13 MCMC
马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)法是一种强大的统计模拟方法,它结合了蒙特卡罗方法和马尔可夫链理论,主要用于从复杂概率分布中进行抽样,并进行近似数值计算。该方法在统计学习中,特别是概率模型的学习与推理中扮演着重要角色。
结合阅读:蒙特卡洛方法与 MCMC 采样
蒙特卡罗法 (Monte Carlo Method) (page 3, 5-19) ¶
蒙特卡罗法,又称统计模拟方法,核心是通过从概率模型中进行随机抽样来实现近似数值计算。它主要解决的问题是,在已知概率分布定义的情况下,通过随机抽样获得样本,然后对该概率分布的特征进行分析。例如,可以通过样本得到经验分布来估计总体分布,或者通过计算样本均值来估计总体期望。
蒙特卡罗法
蒙特卡罗法是一种统计模拟方法,通过从概率模型中随机抽样来近似计算数值。
蒙特卡罗法的核心是随机抽样 (random sampling)。
随机抽样方法 (page 7) ¶
蒙特卡罗法中常用的随机抽样方法包括:
- 直接抽样法:当概率密度函数形式简单,可以直接从其中抽取样本时使用。
- 接受 - 拒绝抽样法 (Accept-Reject Sampling Method):适用于概率密度函数复杂(如含有多个变量,各变量相互不独立,或密度函数形式复杂)导致不能直接抽样的情况。
- 重要性抽样法 (Importance Sampling Method):也是处理复杂概率密度函数的一种抽样方法。
接受 - 拒绝抽样法 (Accept-Reject Sampling Method) (page 8-12) ¶
假设我们有一个随机变量 \(X\),其取值 \(x \in \mathcal{X}\),概率密度函数为 \(p(x)\)。我们的目标是得到该概率分布的随机样本,以便对该分布进行分析。
当 \(p(x)\) 不可以直接抽样时,接受 - 拒绝抽样法提供了一种解决方案。它需要找到一个建议分布 (proposal distribution) \(q(x)\),该分布可以直接抽样,并且满足 \(cq(x) \ge p(x)\) 对于任意 \(x\) 成立,其中 \(c > 0\) 是一个常数。
算法步骤 :
- 输入: 目标概率分布的概率密度函数 \(p(x)\)。
- 输出: 目标概率分布的 \(n\) 个随机样本 \(x_1, x_2, \dots, x_n\)。
- 参数: 样本数 \(n\)。
具体流程 :
- 选择一个概率密度函数 \(q(x)\) 作为建议分布,使其对于任意 \(x\) 满足 \(cq(x) \ge p(x)\),其中 \(c > 0\)。
- 按照建议分布 \(q(x)\) 随机抽样得到一个候选样本 \(x^*\)。
- 从均匀分布 \(U(0,1)\) 中抽样得到一个随机数 \(u\)。
- 判断: 如果 \(u \le \frac{p(x^*)}{cq(x^*)}\),则将 \(x^*\) 作为抽样结果接受;否则,拒绝 \(x^*\) 并回到步骤 (2),重新抽样。
- 重复步骤 (2) 到 (4),直到得到 \(n\) 个随机样本。
接受 - 拒绝抽样法的优缺点 (page 12)
- 优点: 容易实现。
- 缺点: 效率可能不高。当 \(p(x)\) 的涵盖体积占 \(cq(x)\) 的涵盖体积的比例很低时,会导致拒绝的比例很高,抽样效率会很低。特别在高维空间中,即使 \(p(x)\) 与 \(cq(x)\) 很接近,两者涵盖体积的差异也可能很大,进一步降低效率。
数学期望估计 (Estimation of Mathematical Expectation) (page 13-14) ¶
蒙特卡罗法也可以用于数学期望的估计。 假设有一个随机变量 \(X\),取值 \(x \in \mathcal{X}\),其概率密度函数为 \(p(x)\),同时 \(f(x)\) 是定义在 \(\mathcal{X}\) 上的函数。我们的目标是求函数 \(f(x)\) 关于密度函数 \(p(x)\) 的数学期望 \(E_{p(x)}[f(x)]\)。
根据蒙特卡罗法,我们可以从概率分布 \(p(x)\) 中独立地抽取 \(n\) 个样本 \(x_1, x_2, \dots, x_n\),然后计算函数 \(f(x)\) 的样本均值 \(\hat{f}_n\):
根据大数定律 (Law of Large Numbers),当样本容量 \(n\) 趋于无穷大时,样本均值 \(\hat{f}_n\) 将以概率 1 收敛于数学期望 \(E_{p(x)}[f(x)]\):
因此,数学期望的近似计算方法为:
蒙特卡洛积分 (page 15-19) ¶
蒙特卡罗法也可以用于定积分的近似计算,这被称为蒙特卡罗积分 (Monte Carlo integration)。
假设目标是计算函数 \(h(x)\) 的积分 \(\int_{\mathcal{X}} h(x) dx\)。 如果能够将函数 \(h(x)\) 分解成一个函数 \(f(x)\) 和一个概率密度函数 \(p(x)\) 的乘积形式,即 \(h(x) = f(x)p(x)\),那么就有:
这意味着,任何一个函数的积分都可以表示为某个函数的数学期望形式,而这个数学期望又可以通过函数的样本均值来估计。 因此,我们可以利用样本均值来近似计算积分。给定一个概率密度函数 \(p(x)\),我们只需取 \(f(x) = \frac{h(x)}{p(x)}\)。
例 1 (page 17-18): 用蒙特卡罗积分法求 \(\int_0^1 e^{-x^2/2} dx\)
令 \(f(x) = e^{-x^2/2}\),并假设随机变量 \(X\) 在 \((0,1)\) 区间遵循均匀分布,其概率密度函数为 \(p(x)=1\) ( 当 \(0 < x < 1\))。
抽取 \(10\) 个随机样本 \(x_1, x_2, \dots, x_{10}\),计算函数均值 \(\hat{f}_{10} = \frac{1}{10} \sum_{i=1}^{10} e^{-x_i^2/2} = 0.832\)。
