7 SVM
支持向量机(Support Vector Machine, SVM)是一种功能强大且用途广泛的监督学习模型,能够执行线性和非线性分类、回归,甚至异常值检测任务。它在 20 世纪 90 年代由 Vapnik 等人提出,因其在理论上的完备性和在实践中优异的性能,迅速成为机器学习领域的明星算法之一。
推荐阅读 SVM 系列 - 从基础到掌握
感知机 (page 6-7) ¶
在深入了解支持向量机之前,我们先回顾一下它的“前身”——感知机(Perceptron
感知机 (Perceptron)
感知机是 1957 年由 Frank Rosenblatt 提出的一种早期的人工神经网络模型,可以被看作是最简单的前馈神经网络。它本质上是一个二元线性分类器。
模型定义:
-
分类超平面:
\[ w \cdot x + b = 0 \]其中,\(w\) 是权重向量,\(b\) 是偏置项,\(x\) 是输入特征向量。这个超平面将特征空间一分为二。
-
分类决策函数:
\[ f(x) = \text{sign}(w \cdot x + b) \]\(\text{sign}(\cdot)\) 是符号函数,当输入大于 0 时输出 +1,小于 0 时输出 -1。
感知机的学习目标是通过训练数据找到一组参数 \(w\) 和 \(b\)。
- 学习策略:最小化所有误分类点到分类超平面的总距离。
- 学习算法:通常采用随机梯度下降 (SGD) 的方法,一次只用一个误分类点来更新 \(w\) 和 \(b\)。
感知机的特点与局限性:
- 解不唯一:对于同一个线性可分的数据集,感知机算法可能因为初始值的不同或样本点的选取顺序不同,而找到多个不同的分离超平面。如幻灯片第 5 页所示,有很多条线都能将两类点分开,但哪一条是“最好”的呢?感知机没有回答这个问题。
- 收敛性:对于线性可分的数据集,感知机算法被证明是收敛的,即经过有限次迭代后,总能找到一个能够将训练数据完全正确划分的超平面。但对于线性不可分的数据,算法将不会收敛,会永远震荡下去。
感知机 vs. 支持向量机
感知机的目标是找到任意一个可以将数据分开的超平面。而支持向量机(SVM)的目标是找到最好的那一个,也就是接下来要讲的“间隔最大化”的超平面。这使得 SVM 通常具有更好的泛化性能。
支持向量机(SVM)概述 (page 8-9) ¶
支持向量机是对感知机模型的重大改进,其核心思想是间隔最大化。
支持向量机 (Support Vector Machine, SVM)
- 它首先是一个二分类模型。
- 其学习策略是间隔最大化 (Margin Maximization),这使得它与感知机有本质区别。
- 其学习问题可以形式化为一个凸二次规划 (Convex Quadratic Programming) 问题,这保证了它能找到全局最优解。这个问题也等价于一个带 L2 正则化的合页损失函数 (Hinge Loss) 的最小化问题。
- 通过引入核技巧 (Kernel Trick),SVM 可以高效地处理非线性分类问题,成为实质上的非线性分类器。
根据数据和问题的不同,SVM 可以分为以下三类:
- 线性可分支持向量机 (Linear SVM in Linearly Separable Case)
- 当训练数据是线性可分的,通过硬间隔最大化 (Hard Margin Maximization) 学习一个线性分类器。这对应于上图中的图 a。
- 线性支持向量机 (Linear SVM)
- 当训练数据近似线性可分时(即存在一些噪声点或异常值
) ,通过软间隔最大化 (Soft Margin Maximization) 来学习。这对应于上图中的图 b。
- 当训练数据近似线性可分时(即存在一些噪声点或异常值
- 非线性支持向量机 (Non-linear SVM)
- 当训练数据是线性不可分的,通过使用核技巧和软间隔最大化来学习。这对应于上图中的图 c,它将原始二维空间中的数据映射到了三维空间,从而变得线性可分。
线性可分支持向量机 (page 10-28) ¶
我们首先从最简单的情况开始:训练数据是完全线性可分的。
问题设定:
-
给定训练数据集:
\[ T = \{(x_1, y_1), (x_2, y_2), \dots, (x_N, y_N)\} \]其中,\(x_i \in \mathcal{X} = \mathbb{R}^n\) 是第 \(i\) 个样本的特征向量,\(y_i \in \mathcal{Y} = \{+1, -1\}\) 是对应的类别标签。 - 学习目标:在特征空间中找到一个分离超平面,能将不同类别的样本分到超平面的两侧。 - 决策函数:找到最优的 \(w^*\) 和 \(b^*\) 后,最终的决策函数为: $$ f(x) = \text{sign}(w^ \cdot x + b^) $$
