14 grad
介绍 (page 2) ¶
本节主要概述了统计机器学习和凸优化在“大数据”背景下的应用及其相关理论基础。
大规模机器学习与优化 (page 3-5) ¶
在大规模机器学习的背景下,数据通常表现为高维度(large \(d\)) 和大数据量(large \(n\))。
- \(d\): 表示每个观测值(输入)的维度。
- \(n\): 表示观测值的数量。
例如,在计算机视觉、生物信息学和广告等领域,我们经常遇到这类问题。理想的运行时间复杂度通常是 \(O(dn)\)。为了应对大规模数据,研究人员开始重新审视一些“简单”的方法,特别是随机梯度方法 (Stochastic Gradient Methods),最早由 Robbins 和 Monro 在 1951 年提出 1。这些方法通过结合统计学和优化理论,并利用函数的平滑性来超越传统的随机梯度下降。
历史回顾 (page 6-7)
1950 年代:计算机性能不足,例如 1959 年的 IBM “1620”计算机,CPU 频率仅为 50 KHz,价格超过 10 万美元,限制了大规模计算的应用。
2010 年代:数据量变得过于庞大,传统的优化方法难以处理。这促使人们重新关注随机梯度方法等“简单”方法,以应对数据规模的挑战。
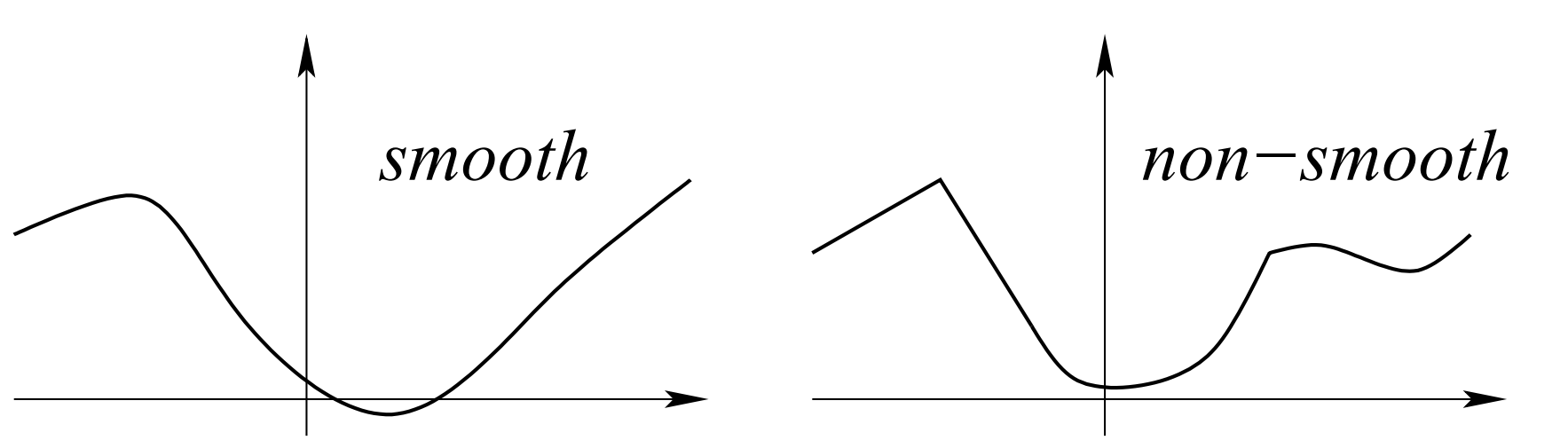
函数的分类 (page 2) ¶
在凸优化中,我们根据函数的性质将其分为不同的类别,这对于选择合适的优化算法至关重要。主要包括:
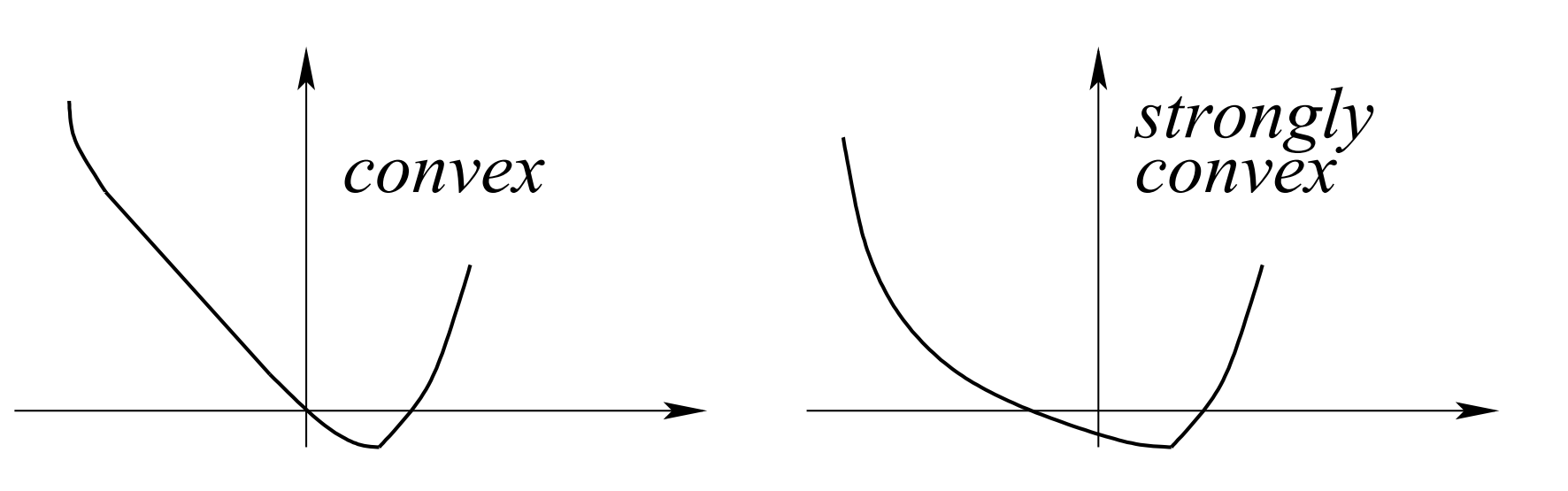
- 凸函数 (Convex Functions):这类函数在定义域内任意两点之间的线段,其函数值不会超过两端点函数值的连线。
- 光滑函数 (Smooth Functions):这类函数的梯度是 \(L\) -Lipschitz 连续的,这意味着函数的坡度变化不会太剧烈。
- 强凸函数 (Strongly Convex Functions):比普通凸函数更强,其函数图像具有更明显的“碗状”结构,保证了全局最优解的唯一性,并且算法收敛速度更快。
监督学习与经验风险最小化 (page 8, 14-17) ¶
在监督学习中,我们的目标是从给定的 \(n\) 个独立同分布(i.i.d.)观测数据 \((x_i, y_i) \in \mathcal{X} \times \mathcal{Y}\) 中学习一个模型。
- 数据: \(n\) 个独立同分布的观测值 \((x_i, y_i) \in \mathcal{X} \times \mathcal{Y}\), \(i = 1, \dots, n\)。
- 预测: 通常通过一个线性函数 \(\theta^\top \Phi(x)\) 进行预测,其中 \(\Phi(x) \in \mathbb{R}^d\) 是特征向量。
- 经验风险最小化 (Empirical Risk Minimization, ERM): 机器学习的核心任务之一是找到一个参数 \(\hat{\theta}\),使得在给定数据集上的损失函数最小化。为了避免过拟合,通常会引入正则化项。
ERM 的目标函数通常表示为:
其中:
- \(\frac{1}{n} \sum_{i=1}^n \ell(y_i, \theta^\top \Phi(x_i))\) 是凸数据拟合项 (convex data fitting term),也称为经验风险 (Empirical Risk) \(\hat{f}(\theta)\) 或训练成本 (training cost)。它衡量了模型在训练数据上的表现。
- \(\mu \Omega(\theta)\) 是正则化项 (regularizer)。其目的是为了避免过拟合,通常通过限制模型复杂度来实现。
或者,正则化也可以表示为约束条件:
这里 \(\Omega(\theta) \le D\) 是一个约束 (constraint)。
- 经验风险 \(\hat{f}(\theta)\): 衡量模型在训练数据上的表现,即: $$ \hat{f}(\theta) = \frac{1}{n} \sum_{i=1}^n \ell(y_i, \theta^\top \Phi(x_i)) \quad \text{training cost} $$
- 期望风险 (Expected Risk) \(f(\theta)\): 衡量模型在未见数据上的泛化能力,即: $$ f(\theta) = \mathbb{E}_{(x,y)} \ell(y, \theta^\top \Phi(x)) \quad \text{testing cost} $$ 期望风险是经验风险在整个数据分布上的期望。
有两个基本问题需要解决:
- 计算 \(\hat{\theta}\): 找到经验风险最小化的参数。
- 分析 \(\hat{\theta}\): 评估 \(\hat{\theta}\) 的统计特性,例如它的泛化能力。
这两个问题通常可以同时解决。
典型损失函数 (page 9-11)
- 回归 (Regression):目标变量 \(y \in \mathbb{R}\)。预测值 \(\hat{y} = \theta^\top \Phi(x)\)。
- 二次损失 (Quadratic Loss): $$ \frac{1}{2}(y - \hat{y})^2 = \frac{1}{2}(y - \theta^\top \Phi(x))^2 $$
- 分类 (Classification):目标变量 \(y \in \{-1, 1\}\)。预测值 \(\hat{y} = \text{sign}(\theta^\top \Phi(x))\)。
- 损失函数形式:\(\ell(y \theta^\top \Phi(x))\)。
- “真实” 0-1 损失 (True 0-1 Loss):\(\ell(y \theta^\top \Phi(x)) = \mathbf{1}_{y \theta^\top \Phi(x) < 0}\)。这是非凸的。