随机样本数越大,计算结果越精确。
例 2 (page 19): 用蒙特卡罗积分法求 \(\int_{-\infty}^\infty x \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{x^2}{2}\right) dx\)。
令 \(f(x) = x\),且 \(p(x) = \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{x^2}{2}\right)\),其中 \(p(x)\) 是标准正态分布的密度函数。
按照标准正态分布在 \((-\infty, \infty)\) 区间抽样 \(x_1, x_2, \dots, x_n\),取其平均值,就得到要求的积分值。当样本增大时,积分值趋于 0。
马尔可夫链 (Markov Chain) (page 20-59) ¶
定义与性质 (page 21-22) ¶
定义 19.1 ( 马尔可夫链 ) (page 21)
考虑一个随机变量的序列 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),其中 \(X_t\) 表示时刻 \(t\) 的随机变量,\(t = 0,1,2, \dots\)。每个随机变量 \(X_t\) (\(t=0,1,2, \dots\)) 的取值集合相同,称为状态空间 (state space),表示为 \(\mathcal{S}\)。随机变量可以是离散的,也可以是连续的。
以上随机变量的序列构成随机过程 (stochastic process)。
假设在时刻 0 的随机变量 \(X_0\) 遵循概率分布 \(P(X_0) = \pi_0\),称为初始状态分布 (initial state distribution)。
在某个时刻 \(t \ge 1\) 的随机变量 \(X_t\) 与前一个时刻的随机变量 \(X_{t-1}\) 之间有条件分布 \(P(X_t | X_{t-1})\)。如果 \(X_t\) 只依赖于 \(X_{t-1}\),而不依赖于过去的随机变量 \(\{X_0, X_1, \dots, X_{t-2}\}\),这一性质称为马尔可夫性 (Markovian property),即:
具有马尔可夫性的随机序列 \(X = \{X_0, X_1, \dots, X_t, \dots\}\) 称为马尔可夫链 (Markov chain),或马尔可夫过程 (Markov process)。条件概率分布 \(P(X_t | X_{t-1})\) 称为马尔可夫链的转移概率分布 (transition probability distribution)。转移概率分布决定了马尔可夫链的特性。
马尔可夫性的直观解释是“未来只依赖于现在(假设现在已知
如果转移概率分布 \(P(X_{t+s} | X_{t-1+s})\) 与时间 \(s\) 无关,即 \(P(X_{t+s} | X_{t-1+s}) = P(X_t | X_{t-1})\),则称该马尔可夫链为时间齐次的马尔可夫链 (time homogeneous Markov chain)。
上述定义是一阶马尔可夫链,它也可以扩展到 \(n\) 阶马尔可夫链,满足 \(P(X_t | X_0, X_1, \dots, X_{t-2}, X_{t-1}) = P(X_t | X_{t-n}, \dots, X_{t-2}, X_{t-1})\)。
离散状态马尔可夫链 (Discrete-state Markov Chain) (page 23-24) ¶
对于离散状态马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),随机变量 \(X_t\) (\(t=0,1,2, \dots\)) 定义在离散状态空间 \(\mathcal{S}\) 上,其转移概率分布可以由矩阵表示。
若马尔可夫链在时刻 \((t-1)\) 处于状态 \(i\),在时刻 \(t\) 移动到状态 \(j\),则将转移概率 (transition probability) 记作 \(p_{ij}\):
转移概率满足 \(p_{ij} \ge 0\) 且 \(\sum_j p_{ij} = 1\)。
转移概率矩阵 (Transition Probability Matrix) (page 24) ¶
马尔可夫链的转移概率 \(p_{ij}\) 可以由转移概率矩阵 (transition probability matrix) \(P\) 表示:
转移概率矩阵 \(P\) 满足 \(p_{ij} \ge 0\) 和 \(\sum_j p_{ij} = 1\) ( 即行元素之和为 1)。满足这两个条件的矩阵称为随机矩阵 (stochastic matrix)。
状态分布 (State Distribution) (page 25-26) ¶
考虑马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),在时刻 \(t\) (\(t=0,1,2, \dots\)) 的概率分布称为时刻 \(t\) 的状态分布 (state distribution at time \(t\)),记作 \(\pi(t)\):
其中 \(\pi_i(t)\) 表示时刻 \(t\) 状态为 \(i\) 的概率 \(P(X_t = i)\)。特别地,马尔可夫链的初始状态分布可以表示为 \(\pi(0)\),其中 \(\pi_i(0)\) 表示时刻 0 状态为 \(i\) 的概率 \(P(X_0 = i)\)。通常,初始分布 \(\pi(0)\) 的向量只有一个分量是 1,其余分量都是 0,这表示马尔可夫链从一个具体状态开始。
转移概率矩阵和状态分布的关系 (page 27, 31-32) ¶
有限离散状态的马尔可夫链可以通过有向图表示,结点表示状态,边表示状态之间的转移,边上的数值表示转移概率。从一个初始状态出发,根据有向边上定义的概率在状态之间随机跳转(或随机转移
马尔可夫链实际上是刻画随时间在状态之间转移的模型,假设未来的转移状态只依赖于现在的状态,而与过去的状态无关。