函数间隔与几何间隔 (page 13-16) ¶
为了找到“最好”的超平面,我们需要一种方式来度量一个超平面对样本分类的确信度。SVM 引入了“间隔” (Margin) 的概念。
函数间隔 (Functional Margin)
对于给定的一个样本 \((x_i, y_i)\) 和一个超平面 \((w,b)\),其函数间隔定义为:
- \(\hat{\gamma}_i > 0\) 表示分类正确。
- \(|\hat{\gamma}_i|\) 的大小可以表示分类的确信程度。值越大,点离超平面越远,分类越可信。
对于整个训练数据集,其函数间隔定义为所有样本点中最小的函数间隔:
缺点:函数间隔有一个问题,当我们按比例缩放 \(w\) 和 \(b\)(例如,都乘以 2
为了解决这个问题,我们需要一个不受缩放影响的、更本质的度量,这就是几何间隔。
几何间隔 (Geometric Margin)
几何间隔是点到超平面的真实欧氏距离。根据点到平面的距离公式,样本 \((x_i, y_i)\) 到超平面 \((w,b)\) 的几何间隔为:
为了表示分类的正确性,我们同样引入标签 \(y_i\):
几何间隔不随 \(w\) 和 \(b\) 的等比例缩放而改变,是一个更稳定的度量。
对于整个训练数据集,其几何间隔定义为:
( 硬 ) 间隔最大化 (page 17-18) ¶
SVM 的目标就是找到一个超平面,使得这个几何间隔 \(\gamma\) 最大化。这可以表示为以下约束最优化问题:
这个问题看起来有点复杂。我们可以利用函数间隔和几何间隔的关系 \(\gamma = \hat{\gamma} / \|w\|\) 来简化它。最大化 \(\gamma\) 相当于在固定 \(\hat{\gamma}\) 的情况下最大化 \(1/\|w\|\)。
我们可以将上述问题转化为:
注意到函数间隔 \(\hat{\gamma}\) 的取值并不影响最优化问题的解(因为如果 \((w, b)\) 是一个解,那么 \((\lambda w, \lambda b)\) 也是,我们可以自由缩放
这个设定非常关键,它意味着所有样本点的函数间隔都必须大于等于 1。
为什么可以令 \(\hat{\gamma}=1\)?
假设我们找到了最优解 \((w^*, b^*)\),它对应的函数间隔是 \(\hat{\gamma}^*\)。那么我们总可以通过缩放得到一组新的参数 \(w' = w^*/\hat{\gamma}^*\) 和 \(b' = b^*/\hat{\gamma}^*\)。对于这组新参数,超平面没有变,但是它的函数间隔变成了 \(\hat{\gamma}' = y_i(w' \cdot x_i + b') = y_i(w^*/\hat{\gamma}^* \cdot x_i + b^*/\hat{\gamma}^*) = 1\)。所以,这个设定不失一般性。
令 \(\hat{\gamma} = 1\) 后,最大化 \(\frac{1}{\|w\|}\) 就等价于最小化 \(\|w\|\),为了后续求导方便,我们通常最小化 \(\frac{1}{2}\|w\|^2\)。这样,我们得到了线性可分 SVM 的最终标准型:
线性可分 SVM 的原始最优化问题
这是一个典型的凸二次规划 (Convex Quadratic Programming) 问题。
凸优化问题 (page 19-22)
凸优化问题是一类特殊的优化问题,它具有很好的性质,即局部最优解就是全局最优解。
- 凸集 (Convex Set):集合内任意两点的连线段上的所有点都仍然在该集合内。
- 凸函数 (Convex Function):函数图形上任意两点之间的弦都在这两点之间的函数图形的上方。对于可微函数,其一阶导数(梯度)满足 \(f(x_2) \ge f(x_1) + \nabla f(x_1)^T (x_2 - x_1)\);对于二阶可微函数,其 Hessian 矩阵半正定。
- 凸优化问题:指目标函数为凸函数,且可行域(由约束条件定义的区域)为凸集的优化问题。 $$ \begin{align} &\min_w f(w) \ \text{s.t.}\quad & g_i(w) \le 0, \quad i = 1,2, \dots, k \ &h_j(w) = 0, \quad j = 1,2, \dots, l \end{align} $$ 其中,\(f(w)\) 和 \(g_i(w)\) 都是凸函数,\(h_j(w)\) 是仿射函数(形如 \(a \cdot w + b = 0\))。
SVM 的优化问题中,目标函数 \(\frac{1}{2}\|w\|^2\) 是凸函数,约束条件 \(1 - y_i(w \cdot x_i + b) \le 0\) 是关于 \((w,b)\) 的仿射函数(也是凸函数
