12 PCA
主成分分析概述 (page 3-4) ¶
主成分分析(Principal Component Analysis, PCA)是一种非常经典且应用广泛的数据分析方法,尤其在机器学习领域,它常被用作一种预处理技术,例如降维或特征提取。
历史渊源
PCA 的思想最早由 Karl Pearson 于 1901 年针对非随机变量提出。随后,Harold Hotelling 在 1933 年将其推广到随机变量,奠定了现代 PCA 的理论基础。
PCA 属于经典的多元统计分析方法之一。它是一种常用的无监督学习1 方法。
其核心思想是利用正交变换将一组可能相关的原始变量转换为一组线性无关的新变量,这些新变量被称为主成分。通常,主成分的个数会远少于原始变量的个数,从而达到降维的目的。PCA 不仅仅是为了减少变量数量,更重要的是它致力于发现数据中的基本结构,即变量之间的主要关系。
PCA 的目标
- 数据降维:用较少的主成分来表示原始数据的大部分变异。
- 特征提取:生成一组新的、信息量大的特征。
- 去相关:消除原始变量之间的线性相关性。
- 噪声过滤:通过保留方差较大的主成分,可能滤除方差较小的噪声成分。
基本想法 (page 5-6) ¶
PCA 的执行过程和核心理念可以概括为以下几点:
-
数据规范化:首先,通常会对原始数据进行规范化处理,使得每个变量的平均值为 0,方差为 1。这样做是为了消除不同变量量纲和数值范围差异带来的影响,确保每个变量在分析中具有同等的重要性。
-
正交变换:对规范化后的数据进行正交变换。原始数据中变量之间可能存在线性相关性,通过正交变换,可以得到一组新的、线性无关的变量(即主成分
) 。 -
最大化方差(信息保存):新变量(主成分)的选择原则是,第一个主成分是在所有可能的线性变换中方差最大的,第二个主成分是在与第一个主成分正交(不相关)的前提下使其方差次大,以此类推。变量的方差在 PCA 中被视为其所包含信息量的大小,因此,最大化方差等价于最大程度地保留原始数据中的信息。
-
近似表示与结构发现:
- 可以用少数几个主成分来近似地表示原始数据,同时揭示数据中的基本结构和主要模式。
- 通过将数据投影到由少数主成分构成的低维子空间,实现数据的降维。
从几何角度理解:
- 数据集中的每个样本可以看作是实数空间(通常是正交坐标系)中的一个点。空间的每一个坐标轴代表一个原始变量。规范化处理后,数据点将分布在原点附近。
- 对原坐标系中的数据进行主成分分析,在几何上等价于进行坐标系的旋转变换。数据点被投影到这个新的坐标系的坐标轴上。
- 新坐标系的第一坐标轴、第二坐标轴等,分别代表第一主成分、第二主成分等。
- 数据在每个新轴上的坐标值的平方和(在数据中心化后)表示了对应主成分的方差。
- PCA 所选择的这个新坐标系,是在所有可能的新坐标系中,使得各坐标轴上的方差之和(即总方差)最大的那一个。
图解示例 (page 7-11) ¶
二维数据降维示例
假设我们有二维数据,由两个线性相关的变量 \(x_1\) 和 \(x_2\) 表示,如图 (a) 所示,数据点呈现椭圆状分布。
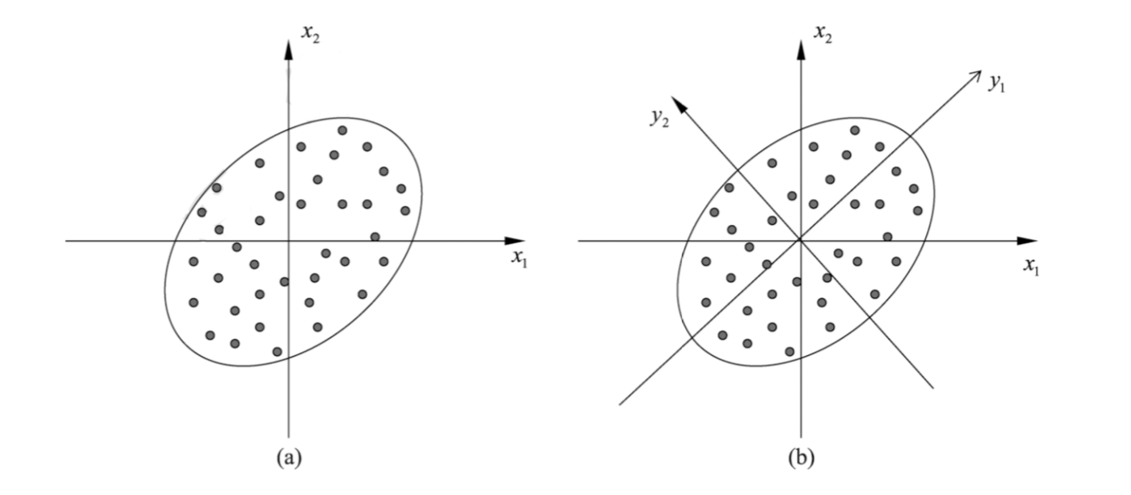
特性:
- 在新坐标系中,变量 \(y_1\) 和 \(y_2\) 是线性无关的。知道一个变量 \(y_1\) 的取值,对另一个变量 \(y_2\) 的预测是完全随机的(在中心化数据下,它们的协方差为 0
) 。- 降维:如果只选择第一主成分 \(y_1\) 轴来表示数据,就等价于将所有数据点投影到椭圆的长轴上。这样,二维空间的数据就被压缩到了一维空间中,损失了 \(y_2\) 方向上的信息,但保留了 \(y_1\) 方向(方差最大方向)的信息。
几何解释 (page 10-11):
假设有三个样本点 A, B, C 在原始 \((x_1, x_2)\) 坐标系中。我们旋转坐标系得到新的 \(y_1\) 轴。
- 将 A, B, C 投影到 \(y_1\) 轴上,得到投影点 A', B', C'。
- 这些投影点在 \(y_1\) 轴上的坐标值(假设原点为 O)的平方和 \(OA'^2 + OB'^2 + OC'^2\) 代表了样本在变量 \(y_1\) 上的方差和(如果数据已中心化
) 。- PCA 旨在选取这样的 \(y_1\) 轴,使得这个平方和最大。
- 这等价于最小化样本点到 \(y_1\) 轴的投影距离的平方和,即 \(AA'^2 + BB'^2 + CC'^2\) 最小。因为根据勾股定理,\(OA^2 = OA'^2 + AA'^2\)。要使 \(OA'^2\) 最大(在 \(OA\) 固定的情况下
) ,就需要 \(AA'^2\) 最小。- 第二主成分等的选取,是在保证与已选坐标轴正交的条件下,类似地进行。
总体主成分分析与样本主成分分析 (page 12) ¶
PCA 可以从两个层面进行讨论:
- 总体主成分分析 (Population PCA):在理论上,假设我们拥有关于数据整体(population)的完整信息(如总体的均值和协方差矩阵
) ,在此基础上进行的主成分分析。 - 样本主成分分析 (Sample PCA):在实际应用中,我们通常只有从总体中抽取的一部分有限样本(observed data
) 。基于这些样本数据(如样本均值和样本协方差矩阵)进行的主成分分析。
总体主成分分析是样本主成分分析的理论基础。样本主成分分析可以看作是总体主成分分析的一种估计。
总体主成分分析 (Population PCA) ¶
定义和导出 (page 13-17) ¶
假设 \(\mathbf{x} = (x_1, x_2, \dots, x_m)^T\) 是一个 \(m\) 维随机变量,其均值向量为 \(\boldsymbol{\mu}\),协方差矩阵为 \(\mathbf{\Sigma}\)。
考虑从 \(m\) 维随机变量 \(\mathbf{x}\) 到 \(m\) 维随机变量 \(\mathbf{y} = (y_1, y_2, \dots, y_m)^T\) 的线性变换:
其中 \(\boldsymbol{\alpha}_i^T = (\alpha_{1i}, \alpha_{2i}, \dots, \alpha_{mi})\) 是变换的系数向量, \(i=1, 2, \dots, m\)。
根据随机变量的性质,我们可以得到新变量 \(y_i\) 的期望、方差以及不同新变量 \(y_i, y_j\) 之间的协方差:
- \(E(y_i) = \boldsymbol{\alpha}_i^T E(\mathbf{x}) = \boldsymbol{\alpha}_i^T \boldsymbol{\mu}\)
- \(\text{var}(y_i) = \text{var}(\boldsymbol{\alpha}_i^T \mathbf{x}) = \boldsymbol{\alpha}_i^T \mathbf{\Sigma} \boldsymbol{\alpha}_i\)
- \(\text{cov}(y_i, y_j) = \text{cov}(\boldsymbol{\alpha}_i^T \mathbf{x}, \boldsymbol{\alpha}_j^T \mathbf{x}) = \boldsymbol{\alpha}_i^T \mathbf{\Sigma} \boldsymbol{\alpha}_j\)
定义 16.1 ( 总体主成分 ) (page 15)
给定一个如上式 \(y_i = \boldsymbol{\alpha}_i^T \mathbf{x}\) 所示的线性变换,如果系数向量 \(\boldsymbol{\alpha}_i\) 满足下列条件,则称 \(y_1, y_2, \dots, y_m\) 分别为 \(\mathbf{x}\) 的第一主成分、第二主成分、...、第 \(m\) 主成分:
-
系数向量 \(\boldsymbol{\alpha}_i\) 是单位向量且两两正交:
- \(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_i = 1, \quad i=1,2,\dots,m\)
- \(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_j = 0, \quad i,j=1,2,\dots,m, \quad i \ne j\)
-
变量 \(y_i\) 与 \(y_j\) 互不相关:
- \(\text{cov}(y_i, y_j) = \boldsymbol{\alpha}_i^T \mathbf{\Sigma} \boldsymbol{\alpha}_j = 0, \quad i \ne j\)
-
方差依次最大化:
- 变量 \(y_1 = \boldsymbol{\alpha}_1^T \mathbf{x}\) 是在 \(\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_1 = 1\) 条件下,\(\mathbf{x}\) 的所有线性变换中方差 \(\text{var}(\boldsymbol{\alpha}_1^T \mathbf{x})\) 最大的;