- 常用凸损失 (Usual Convex Losses):为了使优化问题可解,通常使用凸替代损失。
- 合页损失 (Hinge Loss) ( 支持向量机 , SVM): \(\ell(Y, \theta^\top \Phi(X)) = \max\{1 - Y \theta^\top \Phi(X), 0\}\) ( 非光滑 )。
- 逻辑损失 (Logistic Loss) ( 逻辑回归 ): \(\ell(Y, \theta^\top \Phi(X)) = \log(1 + \exp(-Y \theta^\top \Phi(X)))\) ( 光滑 )。
- 最小二乘回归 (Least-squares Regression): \(\ell(Y, \theta^\top \Phi(X)) = \frac{1}{2}(Y - \theta^\top \Phi(X))^2\)。
常用正则化器 (page 12-13)
正则化的主要目标是避免过拟合 (avoid overfitting)。
- (平方)欧几里得范数 (Squared Euclidean Norm) (L2 正则化 ): $$ |\theta|2^2 = \sum^d |\theta_j|^2 $$
- 这种范数在数值上表现良好。
- 与核方法 (kernel methods) 和表示定理 (representer theorem) 相关联。
- 稀疏诱导范数 (Sparsity-inducing Norms):
- 主要例子是 \(L_1\) 范数 (Lasso): $$ |\theta|1 = \sum^d |\theta_j| $$
- 它不仅进行正则化,还能进行模型选择 (model selection),因为它可以使得模型参数稀疏,即某些特征的权重变为零。
- 涉及非光滑优化和结构化稀疏性。
一般假设 (page 18) ¶
在分析机器学习算法时,通常会引入一些一般性假设:
- 数据: \(n\) 个独立同分布的观测值 \((x_i, y_i) \in \mathcal{X} \times \mathcal{Y}\)。
- 有界特征: 特征 \(\Phi(x) \in \mathbb{R}^d\) 是有界的,即 \(\|\Phi(x)\|_2 \le R\)。
- 经验风险: \(\hat{f}(\theta) = \frac{1}{n} \sum_{i=1}^n \ell(y_i, \theta^\top \Phi(x_i))\) ( 训练成本 )。
- 期望风险: \(f(\theta) = \mathbb{E}_{(x,y)} \ell(y, \theta^\top \Phi(x))\) ( 测试成本 )。
- 单次观测损失: \(f_i(\theta) = \ell(y_i, \theta^\top \Phi(x_i))\)。这意味着对于每个观测,其期望损失 \(f(\theta) = \mathbb{E} f_i(\theta)\)。
- 函数性质: \(f_i, f, \hat{f}\) 都满足:
- 在 \(\mathbb{R}^d\) 上是凸函数 (Convex)。
- 额外的正则性假设,如 Lipschitz 连续性 (Lipschitz-continuity)、光滑性 (smoothness) 和 强凸性 (strong convexity)。
凸性 (page 19-25) ¶
凸性是优化理论中的核心概念,它使得许多优化问题变得可解。
全局定义 (page 20) ¶
对于一个函数 \(g: \mathbb{R}^d \to \mathbb{R}\),如果对于任意 \(\theta_1, \theta_2 \in \mathbb{R}^d\) 和任意 \(\alpha \in\),满足以下条件,则称其为凸函数:
这个定义不要求函数可微。从几何上看,这意味着函数图像上任意两点之间的线段都在函数图像的上方或与图像重合。
如果函数 \(g\) 可微,则其凸性定义可以等价地表示为:
这表示函数图像上任意一点的切线(或超平面)都在函数图像的下方。
次梯度与次微分 (Subgradients and Subdifferentials) (page 22) ¶
对于非光滑凸函数,梯度不一定存在。此时,我们引入次梯度 (subgradient) 和次微分 (subdifferential) 的概念。
次梯度定义
给定一个凸函数 \(g: \mathbb{R}^d \to \mathbb{R}\),如果向量 \(s \in \mathbb{R}^d\) 满足以下条件,则称其为 \(g\) 在点 \(\theta\) 处的次梯度:
次微分定义
函数 \(g\) 在点 \(\theta\) 处的次微分 (subdifferential) \(\partial g(\theta)\) 是所有次梯度的集合:
如果 \(g\) 在 \(\theta\) 处可微,那么次微分只包含一个元素,即 \(\partial g(\theta) = \{g'(\theta)\}\)。著名的 Rockafellar (1997) 证明了凸函数的次微分永远不为空集。
局部定义 (page 23) ¶
对于二次可微函数,凸性也可以通过二阶导数(Hessian 矩阵)来定义:
这意味着 Hessian 矩阵是半正定的。
凸性的重要性 (page 24-25) ¶
凸性在优化中至关重要,因为它带来以下优良性质:
- 局部最小值即全局最小值 (Local Minimum = Global Minimum):对于凸函数,任何局部最小值都是全局最小值。这极大地简化了优化问题,因为我们不需要担心被局部最优解困住。
- 最优性条件 (Optimality Condition):
- 非光滑情况: \(0 \in \partial g(\theta)\) ( 零向量属于次微分 )。
- 光滑情况: \(g'(\theta) = 0\) ( 梯度为零 )。
- 凸对偶性 (Convex Duality):凸优化问题通常可以转化为对偶问题,有时对偶问题更容易求解,并且可以提供原始问题的下界。