支持向量与间隔边界 (page 27) ¶
在解决了这个优化问题之后,我们会发现一个有趣的现象:
支持向量 (Support Vectors)
在线性可分的情况下,训练数据中那些与分离超平面距离最近的样本点被称为支持向量。
这些点是使得优化问题中的约束条件等号成立的点,即:
- 对于正例 (\(y_i = +1\)),支持向量位于超平面 \(w \cdot x + b = 1\) 上。
- 对于负例 (\(y_i = -1\)),支持向量位于超平面 \(w \cdot x + b = -1\) 上。
这两个平行于分离超平面的平面 \(H_1\) 和 \(H_2\) 之间的距离被称为间隔 (margin),其宽度为 \(2/\|w\|\)。
重要性:最终的分离超平面仅仅由这些支持向量决定,而与其他数据点无关。如果移动非支持向量,只要它们不越过间隔边界,就不会对最优解产生任何影响。这体现了 SVM 的稀疏性和鲁棒性。
(page 28) 给定三个点:\(x_1=(3,3)^T, y_1=1\); \(x_2=(4,3)^T, y_2=1\); \(x_3=(1,1)^T, y_3=-1\)。求最大间隔分离超平面。
根据 SVM 原始优化问题,我们求解:
通过求解这个 QP 问题(具体过程在后面的对偶算法中会更清晰
\(w_1 = w_2 = \frac{1}{2}, b = -2\)
- 分离超平面: \(\frac{1}{2}x^{(1)} + \frac{1}{2}x^{(2)} - 2 = 0\)
- 支持向量: 将三个点代入 \(y(w \cdot x + b)\):
- \(x_1\): \(1 \cdot (\frac{1}{2} \cdot 3 + \frac{1}{2} \cdot 3 - 2) = 1\). 这是支持向量。
- \(x_2\): \(1 \cdot (\frac{1}{2} \cdot 4 + \frac{1}{2} \cdot 3 - 2) = 1.5 > 1\). 这不是支持向量。
- \(x_3\): \(-1 \cdot (\frac{1}{2} \cdot 1 + \frac{1}{2} \cdot 1 - 2) = 1\). 这是支持向量。
因此,支持向量是 \(x_1 = (3,3)^T\) 和 \(x_3 = (1,1)^T\)。
对偶算法 (page 29-48) ¶
直接求解原始的凸二次规划问题在变量维度很高时可能很复杂。一个更常用、更高效,并且能自然引出核技巧的方法是求解它的对偶问题 (Dual Problem)。
拉格朗日对偶性 (page 29-35) ¶
拉格朗日对偶性 (Lagrange Duality)
考虑一个一般的约束优化问题(原始问题
-
定义拉格朗日函数:我们为每个约束引入一个拉格朗日乘子 \(\alpha_i \ge 0\) 和 \(\beta_j\),构造拉格朗日函数 \(L(x, \alpha, \beta)\):
\[ L(x, \alpha, \beta) = f(x) + \sum_{i=1}^k \alpha_i c_i(x) + \sum_{j=1}^l \beta_j h_j(x) \] -
原始问题的等价形式:可以证明,原始问题等价于下面的极小极大 (minimax) 问题:
$$ p^* = \min_{x} \max_{\alpha \ge 0, \beta} L(x, \alpha, \beta) $$ 这里的 \(p^*\) 是原始问题的最优值。
-
定义对偶问题:交换
min和max的顺序,得到极大极小 (maximin) 问题,即对偶问题:$$ d^* = \max_{\alpha \ge 0, \beta} \min_{x} L(x, \alpha, \beta) $$ 这里的 \(d^*\) 是对偶问题的最优值。
-
弱对偶性:在任何情况下,对偶问题的最优值总是小于或等于原始问题的最优值,即 \(d^* \le p^*\)。
-
强对偶性与 KKT 条件:当原始问题是凸优化问题,并且满足某些条件(如 Slater 条件)时,强对偶性成立,即 \(d^* = p^*\)。此时,我们可以通过求解更简单的对偶问题来得到原始问题的解。并且,原始问题和对偶问题的最优解 \((x^*, \alpha^*, \beta^*)\) 必须满足Karush-Kuhn-Tucker (KKT) 条件。
KKT 条件 (page 34)
对偶互补条件是 KKT 条件中最重要的部分。它表明,如果一个不等式约束是“松的”(即 \(c_i(x^*) < 0\)
SVM 对偶问题推导 (page 36-39) ¶