- 变量 \(y_2 = \boldsymbol{\alpha}_2^T \mathbf{x}\) 是在 \(\boldsymbol{\alpha}_2^T \boldsymbol{\alpha}_2 = 1\) 且与 \(y_1\) 不相关 (\(\boldsymbol{\alpha}_2^T \boldsymbol{\alpha}_1 = 0\) 且 \(\boldsymbol{\alpha}_2^T \mathbf{\Sigma} \boldsymbol{\alpha}_1 = 0\)) 的条件下,\(\mathbf{x}\) 的所有线性变换中方差 \(\text{var}(\boldsymbol{\alpha}_2^T \mathbf{x})\) 最大的;
- 一般地,变量 \(y_i = \boldsymbol{\alpha}_i^T \mathbf{x}\) 是在 \(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_i = 1\) 且与 \(y_1, y_2, \dots, y_{i-1}\) 都不相关 (\(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_j = 0\) 且 \(\boldsymbol{\alpha}_i^T \mathbf{\Sigma} \boldsymbol{\alpha}_j = 0\) for \(j < i\)) 的条件下,\(\mathbf{x}\) 的所有线性变换中方差 \(\text{var}(\boldsymbol{\alpha}_i^T \mathbf{x})\) 最大的。
定义中的条件 (1) 表明线性变换是一个正交变换,\(\boldsymbol{\alpha}_1, \boldsymbol{\alpha}_2, \dots, \boldsymbol{\alpha}_m\) 构成一组标准正交基。 条件 (2) 和 (3) 给出了一个求解主成分的逐步方法:
- 第一步: 在 \(\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_1 = 1\) 条件下,求使 \(\text{var}(\boldsymbol{\alpha}_1^T \mathbf{x}) = \boldsymbol{\alpha}_1^T \mathbf{\Sigma} \boldsymbol{\alpha}_1\) 最大的 \(\boldsymbol{\alpha}_1\),得到 \(\mathbf{x}\) 的第一主成分 \(y_1 = \boldsymbol{\alpha}_1^T \mathbf{x}\)。
- 第二步: 在 \(\boldsymbol{\alpha}_2^T \boldsymbol{\alpha}_2 = 1\) 和 \(\boldsymbol{\alpha}_2^T \boldsymbol{\alpha}_1 = 0\)(以及 \(\boldsymbol{\alpha}_2^T \mathbf{\Sigma} \boldsymbol{\alpha}_1 = 0\))条件下,求使 \(\text{var}(\boldsymbol{\alpha}_2^T \mathbf{x}) = \boldsymbol{\alpha}_2^T \mathbf{\Sigma} \boldsymbol{\alpha}_2\) 最大的 \(\boldsymbol{\alpha}_2\),得到 \(\mathbf{x}\) 的第二主成分 \(y_2 = \boldsymbol{\alpha}_2^T \mathbf{x}\)。
- ...
- 第 k 步: 在 \(\boldsymbol{\alpha}_k^T \boldsymbol{\alpha}_k = 1\) 和 \(\boldsymbol{\alpha}_k^T \boldsymbol{\alpha}_j = 0\) ( 以及 \(\boldsymbol{\alpha}_k^T \mathbf{\Sigma} \boldsymbol{\alpha}_j = 0\)) for \(j=1, \dots, k-1\) 条件下,求使 \(\text{var}(\boldsymbol{\alpha}_k^T \mathbf{x}) = \boldsymbol{\alpha}_k^T \mathbf{\Sigma} \boldsymbol{\alpha}_k\) 最大的 \(\boldsymbol{\alpha}_k\),得到 \(\mathbf{x}\) 的第 \(k\) 主成分 \(y_k = \boldsymbol{\alpha}_k^T \mathbf{x}\)。
主要性质 (page 18) ¶
定理 16.1 ( 主成分与协方差矩阵的特征分解 )
设 \(\mathbf{x}\) 是 \(m\) 维随机变量,\(\mathbf{\Sigma}\) 是 \(\mathbf{x}\) 的协方差矩阵,\(\mathbf{\Sigma}\) 的特征值分别是 \(\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_m \ge 0\),这些特征值对应的单位特征向量分别是 \(\boldsymbol{\alpha}_1, \boldsymbol{\alpha}_2, \dots, \boldsymbol{\alpha}_m\)。则 \(\mathbf{x}\) 的第 \(k\) 主成分是:
\(\mathbf{x}\) 的第 \(k\) 主成分的方差是:
即协方差矩阵 \(\mathbf{\Sigma}\) 的第 \(k\) 个特征值。
这个定理是 PCA 的核心,它将寻找主成分的问题与求解协方差矩阵的特征值和特征向量联系起来。
主要性质的证明 (page 19-24) ¶
证明 ( 采用拉格朗日乘子法 2 )
1. 求第一主成分 \(y_1 = \boldsymbol{\alpha}_1^T \mathbf{x}\)
我们需要求解以下约束最优化问题:
定义拉格朗日函数:
对 \(\boldsymbol{\alpha}_1\) 求偏导并令其为 0:
这表明 \(\lambda\) 是 \(\mathbf{\Sigma}\) 的一个特征值,\(\boldsymbol{\alpha}_1\) 是对应的特征向量。目标函数为 \(\boldsymbol{\alpha}_1^T \mathbf{\Sigma} \boldsymbol{\alpha}_1 = \boldsymbol{\alpha}_1^T (\lambda \boldsymbol{\alpha}_1) = \lambda (\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_1) = \lambda \cdot 1 = \lambda\)。 为了最大化方差 \(\lambda\),我们应该选择 \(\mathbf{\Sigma}\) 的最大特征值,记为 \(\lambda_1\)。对应的单位特征向量即为 \(\boldsymbol{\alpha}_1\)。 所以,第一主成分 \(y_1 = \boldsymbol{\alpha}_1^T \mathbf{x}\),其方差 \(\text{var}(y_1) = \lambda_1\)。
2. 求第二主成分 \(y_2 = \boldsymbol{\alpha}_2^T \mathbf{x}\)
第二主成分 \(y_2\) 应该与 \(y_1\) 不相关,即 \(\text{cov}(y_1, y_2) = \boldsymbol{\alpha}_1^T \mathbf{\Sigma} \boldsymbol{\alpha}_2 = 0\)。 因为 \(\boldsymbol{\alpha}_1^T \mathbf{\Sigma} = (\mathbf{\Sigma} \boldsymbol{\alpha}_1)^T = (\lambda_1 \boldsymbol{\alpha}_1)^T = \lambda_1 \boldsymbol{\alpha}_1^T\),所以 \(\lambda_1 \boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_2 = 0\)。 如果 \(\lambda_1 \ne 0\),则 \(\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_2 = 0\),即 \(\boldsymbol{\alpha}_1\) 和 \(\boldsymbol{\alpha}_2\) 正交。
我们需要求解以下约束最优化问题:
定义拉格朗日函数
对 \(\boldsymbol{\alpha}_2\) 求导并令其为 0:
将上式左乘 \(\boldsymbol{\alpha}_1^T\):
