9 Expect Max
EM(Expectation-Maximization,期望最大化)算法是一种在机器学习中应用广泛的迭代算法。它主要用于解决含有隐变量(latent variable)的概率模型的参数估计问题。当模型中存在无法直接观测到的变量时,我们无法像往常一样直接使用极大似然估计法(MLE)或极大后验概率估计法(MAP
EM 算法的引入 (page 2) ¶
核心问题
概率模型中,变量可以分为两种:
- 观测变量 (Observable Variable):可以直接观测和获取到的数据。
- 隐变量 (Latent Variable):无法直接观测到的数据,但深刻影响着观测数据的分布。
当一个模型只包含观测变量时,我们可以直接使用极大似然估计法1 或贝叶斯估计法2 来求解模型参数。
然而,当模型中包含隐变量时,直接求解变得非常困难。EM 算法正是为了解决这类问题而设计的,它是一种求解含有隐变量的概率模型参数的极大似然估计或极大后验概率估计的有效方法。
EM 算法 (page 3) ¶
什么是 EM 算法?
- 名称:期望最大化算法 (Expectation Maximization algorithm, EM)
- 历史:由 Dempster 等人在 1977 年提出,是机器学习领域的经典算法之一。
- 用途:用于含有隐变量的概率模型的参数估计。
- 核心思想:通过迭代的方式,交替执行以下两步,直至收敛。
- E 步 (Expectation):基于当前参数,计算对数似然函数关于隐变量的期望。
- M 步 (Maximization):最大化这个期望,以更新模型参数。
EM 算法的导出 (page 4-10) ¶
为了理解 EM 算法为何有效,我们需要深入其数学推导过程。这个过程巧妙地利用了 Jensen 不等式来寻找对数似然函数的一个下界,并通过最大化这个下界来逐步提升对数似然函数的值。
目标与困难 (page 4-5) ¶
假设我们有观测数据 \(Y\) 和隐变量数据 \(Z\)。\(Y\) 和 \(Z\) 一起构成了完全数据 (complete-data)。然而在现实中,我们通常只能得到 \(Y\),即不完全数据 (incomplete-data)。
我们的目标是极大化观测数据 \(Y\) 的对数似然函数 \(L(\theta)\):
这里,\(P(Y,Z|\theta)\) 是完全数据的联合概率分布,可以通过 \(P(Y,Z|\theta) = P(Y|Z,\theta)P(Z|\theta)\) 计算。
主要困难
直接对 \(L(\theta)\) 求导并令其为零来求解参数 \(\theta\) 是非常困难的。其根本原因在于对数函数内部包含了一个求和(或积分),即 log(Σ(...)) 的形式。这种结构使得求导变得异常复杂。
构造下界 (page 6-8) ¶
EM 算法不直接最大化 \(L(\theta)\),而是通过最大化它的一个下界 (lower bound) 来间接实现。假设在第 \(i\) 次迭代后,我们得到的参数估计是 \(\theta^{(i)}\)。我们希望找到一个新的参数 \(\theta\),使得 \(L(\theta) > L(\theta^{(i)})\)。
考虑二者之差 \(L(\theta) - L(\theta^{(i)})\):
这里我们引入一个关于隐变量 \(Z\) 的分布 \(P(Z|Y, \theta^{(i)})\),并利用Jensen 不等式3 进行放缩:
整理上式,我们可以得到 \(L(\theta)\) 的一个下界函数 \(B(\theta, \theta^{(i)})\):
我们希望通过最大化这个下界 \(B(\theta, \theta^{(i)})\) 来尽可能地增大 \(L(\theta)\)。新的参数 \(\theta^{(i+1)}\) 由下式给出:
在对 \(B(\theta, \theta^{(i)})\) 进行最大化时,可以忽略掉与 \(\theta\) 无关的常数项。这等价于最大化一个我们称之为 Q 函数 的部分。
Q 函数 (page 9) ¶
定义 9.1 (Q 函数 )
完全数据的对数似然函数 \(\log P(Y, Z|\theta)\) 关于在给定观测数据 \(Y\) 和当前参数 \(\theta^{(i)}\) 下对未观测数据 \(Z\) 的条件概率分布 \(P(Z|Y, \theta^{(i)})\) 的期望,称为 Q 函数 (Q function)。
因此,EM 算法的 M 步可以简化为:
这个形式通常比直接最大化 \(L(\theta)\) 简单得多,因为 Q 函数中对数内部不再有求和项。
直观解释 (page 10) ¶
EM 算法的迭代过程可以直观地理解为:
- 在当前的参数 \(\theta^{(i)}\) 处,我们构造了一个 \(L(\theta)\) 的下界函数 \(B(\theta, \theta^{(i)})\)(或 Q 函数
) 。这个下界函数在点 \(\theta = \theta^{(i)}\) 处与 \(L(\theta)\) 相切,即 \(L(\theta^{(i)}) = B(\theta^{(i)}, \theta^{(i)})\)。 - 我们寻找一个新的参数 \(\theta^{(i+1)}\) 来最大化这个下界函数。
- 由于 \(L(\theta) \ge B(\theta, \theta^{(i)})\),并且我们选择了 \(\theta^{(i+1)}\) 使得 \(B(\theta^{(i+1)}, \theta^{(i)}) \ge B(\theta^{(i)}, \theta^{(i)})\),因此可以保证 \(L(\theta^{(i+1)}) \ge L(\theta^{(i)})\)。
这个过程确保了每次迭代都会使观测数据的对数似然值单调不减。
Note
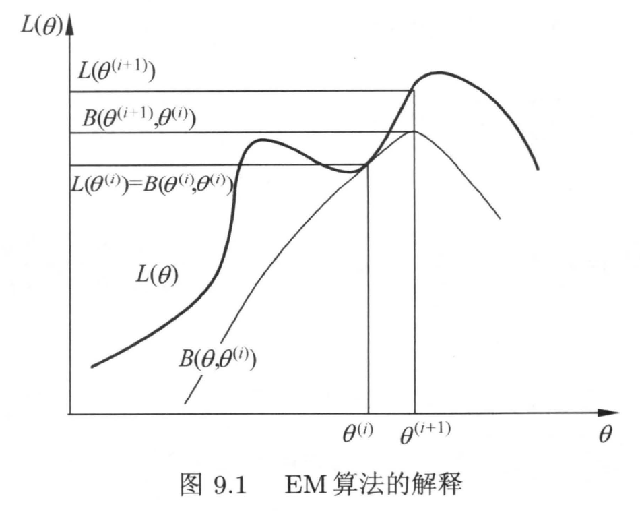
从上图可以看出,EM 算法保证了似然函数值的单调增加,但不能保证找到全局最优解。算法的最终结果依赖于初始值的选择,可能会收敛到局部最优值。
EM 算法流程 (page 11-12) ¶
现在,我们可以总结出 EM 算法的完整流程。
算法 9.1 (EM 算法 )
输入:观测变量数据 \(Y\),隐变量数据 \(Z\),联合分布 \(P(Y, Z|\theta)\),条件分布 \(P(Z|Y, \theta)\)。
输出:模型参数 \(\theta\)。
- 初始化:选择参数的初值 \(\theta^{(0)}\)。
- E 步 (Expectation):在第 \(i+1\) 次迭代中,根据当前参数 \(\theta^{(i)}\) 计算 Q 函数: $$ Q(\theta, \theta^{(i)}) = E_{Z|Y, \theta^{(i)}}[\log P(Y, Z|\theta)] = \sum_{Z} P(Z|Y, \theta^{(i)}) \log P(Y, Z|\theta) $$
- M 步 (Maximization):最大化 Q 函数,得到新的参数估计值 \(\theta^{(i+1)}\): $$ \theta^{(i+1)} = \arg\max_{\theta} Q(\theta, \theta^{(i)}) $$
- 重复:重复第 (2) 步和第 (3) 步,直到收敛。
EM 算法的几点说明 (page 12)
- 初值敏感性:EM 算法对参数的初始值 \(\theta^{(0)}\) 非常敏感。不同的初始值可能导致算法收敛到不同的局部最优解。
- Q 函数:在 E 步计算的 \(Q(\theta, \theta^{(i)})\) 中,第一个变元 \(\theta\) 是需要优化的变量,而第二个变元 \(\theta^{(i)}\) 是上一步迭代得到的固定值。