现在,我们将拉格朗日对偶性应用到线性可分 SVM 的原始问题上。
-
构造拉格朗日函数: 原始问题为 \(\min \frac{1}{2}\|w\|^2\) s.t. \(1 - y_i(w \cdot x_i + b) \le 0\)。引入拉格朗日乘子 \(\alpha = (\alpha_1, \dots, \alpha_N)^T\),其中 \(\alpha_i \ge 0\)。
$$ L(w, b, \alpha) = \frac{1}{2}|w|^2 - \sum_{i=1}^N \alpha_i (y_i(w \cdot x_i + b) - 1) $$ 那么对偶问题为 \(max_{\alpha}min_{w,b}L(w, b, \alpha)\) 。
-
求 \(\min_{w,b} L(w, b, \alpha)\): 为了求 \(L\) 对 \(w, b\) 的极小值,我们分别对 \(w\) 和 \(b\) 求偏导并令其为 0。 $$ \nabla_w L(w, b, \alpha) = w - \sum_{i=1}^N \alpha_i y_i x_i = 0 \quad \implies \quad w = \sum_{i=1}^N \alpha_i y_i x_i $$
\[ \nabla_b L(w, b, \alpha) = -\sum_{i=1}^N \alpha_i y_i = 0 \quad \implies \quad \sum_{i=1}^N \alpha_i y_i = 0 \]将这两个结果代回到拉格朗日函数 \(L\) 中,以消去 \(w\) 和 \(b\):
$$ \begin{align} \min_{w,b} L(w,b,\alpha) &= \frac{1}{2} \left( \sum_i \alpha_i y_i x_i \right)^T \left( \sum_j \alpha_j y_j x_j \right) - \sum_i \alpha_i y_i \left( \left( \sum_j \alpha_j y_j x_j \right)^T x_i + b \right) + \sum_i \alpha_i \ &= \frac{1}{2} \sum_i \sum_j \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_i \sum_j \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - b \sum_i \alpha_i y_i + \sum_i \alpha_i \ &= -\frac{1}{2} \sum_i \sum_j \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_i \alpha_i \end{align} $$ 这里我们用到了 \(\sum_i \alpha_i y_i = 0\)。
-
对偶问题: 现在我们要求解 \(\max_{\alpha} \left( -\frac{1}{2} \sum_i \sum_j \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_i \alpha_i \right)\),这通常写成一个等价的
min问题。
线性可分 SVM 的对偶最优化问题 (page 39)
求解原始变量 (page 40-42) ¶
在解出对偶问题的最优解 \(\alpha^* = (\alpha_1^*, \dots, \alpha_N^*)^T\) 后,我们可以根据 KKT 条件来恢复原始问题的解 \(w^*\) 和 \(b^*\)。
-
计算 \(w^*\): 根据前面求导的结果,我们有: $$ w^ = \sum_{i=1}^N \alpha_i^ y_i x_i $$
-
计算 \(b^*\): 根据KKT的对偶互补条件 \(\alpha_i^*(y_i(w^* \cdot x_i + b^*) - 1) = 0\),我们知道,必然存在至少一个 \(\alpha_j^* > 0\)(否则 \(w^*=0\),不是原始问题的解)。对于任何一个 \(\alpha_j^* > 0\) 的样本 \(x_j\)(它就是一个支持向量),必须有: $$ y_j(w^ \cdot x_j + b^) - 1 = 0 $$ 两边同乘以 \(y_j\)(注意到 \(y_j^2=1\)),可得: $$ w^ \cdot x_j + b^ = y_j $$ 于是,可以解出 \(b^*\): $$ b^ = y_j - w^ \cdot x_j = y_j - \sum_{i=1}^N \alpha_i^* y_i (x_i \cdot x_j) $$ 在实际计算中,为了更稳健,通常会选择所有支持向量计算出的 \(b^*\) 值,然后取平均值。