由于 \(\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_2 = 0\) ( 正交性约束 ) 且 \(\boldsymbol{\alpha}_1^T \mathbf{\Sigma} \boldsymbol{\alpha}_2 = \text{cov}(y_1, y_2) = 0\) ( 不相关约束 ),且 \(\boldsymbol{\alpha}_1^T \boldsymbol{\alpha}_1 = 1\),则有: \(0 - 0 - \phi \cdot 1 = 0 \Rightarrow \phi = 0\)。
因此,式 (16.10) 简化为:
这表明 \(\lambda\) 是 \(\mathbf{\Sigma}\) 的一个特征值,\(\boldsymbol{\alpha}_2\) 是对应的单位特征向量。目标函数值为 \(\lambda\)。 为了使方差最大,我们选择除 \(\lambda_1\) 外最大的特征值,记为 \(\lambda_2\)。对应的单位特征向量为 \(\boldsymbol{\alpha}_2\)。 所以,第二主成分 \(y_2 = \boldsymbol{\alpha}_2^T \mathbf{x}\),其方差 \(\text{var}(y_2) = \lambda_2\)。
3. 一般情况 - 第 \(k\) 主成分
类似地,可以证明第 \(k\) 主成分 \(y_k = \boldsymbol{\alpha}_k^T \mathbf{x}\) 对应于协方差矩阵 \(\mathbf{\Sigma}\) 的第 \(k\) 大的特征值 \(\lambda_k\),而 \(\boldsymbol{\alpha}_k\) 是对应的单位特征向量。
综上,通过上述方法求得的第一、第二、...、第 \(m\) 主成分,其系数向量 \(\boldsymbol{\alpha}_1, \boldsymbol{\alpha}_2, \dots, \boldsymbol{\alpha}_m\) 分别是 \(\mathbf{\Sigma}\) 的按特征值大小顺序排列的单位特征向量。第 \(k\) 主成分的方差等于 \(\mathbf{\Sigma}\) 的第 \(k\) 个特征值 \(\lambda_k\)。
进一步的性质 (page 25-30) ¶
-
推论 16.1: \(m\) 维随机变量 \(\mathbf{y} = (y_1, y_2, \dots, y_m)^T\) 的分量依次是 \(\mathbf{x}\) 的第一主成分到第 \(m\) 主成分的充要条件是:
-
\(\mathbf{y} = \mathbf{A}^T \mathbf{x}\),其中 \(\mathbf{A} = [\boldsymbol{\alpha}_1, \boldsymbol{\alpha}_2, \dots, \boldsymbol{\alpha}_m]\) 是一个正交矩阵,列向量为 \(\mathbf{\Sigma}\) 的单位特征向量。
\[ \mathbf{A} = \begin{bmatrix} \alpha_{11} & \alpha_{12} & \dots & \alpha_{1m} \\ \alpha_{21} & \alpha_{22} & \dots & \alpha_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ \alpha_{m1} & \alpha_{m2} & \dots & \alpha_{mm} \end{bmatrix} \]( 注意:这里 \(\boldsymbol{\alpha}_k = (\alpha_{1k}, \dots, \alpha_{mk})^T\) 是第 \(k\) 个特征向量。) 1. \(\mathbf{y}\) 的协方差矩阵为对角矩阵: $$ \text{cov}(\mathbf{y}) = \mathbf{\Lambda} = \text{diag}(\lambda_1, \lambda_2, \dots, \lambda_m) $$ 其中 \(\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_m \ge 0\) 是 \(\mathbf{\Sigma}\) 的特征值。
从证明过程可知 \(\mathbf{\Sigma} \boldsymbol{\alpha}_k = \lambda_k \boldsymbol{\alpha}_k\)。写成矩阵形式为 \(\mathbf{\Sigma A} = \mathbf{A \Lambda}\)。 由于 \(\mathbf{A}\) 是正交矩阵,即 \(\mathbf{A}^T \mathbf{A} = \mathbf{A A}^T = \mathbf{I}\),所以可以得到: \(\mathbf{A}^T \mathbf{\Sigma A} = \mathbf{\Lambda}\) 和 \(\mathbf{\Sigma} = \mathbf{A \Lambda A}^T\) (这称为 \(\mathbf{\Sigma}\) 的特征值分解或谱分解)。
-
-
总体主成分的性质:
-
主成分的协方差矩阵是对角阵: \(\text{cov}(\mathbf{y}) = \mathbf{\Lambda} = \text{diag}(\lambda_1, \lambda_2, \dots, \lambda_m)\)。这意味着主成分之间互不相关。
-
总方差不变性: 总体主成分 \(\mathbf{y}\) 的方差之和等于原始随机变量 \(\mathbf{x}\) 的方差之和。 $$ \sum_{i=1}^m \lambda_i = \sum_{i=1}^m \sigma_{ii} $$ 其中 \(\sigma_{ii} = \text{var}(x_i)\) 是原始变量 \(x_i\) 的方差。
证明:利用矩阵的迹 (trace) 的性质 (\(\text{tr}(\mathbf{BC}) = \text{tr}(\mathbf{CB})\)): $$ \sum_{i=1}^m \text{var}(x_i) = \text{tr}(\mathbf{\Sigma}) = \text{tr}(\mathbf{A \Lambda A}^T) = \text{tr}(\mathbf{A}^T \mathbf{A \Lambda}) = \text{tr}(\mathbf{I \Lambda}) = \text{tr}(\mathbf{\Lambda}) = \sum_{i=1}^m \lambda_i = \sum_{i=1}^m \text{var}(y_i) $$
-
因子负荷量 (Factor Loading): 第 \(k\) 个主成分 \(y_k\) 与原始变量 \(x_i\) 的相关系数 \(\rho(y_k, x_i)\) 称为因子负荷量,它表示 \(y_k\) 与 \(x_i\) 的相关关系,也反映了 \(x_i\) 对 \(y_k\) 的贡献程度或 \(y_k\) 对 \(x_i\) 的解释程度。 $$ \rho(y_k, x_i) = \frac{\text{cov}(y_k, x_i)}{\sqrt{\text{var}(y_k)\text{var}(x_i)}} $$ 我们有 \(y_k = \boldsymbol{\alpha}_k^T \mathbf{x}\) 和 \(x_i = \mathbf{e}_i^T \mathbf{x}\) (其中 \(\mathbf{e}_i\) 是第 \(i\) 个分量为 1,其余为 0 的单位向量)。 \(\text{cov}(y_k, x_i) = \text{cov}(\boldsymbol{\alpha}_k^T \mathbf{x}, \mathbf{e}_i^T \mathbf{x}) = \boldsymbol{\alpha}_k^T \mathbf{\Sigma} \mathbf{e}_i\)。 因为 \(\mathbf{\Sigma} \boldsymbol{\alpha}_k = \lambda_k \boldsymbol{\alpha}_k \implies \boldsymbol{\alpha}_k^T \mathbf{\Sigma} = \lambda_k \boldsymbol{\alpha}_k^T\) (由于 \(\mathbf{\Sigma}\) 是对称的)。 所以 \(\text{cov}(y_k, x_i) = \lambda_k \boldsymbol{\alpha}_k^T \mathbf{e}_i = \lambda_k \alpha_{ik}\) (其中 \(\alpha_{ik}\) 是向量 \(\boldsymbol{\alpha}_k\) 的第 \(i\) 个分量)。 因此, $$ \rho(y_k, x_i) = \frac{\lambda_k \alpha_{ik}}{\sqrt{\lambda_k \sigma_{ii}}} = \frac{\sqrt{\lambda_k} \alpha_{ik}}{\sqrt{\sigma_{ii}}}, \quad k,i = 1,2,\dots,m \quad (16.20) $$