马尔可夫链 \(X\) 在时刻 \(t\) 的状态分布可以由在时刻 \((t-1)\) 的状态分布以及转移概率分布决定:
这是因为:
通过递推,可以得到:
这里的 \(P^t\) 称为 \(t\) 步转移概率矩阵 (t-step transition probability matrix),其元素 \(P^t_{ij}\) 表示时刻 0 从状态 \(j\) 出发,时刻 \(t\) 达到状态 \(i\) 的概率 \(P(X_t = i | X_0 = j)\)。\(P^t\) 也是随机矩阵。马尔可夫链的状态分布由初始分布和转移概率分布决定。
平稳分布 (page 36-43) ¶
定义 19.2 ( 平稳分布 ) (page 36)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),其状态空间为 \(\mathcal{S}\),转移概率矩阵为 \(P = (p_{ij})\)。如果存在状态空间 \(\mathcal{S}\) 上的一个分布 \(\pi = \begin{pmatrix} \pi_1 \\ \pi_2 \\ \vdots \end{pmatrix}\) 使得:
则称 \(\pi\) 为马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\) 的平稳分布 (stationary distribution)。
直观上,如果马尔可夫链的平稳分布存在,那么以该平稳分布作为初始分布,面向未来进行随机状态转移,之后任何一个时刻的状态分布都是该平稳分布。
引理 19.1 ( 平稳分布的充分必要条件 ) (page 37)
给定一个马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\),转移概率矩阵为 \(P = (p_{ij})\),则分布 \(\pi = (\pi_1, \pi_2, \dots)^T\) 为 \(X\) 的平稳分布的充分必要条件是 \(\pi = (\pi_1, \pi_2, \dots)^T\) 是下列方程组的解:
马尔可夫链可能存在唯一平稳分布,无穷多个平稳分布,或者不存在平稳分布。
连续状态马尔可夫链 (Continuous-state Markov Chain) (page 44-45) ¶
对于连续状态马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),随机变量 \(X_t\) (\(t=0,1,2, \dots\)) 定义在连续状态空间 \(\mathcal{S}\) 上。其转移概率分布由概率转移核 (transition kernel) 或简称为转移核 (transition kernel) \(P(x, A)\) 表示。
设 \(\mathcal{S}\) 是连续状态空间,对于任意的 \(x \in \mathcal{S}, A \subset \mathcal{S}\),定义为:
其中 \(p(x,\cdot)\) 是概率密度函数,满足 \(p(x,\cdot) \ge 0\) 且 \(\int_{\mathcal{S}} p(x,y) dy = 1\)。 \(P(x,A)\) 表示从状态 \(x\) 转移到集合 \(A\) 的转移概率。有时也将概率密度函数 \(p(x,\cdot)\) 称为转移核。
若马尔可夫链的状态空间 \(\mathcal{S}\) 上的概率分布 \(\pi(x)\) 满足条件:
则称分布 \(\pi(x)\) 为该马尔可夫链的平稳分布。等价地,\(\pi = P\pi\) 或写为:
马尔可夫链的性质 (page 46-58) ¶
马尔可夫链具有一些重要的性质,这些性质对于 MCMC 方法的收敛性和有效性至关重要。
1. 不可约性 (Irreducibility) (page 46-47) ¶
定义 19.3 ( 不可约 ) (page 46)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\)。对于任意状态 \(i, j \in \mathcal{S}\),如果存在一个时刻 \(t > 0\) 满足 \(P(X_t = i | X_0 = j) > 0\) (19.24),则称此马尔可夫链 \(X\) 是不可约的 (irreducible),否则称马尔可夫链是可约的 (reducible)。
直观上,一个不可约的马尔可夫链,从任意状态出发,当经过充分长时间后,可以到达任意状态。这意味着状态之间可以相互连通。
2. 非周期性 (Aperiodicity) (page 48-50) ¶
定义 19.4 ( 非周期 ) (page 48)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\)。对于任意状态 \(i \in \mathcal{S}\),如果时刻 0 从状态 \(i\) 出发,时刻 \(t\) 返回状态 \(i\) 的所有时间长 \(\{t : P(X_t = i | X_0 = i) > 0\}\) 的最大公约数是 1,则称此马尔可夫链 \(X\) 是非周期的 (aperiodic),否则称马尔可夫链是周期的 (periodic)。
直观上,一个非周期性的马尔可夫链,不存在一个状态,从这一个状态出发,再返回到这个状态时所经历的时间长呈一定的周期性。
定理 19.2 (page 50)
不可约且非周期的有限状态马尔可夫链,有唯一平稳分布存在。
3. 正常返性 (Positive Recurrent) (page 51-53) ¶
定义 19.5 ( 正常返 ) (page 51)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\)。对于任意状态 \(i, j \in \mathcal{S}\),定义概率 \(f^t_{ij}\) 为时刻 0 从状态 \(j\) 出发,时刻 \(t\) 首次转移到状态 \(i\) 的概率,即 \(f^t_{ij} = P(X_t = i, X_s \ne i, s = 1,2, \dots, t-1 | X_0 = j), t = 1,2, \dots\)。若对所有状态 \(i, j\) 都满足 \(\lim_{t \to \infty} f^t_{ij} > 0\),则称马尔可夫链 \(X\) 是正常返的 (positive recurrent)。