- 识别凸问题 (Recognizing Convex Problems):存在成熟的理论和工具来识别和处理凸问题。
Lipschitz 连续性 (page 26) ¶
Lipschitz 连续性描述了函数变化的平滑程度,即函数值(或梯度值)的变化不会超过输入变量变化的某个常数倍。
Lipschitz 连续性定义
函数 \(g\) 是 \(B\) -Lipschitz 连续的,如果对于其定义域内任意两点 \(\theta, \theta'\),函数值的变化有界:
对于凸可微函数,如果其梯度是 \(B\) - 有界的(在中心为 0 半径为 \(D\) 的球内
这与上述函数值定义的 Lipschitz 连续性是等价的,即:
Lipschitz 连续的意义是:输入的一个很小的变化,会引起输出的一个很小的变化。
在机器学习中,如果损失函数是 \(G\) -Lipschitz 连续的,并且数据是 \(R\) - 有界的(即 \(\|\Phi(x)\|_2 \le R\)
光滑性与强凸性 (Smoothness and Strong Convexity) (page 27-31) ¶
光滑性 (Smoothness) (page 27-28) ¶
L- 光滑函数定义
函数 \(g: \mathbb{R}^d \to \mathbb{R}\) 是 \(L\) - 光滑的 (L-smooth),当且仅当它是可微的,并且其梯度是 \(L\) -Lipschitz 连续的:
如果 \(g\) 是二次可微的,那么 \(L\) - 光滑性等价于其 Hessian 矩阵的最大特征值有界:
其中 \(\mathbf{Id}\) 是单位矩阵。在机器学习中:
- 对于 \(g(\theta) = \frac{1}{n} \sum_{i=1}^n \ell(y_i, \theta^\top \Phi(x_i))\),如果损失函数 \(\ell\) 是 \(L_{\text{loss}}\) - 光滑的,并且数据是 \(R\) - 有界的,那么整个损失函数 \(g\) 的光滑常数 \(L = L_{\text{loss}} R^2\)。
强凸性 (Strong Convexity) (page 29-31) ¶
强凸性是比普通凸性更强的性质,它保证了函数有一个“碗状”的下界。
\(\mu\) - 强凸函数定义
函数 \(g: \mathbb{R}^d \to \mathbb{R}\) 是 \(\mu\) - 强凸的 (\(\mu\) -strongly convex),当且仅当对于任意 \(\theta_1, \theta_2 \in \mathbb{R}^d\),满足:
如果 \(g\) 是二次可微的,那么 \(\mu\) - 强凸性等价于其 Hessian 矩阵的最小特征值有界:
在机器学习中:
- 对于 \(g(\theta) = \frac{1}{n} \sum_{i=1}^n \ell(y_i, \theta^\top \Phi(x_i))\),其 Hessian 矩阵近似于协方差矩阵 \(\frac{1}{n} \sum_{i=1}^n \Phi(x_i)\Phi(x_i)^\top\)。
- 如果数据具有可逆的协方差矩阵(低相关性 / 维度
) ,可能表现出强凸性。 - 通过添加正则化项 \(\frac{\mu}{2}\|\theta\|_2^2\),可以使函数变为强凸。但这会引入额外的偏差,除非 \(\mu\) 很小。
平滑性 / 凸性假设总结 (page 32) ¶
- 有界梯度 (Lipschitz-continuity):对于凸可微函数 \(g\),如果其在中心为 \(0\)、半径为 \(D\) 的球上的次梯度均匀有界为 \(B\),即: $$ \forall \theta \in \mathbb{R}^d, |\theta|_2 \le D \Rightarrow |g'(\theta)|_2 \le B $$
- 光滑性 (Smoothness):函数 \(g\) 是凸、可微的,并且其梯度 \(g'\) 是 \(L\) -Lipschitz 连续的(例如,Hessian 有界
) : $$ \forall \theta_1, \theta_2 \in \mathbb{R}^d, |g'(\theta_1) - g'(\theta_2)|_2 \le L |\theta_1 - \theta_2|_2 $$ - 强凸性 (Strong Convexity):函数 \(g\) 是强凸的,其凸性常数 \(\mu > 0\): $$ \forall \theta_1, \theta_2 \in \mathbb{R}^d, g(\theta_1) \ge g(\theta_2) + g'(\theta_2)^\top(\theta_1 - \theta_2) + \frac{\mu}{2}|\theta_1 - \theta_2|_2^2 $$
经验风险最小化分析 (page 33-36) ¶
经验风险最小化的分析通常涉及逼近误差 (Approximation Error) 和估计误差 (Estimation Error) 的分解。
设 \(\Theta = \{\theta \in \mathbb{R}^d | \Omega(\theta) \le D\}\) 是参数空间。经验风险最小化解 \(\hat{\theta}\) 与真实风险的全局最小值之间的差距可以分解为两部分:
- 估计误差 (Estimation Error):衡量了在给定参数空间 \(\Theta\) 内,通过经验风险最小化得到的解 \(\hat{\theta}\) 的期望风险与真实风险在该参数空间内的最优值 \(\min_{\theta \in \Theta} f(\theta)\) 之间的差距。这部分误差通常随着数据量的增加而减小。
- 逼近误差 (Approximation Error):衡量了真实风险在受限参数空间 \(\Theta\) 内的最优值 \(\min_{\theta \in \Theta} f(\theta)\) 与在整个 \(\mathbb{R}^d\) 空间内的全局最优值 \(\min_{\theta \in \mathbb{R}^d} f(\theta)\) 之间的差距。这部分误差与模型的表达能力(参数空间 \(\Theta\) 的选择)有关,通常不会随着数据量的增加而减小。