-
单个主成分的因子负荷量平方和: 第 \(k\) 个主成分 \(y_k\) 与所有 \(m\) 个原始变量 \(x_i\) 的因子负荷量(经方差 \(\sigma_{ii}\) 加权)的平方和等于该主成分的方差 \(\lambda_k\)。 $$ \sum_{i=1}^m \sigma_{ii} \rho^2(y_k, x_i) = \sum_{i=1}^m \sigma_{ii} \left( \frac{\lambda_k \alpha_{ik}^2}{\sigma_{ii}} \right) = \sum_{i=1}^m \lambda_k \alpha_{ik}^2 = \lambda_k \sum_{i=1}^m \alpha_{ik}^2 = \lambda_k (\boldsymbol{\alpha}_k^T \boldsymbol{\alpha}_k) = \lambda_k \cdot 1 = \lambda_k $$
-
单个原始变量被所有主成分解释的方差比例: \(m\) 个主成分与第 \(i\) 个原始变量 \(x_i\) 的因子负荷量的平方和为 1。 $$ \sum_{k=1}^m \rho^2(y_k, x_i) = 1 \quad (16.22) $$ 这是因为 \(y_1, \dots, y_m\) 构成了对 \(\mathbf{x}\) 空间的一个完整描述(通过正交变换),\(x_i\) 可以由 \(y_1, \dots, y_m\) 线性表示。由于 \(y_k\) 互不相关,所以 \(x_i\) 与向量 \((y_1, \dots, y_m)\) 的多重相关系数的平方 \(R^2(x_i | y_1, \dots, y_m)\) 等于 \(\sum_{k=1}^m \rho^2(x_i, y_k)\)。因为 \(x_i\) 本身就是这个变换空间的一部分,所以这个多重相关系数的平方为 1。
-
主成分的个数 (page 31-37) ¶
PCA 的主要目的是降维,所以一般选择 \(q \ll m\) 个主成分来代替 \(m\) 个原有变量。选择多少个主成分是一个重要的问题。
定理 16.2 ( 保留方差最大化 ) (page 31)
对任意正整数 \(q, 1 \le q \le m\),考虑正交线性变换 \(\mathbf{y} = \mathbf{B}^T \mathbf{x}\),其中 \(\mathbf{y}\) 是 \(q\) 维向量,\(\mathbf{B}^T\) 是 \(q \times m\) 矩阵,其列向量(即 \(\mathbf{B}\) 的列向量,或者说 \(\mathbf{B}^T\) 的行向量 \(\boldsymbol{\beta}_1, \dots, \boldsymbol{\beta}_q\))标准正交。令 \(\mathbf{y}\) 的协方差矩阵为 \(\mathbf{\Sigma_y} = \mathbf{B}^T \mathbf{\Sigma B}\)。 则 \(\mathbf{\Sigma_y}\) 的迹 \(\text{tr}(\mathbf{\Sigma_y})\)(即 \(q\) 个新变量的方差之和)在 \(\mathbf{B} = \mathbf{A}_q\) 时取得最大值。其中矩阵 \(\mathbf{A}_q = [\boldsymbol{\alpha}_1, \boldsymbol{\alpha}_2, \dots, \boldsymbol{\alpha}_q]\) 是由协方差矩阵 \(\mathbf{\Sigma}\) 的前 \(q\) 个(对应最大 \(q\) 个特征值的)单位特征向量按列组成的矩阵。 此时,最大值为 \(\sum_{k=1}^q \lambda_k\)。
定理 16.2 的证明 (page 32-36)
令 \(\boldsymbol{\beta}_k\) 是矩阵 \(\mathbf{B}\) 的第 \(k\) 列(即 \(\mathbf{B} = [\boldsymbol{\beta}_1, \dots, \boldsymbol{\beta}_q]\)
那么 \(\mathbf{\Sigma_y} = \mathbf{B}^T \mathbf{\Sigma B} = (\mathbf{AC})^T \mathbf{\Sigma} (\mathbf{AC}) = \mathbf{C}^T \mathbf{A}^T \mathbf{\Sigma A C}\)。 因为 \(\mathbf{A}^T \mathbf{\Sigma A} = \mathbf{\Lambda}\) (对角阵,对角元素为 \(\lambda_j\)),所以 \(\mathbf{\Sigma_y} = \mathbf{C}^T \mathbf{\Lambda C}\)。
\(\text{tr}(\mathbf{\Sigma_y}) = \text{tr}(\mathbf{C}^T \mathbf{\Lambda C}) = \text{tr}(\mathbf{C C}^T \mathbf{\Lambda})\) ( 利用迹的轮换性 ) 令 \(\mathbf{c}_j^T\) 为 \(\mathbf{C}\) 的第 \(j\) 行。\(\mathbf{C}^T \mathbf{\Lambda C}\) 的对角线元素 \(k\) 为 \(\mathbf{c}_k'^T \mathbf{\Lambda} \mathbf{c}_k'\) (这里 \(\mathbf{c}_k'\) 是 \(\mathbf{C}\) 的第 \(k\) 列)。
\(\mathbf{B}^T \mathbf{\Sigma B} = \mathbf{C}^T \mathbf{A}^T \mathbf{\Sigma A C} = \mathbf{C}^T \mathbf{\Lambda C}\)。 如果 \(\mathbf{c}_j^T\) 是 \(\mathbf{C}\) 的第 \(j\) 行,那么 \(\mathbf{C}^T \mathbf{\Lambda C} = \sum_{j=1}^m \lambda_j (\mathbf{c}_j \mathbf{c}_j^T)\) (这里 \(\mathbf{c}_j\) 是 \(m \times 1\) 列向量,是 \(\mathbf{C}^T\) 的第 \(j\) 列,即 \(\mathbf{C}\) 的第 \(j\) 行的转置)。 \(\text{tr}(\mathbf{B}^T \mathbf{\Sigma B}) = \text{tr}(\sum_{j=1}^m \lambda_j \mathbf{c}_j \mathbf{c}_j^T) = \sum_{j=1}^m \lambda_j \text{tr}(\mathbf{c}_j \mathbf{c}_j^T) = \sum_{j=1}^m \lambda_j (\mathbf{c}_j^T \mathbf{c}_j) = \sum_{j=1}^m \lambda_j \sum_{k=1}^q c_{jk}^2\)。 (这里 \(c_{jk}\) 是矩阵 \(\mathbf{C}\) 的第 \(j\) 行第 \(k\) 列元素)。
由于 \(\mathbf{B}\) 的列是标准正交的,\(\mathbf{B}^T\mathbf{B} = \mathbf{I}_q\)。 \(\mathbf{I}_q = \mathbf{B}^T\mathbf{B} = (\mathbf{AC})^T(\mathbf{AC}) = \mathbf{C}^T\mathbf{A}^T\mathbf{A C} = \mathbf{C}^T\mathbf{I C} = \mathbf{C}^T\mathbf{C}\)。 所以 \(\mathbf{C}^T\mathbf{C} = \mathbf{I}_q\),这意味着 \(\mathbf{C}\) 的 \(q\) 个列向量是标准正交的。 \(\text{tr}(\mathbf{C}^T\mathbf{C}) = \text{tr}(\mathbf{I}_q) = q\)。 \(\sum_{k=1}^q (\sum_{j=1}^m c_{jk}^2) = q\)。 (即 \(\mathbf{C}\) 的每一列的平方和为1: \(\sum_{j=1}^m c_{jk}^2 = 1\) for \(k=1,\dots,q\))。