对偶形式的优势
- 支持向量的体现:从 \(w^*\) 的表达式可以看出,只有那些 \(\alpha_i^* > 0\) 的样本(即支持向量)才对 \(w^*\) 有贡献。
- 内积计算:可以看到,无论是对偶问题的目标函数还是最终的决策函数,都只涉及到输入样本之间的内积 (inner product) \(x_i \cdot x_j\)。这个特性是使用核技巧的关键。
最终,分类决策函数也可以写成对偶形式: $$ f(x) = \text{sign} \left( \sum_{i=1}^N \alpha_i^ y_i (x_i \cdot x) + b^ \right) $$
线性支持向量机与软间隔最大化 (page 49-62) ¶
现实世界的数据往往不是完美线性可分的,可能存在一些特异点 (outlier) 或噪声。如果坚持使用硬间隔最大化,可能会导致模型过拟合,或者根本找不到解。
为了解决这个问题,我们允许模型犯一些错误,引入软间隔最大化 (Soft Margin Maximization)。
软间隔的优化问题 (page 49-50) ¶
我们对每个样本点 \((x_i, y_i)\) 引入一个松弛变量 (slack variable) \(\xi_i \ge 0\)。
-
约束条件:函数间隔加上松弛变量要大于等于 1。 $$ y_i(w \cdot x_i + b) \ge 1 - \xi_i $$ 如果 \(\xi_i = 0\),样本被正确分类且在间隔边界之外。如果 \(0 < \xi_i \le 1\),样本在间隔边界之内但仍被正确分类。如果 \(\xi_i > 1\),样本被错误分类。
-
目标函数:我们希望总的松弛量尽可能小,因此在原目标函数中加入一个惩罚项。 $$ \min_{w,b,\xi} \frac{1}{2}|w|^2 + C \sum_{i=1}^N \xi_i $$ 其中 \(C > 0\) 是一个惩罚参数(也叫正则化参数
) ,由用户设定。
惩罚参数 C 的作用
\(C\) 用来权衡“间隔大小”和“分类错误”这两个目标。 - 大的 C:意味着对误分类的惩罚很重,算法会倾向于选择一个更小的间隔来尽可能地正确分类所有样本,可能导致过拟合。 - 小的 C:意味着对误分类的容忍度更高,算法会选择一个更大的间隔,即使这会导致一些样本被误分类,模型泛化能力可能更强。
最终,线性 SVM(软间隔)的原始优化问题是:
软间隔的对偶问题 (page 51-57) ¶
通过与硬间隔情况类似的推导(引入两组拉格朗日乘子 \(\alpha_i\) 和 \(\beta_i\)
线性 SVM 的对偶最优化问题 (page 54)
对比硬间隔的对偶问题,唯一的变化是 \(\alpha_i\) 多了一个上界 \(C\),即所谓的盒约束 (box constraint)。
在软间隔情况下,支持向量的含义更丰富,根据 KKT 条件和 \(\alpha_i^*\) 的取值(page 57
- 若 \(\alpha_i^* = 0\),则 \(y_i(w^* \cdot x_i + b^*) \ge 1\),样本在间隔边界外被正确分类。
- 若 \(0 < \alpha_i^* < C\),则 \(y_i(w^* \cdot x_i + b^*) = 1\)(即 \(\xi _{i} = 0\)
) ,样本在间隔边界上,是标准的支持向量。 - 若 \(\alpha_i^* = C\),则 \(y_i(w^* \cdot x_i + b^*) \le 1\)。
- 若 \(y_i(w^* \cdot x_i + b^*) < 1\) ( 即 \(\xi_i > 0\)),样本在间隔边界内,可能是正确分类(\(\xi _{i}<1\))也可能是错误分类(\(\xi_{i}>1\)
) 。这些点也是支持向量。
- 若 \(y_i(w^* \cdot x_i + b^*) < 1\) ( 即 \(\xi_i > 0\)),样本在间隔边界内,可能是正确分类(\(\xi _{i}<1\))也可能是错误分类(\(\xi_{i}>1\)
合页损失函数 (page 58-62) ¶
软间隔 SVM 的原始优化问题还可以从另一个角度来理解,即损失函数最小化。
合页损失函数 (Hinge Loss)
合页损失函数定义为:
对于一个样本 \((x_i, y_i)\),令 \(z = y_i(w \cdot x_i + b)\),则其合页损失为 \(\max(0, 1 - y_i(w \cdot x_i + b))\)。