- 收敛条件:迭代停止的条件通常是参数变化量很小或 Q 函数值变化量很小,例如: $$ ||\theta^{(i+1)} - \theta^{(i)}|| < \epsilon_1 \quad \text{或} \quad ||Q(\theta^{(i+1)}, \theta^{(i)}) - Q(\theta^{(i)}, \theta^{(i)})|| < \epsilon_2 $$
EM 算法的收敛性 (page 13-17) ¶
EM 算法具有良好的收敛性质,但理解其收敛的含义至关重要。
定理 9.1 ( 似然函数单调性 )
设 \(P(Y|\theta)\) 为观测数据的似然函数,\(\{\theta^{(i)}\}\) 为 EM 算法得到的参数估计序列。那么对应的似然函数序列 \(\{P(Y|\theta^{(i)})\}\) 是单调递增的,即:
证明概要:
证明的关键在于将对数似然函数分解为 \(Q\) 函数和另一个函数 \(H\):
其中 \(H(\theta, \theta^{(i)}) = \sum_Z P(Z|Y, \theta^{(i)}) \log P(Z|Y, \theta)\)。
- 根据 M 步的定义,\(Q(\theta^{(i+1)}, \theta^{(i)}) \ge Q(\theta^{(i)}, \theta^{(i)})\)。
- 可以证明 ( 利用 Jensen 不等式 ),\(H(\theta^{(i+1)}, \theta^{(i)}) \le H(\theta^{(i)}, \theta^{(i)})\)。
综合这两点,可以证明 \(\log P(Y|\theta^{(i+1)}) - \log P(Y|\theta^{(i)}) \ge 0\)。
定理 9.2 ( 收敛性 )
- \(P(Y|\theta)\) 有上界(作为一个概率
) ,则对数似然函数序列 \(L(\theta^{(i)}) = \log P(Y|\theta^{(i)})\) 收敛到某一值 \(L^*\)。 - 在一定条件下,EM 算法得到的参数估计序列 \(\theta^{(i)}\) 的收敛值 \(\theta^*\) 是 \(L(\theta)\) 的稳定点(通常是局部极大值点
) 。
核心要点:
- 定理保证似然函数值会收敛,但不保证参数本身会收敛到一个特定值。
- 即使参数收敛,也只能保证收敛到稳定点,而不能保证是全局最大值点。
- 实践建议:由于对初值敏感且可能陷入局部最优,常用的方法是选取多个不同的初值进行迭代,然后从得到的结果中选择似然函数值最大的那个作为最终解。
EM 算法在高斯混合模型学习中的应用 (page 18-26) ¶
高斯混合模型(Gaussian Mixture Model, GMM)是 EM 算法的一个经典应用场景。
高斯混合模型 (GMM)
GMM 认为数据是由 \(K\) 个不同的高斯分布(也称为“分模型”)混合而成的。其概率密度函数为:
其中: * \(\alpha_k\) 是第 \(k\) 个分模型的混合系数,满足 \(\alpha_k \ge 0\) 且 \(\sum_{k=1}^{K} \alpha_k = 1\)。 * \(\phi(y|\theta_k)\) 是第 \(k\) 个高斯分模型的概率密度函数,其参数为 \(\theta_k = (\mu_k, \sigma_k^2)\)。 $$ \phi(y|\theta_k) = \frac{1}{\sqrt{2\pi}\sigma_k} \exp\left(-\frac{(y-\mu_k)^2}{2\sigma_k^2}\right) $$ * 整个模型的参数为 \(\theta = (\alpha_1, \dots, \alpha_K; \theta_1, \dots, \theta_K)\)。