我们要最大化 \(\sum_{j=1}^m \lambda_j (\sum_{k=1}^q c_{jk}^2)\),其中 \(\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_m \ge 0\)。 并且 \(\sum_{j=1}^m c_{jk}^2 = 1\) (C 的列是单位向量)。 另外,\(\sum_{k=1}^q (\sum_{j=1}^m c_{jk}^2) = q\)。 幻灯片 page 35: \(\sum_{k=1}^q c_{jk}^2 \le 1\) for \(j=1,\dots,m\) (因为 \(\mathbf{C}\) 的行向量长度不大于1,因为 \(\mathbf{CC}^T\) 的对角元素 \(\le 1\))。 且 \(\sum_{j=1}^m \sum_{k=1}^q c_{jk}^2 = q\)。
为了最大化 \(\sum_{j=1}^m \lambda_j (\sum_{k=1}^q c_{jk}^2)\),我们应该将权重 \((\sum_{k=1}^q c_{jk}^2)\) 尽可能分配给大的 \(\lambda_j\)。 当 \(\mathbf{B} = \mathbf{A}_q\) (即 \(\mathbf{B}\) 的列是 \(\boldsymbol{\alpha}_1, \dots, \boldsymbol{\alpha}_q\)) 时,\(\mathbf{C}\) 矩阵的前 \(q\) 行构成一个 \(q \times q\) 的单位矩阵 \(\mathbf{I}_q\),其余 \(m-q\) 行为零矩阵。 即 \(c_{jk} = 1\) if \(j=k \le q\), \(c_{jk}=0\) otherwise。 此时 \(\sum_{k=1}^q c_{jk}^2 = 1\) if \(j \le q\), and \(0\) if \(j > q\)。 则 \(\text{tr}(\mathbf{\Sigma_y}) = \sum_{j=1}^q \lambda_j \cdot 1 + \sum_{j=q+1}^m \lambda_j \cdot 0 = \sum_{j=1}^q \lambda_j\)。 这是能取得的最大值。
注 (page 36): 定理 16.2 表明,当选取协方差矩阵 \(\mathbf{\Sigma}\) 的前 \(q\) 个特征向量对应的 \(q\) 个主成分时,这些主成分的方差之和(即 \(\text{tr}(\mathbf{\Sigma_y})\))达到最大。这意味着选取前 \(q\) 个主成分能够最大限度地保留原有变量方差的信息。
定理 16.3 ( 信息损失最小化 ) (page 37)
考虑正交变换 \(\mathbf{y} = \mathbf{B}^T\mathbf{x}\),这里 \(\mathbf{B}^T\) 是 \(p \times m\) 矩阵。\(\text{tr}(\mathbf{\Sigma_y})\) 在 \(\mathbf{B} = \mathbf{A}_p\) 时取得最小值,其中 \(\mathbf{A}_p\) 由 \(\mathbf{A}\) 的后 \(p\) 列(对应最小的 \(p\) 个特征值)组成。 这意味着,当舍弃 \(\mathbf{A}\) 的后 \(p\) 列,即舍弃变量 \(\mathbf{x}\) 的后 \(p\) 个主成分时,原有变量的方差的信息损失最少。这些被舍弃的主成分的方差之和为 \(\sum_{j=m-p+1}^m \lambda_j\)。
方差贡献率 (page 38-40) ¶
为了决定保留多少个主成分 \(q\),经常使用方差贡献率的概念。
定义 16.2 ( 方差贡献率 ) (page 38)
- 第 \(k\) 主成分 \(y_k\) 的方差贡献率 \(\eta_k\) 定义为 \(y_k\) 的方差与所有主成分方差之和(即总方差)的比: $$ \eta_k = \frac{\lambda_k}{\sum_{i=1}^m \lambda_i} \quad (16.30) $$
- 前 \(q\) 个主成分 \(y_1, y_2, \dots, y_q\) 的累计方差贡献率定义为这 \(q\) 个主成分的方差之和与所有方差之和的比: $$ \text{Cumulative } \eta_q = \frac{\sum_{i=1}^q \lambda_i}{\sum_{i=1}^m \lambda_i} \quad (16.31) $$
选择 \(q\) 的准则:
通常选择一个 \(q\) 使得累计方差贡献率达到某个预定的百分比,如 80%,90% 或 95% 以上。这意味着所选取的主成分能解释原始数据的大部分变异。
局限性:累计方差贡献率反映了主成分保留总体信息的比例,但它不能直接反映对某一个特定原有变量 \(x_i\) 保留信息的比例。
定义 16.3 ( 主成分对原变量的贡献率 ) (page 40)
前 \(q\) 个主成分 \(y_1, y_2, \dots, y_q\) 对原有变量 \(x_i\) 的贡献率 \(v_i\) 定义为 \(x_i\) 与 \((y_1, y_2, \dots, y_q)\) 的多重相关系数的平方:
由于主成分 \(y_j\) 之间不相关,这个贡献率可以简化为:
这个值表示前 \(q\) 个主成分解释了原始变量 \(x_i\) 的方差的多大比例。
规范化变量的总体主成分 (page 41-44) ¶
在实际问题中,不同变量可能有不同的量纲或数值范围。例如,一个变量是长度(米
为了消除这个影响,常常对各个随机变量实施规范化 (standardization),使其均值为 0,方差为 1。 设 \(x_i\) 是第 \(i\) 个随机变量,其规范化后的变量 \(x_i^*\) 为:
对规范化后的随机变量 \(\mathbf{x}^* = (x_1^*, \dots, x_m^*)^T\) 进行主成分分析,此时: \(E(\mathbf{x}^*) = \mathbf{0}\);\(\text{cov}(\mathbf{x}^*)\) 就是原始变量 \(\mathbf{x}\) 的相关矩阵 (correlation matrix) \(\mathbf{R} = [\rho_{ij}]\),其中 \(\rho_{ij} = \frac{\text{cov}(x_i, x_j)}{\sqrt{\text{var}(x_i)\text{var}(x_j)}}\)。对角线元素 \(\rho_{ii}=1\)。
此时,PCA 是基于相关矩阵 \(\mathbf{R}\) 进行的。设 \(\mathbf{R}\) 的特征值为 \(\lambda_1^* \ge \lambda_2^* \ge \dots \ge \lambda_m^* \ge 0\),对应的单位特征向量为 \(\mathbf{e}_1^*, \mathbf{e}_2^*, \dots, \mathbf{e}_m^*\)。 规范化变量的主成分 \(y_k^* = (\mathbf{e}_k^*)^T \mathbf{x}^*\)。
规范化变量总体主成分的性质:
- 规范化变量主成分的协方差矩阵是 \(\mathbf{\Lambda}^* = \text{diag}(\lambda_1^*, \lambda_2^*, \dots, \lambda_m^*)\)。
-
相关矩阵 \(\mathbf{R}\) 的特征值之和为 \(m\): $$ \sum_{k=1}^m \lambda_k^* = \text{tr}(\mathbf{R}) = \sum_{i=1}^m \rho_{ii} = m $$
-
规范化随机变量 \(x_i^*\) 与主成分 \(y_k^*\) 的相关系数 ( 因子负荷量 ): 由于 \(\text{var}(x_i^*) = 1\),根据式 (16.20): $$ \rho(y_k^, x_i^) = \sqrt{\lambda_k^} e_{ik}^ $$
其中 \(e_{ik}^*\) 是特征向量 \(\mathbf{e}_k^*\) 的第 \(i\) 个分量。 3. 所有规范化随机变量 \(x_i^*\) 与主成分 \(y_k^*\) 的相关系数的平方和等于 \(\lambda_k^*\): $$ \sum_{i=1}^m \rho^2(y_k^, x_i^) = \sum_{i=1}^m (\sqrt{\lambda_k^} e_{ik}^)^2 = \lambda_k^ \sum_{i=1}^m (e_{ik}^)^2 = \lambda_k^ ((\mathbf{e}_k^)^T \mathbf{e}k^) = \lambda_k^ $$ 4. 规范化随机变量 \(x_i^*\) 与所有主成分 \(y_k^*\) 的相关系数的平方和等于 1: $$ \sum^m \rho^2(y_k^, x_i^) = \sum_{k=1}^m \lambda_k^ (e_{ik}^)^2 = 1 $$
( 这是因为 \((\mathbf{e}_i^*)^T \mathbf{R} \mathbf{e}_i^* = 1\), 且 \(\mathbf{R} = \sum_k \lambda_k^* \mathbf{e}_k^* (\mathbf{e}_k^*)^T\) )
何时使用协方差矩阵 vs 相关矩阵 ?