均匀偏差界 (Uniform Deviation Bounds) (page 34-36) ¶
对于 \(\hat{\theta} \in \arg \min_{\theta \in \Theta} \hat{f}(\theta)\),我们有:
这意味着估计误差的上限可以通过经验风险与期望风险之间的最大偏差来控制。这种偏差通常以 \(O(1/\sqrt{n})\) 的慢速收敛。
通过更精细的集中不等式,可以获得更快的收敛速率,例如 \(O(1/n)\)。
慢速率(Lipschitz 函数)与快速率(强凸函数) (page 38-40)¶
- Lipschitz 函数导致慢速率 (Lipschitz functions \(\Rightarrow\) slow rate):在没有凸性假设的情况下,对于 Lipschitz 损失函数,经验风险和期望风险之间的偏差通常以 \(O(1/\sqrt{n})\) 的速度收敛。这可以通过 Rademacher 复杂度分析得到。 $$ \sup_{\theta \in \Theta} |\hat{f}(\theta) - f(\theta)| \le \frac{\ell_0 + GRD}{\sqrt{n}} \left[2 + \sqrt{2 \log \frac{2}{\delta}}\right] $$ 期望估计误差: $$ \mathbb{E}\left[\sup_{\theta \in \Theta} |\hat{f}(\theta) - f(\theta)|\right] \le \frac{4\ell_0 + 4GRD}{\sqrt{n}} $$
- 强凸函数导致快速率 (Strongly convex functions \(\Rightarrow\) fast rate): 如果函数是强凸的,则可以获得更快的收敛速率。引入正则化后的风险函数 \(f^\mu(\theta) = f(\theta) + \frac{\mu}{2}\|\theta\|_2^2\) 和 \(\hat{f}^\mu(\theta) = \hat{f}(\theta) + \frac{\mu}{2}\|\theta\|_2^2\)。对于强凸函数,我们可以得到如下界: $$ f^\mu(\hat{\theta}) - \min_{\eta \in \mathbb{R}^d} f^\mu(\eta) \le \frac{8G^2R^2(32 + \log \frac{1}{\delta})}{\mu n} $$ 需要注意的是,为了减小逼近误差,正则化参数 \(\mu\) 应该随着 \(n\) 的增加而减小。
凸优化经典方法 (page 41-42) ¶
本节将介绍几种用于凸优化的经典算法:
- 梯度下降 (Gradient Descent):一种迭代优化算法,用于寻找函数的局部最小值。
- 牛顿法 (Newton Method):一种二阶优化算法,收敛速度通常比梯度下降快,但计算成本更高。
- 加速梯度下降 (Accelerated Gradient Descent) (Nesterov 方法 ):一种改进的梯度下降方法,在光滑凸函数上可以获得更快的收敛速度。
- 次梯度法 (Subgradient Method):适用于非光滑凸函数,使用次梯度而非梯度进行更新。
- 椭球法 (Ellipsoid Algorithm):一种通用的凸优化算法,理论上收敛,但在实践中不如梯度下降类方法高效。
( 光滑 ) 梯度下降 (Smooth Gradient Descent) (page 43-47) ¶
- 假设: \(g\) 是凸的,且其梯度是 \(L\) -Lipschitz 连续的(即 \(L\) - 光滑
) ,且存在最小值 \(\theta^*\)。 - 算法: $$ \theta_t = \theta_{t-1} - \frac{1}{L}g'(\theta_{t-1}) $$ 其中 \(\frac{1}{L}\) 是步长。
强凸情况下的梯度下降 (Strong Convexity) (page 44, 46) ¶
如果 \(g\) 是 \(\mu\) - 强凸的,则梯度下降的收敛速度是线性 (linear) 的,即误差呈几何级数下降:
这里的 \(\frac{\mu}{L}\) 称为条件数 (condition number),它决定了收敛速度。条件数越大,收敛越慢。
一般凸情况下的梯度下降 (Slow Rate) (page 45, 47) ¶
如果 \(g\) 只是凸的(而不是强凸
这意味着误差以 \(O(1/t)\) 的速率收敛。
- 梯度下降的适应性 (Adaptivity of gradient descent):梯度下降对问题难度具有适应性。
- 收敛率并非最优 (Not best possible convergence rates):在某些情况下,梯度下降在经过 \(O(d)\) 次迭代后可能无法达到最优收敛率。
梯度下降用于二次函数 (Proof for Quadratic Functions) (page 46-47) ¶
对于二次凸函数 \(g(\theta) = \frac{1}{2}\theta^\top H\theta - c^\top\theta\),其中 \(H\) 是对称正定矩阵:
- \(\mu\) 和 \(L\) 分别是 \(H\) 的最小和最大特征值。
- 全局最优解 \(\theta^* = H^{-1}c\)。
梯度下降的更新规则变为:
这可以进一步简化为:
- 强凸性 \(\mu > 0\):
- 迭代的收敛:\(\|\theta_t - \theta^*\|_2^2 \le (1 - \mu/L)^{2t}\|\theta_0 - \theta^*\|_2^2\)。
- 函数值的收敛:\(g(\theta_t) - g(\theta^*) \le (1 - \mu/L)^{2t}[g(\theta_0) - g(\theta^*)]\)。