直观上,一个正常返的马尔可夫链,其中任意一个状态,从其他任意一个状态出发,当时间趋于无穷时,首次转移到这个状态的概率不为 0。
说明下图所示无限状态马尔可夫链,当 p>q 时是正常返的,当 p≤q 不是正常返的 (page 52)
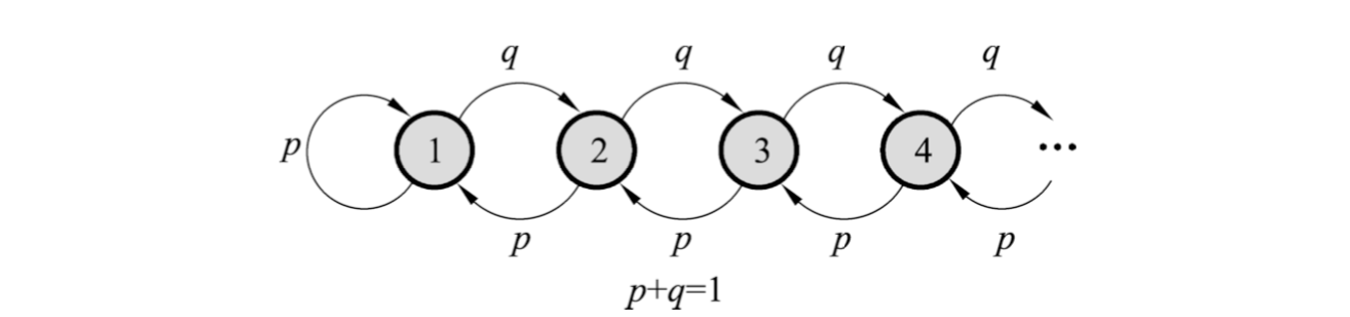
定理 19.3 (page 53)
不可约、非周期且正常返的马尔可夫链,有唯一平稳分布存在。
4. 遍历定理 (Ergodic Theorem) (page 54-56) ¶
定理 19.4 ( 遍历定理 ) (page 54)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\)。若马尔可夫链 \(X\) 是不可约、非周期且正常返的,则该马尔可夫链有唯一平稳分布 \(\pi = (\pi_1, \pi_2, \dots)^T\),并且转移概率的极限分布是马尔可夫链的平稳分布:
若 \(f(x)\) 是定义在状态空间上的函数,且 \(E_{\pi}[f(X)] < \infty\),则:
这里 \(\hat{f}_t = \frac{1}{t}\sum_{s=1}^t f(x_s)\)。
表达式 (19.26) 表示 \(\hat{f}_t \to E_{\pi}[f(X)]\),当 \(t \to \infty\) 时几乎处处成立或以概率 1 成立。
遍历定理的直观解释 (page 55):
- 满足相应条件的马尔可夫链,当时间趋于无穷时,马尔可夫链的状态分布趋近于平稳分布,随机变量的函数的样本均值以概率 1 收敛于该函数的数学期望。
- 样本均值可以认为是时间均值 (time average),而数学期望是空间均值 (space average)。遍历定理实际表述了遍历性的含义:当时间趋于无穷时,时间均值等于空间均值。
- 遍历定理的三个条件:不可约、非周期、正常返,保证了当时间趋于无穷时达到任意一个状态的概率不为 0。
在实际应用遍历定理时,我们通常会取一个足够大的整数 \(m\) 作为燃烧期 (burn-in period),认为经过 \(m\) 次迭代之后状态分布就是平稳分布。这时计算从第 \(m+1\) 次迭代到第 \(n\) 次迭代的均值:
5. 可逆马尔可夫链 (Reversible Markov Chain) (page 57-59) ¶
定义 19.6 ( 可逆马尔可夫链 ) (page 57)
设有马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),状态空间为 \(\mathcal{S}\),转移概率矩阵为 \(P\)。如果存在状态分布 \(\pi = (\pi_1, \pi_2, \dots)^T\),对于任意状态 \(i, j \in \mathcal{S}\),对任意一个时刻 \(t\) 满足:
或简写为:
则称此马尔可夫链 \(X\) 为可逆马尔可夫链 (reversible Markov chain),式 (19.30) 称为细致平衡方程 (detailed balance equation)。
直观上,如果有可逆的马尔可夫链,那么以该马尔可夫链的平稳分布作为初始分布,进行随机状态转移,无论是面向未来还是面向过去,任何一个时刻的状态分布都是该平稳分布。
定理 19.5 ( 细致平衡方程 ) (page 58)
满足细致平衡方程的状态分布 \(\pi\) 就是该马尔可夫链的平稳分布。即:
证明: 事实上,
因此,\((P\pi)_i = \pi_i\),即 \(P\pi = \pi\)。
可逆马尔可夫链一定有唯一平稳分布,给出了一个马尔可夫链有平稳分布的充分条件 ( 不是必要条件 )。也就是说,可逆马尔可夫链满足遍历定理 19.4 的条件。
说明下图所示马尔可夫链是不可逆的 (page 59)
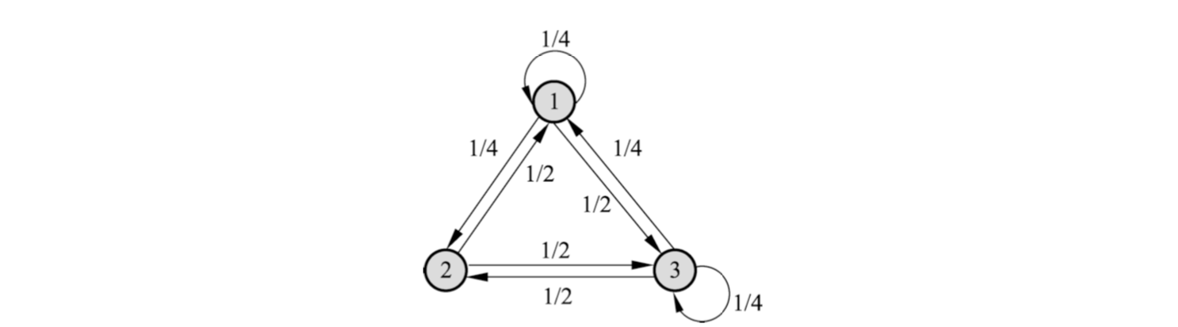
马尔可夫链蒙特卡罗法 (Markov Chain Monte Carlo, MCMC) (page 60-69) ¶
基本想法 (page 61-66) ¶
马尔可夫链蒙特卡罗法更适合于随机变量是多元的、密度函数是非标准形式的、随机变量各分量不独立等情况。
假设我们有一个多元随机变量 \(X\),满足 \(x \in \mathcal{X}\),其概率密度函数为 \(p(x)\)。同时 \(f(x)\) 是定义在 \(\mathcal{X}\) 上的函数。我们的目标是获得概率分布 \(p(x)\) 的样本集合,以及求函数 \(f(x)\) 的数学期望 \(E_{p(x)}[f(x)]\)。
MCMC 的基本想法 (page 62):
- 在随机变量 \(x\) 的状态空间 \(\mathcal{S}\) 上定义一个满足遍历定理的马尔可夫链 \(X = \{X_0, X_1, \dots, X_t, \dots\}\),使其平稳分布就是抽样的目标分布 \(p(x)\)。
- 然后在这个马尔可夫链上进行随机游走,每个时刻得到一个样本。
- 根据遍历定理,当时间趋于无穷时,样本的分布趋近平稳分布,样本的函数均值趋近函数的数学期望。
实际应用 (page 63):
当时间足够长时(时刻大于某个正整数 \(m\),称为燃烧期
构建具体的马尔可夫链 (page 64):
- 连续变量时,需要定义转移核函数。
- 离散变量时,需要定义转移矩阵。
一个方法是定义特殊的转移核函数或者转移矩阵,构建可逆马尔可夫链,这样可以保证遍历定理成立。
常用的马尔可夫链蒙特卡罗法有Metropolis-Hastings 算法和吉布斯抽样。由于这些马尔可夫链满足遍历定理,随机游走的起始点不影响得到的结果,即从不同的起始点出发,都会收敛到同一平稳分布。