- 使用协方差矩阵 \(\mathbf{\Sigma}\):当所有变量具有相同的量纲,或者你希望变量的原始方差大小影响主成分的构成时。
- 使用相关矩阵 \(\mathbf{R}\)(即对数据进行规范化处理后求协方差矩阵
) :当变量具有不同的量纲或数值范围差异很大时,这是更常用的做法,因为它消除了量纲的影响,使得每个变量在分析开始时具有同等的重要性(方差为 1) 。
样本主成分分析 (Sample PCA) (page 45) ¶
总体主成分分析是定义在理论上的总体参数(如 \(\mathbf{\Sigma}\))之上的。在实际应用中,我们只有观测到的样本数据。样本主成分分析就是基于这些样本数据进行的。
样本主成分分析 (page 46) ¶
在实际问题中,我们需要在观测数据上进行主成分分析,这就是样本主成分分析。样本主成分也和总体主成分具有相同的性质,只是将总体参数替换为样本统计量。
样本主成分的定义和性质 (page 47-54) ¶
假设对 \(m\) 维随机变量 \(\mathbf{x} = (x_1, x_2, \dots, x_m)^T\) 进行了 \(n\) 次独立观测,得到观测样本 \(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_n\)。其中 \(\mathbf{x}_j = (x_{1j}, x_{2j}, \dots, x_{mj})^T\) 表示第 \(j\) 个观测样本,\(x_{ij}\) 表示第 \(j\) 个观测样本的第 \(i\) 个变量值。 观测数据可以用样本矩阵 \(\mathbf{X}\) 表示:
-
样本均值向量 \(\bar{\mathbf{x}}\): $$ \bar{\mathbf{x}} = \frac{1}{n} \sum_{j=1}^n \mathbf{x}j, \quad \text{ 其中 } \bar{x}_i = \frac{1}{n} \sum $$}^n x_{ij
-
样本协方差矩阵 \(\mathbf{S} = [s_{ij}]_{m \times m}\): $$ s_{ij} = \frac{1}{n-1} \sum_{k=1}^n (x_{ik} - \bar{x}i)(x_j) $$ } - \bar{x\(\mathbf{S}\) 是总体协方差矩阵 \(\mathbf{\Sigma}\) 的无偏估计。
-
样本相关矩阵 \(\mathbf{R} = [r_{ij}]_{m \times m}\): $$ r_{ij} = \frac{s_{ij}}{\sqrt{s_{ii}s_{jj}}} $$ \(\mathbf{R}\) 是总体相关矩阵的估计。
考虑线性变换 \(y_i = \mathbf{a}_i^T \mathbf{x}\),其中 \(\mathbf{a}_i\) 是系数向量。
- 对于样本数据,第 \(j\) 个观测样本的第 \(i\) 个主成分得分为 \(y_{ij} = \mathbf{a}_i^T \mathbf{x}_j\)。
- 第 \(i\) 个主成分的样本均值 \(\bar{y}_i = \mathbf{a}_i^T \bar{\mathbf{x}}\)。
- 第 \(i\) 个主成分的样本方差 \(\text{var}(y_i) = \mathbf{a}_i^T \mathbf{S} \mathbf{a}_i\)。
- 第 \(i\) 和第 \(k\) 个主成分的样本协方差 \(\text{cov}(y_i, y_k) = \mathbf{a}_i^T \mathbf{S} \mathbf{a}_k\)。
定义 16.4 ( 样本主成分 ) (page 52)
给定样本矩阵 \(\mathbf{X}\)。 - 样本第一主成分 \(y_1 = \mathbf{a}_1^T \mathbf{x}\) 是在 \(\mathbf{a}_1^T \mathbf{a}_1 = 1\) 条件下,使得 \(n\) 个样本点 \(\mathbf{x}_j (j=1,\dots,n)\) 在该方向上的样本方差 \(\mathbf{a}_1^T \mathbf{S} \mathbf{a}_1\) 最大的 \(\mathbf{x}\) 的线性变换。 - 样本第二主成分 \(y_2 = \mathbf{a}_2^T \mathbf{x}\) 是在 \(\mathbf{a}_2^T \mathbf{a}_2 = 1\) 和与 \(y_1\) 的样本协方差 \(\mathbf{a}_2^T \mathbf{S} \mathbf{a}_1 = 0\) 条件下,样本方差 \(\mathbf{a}_2^T \mathbf{S} \mathbf{a}_2\) 最大的 \(\mathbf{x}\) 的线性变换。 - 以此类推,样本第 \(i\) 主成分 \(y_i = \mathbf{a}_i^T \mathbf{x}\) 是在 \(\mathbf{a}_i^T \mathbf{a}_i = 1\) 和与 \(y_1, \dots, y_{i-1}\) 的样本协方差均为0的条件下,样本方差 \(\mathbf{a}_i^T \mathbf{S} \mathbf{a}_i\) 最大的 \(\mathbf{x}\) 的线性变换。
- 样本主成分与总体主成分具有同样的性质,只需将总体协方差矩阵 \(\mathbf{\Sigma}\) 及其特征值 \(\lambda_k\)、特征向量 \(\boldsymbol{\alpha}_k\) 替换为样本协方差矩阵 \(\mathbf{S}\) 及其特征值 \(\hat{\lambda}_k\)、特征向量 \(\hat{\boldsymbol{\alpha}}_k\)。
- 总体主成分的定理 16.2(保留方差最大化)及定理 16.3(信息损失最小化)对样本主成分依然成立。
数据规范化: 在使用样本主成分时,通常也需要对样本数据进行规范化。对样本矩阵的每个元素 \(x_{ij}\)(第 \(i\) 个变量的第 \(j\) 个观测值)进行如下变换:
其中 \(\bar{x}_i = \frac{1}{n}\sum_{j=1}^n x_{ij}\) 是第 \(i\) 个变量的样本均值,\(s_{ii} = \frac{1}{n-1}\sum_{j=1}^n (x_{ij}-\bar{x}_i)^2\) 是第 \(i\) 个变量的样本方差。 规范化后,每个变量的样本均值为 0,样本方差为 1。此时,样本协方差矩阵 \(\mathbf{S}^*\) 就等于样本相关矩阵 \(\mathbf{R}\)。
幻灯片 page 54 提到,为了方便,规范化后的变量 \(x_{ij}^*\) 仍记作 \(x_{ij}\),规范化的样本矩阵仍记作 \(\mathbf{X}\)。这时,样本协方差矩阵 \(\mathbf{S}\) 就是样本相关矩阵 \(\mathbf{R}\)。
- \(\mathbf{S}\) 是 \(\mathbf{\Sigma}\) 的无偏估计。
- \(\mathbf{R}\) 是总体相关矩阵的(近似)无偏估计。
- \(\mathbf{S}\) 的特征值和特征向量是 \(\mathbf{\Sigma}\) 的特征值和特征向量的极大似然估计。
相关矩阵的特征值分解算法 (page 55-59) ¶
当基于样本相关矩阵 \(\mathbf{R}\) 进行主成分分析时(即数据已规范化
-
数据规范化: 对观测数据按式 (16.48) 进行规范化处理,得到规范化数据矩阵 \(\mathbf{X}^*\) ( 仍记为 \(\mathbf{X}\))。 $\(x_{ij}^* = \frac{x_{ij} - \bar{x}_i}{\sqrt{s_{ii}}}\)$
-
计算样本相关矩阵 \(\mathbf{R}\): $\(\mathbf{R} = [r_{ij}]_{m \times m} \quad \text{其中 } r_{ij} = \frac{1}{n-1} \sum_{l=1}^n x_{il}^* x_{jl}^*\)$
