将写入操作缓冲在内存中一段时间(例如 5 秒或 30 秒
) 。之后,写入操作才会实际提交到存储设备。
fsync():- 强制将所有脏数据(尚未写入的数据)同步到磁盘。
- 这个系统调用确保了数据在返回前已经写入到物理存储,常用于需要高数据一致性的场景(如数据库
) 。
write 和 fsync 代码示例 (page 8)
获取文件信息stat (Getting Information about Files) (page 9) ¶
Unix 系统使用 struct stat 结构体来存储文件的各种信息,可以通过 stat() 系列系统调用获取。
硬链接 vs. 软链接 (Hard link vs soft link) (page 11-13, 18) ¶
- 链接 (Link):文件可以通过多个名称在一个或多个目录中被知晓。这些多重名称被称为链接。
- 硬链接 (Hard link):
- 硬链接是一个目录条目,它与文件关联。多个名称(硬链接)可以指向同一个 i-node。
- 在同一个文件系统内,文件可以有多个名称。
- 目录中的文件名
.是指向目录本身的硬链接。 - 目录中的文件名
..是指向父目录的硬链接。 - 硬链接数不会因为软链接而增加。
- 不同 i-node。
- 软链接 (Soft link) / 符号链接 (Symbolic link or symlink):
- 软链接是一个包含另一个文件路径名的文件。
- 软链接与硬链接不同,它可以指向目录,并且可以跨越文件系统边界。
- 如果目标文件被删除,软链接将失效 (invalided),变成悬空链接。
软链接示例 (page 18)
parallels@ubuntu :~/os-course$ echo hello > file1
parallels@ubuntu :~/os-course$ cat file1
hello
parallels@ubuntu :~/os-course$ ln -s file1 file2
parallels@ubuntu :~/os-course$ ls -i file*
3670573 file1 3670575 file2
parallels@ubuntu :~/os-course$ rm file1
parallels@ubuntu :~/os-course$ ls -l file*
lrwxrwxrwx 1 parallels parallels 6 Dec 17 21:14 file2 -> file1
parallels@ubuntu :~/os-course$ rm file2
parallels@ubuntu :~/os-course$ ls -l file*
ls: cannot access 'file*': No such file or directory
echo hello > file1:创建文件file1。ln -s file1 file2:创建file2作为file1的软链接。ls -i file*:查看file1和file2的 i-node 编号。可以看到它们不同 (3670573vs3670575),这验证了软链接有自己的 i-node。rm file1:删除原始文件file1。ls -l file*:此时file2仍然存在,但它指向的目标file1已经不存在了,所以file2变成了无效链接 (invalided link) 或悬空链接。rm file2:删除软链接file2本身。
引用计数 (Reference count) (page 17) ¶
当文件有硬链接时,系统会维护一个引用计数。rm 命令实际上是调用 unlink。只有当文件的引用计数降为 0 时,文件才会被物理删除。
引用计数示例 (page 17)
parallels@ubuntu :~/os-course$ ls -l file1
-rw-rw-r-- 1 parallels parallels 6 Dec 17 21:02 file1
parallels@ubuntu :~/os-course$ ln file1 file2
parallels@ubuntu :~/os-course$ ls -l file1 file2
-rw-rw-r-- 2 parallels parallels 6 Dec 17 21:02 file1
-rw-rw-r-- 2 parallels parallels 6 Dec 17 21:02 file2
parallels@ubuntu :~/os-course$ ln file1 file3
parallels@ubuntu :~/os-course$ ls -l file1 file2 file3
-rw-rw-r-- 3 parallels parallels 6 Dec 17 21:02 file1
-rw-rw-r-- 3 parallels parallels 6 Dec 17 21:02 file2
-rw-rw-r-- 3 parallels parallels 6 Dec 17 21:02 file3
parallels@ubuntu :~/os-course$ rm file3
parallels@ubuntu :~/os-course$ ls -l file1 file2
-rw-rw-r-- 2 parallels parallels 6 Dec 17 21:02 file1
-rw-rw-r-- 2 parallels parallels 6 Dec 17 21:02 file2
parallels@ubuntu :~/os-course$ rm file2
parallels@ubuntu :~/os-course$ ls -l file1
-rw-rw-r-- 1 parallels parallels 6 Dec 17 21:02 file1
上述输出中,file1、file2、file3 都是硬链接,它们指向同一个底层文件。
ls -l file1:file1的链接数为 1。ln file1 file2:创建file2作为file1的硬链接。此时file1和file2的链接数都变为 2。ln file1 file3:创建file3。此时file1、file2、file3的链接数都变为 3。rm file3:删除file3。此时file1和file2的链接数都变为 2。文件本身没有被物理删除,因为引用计数不为 0。rm file2:删除file2。此时file1的链接数变为 1。文件仍然没有被物理删除。- 如果再执行
rm file1,链接数变为 0,文件才会被物理删除。
移除文件:unlink (Removing Files: unlink) (page 10)¶
为什么我们移除文件时,有时系统调用是 unlinkat 而不是 remove 或 delete?