MCMC 收敛性的判断 (page 65):
MCMC 方法的收敛性的判断通常是经验性的:
- 在马尔可夫链上进行随机游走,检验遍历均值是否收敛。具体地,每隔一段时间取一次样本,得到多个样本后,计算遍历均值。当计算的均值稳定后,认为马尔可夫链已经收敛。
- 在马尔可夫链上并行进行多个随机游走,比较各个随机游走的遍历均值是否接近一致。
MCMC 的样本性质 (page 66):
MCMC 法中得到的样本序列,相邻的样本点是相关的,而不是独立的。若需要独立样本时,可以在该样本序列中再次进行随机抽样,比如每隔一段时间取一次样本,将这样得到的子样本集合作为独立样本集合。
MCMC 与接受 - 拒绝抽样法的比较 (page 66)
马尔可夫链蒙特卡罗法比接受 - 拒绝法更容易实现,因为只需要定义马尔可夫链,而不需要定义建议分布。一般来说,MCMC 法比接受 - 拒绝法效率更高,没有大量被拒绝的样本,虽然燃烧期的样本也要抛弃。
基本步骤 (page 67) ¶
MCMC 方法可以概括为以下三步:
- 构造马尔可夫链: 在随机变量 \(x\) 的状态空间 \(\mathcal{S}\) 上构造一个满足遍历定理的马尔可夫链,使其平稳分布为目标分布 \(p(x)\)。
- 随机游走: 从状态空间的某一点 \(x_0\) 出发,用构造的马尔可夫链进行随机游走,产生样本序列 \(x_0, x_1, \dots, x_t, \dots\)。
- 计算均值: 应用马尔可夫链的遍历定理,确定正整数 \(m\) 和 \(n\) (\(m < n\)),得到样本集合 \(\{x_{m+1}, x_{m+2}, \dots, x_n\}\),求得函数 \(f(x)\) 的均值(遍历均值
) : $$ \hat{f} = \frac{1}{n-m} \sum_{i=m+1}^n f(x_i) $$
MCMC 与统计学习 (MCMC and Statistical Learning) (page 68-69) ¶
在统计学习中,特别是贝叶斯学习,MCMC 方法提供了一个通用的有效解决方案,用于计算后验概率中涉及的三种积分运算:
- 归范化 (normalization): 后验概率分母的积分 \(\int_{\mathcal{X}} p(y|x')p(x')dx'\)。
- 边缘化 (marginalization): 当存在隐变量 \(z \in \mathcal{Z}\) 时,后验概率的计算需要边缘化积分 \(p(x|y) = \int_{\mathcal{Z}} p(x,z|y)dz\)。
- 数学期望 (expectation): 如果有一个函数 \(f(x)\),需要计算其关于后验概率分布的数学期望 \(E_{P(x|y)}[f(x)] = \int_{\mathcal{X}} f(x)p(x|y)dx\)。
假设观测数据由随机变量 \(y \in \mathcal{Y}\) 表示,模型由随机变量 \(x \in \mathcal{X}\) 表示。贝叶斯学习通过贝叶斯定理计算给定数据条件下模型的后验概率,并选择后验概率最大的模型。 后验概率为 \(p(x|y) = \frac{p(y|x)p(x)}{\int_{\mathcal{X}} p(y|x')p(x')dx'}\)。
在贝叶斯学习中,如果我们将 \(x = (\alpha, \theta, z)\) 表示为超参数 \(\alpha\)、模型参数 \(\theta\) 和未观测数据 \(z\)。吉布斯抽样中各个变量 \(\alpha, \theta, z\) 的满条件分布存在如下关系:
- \(p(\alpha | \alpha_{-i}, \theta, z, y) \propto p(y|\theta)p(\alpha)\)
- \(p(\theta | \theta_{-j}, \alpha, z, y) \propto p(z,y|\theta)p(\theta|\alpha)\)
- \(p(z | z_{-k}, \alpha, \theta, y) \propto p(z,y|\theta)\)
其中 \(\alpha_{-i}\) 表示变量 \(\alpha_i\) 以外的所有变量,\(\theta_{-j}\) 和 \(z_{-k}\) 类似。 依照满条件概率分布的抽样可以通过依照这些条件概率分布的乘积的抽样进行。这样可以大幅减少抽样的计算复杂度,因为计算只涉及部分变量。
Metropolis-Hastings 算法 (page 70-92) ¶
Metropolis-Hastings (M-H) 算法是最基本的马尔可夫链蒙特卡罗法,用于从复杂概率分布中抽取样本。
基本原理 (page 71-77) ¶
假设要抽样的概率分布为 \(p(x)\)。Metropolis-Hastings 算法采用转移核 \(p(x, x')\) 的马尔可夫链, \(p(x, x') = q(x, x')\alpha(x, x')\)。
其中 \(q(x, x')\) 称为建议分布 (proposal distribution),\(\alpha(x, x')\) 称为接受分布 (acceptance distribution)。
-
建议分布 \(q(x, x')\):、
- 建议分布 \(q(x, x')\) 不需要额外定义,一般是另一个马尔可夫链的转移核,并且 \(q(x, x')\) 是不可约的,即其概率值恒不为 0。同时它是一个容易抽样的分布。
-
接受分布 \(\alpha(x, x')\):
-
接受分布为:
\[\alpha(x, x') = \min\left\{1, \frac{p(x')q(x',x)}{p(x)q(x,x')}\right\}\]
-
这时,转移核 \(p(x, x')\) 可以写成:
马尔可夫链上的随机游走方式 :
- 如果在时刻 \((t-1)\) 处于状态 \(x\),即 \(X_{t-1} = x\),则先按照建议分布 \(q(x, x')\) 抽样产生一个候选状态 (candidate state) \(x'\)。
- 然后按照接受分布 \(\alpha(x, x')\) 抽样决定是否接受状态 \(x'\)。