( 如果 \(\mathbf{X}^*\) 是 \(m \times n\) 矩阵,则 \(\mathbf{R} = \frac{1}{n-1} \mathbf{X}^* (\mathbf{X}^*)^T\))。 2. 求解 \(\mathbf{R}\) 的特征值和特征向量: - 求解特征方程 \(|\mathbf{R} - \lambda \mathbf{I}| = 0\),得到 \(m\) 个特征值 \(\hat{\lambda}_1 \ge \hat{\lambda}_2 \ge \dots \ge \hat{\lambda}_m \ge 0\)。 - 对每个特征值 \(\hat{\lambda}_i\),求解 \((\mathbf{R} - \hat{\lambda}_i \mathbf{I})\mathbf{a}_i = \mathbf{0}\) 得到对应的单位特征向量 \(\mathbf{a}_i = (a_{1i}, a_{2i}, \dots, a_{mi})^T\)。 3. 选择主成分个数 \(k\): 计算方差贡献率 \(\eta_i = \hat{\lambda}_i / \sum \hat{\lambda}_j\) 和累计方差贡献率 \(\sum_{j=1}^k \eta_j\),选择使得累计贡献率达到预定值(如 80%-95%)的最小 \(k\) 值。 4. 计算 \(k\) 个样本主成分的表达式: 第 \(i\) 个主成分 \(y_i = \mathbf{a}_i^T \mathbf{x}^* = a_{1i}x_1^* + \dots + a_{mi}x_m^*\), for \(i=1,\dots,k\)。 5. ( 可选 ) 解释主成分: 计算 \(k\) 个主成分 \(y_j\) 与原(规范化)变量 \(x_i^*\) 的相关系数 ( 因子负荷量 ) \(\rho(x_i^*, y_j) = \sqrt{\hat{\lambda}_j} a_{ij}\),以及 \(k\) 个主成分对原变量 \(x_i^*\) 的贡献率 \(v_i = \sum_{j=1}^k \rho^2(x_i^*, y_j)\)。 6. 计算 \(n\) 个样本的 \(k\) 个主成分值 (PC scores): 将规范化样本数据 \(\mathbf{x}_j^* = (x_{1j}^*, \dots, x_{mj}^*)^T\) 代入 \(k\) 个主成分的表达式中: 第 \(j\) 个样本的第 \(i\) 个主成分值为 \(y_{ij} = \mathbf{a}_i^T \mathbf{x}_j^* = \sum_{l=1}^m a_{li} x_{lj}^*\)。 这样得到一个 \(k \times n\) 的主成分得分矩阵 \(\mathbf{Y}\)。
数据矩阵的奇异值分解 (SVD) 算法 (page 67-70) ¶
主成分分析也可以通过对数据矩阵的奇异值分解 (SVD) 3 来实现。这在计算上可能更稳定和高效,特别是当变量数 \(m\) 远大于样本数 \(n\) ( 或反之 ) 时。
假设我们有 \(k\) 个主成分。给定样本矩阵 \(\mathbf{X}\) (\(m \times n\),每行(变量)已中心化,即均值为 0)。
-
构造新的 \(n \times m\) 矩阵 \(\mathbf{X}'\): 为了与协方差矩阵 \(\mathbf{S} = \frac{1}{n-1}\mathbf{X}\mathbf{X}^T\) (假设 \(\mathbf{X}\) 行是变量,列是样本,已中心化) 联系起来,我们通常处理的是 \(\mathbf{X}\)。 幻灯片 (page 68) 定义了一个新的矩阵: $$ \mathbf{X}' = \frac{1}{\sqrt{n-1}} \mathbf{X}^T $$ 此时 \(\mathbf{X}'\) 是 \(n \times m\) 矩阵。如果原始 \(\mathbf{X}\) 的每一行(变量)均值为0,则 \(\mathbf{X}'\) 的每一列均值为 0。 那么: $$ (\mathbf{X}')^T \mathbf{X}' = \left(\frac{1}{\sqrt{n-1}} \mathbf{X}\right) \left(\frac{1}{\sqrt{n-1}} \mathbf{X}^T\right) = \frac{1}{n-1} \mathbf{X} \mathbf{X}^T = \mathbf{S}_X $$
这里 \(\mathbf{S}_X\) 就是原始变量的样本协方差矩阵(如果 \(\mathbf{X}\) 的行是变量,已中心化
) 。 PCA的目标是求 \(\mathbf{S}_X\) 的特征向量(主成分方向 \(\mathbf{a}_k\))和特征值(主成分方差 \(\lambda_k\))。 -
对 \(\mathbf{X}'\) 进行 SVD: 设 \(\mathbf{X}' = \mathbf{U \Sigma_S V}^T\),其中:
- \(\mathbf{U}\) 是 \(n \times n\) 左奇异向量矩阵 ( 列正交 )。
- \(\mathbf{\Sigma_S}\) 是 \(n \times m\) 对角矩阵,对角线上是奇异值 \(\sigma_1 \ge \sigma_2 \ge \dots \ge \sigma_r > 0\) (\(r\) 是 \(\mathbf{X}'\) 的秩 )。
- \(\mathbf{V}\) 是 \(m \times m\) 右奇异向量矩阵 ( 列正交 )。
那么 \((\mathbf{X}')^T \mathbf{X}' = (\mathbf{V \Sigma_S}^T \mathbf{U}^T)(\mathbf{U \Sigma_S V}^T) = \mathbf{V} (\mathbf{\Sigma_S}^T \mathbf{\Sigma_S}) \mathbf{V}^T\)。 令 \(\mathbf{D} = \mathbf{\Sigma_S}^T \mathbf{\Sigma_S}\),这是一个 \(m \times m\) 的对角矩阵,其对角元素为 \(\sigma_j^2\)。 所以 \(\mathbf{S}_X = \mathbf{V D V}^T\)。 这正是 \(\mathbf{S}_X\) 的特征值分解形式。 - \(\mathbf{S}_X\) 的特征向量是 \(\mathbf{V}\) 的列向量 \(v_j\) (这些就是主成分的方向 \(\mathbf{a}_j\))。 - \(\mathbf{S}_X\) 的特征值是 \(\mathbf{D}\) 的对角元素 \(\lambda_j = \sigma_j^2\) (这些就是主成分的方差)。
-
提取主成分: \(\mathbf{V}\) 的列向量即为所求的主成分系数向量。选择前 \(k\) 个奇异值对应的 \(\mathbf{V}\) 的前 \(k\) 列,记为 \(\mathbf{V}_k = [\mathbf{v}_1, \dots, \mathbf{v}_k]\) (即 \(\mathbf{A}_k = [\mathbf{a}_1, \dots, \mathbf{a}_k]\))。
-
计算主成分得分: 样本主成分矩阵 \(\mathbf{Y}\) (\(k \times n\)) 为: $$ \mathbf{Y} = \mathbf{V}_k^T \mathbf{X} $$ (注意:如果原始PCA是基于 \(\mathbf{X}_{m \times n}\),则 \(\mathbf{Y}_{k \times n} = \mathbf{A}_k^T \mathbf{X}_{m \times n}\)。这里的 \(\mathbf{X}\) 是中心化后的数据矩阵。)
算法 16.1 ( 主成分分析算法 - 基于 SVD) (page 70)
输入: \(m \times n\) 样本矩阵 \(\mathbf{X}\),其每一行元素的均值为零。 输出: \(k \times n\) 样本主成分矩阵 \(\mathbf{Y}\)。 参数: 主成分个数 \(k\)。
- 构造新的 \(n \times m\) 矩阵 \(\mathbf{X}' = \frac{1}{\sqrt{n-1}}\mathbf{X}^T\)。( 此时 \(\mathbf{X}'\) 每一列的均值为零 )。
- 对矩阵 \(\mathbf{X}'\) 进行截断奇异值分解,得到 \(\mathbf{X}' \approx \mathbf{U}_k \mathbf{\Sigma}_{S,k} \mathbf{V}_k^T\)。 (即保留前 \(k\) 个奇异值和对应的奇异向量。矩阵 \(\mathbf{V}_k\) 的前 \(k\) 列构成 \(k\) 个样本主成分的方向。)
- 求 \(k \times n\) 样本主成分矩阵 \(\mathbf{Y} = \mathbf{V}_k^T \mathbf{X}\)。 (注意: 这里 \(\mathbf{V}_k\) 是 \(m \times k\) 矩阵,\(\mathbf{X}\) 是 \(m \times n\) 矩阵,所以 \(\mathbf{V}_k^T\) 是 \(k \times m\),\(\mathbf{Y}\) 是 \(k \times n\)。)
应用实例 (page 60-66) ¶
学生成绩分析
假设有 \(n\) 个学生参加四门课程(语文 \(x_1\), 外语 \(x_2\), 数学 \(x_3\), 物理 \(x_4\))的考试。对考试成绩数据进行标准化处理后,得到样本相关矩阵 \(\mathbf{R}\) 如下:
| 课程 | 语文 | 外语 | 数学 | 物理 |
|---|---|---|---|---|
| 语文 | 1 | 0.44 | 0.29 | 0.33 |
| 外语 | 0.44 | 1 | 0.35 | 0.32 |
| 数学 | 0.29 | 0.35 | 1 | 0.60 |
| 物理 | 0.33 | 0.32 | 0.60 | 1 |