- 当 \(y_i(w \cdot x_i + b) \ge 1\) 时(分类正确且在间隔外
) ,损失为 0。 - 当 \(y_i(w \cdot x_i + b) < 1\) 时(在间隔内或分类错误
) ,损失为 \(1 - y_i(w \cdot x_i + b) > 0\),且损失随距离线性增加。
可以证明,软间隔 SVM 的原始优化问题 $$ \min_{w,b,\xi} \quad \frac{1}{2}|w|^2 + C \sum_{i=1}^N \xi_i $$ 等价于最小化以下目标函数: $$ \min_{w,b} \quad \sum_{i=1}^N [1 - y_i(w \cdot x_i + b)]_+ + \lambda |w|^2 $$ 这是一种常见的正则化形式:经验风险 ( 合页损失 ) + 结构风险 (L2 正则化项 )。其中正则化参数 \(\lambda\) 和惩罚参数 \(C\) 是成反比关系的 (\(\lambda = 1/(2C)\))。
非线性支持向量机与核函数 (page 65-83) ¶
当数据本身就是非线性的,比如一个“环形”分布的数据,任何直线都无法分开。此时,我们需要非线性支持向量机。
特征映射与核技巧 (page 66-72) ¶
解决非线性问题的基本思路是:
- 非线性变换(特征映射):使用一个映射函数 \(\phi(x)\),将原始输入空间 \(\mathcal{X}\) 中的数据点 \(x\) 映射到一个更高维度的特征空间 \(\mathcal{H}\)。
- 线性分类:我们希望在这个新的特征空间中,数据变得线性可分(或近似线性可分
) ,然后我们就可以在 \(\mathcal{H}\) 中使用前面介绍的线性 SVM 来学习分类模型。
然而,这个特征空间 \(\mathcal{H}\) 的维度可能非常高,甚至是无限维,直接计算 \(\phi(x)\) 是不现实的。
核技巧 (Kernel Trick)
回顾 SVM 的对偶问题,我们发现所有计算都只涉及样本的内积 \((x_i \cdot x_j)\)。在特征空间中,这个内积就变成了 \((\phi(x_i) \cdot \phi(x_j))\)。
核技巧的核心思想是:我们不需要知道映射函数 \(\phi\) 的具体形式,也不需要在高维特征空间中进行计算,我们只需要定义一个核函数 (Kernel Function) \(K(x_i, x_j)\),使得它的计算结果等于特征空间中的内积:
这样,我们就可以直接在原始输入空间中计算核函数的值,来隐式地利用高维特征空间的强大表示能力,而计算量却没有显著增加。
核函数的定义与常用核函数 (page 68, 81) ¶
核函数 (Kernel Function)
设 \(\mathcal{X}\) 是输入空间,\(\mathcal{H}\) 是特征空间(一个希尔伯特空间
一个函数 \(K(x,z)\) 能否成为核函数的充要条件是它是正定核 (Positive-definite Kernel),即对于任意数据点集 \(\{x_1, \dots, x_m\}\),其对应的Gram 矩阵 \(K_{ij} = K(x_i, x_j)\) 是半正定的。
常用核函数:
-
多项式核函数 (Polynomial Kernel) $$ K(x, z) = (x \cdot z + 1)^p $$ 它对应的SVM是一个 \(p\) 次多项式分类器。
-
高斯核函数 (Gaussian Kernel),也称径向基函数核 (RBF Kernel) $$ K(x, z) = \exp\left(-\frac{|x-z|^2}{2\sigma^2}\right) $$ 这是最常用的一种核函数,它可以将原始数据映射到无限维的特征空间,具有很强的拟合能力。\(\sigma\) 是一个需要调节的超参数,控制了“高斯钟形”的宽度。
非线性 SVM 算法 (page 82-83) ¶
使用核技巧后,非线性 SVM 的学习算法非常简洁:
非线性 SVM 学习算法
- 输入:训练数据 \(T = \{(x_1, y_1), \dots, (x_N, y_N)\}\)。
- 选取:选择合适的核函数 \(K(x_{i},x_{j})\) 和惩罚参数 \(C\)。
- 求解对偶问题: $$ \begin{align} \min_{\alpha} \quad &\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j K(x_i, x_j) - \sum_{i=1}^N \alpha_i \ \text{s.t.} \quad & \sum_{i=1}^N \alpha_i y_i = 0 \ & 0 \le \alpha_i \le C, \quad i = 1,2, \dots, N \end{align} $$ 得到最优解 \(\alpha^*\)。