- 以概率 \(\alpha(x, x')\) 接受了 \(x'\),决定时刻 \(t\) 转移到状态 \(x'\)。
- 以概率 \(1 - \alpha(x, x')\) 拒绝 \(x'\),决定时刻 \(t\) 仍停留在状态 \(x\)。
具体地 : 从区间 \((0,1)\) 上的均匀分布中抽取一个随机数 \(u\),决定时刻 \(t\) 的状态 \(X_t\):
可以证明,转移核 \(p(x, x')\) 的马尔可夫链是可逆马尔可夫链(满足遍历定理
定理 19.6 (page 75)
由转移核 \(p(x, x')\) (19.38) ~ (19.40) 构成的马尔可夫链是可逆的,即:
并且 \(p(x)\) 是该马尔可夫链的平稳分布。
建议分布 \(q(x, x')\) 的形式 (page 78-80) ¶
建议分布 \(q(x, x')\) 有多种可能的形式:
-
对称建议分布 (Symmetric Proposal Distribution) ( 称为 Metropolis 选择):
假设建议分布是对称的,即对任意的 \(x\) 和 \(x'\) 有 \(q(x, x') = q(x', x)\)。 这时,接受分布 \(\alpha(x, x')\) 简化为:
\[\alpha(x, x') = \min\left\{1, \frac{p(x')}{p(x)}\right\}\]Metropolis 选择的一个特例是令 \(q(x, x') = q(|x-x'|)\),这时算法称为随机游走 Metropolis 算法 (Random Walk Metropolis algorithm)。例如,\(q(x, x') \propto \exp\left(-\frac{(x'-x)^2}{2}\right)\)。 Metropolis 选择的特点是当 \(x'\) 与 \(x\) 接近时,\(q(x, x')\) 的概率值高,否则概率值低。状态转移在附近点的可能性更大。
-
独立抽样建议分布 (Independent Sampling Proposal Distribution):
假设 \(q(x, x')\) 与当前状态 \(x\) 无关,即 \(q(x, x') = q(x')\)。 建议分布的计算按照 \(q(x')\) 独立抽样进行。此时,接受分布 \(\alpha(x, x')\) 可以写成:
\[\alpha(x, x') = \min\left\{1, \frac{w(x')}{w(x)}\right\}\]其中 \(w(x') = p(x')/q(x')\),\(w(x) = p(x)/q(x)\)。
独立抽样实现简单,但可能收敛速度慢,通常选择接近目标分布 \(p(x)\) 的分布作为建议分布 \(q(x)\)。
满条件分布 (Full Conditional Distribution) (page 81-85) ¶
马尔可夫链蒙特卡罗法的目标分布通常是多元联合概率分布 \(p(x) = p(x_1, x_2, \dots, x_k)\),其中 \(x = (x_1, x_2, \dots, x_k)^T\) 为 \(k\) 维随机变量。
如果条件概率分布 \(p(x_I | x_{-I})\) 中所有 \(k\) 个变量全部出现,其中 \(x_I = \{x_i, i \in I\}\),\(x_{-I} = \{x_i, i \notin I\}\),\(I \subset K = \{1,2, \dots, k\}\),那么称这种条件概率分布为满条件分布 (full conditional distribution)。
满条件分布的性质 :
对任意的 \(x, x' \in \mathcal{X}\) 和任意的 \(I \subset K\),有: $$ p(x_I | x_{-I}) = \frac{p(x)}{\int_I p(x)dx_I} \propto p(x) $$ 而且,对任意的 \(x, x' \in \mathcal{X}\) 和任意的 \(I \subset K\),有:
Metropolis-Hastings 算法中,可以利用上述性质,简化计算,提高计算效率。具体地,通过满条件分布概率的比值 \(p(x'_I | x'_{-I})/p(x_I | x_{-I})\),计算联合概率的比值 \(p(x')/p(x)\),而前者更容易计算。
算法 19.2 (Metropolis-Hastings 算法 ) (page 86-87) ¶
输入: 抽样的目标分布的密度函数 \(p(x)\),函数 \(f(x)\)。 输出: \(p(x)\) 的随机样本 \(x_{m+1}, x_{m+2}, \dots, x_n\),函数样本均值 \(f_{mn}\)。 参数: 收敛步数 \(m\),迭代步数 \(n\)。
步骤:
- 任意选择一个初始值 \(x_0\)。
- 对 \(i = 1,2, \dots, n\) 循环执行 :
- 设状态 \(x_{i-1} = x\),按照建议分布 \(q(x, x')\) 随机抽取一个候选状态 \(x'\)。
- 计算接受概率 \(\alpha(x, x') = \min\left\{1, \frac{p(x')q(x',x)}{p(x)q(x,x')}\right\}\)。
- 从区间 \((0,1)\) 中按均匀分布随机抽取一个数 \(u\)。若 \(u \le \alpha(x, x')\),则状态 \(x_i = x'\);否则,状态 \(x_i = x\)。
- 得到样本集合 \(\{x_{m+1}, x_{m+2}, \dots, x_n\}\)。
- 计算函数样本均值: $$ f_{mn} = \frac{1}{n-m} \sum_{i=m+1}^n f(x_i) $$
单分量 Metropolis-Hastings 算法 (Single-Component Metropolis-Hastings Algorithm) (page 88-92) ¶