1. 特征值分解: 对 \(\mathbf{R}\) 进行特征值分解,得到按大小排序的特征值: \(\hat{\lambda}_1 = 2.17\), \(\hat{\lambda}_2 = 0.87\), \(\hat{\lambda}_3 = 0.57\), \(\hat{\lambda}_4 = 0.39\)。
2. 选择主成分个数 \(k\): 总方差(因为是相关矩阵)为 \(m=4\)。 累计方差贡献率: - \(k=1\): \(\eta_1 = 2.17/4 = 0.5425\) (54.3%) - \(k=2\): \((\hat{\lambda}_1 + \hat{\lambda}_2) / 4 = (2.17 + 0.87) / 4 = 3.04 / 4 = 0.76\) (76%) 假设要求累计方差贡献率大于75%,则选择 \(k=2\)。
3. 确定主成分表达式: 求出对应于 \(\hat{\lambda}_1, \hat{\lambda}_2\) 的单位特征向量 \(\mathbf{a}_1, \mathbf{a}_2\)。 根据表 16.2 (单位特征向量和主成分的方差贡献率): - \(\mathbf{a}_1 = (0.460, 0.476, 0.523, 0.537)^T\) (对应 \(\hat{\lambda}_1 = 2.17\), 贡献率 \(2.17/4 \approx 0.543\)) - \(\mathbf{a}_2 = (0.574, 0.486, -0.476, -0.456)^T\) (对应 \(\hat{\lambda}_2 = 0.87\), 贡献率 \(0.87/4 \approx 0.218\))
第一主成分 : \(y_1 = 0.460x_1^* + 0.476x_2^* + 0.523x_3^* + 0.537x_4^*\) 第二主成分: \(y_2 = 0.574x_1^* + 0.486x_2^* - 0.476x_3^* - 0.456x_4^*\) (其中 \(x_i^*\) 是标准化后的成绩)
4. 解释主成分 ( 因子负荷量 ): 因子负荷量 \(\rho(y_j^*, x_i^*) = \sqrt{\hat{\lambda}_j} a_{ij}\)。
| 项目 | \(x_1\) ( 语文 ) | \(x_2\) ( 外语 ) | \(x_3\) ( 数学 ) | \(x_4\) ( 物理 ) |
|---|---|---|---|---|
| \(y_1\) 的因子负荷量 | 0.678 | 0.701 | 0.770 | 0.791 |
| \(y_2\) 的因子负荷量 | 0.536 | 0.453 | -0.444 | -0.425 |
| \(y_1, y_2\) 对 \(x_i\) 的贡献率 | 0.747 | 0.697 | 0.790 | 0.806 |
- \(y_1\) ( 第一主成分 ): 所有因子负荷量均为正,且数值都比较大。这表明 \(y_1\) 代表了学生的整体学习成绩。各门课成绩提高都会使 \(y_1\) 提高。物理 (\(x_4\)) 和数学 (\(x_3\)) 的负荷量略高,说明它们在整体成绩中权重稍大。
- \(y_2\) ( 第二主成分 ): 语文 (\(x_1\)) 和外语 (\(x_2\)) 的因子负荷量为正,数学 (\(x_3\)) 和物理 (\(x_4\)) 的为负。这表明 \(y_2\) 反映了学生的文科成绩与理科成绩之间的差异或偏向。文科成绩高或理科成绩低都会使 \(y_2\) 提高。
5. 因子负荷量图 (page 66):
将原变量在以 \(y_1, y_2\) 为轴的平面上表示(坐标为因子负荷量
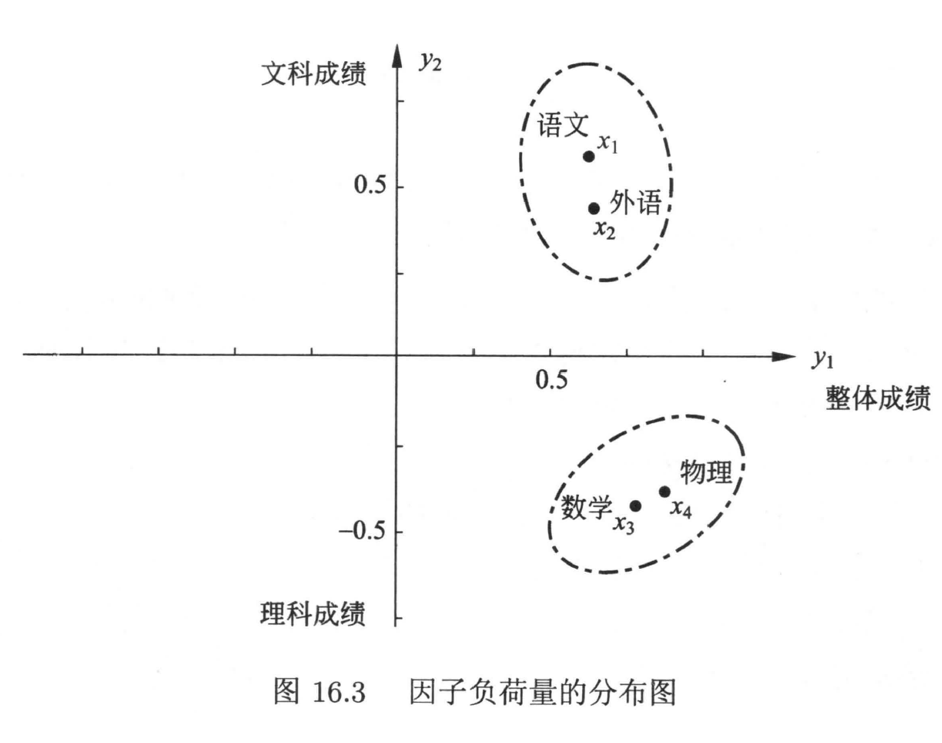
从图中可以看出:
- 语文 (\(x_1\)) 和外语 (\(x_2\)) 聚为一类,代表文科。
- 数学 (\(x_3\)) 和物理 (\(x_4\)) 聚为另一类,代表理科。
这与主成分的解释一致。
总结 (page 71-77) ¶
-
总体主成分定义:
- 假设 \(\mathbf{x}\) 是 \(m\) 维随机变量,均值为 \(\boldsymbol{\mu}\),协方差矩阵为 \(\mathbf{\Sigma}\)。
- 线性变换 \(y_i = \boldsymbol{\alpha}_i^T \mathbf{x} = \sum_{k=1}^m \alpha_{ki} x_k\)。
- 如果满足:
- \(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_i = 1\), \(\boldsymbol{\alpha}_i^T \boldsymbol{\alpha}_j = 0 (i \ne j)\)
- \(\text{cov}(y_i, y_j) = 0 (i \ne j)\)
- \(y_1\) 方差最大;\(y_2\) 是与 \(y_1\) 无关的方差最大的;以此类推。
则 \(y_i\) 为主成分。
-
总体主成分计算:
\(\mathbf{\Sigma}\) 的特征值为 \(\lambda_1 \ge \dots \ge \lambda_m \ge 0\),对应单位特征向量为 \(\boldsymbol{\alpha}_1, \dots, \boldsymbol{\alpha}_m\)。 第 \(i\) 主成分 \(y_i = \boldsymbol{\alpha}_i^T \mathbf{x}\),其方差 \(\text{var}(y_i) = \lambda_i\)。
-
主成分性质:
- \(\text{cov}(\mathbf{y}) = \mathbf{\Lambda} = \text{diag}(\lambda_1, \dots, \lambda_m)\)。
- \(\sum \text{var}(y_i) = \sum \lambda_i = \sum \text{var}(x_i) = \text{tr}(\mathbf{\Sigma})\)。
- 因子负荷量 : \(\rho(y_k, x_i) = \frac{\sqrt{\lambda_k}\alpha_{ik}}{\sqrt{\sigma_{ii}}}\)。
-
样本主成分分析: 基于样本协方差矩阵 \(\mathbf{S}\)(或样本相关矩阵 \(\mathbf{R}\))进行。 给定样本矩阵 \(\mathbf{X} = [\mathbf{x}_1, \dots, \mathbf{x}_n]\)。 样本协方差 \(s_{ij} = \frac{1}{n-1}\sum_{k=1}^n (x_{ik}-\bar{x}_i)(x_{jk}-\bar{x}_j)\)。 定义和性质与总体 PCA 类似,用样本量替换总体参数。
-
主成分分析方法 ( 下面的 \(\mathbf{X}\) 均为标准化 / 中心化后的结果 ):
- 相关 / 协方差矩阵的特征值分解:
- (规范化)计算 \(\mathbf{R}\) ( 或 \(\mathbf{S}\))。
- 求 \(\mathbf{R}\) 的 \(k\) 个最大特征值 \(\hat{\lambda}_i\) 和对应特征向量 \(\mathbf{a}_i\)。
- 构造正交矩阵 \(\mathbf{A}_k = [\mathbf{a}_1, \dots, \mathbf{a}_k]\)。
- 主成分得分 \(\mathbf{Y} = \mathbf{A}_k^T \mathbf{X}\)。
- 数据矩阵的奇异值分解 (SVD):
- 对(中心化)数据矩阵 \(\mathbf{X}_{m \times n}\) 构造 \(\mathbf{X}' = \frac{1}{\sqrt{n-1}}\mathbf{X}^T\)。
- 对 \(\mathbf{X}'\) 进行 SVD: \(\mathbf{X}' = \mathbf{U \Sigma_S V}^T\)。
- \(\mathbf{V}\) 的前 \(k\) 列 \(\mathbf{V}_k\) 是主成分系数。
- 主成分得分 \(\mathbf{Y} = \mathbf{V}_k^T \mathbf{X}\)。
- 相关 / 协方差矩阵的特征值分解:
-
无监督学习 (Unsupervised Learning): 机器学习的一类,其目标是从未标记的数据中学习模式和结构。与监督学习不同,无监督学习的训练数据没有预先定义的输出标签。常见的无监督学习任务包括聚类、降维、关联规则挖掘等。 ↩
-
拉格朗日乘子法 (Lagrange Multiplier Method): 一种寻找多元函数在其变量受到一个或多个等式约束时的极值的方法。通过引入拉格朗日乘子,可以将约束优化问题转化为无约束优化问题。 ↩
-
奇异值分解 (Singular Value Decomposition, SVD): 线性代数中一种重要的矩阵分解,将一个实数矩阵分解为三个矩阵的乘积:\(\mathbf{M} = \mathbf{U \Sigma V}^T\),其中 \(\mathbf{U}\) 和 \(\mathbf{V}\) 是正交矩阵,\(\mathbf{\Sigma}\) 是对角矩阵(对角元素称为奇异值
) 。SVD 在 PCA、推荐系统、图像压缩等领域有广泛应用。 ↩