- 计算 \(b^*\):选择一个满足 \(0 < \alpha_j^* < C\) 的分量,计算 $$ b^ = y_j - \sum_{i=1}^N \alpha_i^ y_i K(x_i, x_j) $$
- 构造决策函数: $$ f(x) = \text{sign}\left( \sum_{i=1}^{N_s} \alpha_i^ y_i K(x_i, x) + b^ \right) $$ 其中 \(N_s\) 是支持向量的个数。
序列最小最优化算法(SMO) (page 84-100)¶
SVM 的对偶问题是一个二次规划问题。当训练样本数量 \(N\) 非常大时,通用的 QP 求解器会变得非常慢,内存开销也很大(因为 Gram 矩阵 \(K\) 的大小是 \(N \times N\)
序列最小最优化 (Sequential Minimal Optimization, SMO) 是一种专门用于快速求解 SVM 对偶问题的有效算法。
SMO 算法 (page 84, 86)
动机:解决大规模训练集下 SVM 的计算效率问题。
核心思想:SMO 将一个大的 QP 问题分解为一系列最小的 QP 子问题来求解。
- 变量选择:SMO 算法每次迭代时,选择两个拉格朗日乘子 \(\alpha_i\) 和 \(\alpha_j\) 作为变量,并将其他所有乘子 \(\alpha_k (k \ne i, j)\) 看作是固定的。
- 解析求解:因为有约束 \(\sum \alpha_i y_i = 0\),一旦固定了其他变量,\(\alpha_i\) 和 \(\alpha_j\) 之间就存在线性关系。这使得这个两个变量的二次规划子问题可以被解析地(也就是用公式直接)求解,而不需要调用数值优化方法,从而大大提高了计算速度。
- 迭代:算法不断地重复这个过程,通过启发式方法(通常是选择违反 KKT 条件最严重的变量)选择一对 \((\alpha_i, \alpha_j)\) 进行优化,直到所有变量都在一定精度内满足 KKT 条件为止。
SMO 算法的详细推导过程比较复杂(如幻灯片 page 87-99 所示
误差分析 (page 101-102,考试不涉及 ) ¶
这部分简要介绍了 SVM 的理论基础,涉及统计学习理论中的泛化误差分析。
- 错分误差 (Misclassification Error) \(\mathcal{R}(C)\):指分类器 \(C\) 在整个数据分布上犯错的概率。
- 贝叶斯最优分类器 (Bayes Rule) \(f_c\):理论上能达到的最低错分误差的分类器,它的决策是 \(f_c(x) = \text{arg min}_y P(y|x)\)。
- Excess Misclassification Error:指我们通过算法学到的分类器 \(f_{z, \lambda}^\phi\) 的错分误差,与理论最优的贝叶斯误差 \(\mathcal{R}(f_c)\) 之间的差距。
- 泛化界:幻灯片第 102 页展示了一个 SVM 泛化误差界的例子。这类理论结果告诉我们,在一定条件下,SVM 的泛化误差会随着训练样本数量的增加而减小,这为 SVM 的良好性能提供了理论保障。
习题 ¶
习题 7.1
比较感知机的对偶形式与线性可分支持向量机的对偶形式。
在感知机的对偶形式中,对偶函数为:
线性可分支持向量机的对偶函数最后可化作:
结合上课内容可以发现:
- 在两者的对偶形式中,w,b 都可以表示为⟨xi,yi⟩的线性组合形式;
- 在两者的对偶形式中,都可以通过求解 \(\alpha=(\alpha_1,\alpha_2,\cdots,\alpha_N)^T\),最后代入由 \(x_i,y_i,α_i\) 表示的 L(w, b) 中,从而求解最优化问题的解 \(w^{*}\) 和 \(b^{*}\);
- 感知机学习得到一个分隔超平面,而线性可分支持向量机学习得到所有分隔超平面中的间隔最大分隔超平面。
习题 7.2
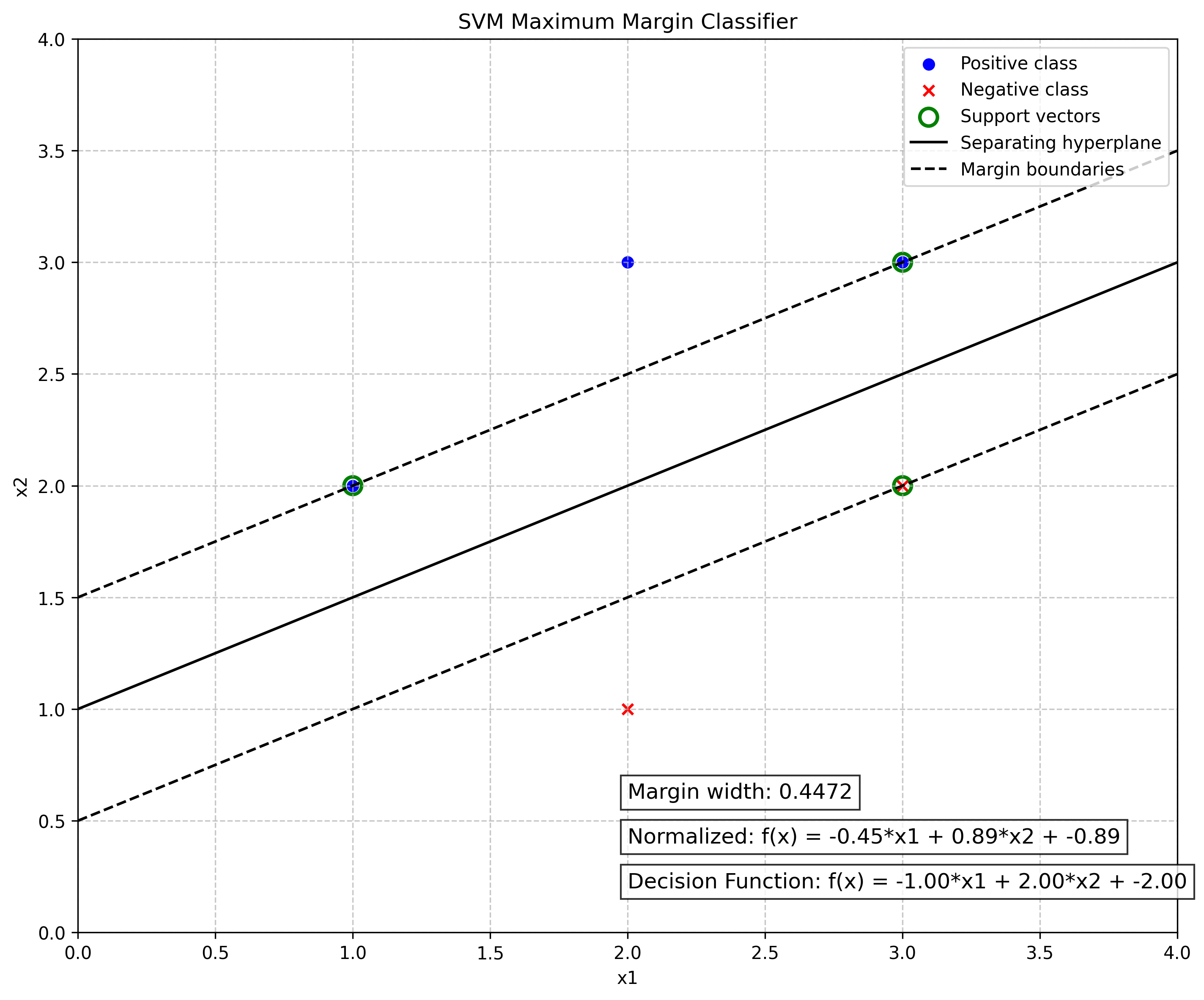
已知正例点 \(x_{1}=(1,2)^{T},x_{2}=(2,3)^{T},x_{3}=(3,3)^{T}\) 负例点 \(x_{4}=(2,1)^{T},x_{5}=(3,2)^{T}\) 试求最大间隔分离平面和分类决策函数 , 并在图中画出分离超平面、间隔边界及支持向量。
也可以参考 slide 46-47 页方法计算,这里 5 个点数据计算比较多。
利用 sklearn 以及 matplotlab 进行求解绘图(代码附在末尾)输出结果如下:
Weight vector (w): [-1. 2.]