- 凸性 \(\mu = 0\):
- 迭代不收敛到 \(\theta^*\)。
- 函数值收敛:\(g(\theta_t) - g(\theta^*) \le \frac{L}{t}\|\theta_0 - \theta^*\|_2^2\)。
光滑凸函数的性质 (Properties of Smooth Convex Functions) (page 48) ¶
对于一个 \(L\) - 光滑的凸函数 \(g: \mathbb{R}^d \to \mathbb{R}\),对于任意 \(\theta, \eta \in \mathbb{R}^d\):
- 梯度 \(L\) -Lipschitz 连续: \(\|g'(\theta) - g'(\eta)\| \le L\|\theta - \eta\|\)。
- 二次上界 (Quadratic Upper-Bound): $$ 0 \le g(\theta) - g(\eta) - g'(\eta)^\top(\theta - \eta) \le \frac{L}{2}|\theta - \eta|_2^2 $$ 这可以通过泰勒展开与积分余项得到。
-
Co-coercivity ( 共强制性 ): $$ \frac{1}{L}|g'(\theta) - g'(\eta)|_2^2 \le [g'(\theta) - g'(\eta)]^\top(\theta - \eta) $$ Co-coercivity 的证明可以利用二次上界和定义辅助函数 \(h(\theta) = g(\theta) - \theta^\top g'(\eta)\)。通过最小化 \(h(\theta)\),并利用其凸性,可以推导出 co-coercivity 关系 (page 49)。
-
如果 \(g\) 是 \(\mu\) - 强凸的,则满足: $$ g(\theta) \ge g(\eta) + g'(\eta)^\top(\theta - \eta) + \frac{1}{2\mu}|g'(\theta) - g'(\eta)|_2^2 $$
- 到最优解的“距离” (Distance to Optimum): $$ g(\theta) - g(\theta^) \ge g'(\theta)^\top(\theta - \theta^) $$
Polyak-Lojasiewicz 不等式 (page 50) ¶
如果 \(\eta = \theta^*\) 是全局最小点,则对于 \(\mu\) - 强凸函数,有:
这被称为 Polyak-Lojasiewicz 不等式,它表明了函数值与梯度的范数之间的关系,对于分析收敛性非常有用。
加速梯度方法 (Accelerated Gradient Methods) (page 54-55) ¶
加速梯度方法 ( 通常指 Nesterov 梯度下降,Nesterov, 1983) 是一种针对光滑凸函数优化的重要算法,它在收敛速度上优于标准梯度下降。
- 假设: \(g\) 是凸的,且其梯度是 \(L\) -Lipschitz 连续的,并且存在最小值 \(\theta^*\)。
- 算法: Nesterov 的加速梯度下降通常涉及两个序列的更新:\(\theta_t\) 和 \(\eta_t\)。 $$ \theta_t = \eta_{t-1} - \frac{1}{L}g'(\eta_{t-1}) $$ $$ \eta_t = \theta_t + \frac{t-1}{t+2}(\theta_t - \theta_{t-1}) $$
- 收敛界 (Bound):对于一般光滑凸函数,Nesterov 方法可以达到 \(O(1/t^2)\) 的收敛速度: $$ g(\theta_t) - g(\theta^) \le \frac{2L|\theta_0 - \theta^|_2^2}{(t + 1)^2} $$ 这个收敛率被认为是不可改进的,因为对于光滑凸函数,存在匹配这个下界的优化问题。
强凸情况下的加速梯度方法 (page 55) ¶
如果 \(g\) 是 \(\mu\) - 强凸的,加速梯度方法可以获得线性收敛速度,其依赖于条件数 \(\kappa = L/\mu\):
- 与共轭梯度法的关系 (Relationship with conjugate gradient):对于二次函数,加速梯度法与共轭梯度法 (Conjugate Gradient) 有密切关系。
投影梯度下降 (Projected Gradient Descent) (page 56) ¶
投影梯度下降用于解决带有简单凸约束的优化问题,形式为 \(\min_{\theta \in \mathcal{K}} f(\theta)\),其中 \(\mathcal{K}\) 是一个凸集。
-
算法: 投影梯度下降的迭代更新包括一个梯度下降步骤和一个到约束集的投影步骤: $\(\theta_{t+1} = \arg \min_{\theta \in \mathcal{K}} \left\{f(\theta_t) + (\theta - \theta_t)^\top \nabla f(\theta_t) + \frac{L}{2}\|\theta - \theta_t\|_2^2\right\}\)$
这等价于: $\(\theta_{t+1} = \arg \min_{\theta \in \mathcal{K}} \frac{1}{2}\left\|\theta - \left(\theta_t - \frac{1}{L}\nabla f(\theta_t)\right)\right\|_2^2\)$ 这个操作 \(\Pi_{\mathcal{K}}(x) = \arg \min_{z \in \mathcal{K}} \|x - z\|_2\) 就是将点 \(x\) 投影到凸集 \(\mathcal{K}\) 上。 - 收敛率 (Convergence Rates):投影梯度下降的收敛率与无约束的光滑优化方法类似。 - 加速方法 (Acceleration Methods):同样存在加速投影梯度下降的方法 (Nesterov, 2007; Beck and Teboulle, 2009)。