在 Metropolis-Hastings 算法中,通常需要对多元变量分布进行抽样,有时对多元变量分布的抽样是困难的。 单分量 Metropolis-Hastings 算法允许对多元变量的每一变量的条件分布依次分别进行抽样,从而实现对整个多元变量的一次抽样。
假设马尔可夫链的状态由 \(k\) 维随机变量表示 (page 89):
\(x = (x_1, x_2, \dots, x_k)^T\)。 其中 \(x_j\) 表示随机变量 \(x\) 的第 \(j\) 个分量,\(j = 1,2, \dots, k\)。 \(x^{(i)}\) 表示马尔可夫链在时刻 \(i\) 的状态:\(x^{(i)} = (x_1^{(i)}, x_2^{(i)}, \dots, x_k^{(i)})^T\)。 其中 \(x_j^{(i)}\) 是随机变量 \(x^{(i)}\) 的第 \(j\) 个分量。
算法步骤 (page 90-91):
为了生成容量为 \(n\) 的样本集合 \(\{x^{(1)}, x^{(2)}, \dots, x^{(n)}\}\),单分量 Metropolis-Hastings 算法由下面的 \(k\) 步迭代实现 Metropolis-Hastings 算法的一次迭代。
设在第 \((i-1)\) 次迭代结束时分量 \(x_j\) 的取值为 \(x_j^{(i-1)}\)。在第 \(i\) 次迭代的第 \(j\) 步,对分量 \(x_j\) 根据 Metropolis-Hastings 算法更新,得到其新的取值 \(x_j^{(i)}\):
- 首先,由建议分布 \(q(x_j^{(i-1)}, x_j' | x_{-j}^{(i)})\) 抽样产生分量 \(x_j\) 的候选值 \(x_j'\)。这里 \(x_{-j}^{(i)}\) 表示在第 \(i\) 次迭代的第 \((j-1)\) 步后的 \(x^{(i)}\) 除去 \(x_j^{(i-1)}\) 的所有值,即:\(x_{-j}^{(i)} = (x_1^{(i)}, \dots, x_{j-1}^{(i)}, x_{j+1}^{(i-1)}, \dots, x_k^{(i-1)})^T\);其中分量 \(1,2, \dots, j-1\) 已经更新。
-
然后,按照接受概率计算: $$ \alpha(x_j^{(i-1)}, x_j' | x_{-j}^{(i)}) = \min\left{1, \frac{p(x_j' | x_{-j}^{(i)}) q(x_j', x_j^{(i-1)} | x_{-j}^{(i)})}{p(x_j^{(i-1)} | x_{-j}^{(i)}) q(x_j^{(i-1)}, x_j' | x_{-j}^{(i)})}\right} $$
-
抽样决定是否接受候选值 \(x_j'\)。如果 \(x_j'\) 被接受,则令 \(x_j^{(i)} = x_j'\);否则令 \(x_j^{(i)} = x_j^{(i-1)}\),其余分量在第 \(j\) 步不改变。
由于建议分布可能不被接受,Metropolis-Hastings 算法可能在一些相邻的时刻不产生移动。这意味着样本点之间可能存在停滞。
吉布斯抽样 (Gibbs Sampling) (page 93-109) ¶
吉布斯抽样是马尔可夫链蒙特卡罗法的常用算法,可以认为是 Metropolis-Hastings 算法的特殊情况,但更容易实现,因而被广泛使用。
基本原理 (page 95-100) ¶
吉布斯抽样用于多元变量联合分布的抽样和估计。其基本做法是,从联合概率分布定义满条件概率分布,依次对满条件概率分布进行抽样,得到样本的序列。
可以证明这样的抽样过程是在一个马尔可夫链上的随机游走,每一个样本对应着马尔可夫链的状态,平稳分布就是目标的联合分布。 整体成为一个马尔可夫链蒙特卡罗法,燃烧期之后的样本就是联合分布的随机样本。
假设多元变量的联合概率分布为 : \(p(x) = p(x_1, x_2, \dots, x_k)\)。
吉布斯抽样从一个初始样本 \(x^{(0)} = (x_1^{(0)}, x_2^{(0)}, \dots, x_k^{(0)})^T\) 出发,不断进行迭代,每一次迭代得到联合分布的一个样本 \(x^{(i)} = (x_1^{(i)}, x_2^{(i)}, \dots, x_k^{(i)})^T\),最终得到样本序列 \(\{x^{(0)}, x^{(1)}, \dots, x^{(n)}\}\)。
迭代过程 ¶
在每次迭代中,依次对 \(k\) 个随机变量中的一个变量进行随机抽样。 如果在第 \(i\) 次迭代中,对第 \(j\) 个变量进行随机抽样,那么抽样的分布是满条件概率分布 \(p(x_j | x_{-j}^{(i)})\),这里 \(x_{-j}^{(i)}\) 表示第 \(i\) 次迭代中,变量 \(x_j\) 以外的其他变量。
- 设在第 \((i-1)\) 步得到样本 \(x^{(i-1)} = (x_1^{(i-1)}, x_2^{(i-1)}, \dots, x_k^{(i-1)})^T\)。
- 在第 \(i\) 步,首先对第一个变量按照以下满条件概率分布随机抽样:\(x_1^{(i)} \sim p(x_1 | x_2^{(i-1)}, \dots, x_k^{(i-1)})\) 得到 \(x_1^{(i)}\)。
- 之后依次对第 \(j\) 个变量按照以下满条件概率分布随机抽样:\(x_j^{(i)} \sim p(x_j | x_1^{(i)}, \dots, x_{j-1}^{(i)}, x_{j+1}^{(i-1)}, \dots, x_k^{(i-1)}), \quad j = 2, \dots, k-1\) 得到 \(x_j^{(i)}\)。
- 最后对第 \(k\) 个变量按照以下满条件概率分布随机抽样:\(x_k^{(i)} \sim p(x_k | x_1^{(i)}, \dots, x_{k-1}^{(i)})\) 得到 \(x_k^{(i)}\)。
- 于是得到整体样本 \(x^{(i)} = (x_1^{(i)}, x_2^{(i)}, \dots, x_k^{(i)})^T\),回到第一步进行迭代。