Bias (b): -2.0000000000000004
Support vector indices: [4 0 2]
Support vectors:
[[3 2]
[1 2]
[3 3]]
Margin width: 0.44721359549995765
Decision function: f(x) = -1.0000*x1 + 2.0000*x2 + -2.0000
可以得到:
- 最大间隔分离超平面: \(-x^{(1)}+2x^{(2)}-2=0\)
- 分类决策函数:\(f(x)=\sin(-x^{(1)}+2x^{(2)}-2)\)
- 支持向量: \(x_1=(3,2)^T,x_2=(1,2)^T,x_3=(3,3)^T\)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
##### train the svm #####
positive_samples = np.array([[1, 2], [2, 3], [3, 3]])
negative_samples = np.array([[2, 1], [3, 2]])
X = np.vstack((positive_samples, negative_samples))
y = np.array([1, 1, 1, -1, -1]) # 1 for positive class, -1 for negative class
svm = SVC(kernel="linear", C=1e6)
svm.fit(X, y)
w = svm.coef_[0] # Normal vector to the hyperplane
b = svm.intercept_[0] # Intercept
sv_indices = svm.support_ # Indices of support vectors
##### Draw the pic #####
def get_hyperplane_points(w, b, x_min, x_max):
# w[0]*x + w[1]*y + b = 0
# y = (-w[0]*x - b) / w[1]
x = np.linspace(x_min, x_max, 100)
y = (-w[0] * x - b) / w[1]
return x, y
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(
positive_samples[:, 0],
positive_samples[:, 1],
c="b",
marker="o",
label="Positive class",
)
ax.scatter(
negative_samples[:, 0],
negative_samples[:, 1],
c="r",
marker="x",
label="Negative class",
)
support_vectors = X[sv_indices]
ax.scatter(
support_vectors[:, 0],
support_vectors[:, 1],
s=100,
facecolors="none",
edgecolors="g",
linewidths=2,
label="Support vectors",
)
x_min, x_max = 0, 4
x_hyperplane, y_hyperplane = get_hyperplane_points(w, b, x_min, x_max)
ax.plot(x_hyperplane, y_hyperplane, "k-", label="Separating hyperplane")
x_pos_margin, y_pos_margin = get_hyperplane_points(w, b - 1, x_min, x_max)
x_neg_margin, y_neg_margin = get_hyperplane_points(w, b + 1, x_min, x_max)
ax.plot(x_pos_margin, y_pos_margin, "k--", label="Margin boundaries")
ax.plot(x_neg_margin, y_neg_margin, "k--")
ax.set_xlim(x_min, x_max)
ax.set_ylim(0, 4)
ax.set_xlabel("x1")
ax.set_ylabel("x2")
ax.set_title("SVM Maximum Margin Classifier")
margin = 1 / np.sqrt(np.sum(w**2))
w_norm = np.linalg.norm(w)
normalized_w = w / w_norm
normalized_b = b / w_norm
formula = f"Decision Function: f(x) = {w[0]:.2f}*x1 + {w[1]:.2f}*x2 + {b:.2f}"
normalized_formula = f"Normalized: f(x) = {normalized_w[0]:.2f}*x1 + {normalized_w[1]:.2f}*x2 + {normalized_b:.2f}"
margin_text = f"Margin width: {margin:.4f}"
ax.text(
0.5,
0.05,
formula,
transform=ax.transAxes,
fontsize=12,
bbox=dict(facecolor="white", alpha=0.8),
)
ax.text(
0.5,
0.1,
normalized_formula,
transform=ax.transAxes,
fontsize=12,
bbox=dict(facecolor="white", alpha=0.8),
)
ax.text(
0.5,
0.15,
margin_text,
transform=ax.transAxes,
fontsize=12,
bbox=dict(facecolor="white", alpha=0.8),
)
ax.legend(loc="upper right")
ax.grid(True, linestyle="--", alpha=0.7)
print("Weight vector (w):", w)
print("Bias (b):", b)
print("Support vector indices:", sv_indices)
print("Support vectors:\n", support_vectors)
print("Margin width:", margin)
print(f"Decision function: f(x) = {w[0]:.4f}*x1 + {w[1]:.4f}*x2 + {b:.4f}")
plt.tight_layout()
plt.savefig("imgs/svm_plot.png", dpi=300, bbox_inches="tight")
# plt.show()
习题 7.3
线性支持向量机还可以定义为以下形式:
试求其对偶形式。
构建拉格朗日函数:
首先求 \(L(w,b,\xi,\alpha,\mu)\) 对 \(w,b,\xi\) 的极小,由
代入拉格朗日函数得:
对上述拉格朗日函数求 \(\alpha, \mu\) 的极大,再将对目标函数求极大转换为求极小 , 于是得到对偶问题:
习题 7.4
证明内积的正整数幕函数:\(K(x,z)=(x\bullet z)^p\) 是正定核函数,这里 p 是正整数,\(x,z \in \mathbf{R}^{n}\) 。
根据书中第 7 章的定理 7.5(正定核的充要条件
- 当 p=1 时,则应该有:
表明 p = 1 时,K(x, z) 对应的 Gram 矩阵 \(K_{G}\) 是半正定的。
- 假设当 p=t (t>1) 时 \(K_{G}\) 是半正定的。
- 考虑 p = t+1 的情况,记 \(\mathbf{d}=(d_{1},d_{2},\cdots,d_{n})^{T},d_{i}=\sum_{i}^{n}c_{i}x_{i}\),有
所以 p = t+1 时 \(K_{G}\) 也是半正定的。
- 由数学归纳法知, K(x, z) 对应的 Gram 矩阵 \(K = [K(x_i , x_j )]_{n×n}\) 是半正定的。
根据书中第 7 章的定理 7.5(正定核的充要条件