牛顿法 (Newton Method) (page 57) ¶
牛顿法是一种二阶优化算法,它利用函数的二阶导数信息(Hessian 矩阵)来确定搜索方向。
- 原理: 在当前点 \(\theta_{t-1}\) 处,最小化目标函数 \(g(\theta)\) 的二阶泰勒展开式 \(\tilde{g}(\theta)\): $$ \tilde{g}(\theta) = g(\theta_{t-1}) + g'(\theta_{t-1})^\top(\theta - \theta_{t-1}) + \frac{1}{2}(\theta - \theta_{t-1})^\top g''(\theta_{t-1})(\theta - \theta_{t-1}) $$
- 迭代: 通过设置 \(\tilde{g}'(\theta) = 0\) 找到最小值,得到牛顿迭代公式: $$ \theta_t = \theta_{t-1} - [g''(\theta_{t-1})]^{-1}g'(\theta_{t-1}) $$
- 计算成本: 每次迭代需要计算 Hessian 矩阵的逆,其运行时间复杂度通常为 \(O(d^3)\),这在 \(d\) 很大时非常昂贵。
- 二次收敛 (Quadratic Convergence):如果初始点 \(\theta_{t-1}\) 足够接近最优解 \(\theta^*\),牛顿法表现出二次收敛速度。这意味着误差在每次迭代中会平方级减小: $$ (C|\theta_t - \theta^|) \le (C|\theta_{t-1} - \theta^|)^2 $$ (其中 \(C\) 是一个常数)。
光滑凸函数最小化总结 (Summary: Minimizing Smooth Convex Functions) (page 58-59) ¶
| 方法 | 收敛假设 | 收敛率 ( 一般凸 ) | 收敛率 ( 强凸 ) |
|---|---|---|---|
| 梯度下降 | \(g\) 凸,梯度 \(L\) -Lipschitz 连续 | \(O(1/t)\) | \(O(e^{-t\mu/L})\) |
| 加速梯度下降 | \(g\) 凸,梯度 \(L\) -Lipschitz 连续 | \(O(1/t^2)\) | \(O(e^{-t\sqrt{\mu/L}})\) |
| 牛顿法 | \(g\) 凸,二阶可微 Hessian \(L\) -Lipschitz 连续 |
\(O(e^{-\rho^2t})\) | \(O(e^{-\rho^2t})\) ( 局部二次收敛 ) |
从光滑函数到非光滑函数,通常使用次梯度法 (Subgradient Method) 和 椭球法 (Ellipsoid Algorithm)。
次梯度法 /" 下降 " (Subgradient Method/"Descent") (Shor et al., 1985) (page 60-64) ¶
次梯度法是用于非光滑凸优化的基本方法。
- 假设: \(g\) 是凸的,且在中心为 \(0\)、半径为 \(D\) 的球上是 \(B\) -Lipschitz 连续的,且存在最优解 \(\theta^*\)。
- 算法: 次梯度法的迭代更新公式为: $$ \theta_t = \Pi_D \left(\theta_{t-1} - \frac{2D}{B\sqrt{t}}g'(\theta_{t-1})\right) $$ 其中 \(\Pi_D\) 是到球体 \(\{\theta \mid \|\theta\|_2 \le D\}\) 的正交投影,\(g'(\theta_{t-1})\) 是次梯度。
- 收敛界 (Bound):次梯度法的收敛速度通常是 \(O(1/\sqrt{t})\): $$ g\left(\frac{1}{t}\sum_{k=0}^{t-1}\theta_k\right) - g(\theta^*) \le \frac{2DB}{\sqrt{t}} $$ 这表示平均迭代点的函数值收敛到最优值。
次梯度法用于机器学习 (Subgradient Descent for Machine Learning) (page 65) ¶
- 假设: \(f\) 是期望风险,\(\hat{f}\) 是经验风险。线性预测器 \(\theta(x) = \theta^\top \Phi(x)\),特征 \(\Phi(x)\) 有界 \(\|\Phi(x)\|_2 \le R\)。损失函数 \(f\) 和 \(\hat{f}\) 是 \(GR\) -Lipschitz 连续的,且参数在有界集合 \(\Theta = \{\theta \mid \|\theta\|_2 \le D\}\) 中。
- 统计学 (Statistics):对于 Lipschitz 函数,期望风险和经验风险之间的偏差有界: $$ \sup_{\theta \in \Theta} |\hat{f}(\theta) - f(\theta)| \le \frac{GRD}{\sqrt{n}}\left[2 + \sqrt{2 \log \frac{2}{\delta}}\right] $$
- 优化 (Optimization):经过 \(t\) 次次梯度迭代后,经验风险的收敛: $$ \hat{f}(\hat{\theta}) - \min_{\eta \in \Theta} \hat{f}(\eta) \le \frac{GRD}{\sqrt{t}} $$
- 总运行时间复杂度 (Total Running-Time Complexity):如果迭代次数 \(t = n\),则总运行时间复杂度为 \(O(n^2d)\),这是因为每次迭代需要计算所有 \(n\) 个样本的次梯度。
强凸情况下的次梯度下降 (Strong Convexity) (page 66-68) ¶