吉布斯抽样是单分量 Metropolis-Hastings 算法的特殊情况 (page 99-100) ¶
定义建议分布是当前变量 \(x_j, j = 1,2, \dots, k\) 的满条件概率分布 \(q(x, x') = p(x_j' | x_{-j})\)。 这时,接受概率 \(\alpha = 1\):
这里用到 \(p(x) = p(x_j|x_{-j})p(x_{-j})\) 和 \(p(x') = p(x_j'|x_{-j})p(x_{-j})\)。因此,转移核就是满条件概率分布 \(p(x, x') = p(x_j' | x_{-j})\)。
吉布斯抽样特点 (page 100)
也就是说,依次按照单变量的满条件概率分布 \(p(x_j' | x_{-j})\) 进行随机抽样,就能实现单分量 Metropolis-Hastings 算法。
吉布斯抽样对每次抽样的结果都接受,没有拒绝,这一点和一般的 Metropolis-Hastings 算法不同。
这里,假设满条件概率分布 \(p(x_j' | x_{-j})\) 不为 0,即马尔可夫链是不可约的。
算法 19.3 ( 吉布斯抽样 ) (page 101-102) ¶
输入: 目标概率分布的密度函数 \(p(x)\),函数 \(f(x)\)。 输出: \(p(x)\) 的随机样本 \(x_{m+1}, x_{m+2}, \dots, x_n\),函数样本均值 \(f_{mn}\)。 参数: 收敛步数 \(m\),迭代步数 \(n\)。
步骤: 1. 初始化: 给出初始样本 \(x^{(0)} = (x_1^{(0)}, x_2^{(0)}, \dots, x_k^{(0)})^T\)。 2. 对 \(i\) 执行循环: 设第 \((i-1)\) 次迭代结束时的样本为 \(x^{(i-1)} = (x_1^{(i-1)}, x_2^{(i-1)}, \dots, x_k^{(i-1)})^T\),则第 \(i\) 次迭代进行如下几步操作: - 由满条件分布 \(p(x_1 | x_2^{(i-1)}, \dots, x_k^{(i-1)})\) 抽取 \(x_1^{(i)}\)。 - 由满条件分布 \(p(x_j | x_1^{(i)}, \dots, x_{j-1}^{(i)}, x_{j+1}^{(i-1)}, \dots, x_k^{(i-1)})\) 抽取 \(x_j^{(i)}\)。 - 由满条件分布 \(p(x_k | x_1^{(i)}, \dots, x_{k-1}^{(i)})\) 抽取 \(x_k^{(i)}\)。
得到第 $i$ 次迭代值 $x^{(i)} = (x_1^{(i)}, x_2^{(i)}, \dots, x_k^{(i)})^T$。
- 得到样本集合 \(\{x^{(m+1)}, x^{(m+2)}, \dots, x^{(n)}\}\)。
- 计算: $$ f_{mn} = \frac{1}{n-m} \sum_{i=m+1}^n f(x^{(i)}) $$
( 例 11) 用吉布斯抽样从二元正态分布中抽取随机样本。 (page 103-105)
\(x = (x_1, x_2)^T \sim p(x_1, x_2)\) \(p(x_1, x_2) = \mathcal{N}(0, \Sigma)\), \(\Sigma = \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix}\)。
条件概率分布为一元正态分布:
- \(p(x_1 | x_2) = \mathcal{N}(\rho x_2, 1 - \rho^2)\)
- \(p(x_2 | x_1) = \mathcal{N}(\rho x_1, 1 - \rho^2)\)
假设初始样本为 \(x^{(0)} = (x_1^{(0)}, x_2^{(0)})\),通过吉布斯抽样,可以得到样本序列。最终得到的样本集合 \(\{x^{(m+1)}, x^{(m+2)}, \dots, x^{(n)}\}\), \(m < n\) 就是二元正态分布的随机抽样。
抽样计算 (page 106-109) ¶
吉布斯抽样中需要对满条件概率分布进行重复多次抽样。可以利用概率分布的性质提高抽样的效率。 在贝叶斯学习中,设 \(y\) 表示观测数据,\(\alpha, \theta, z\) 分别表示超参数、模型参数、未观测数据,\(x = (\alpha, \theta, z)\)。贝叶斯学习的目的是估计后验概率分布 \(p(x|y)\),并求后验概率最大的模型。 \(p(x|y) = p(\alpha, \theta, z | y) \propto p(z,y|\theta)p(\theta|\alpha)p(\alpha)\)。 式中 \(p(\alpha)\) 是超参数分布,\(p(\theta|\alpha)\) 是先验分布,\(p(z,y|\theta)\) 是完全数据的分布。
现在用吉布斯抽样估计 \(p(x|y)\),其中 \(y\) 已知,\(x = (\alpha, \theta, z)\) 未知。吉布斯抽样中各个变量 \(\alpha, \theta, z\) 的满条件分布有以下关系:
- \(p(\alpha | \alpha_{-i}, \theta, z, y) \propto p(\alpha)p(\theta|\alpha)\)
- \(p(\theta | \theta_{-j}, \alpha, z, y) \propto p(z,y|\theta)p(\theta|\alpha)\)
- \(p(z | z_{-k}, \alpha, \theta, y) \propto p(z,y|\theta)\)
其中 \(\alpha_{-i}\) 表示变量 \(\alpha_i\) 以外的所有变量,\(\theta_{-j}\) 和 \(z_{-k}\) 类似。 依照满条件概率分布的抽样可以通过依照这些条件概率分布的乘积的抽样进行。这样可以大幅减少抽样的计算复杂度,因为计算只涉及部分变量。