创建一个文件通常涉及两个主要步骤:
- 创建结构 (making a structure):操作系统创建一个 i-node 等结构来跟踪文件的所有相关信息。
- 链接名称 (linking a human-readable name):将一个用户可读的名称链接到这个文件(或 i-node
) ,并将这个链接放入目录中。
因此,移除文件通常是解除链接 (unlink) 过程,即从目录中移除指向文件的链接。
unlink() 系统调用 (page 16)
unlink() 删除文件系统中的一个名称。如果该名称是文件的最后一个链接,并且没有进程打开该文件,那么该文件将被删除,其空间将可用于重用。
FS 组织示例 (An Example of FS Organization) (page 21-25) ¶
一个简单的文件系统组织示例:
- 假设有 64 个块,块大小为 4KB。
- 数据区 (Data Region):保留大部分块用于存储实际数据。例如,64 块中的 56 块(块 8 到 63)用于数据。
- i-node 区 (Inodes):保留一部分块用于存储 i-node。如果 i-node 大小为 256 字节,4KB 的块可以容纳 16 个 i-node。那么 5 个块可以容纳 80 个 i-node,即支持 80 个文件(或目录
) 。- i-node 表占用块 3 到 7。
- 位图 (Bitmap):
- 一个位图用于管理空闲 i-node (
i: inode bitmap)。 - 一个位图用于管理空闲数据区 (
d: data region bitmap)。 - 例如,i-node 位图占用块 1,数据区位图占用块 2。
- 一个位图用于管理空闲 i-node (
- 超级块 (Superblock):
- 包含文件系统的元信息:i-node/ 数据块的数量、i-node 表起始位置、数据区起始位置以及一个魔数 (magic number)。
- 例如,超级块占用块 0。
文件系统块布局 (page 25)
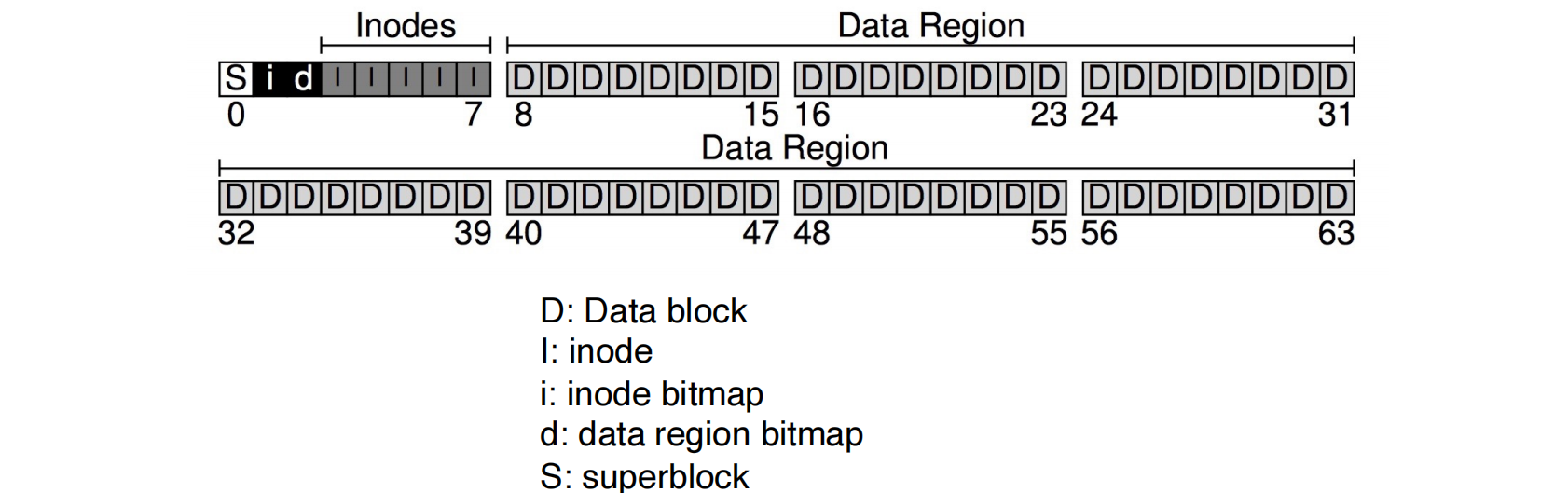
图示中,块 3-7 是 Inodes (I), 块 1 是 inode bitmap (i), 块 2 是 data region bitmap (d), 块 0 是 Superblock (S)。块 8-63 是 Data Region (D)。
i-node 地址计算 (inode address calculation) (page 26) ¶
假设要读取 i-node 编号 No. 32:
- 每个 i-node 大小为 256 字节。
- i-node 32 的偏移量 = \(32 \times 256 \text{ bytes} = 8 \text{ KB}\)。
- 要找到 i-node 32 的物理地址,需要加上所有控制块(超级块、位图)的大小,以及 i-node 表的起始地址。
- 起始地址 = 4KB ( 超级块 ) + 8KB ( 位图 ) + 8KB (i-node 偏移量 ) = 20KB。
- 所以 i-node 32 在磁盘上的地址是 20KB。
缓存和缓冲 (Caching and Buffering) (page 32) ¶
为了提高文件系统性能,缓存和缓冲至关重要:
- 如果没有缓存,每次打开文件都需要两次读取(一次用于目录,一次用于 i-node
) ,每个目录层级都需要两次读取。 - 早期的系统会分配固定大小的缓存来保存热门块。
- 现代系统使用统一页面缓存 (unified page cache) 来同时缓存虚拟内存页面和文件系统页面,避免双重缓存。
- 写入缓冲 (Write buffering):数据不会立即写入磁盘,而是先缓冲 5-30 秒后才同步写入磁盘。这提高了写入性能,但增加了数据丢失的风险。
- 数据库等应用程序通常会直接进行 I/O (direct IO) 而不经过文件系统缓存,直接操作原始数据 (raw data),以获得更严格的控制和性能。
实践总结 (Takeaway) (page 33) ¶
文件和目录实践部分的要点包括:
- 文件接口 (File interfaces):外部名称(用户可见)和内部名称(低级名称,i-node
) 。 - 目录 (Directory):将外部名称翻译为内部名称。
- 硬链接 vs. 软链接 (Hard link vs soft link):理解它们之间的区别和用途。
- 磁盘上的文件系统布局 (On-disk layout of FS):理解超级块、i-node、数据块、位图的组织方式。