如果函数 \(g\) 是 \(\mu\) - 强凸的,则次梯度下降的收敛速度为 \(O(1/t)\): $$ g\left(\frac{2}{t(t+1)}\sum_{k=1}^t k\theta_{k-1}\right) - g(\theta^*) \le \frac{2B^2}{\mu(t+1)} $$ 这表示加权平均迭代点的函数值收敛到最优值。
凸函数最小化总结 (Summary: Minimizing Convex Functions) (page 69) ¶
| 方法 | 收敛假设 | 收敛率 ( 非光滑凸 ) | 收敛率 ( 光滑凸 ) | 收敛率 ( 强光滑凸 ) |
|---|---|---|---|---|
| 梯度下降 | \(g\) 凸 | \(O(1/\sqrt{t})\) | \(O(1/t)\) | \(O(e^{-\rho t})\) |
| 牛顿法 | \(g\) 凸,二阶可微 | - | - | \(O(e^{-\rho^2t})\) |
关键见解 (Key Insights from Bottou and Bousquet (2008)) (page 70) ¶
- 无需优化到统计误差以下: 在机器学习中,没有必要将经验风险优化到远远低于统计误差的程度。这意味着我们不需要追求极高的优化精度,因为数据本身带有噪声和不确定性。
- 成本函数是平均值: 机器学习中的成本函数通常是数据样本的平均损失。这为使用随机优化方法提供了基础。
这两个见解共同导向了随机逼近 (Stochastic Approximation) 方法的应用。
非光滑随机逼近 (Non-smooth Stochastic Approximation) (page 72-78) ¶
随机逼近方法的目标是在只能获得梯度(或次梯度)的无偏估计的情况下,最小化一个函数。
目标 (Goal) (page 73) ¶
- 目标: 最小化一个定义在 \(\mathbb{R}^d\) 上的函数 \(f\)。
- 挑战: 只能获得其梯度 \(f'(\theta_n)\) 的无偏估计 \(f'_n(\theta_n)\)。
机器学习与统计 (Machine Learning - Statistics) (page 74) ¶
在机器学习中,这种无偏估计是很自然的:
- 单对观测的损失 (Loss for a single pair of observations):\(f_n(\theta) = \ell(y_n, \theta^\top \Phi(x_n))\)。
- 期望损失 (Expected loss):\(f(\theta) = \mathbb{E} f_n(\theta) = \mathbb{E} \ell(y_n, \theta^\top \Phi(x_n))\),这就是泛化误差 (generalization error)。
- 期望梯度 (Expected gradient):\(f'(\theta) = \mathbb{E} f'_n(\theta) = \mathbb{E}[\ell'(y_n, \theta^\top \Phi(x_n)) \Phi(x_n)]\)。
- 迭代次数 = 观测次数 (Number of iterations = number of observations)。
随机逼近的适用性 (Stochastic Approximation) (page 75) ¶
随机逼近的适用范围比凸优化更广,它不一定要求凸性、i.i.d. 假设或有限维度。
-
核心算法 (Key Algorithm):随机梯度下降 (Stochastic Gradient Descent, SGD),也被称为 Robbins-Monro 算法。 $$ \theta_n = \theta_{n-1} - \gamma_n h_n(\theta_{n-1}) \quad \text{with } \mathbb{E}[h_n(\theta_{n-1})|\theta_{n-1}] = h(\theta_{n-1}) $$
其中 \(h_n(\theta_{n-1})\) 是真实梯度 \(h(\theta_{n-1})\) 的无偏估计,\(\gamma_n\) 是学习率(步长
) 。 - Polyak-Ruppert 平均 (Polyak-Ruppert Averaging):通常对迭代点进行平均可以改善收敛性,即 \(\bar{\theta}_n = \frac{1}{n}\sum_{k=0}^{n-1} \theta_k\)。 - 学习率序列 (Learning Rate Sequence):经典的设置是 \(\gamma_n = Cn^{-\alpha}\)。 - 理想行为: 适用于经典监督学习问题,对未知常数 (L, B, \(\mu\)) 具有鲁棒性,并能适应问题难度(如强凸性) 。
与在线学习的关系 (Relationship to Online Learning) (page 76-78) ¶
- 随机逼近 (Stochastic Approximation):最小化期望风险 \(f(\theta) = \mathbb{E}_z \ell(\theta, z)\),使用单次 i.i.d. 观测的梯度。
- 批量学习 (Batch Learning):给定有限观测集 \(z_1, \dots, z_n\),最小化经验风险 \(\hat{f}(\theta) = \frac{1}{n}\sum_{k=1}^n \ell(\theta, z_k)\)。泛化界通常使用均匀集中结果得到。
- 在线学习 (Online Learning):每次接收一个新的(可能是对抗性的)观测 \(z_n\),并更新 \(\hat{\theta}_n\)。累积损失为 \(\frac{1}{n}\sum_{k=1}^n \ell(\hat{\theta}_{k-1}, z_k)\)。通过平均可以将在线学习结果转化为批量学习结果。
凸随机逼近 (Convex Stochastic Approximation) (page 79-81) ¶
- 关键性质 :
- 光滑性 (Smoothness):函数 \(f\) 是 \(B\) -Lipschitz 连续的,其梯度 \(f'\) 是 \(L\) -Lipschitz 连续的。
- 强凸性 (Strong Convexity):函数 \(f\) 是 \(\mu\) - 强凸的。
- 核心算法: 随机梯度下降 (Robbins-Monro)。 $$ \theta_n = \theta_{n-1} - \gamma_n f'n(\theta) $$
- Polyak-Ruppert 平均: \(\bar{\theta}_n = \frac{1}{n}\sum_{k=0}^{n-1} \theta_k\)。
- 学习率序列: 经典的设置是 \(\gamma_n = Cn^{-\alpha}\)。
随机次梯度下降 (Stochastic Subgradient Method) (page 82-85) ¶
- 假设: \(f_n\) 是凸的且 \(B\) -Lipschitz 连续的,并且是 i.i.d. 函数,满足 \(\mathbb{E} f_n = f\)。\(f\) 的全局最优解 \(\theta^*\) 在约束集 \(C = \{\theta \mid \|\theta\|_2 \le D\}\) 内。
- 算法: $$ \theta_n = \Pi_D \left(\theta_{n-1} - \frac{2D}{B\sqrt{n}}f'n(\theta)\right) $$
- 收敛界 (Bound):随机次梯度法的收敛速度通常是 \(O(1/\sqrt{n})\): $$ \mathbb{E}f\left(\frac{1}{n}\sum_{k=0}^{n-1}\theta_k\right) - f(\theta^*) \le \frac{2DB}{\sqrt{n}} $$
- 运行时间复杂度: 经过 \(n\) 次迭代后,总运行时间复杂度为 \(O(dn)\)。这比批量次梯度下降的 \(O(n^2d)\) 更优,因为每次迭代只计算一个样本的次梯度。
强凸情况下的随机次梯度下降 (Strong Convexity) (page 89-91) ¶
如果函数 \(f\) 是 \(\mu\) - 强凸的,且次梯度有界,那么随机次梯度下降的收敛速度为 \(O(1/n)\): $$ \mathbb{E}f\left(\frac{2}{n(n+1)}\sum_{k=1}^n k\theta_{k-1}\right) - f(\theta^*) \le \frac{2B^2}{\mu(n+1)} $$
高概率界 (High-Probability Bounds) (page 96-100) ¶
除了期望收敛,我们还关心高概率下的收敛界。
- 典型结果: 通过马尔可夫不等式,可以从期望收敛结果推导出高概率界: $$ \mathbb{P}\left(f\left(\frac{1}{n}\sum_{k=0}^{n-1}\theta_k\right) - f(\theta^*) \ge \varepsilon\right) \le \frac{2DB}{\sqrt{n}\varepsilon} $$
- 偏差不等式 (Deviation inequality):利用更强大的偏差不等式(如 Azuma-Hoeffding 不等式)可以获得更紧的高概率界。对于有界鞅差分序列,可以得到: $$ \mathbb{P}\left(\sum_{u=1}^n \frac{Z_u}{2\gamma_u} \ge t\sqrt{n} \cdot 4DB\right) \le \exp\left(-\frac{t^2}{2}\right) $$ 其中 \(Z_u = -2\gamma_u(\theta_{u-1}-\theta^*)^\top[f'_u(\theta_{u-1}) - f'(\theta_{u-1})]\) 是鞅差分序列。
收敛速率总结 (Summary of Rates of Convergence) (page 71, 101) ¶
下表总结了不同类型函数和优化设置下的收敛速率。
| 类型 | 性质 | 确定性方法 (Deterministic) | 随机方法 (Stochastic) | 有限和 (Finite Sum) |
|---|---|---|---|---|
| 非光滑凸 | 凸 | \(BD/\sqrt{t}\) | \(BD/\sqrt{n}\) | |
| 强凸 | \(B^2/(t\mu)\) | \(B^2/(n\mu)\) | ||
| 光滑凸 | 凸 | \(LD^2/t^2\) | \(LD^2/\sqrt{n}\) | \(n/t\) |
| 强凸 | \(\exp(-t\sqrt{\mu/L})\) | \(L/(n\mu)\) | \(\exp(-\min\{1/n, \mu/L\}t)\) | |
| 二次 | 凸 | \(LD^2/t^2\) | \(d/n + LD^2/n\) | |
| 强凸 | \(\exp(-t\sqrt{\mu/L})\) | \(d/n + LD^2/n\) |
其中:
- \(D\): 域的直径 (diameter of the domain)。
- \(B\): Lipschitz 常数。
- \(L\): 光滑常数。
- \(\mu\): 强凸常数。
- \(t\): 迭代次数。
- \(n\): 样本数量。
- \(d\): 维度。
注意:
- 对于非光滑凸函数,随机方法通常比确定性方法更快,因为它们能够利用数据的随机性。
- 对于光滑凸函数,加速梯度方法可以达到 \(O(1/t^2)\) 的收敛率,优于普通梯度下降的 \(O(1/t)\)。
- 强凸函数通常具有指数级的收敛速度,这比次线性收敛快得多。
- 在随机设置下,收敛率通常依赖于样本数量 \(n\),而不是迭代次数 \(t\)。
-
Robbins, H., & Monro, S. (1951). A stochastic approximation method. The Annals of Mathematical Statistics, 22(3), 400-407. ↩