直接对 GMM 的似然函数求极大值非常困难,因为对数里面有求和项。这正是 EM 算法的用武之地。
使用 EM 算法估计 GMM 参数
1. 定义隐变量 (page 19)
我们引入一个隐变量 \(\gamma_{jk}\),它是一个 0-1 变量:
有了这个隐变量,我们就知道了每个数据点“属于”哪个高斯分布,数据就变成了“完全数据” \((y_j, \gamma_{j1}, \dots, \gamma_{jK})\)。
2. 完全数据的对数似然函数 (page 20-21)
完全数据的对数似然函数为:
其中 \(n_k = \sum_{j=1}^N \gamma_{jk}\) 是属于第 \(k\) 个分模型的数据点总数。这个形式中,对数内部没有了求和,求导会方便很多。
3. E 步:计算 Q 函数 (page 22-24)
E 步的目标是计算 $$ \begin{align} Q(\theta, \theta^{(i)}) &= E[\log P(y, \gamma|\theta) | y, \theta^{(i)}] \ &=\sum_{k=1}^K\left{\sum_{j=1}^N\left(E\gamma_{jk}\right)\log\alpha_k+\sum_{j=1}^N\left(E\gamma_{jk}\right)\left[\log\left(\frac{1}{\sqrt{2\pi}}\right)-\log\sigma_k-\frac{1}{2\sigma_k^2}\left(y_j-\mu_k\right)^2\right]\right} \end{align} $$ 这需要计算隐变量 \(\gamma_{jk}\) 的期望,记为 \(\hat{\gamma}_{jk}\):
这个值表示在当前模型参数下,观测数据 \(y_j\) 由第 \(k\) 个分模型生成的概率,也称为分模型 \(k\) 对观测数据 \(y_j\) 的响应度 (responsibility)。
将 \(\hat{\gamma}_{jk}\) 代入完全数据的对数似然函数,就得到了 Q 函数。
4. M 步:最大化 Q 函数 (page 25)
M 步的目标是最大化 Q 函数,求解新的参数 \(\theta^{(i+1)} = (\hat{\alpha}_k, \hat{\mu}_k, \hat{\sigma}_k^2)\)。将 Q 函数分别对 \(\mu_k, \sigma_k^2\) 求偏导并令其为 0,并在约束 \(\sum \alpha_k=1\) 下对 \(\alpha_k\) 求偏导,可以得到更新公式:
5. 算法总结 (page 26)
输入:观测数据 \(y_1, \dots, y_N\),高斯混合模型。
输出:GMM 参数 \(\theta\)。
- 初始化:随机初始化参数 \(\alpha_k, \mu_k, \sigma_k^2\)。
- E 步:根据当前参数,计算每个分模型对每个数据点的响应度 \(\hat{\gamma}_{jk}\)。
- M 步:利用 E 步计算出的响应度,更新模型参数 \(\hat{\alpha}_k, \hat{\mu}_k, \hat{\sigma}_k^2\)。
- 重复:重复 E 步和 M 步,直到参数收敛。
EM 算法 - 例子 (page 27-30) ¶
抛硬币问题
场景:我们有两枚硬币 A 和 B,它们各自出现正面的概率 \(\theta_A\) 和 \(\theta_B\) 是未知的。实验过程是:随机选一枚硬币(A 或 B
目标:估计 \(\theta_A\) 和 \(\theta_B\)。
情况 1:无隐变量(知道每次选的是哪枚硬币) (page 27)
如果我们每次都知道选择的是硬币 A 还是 B,那么问题就变得简单了。我们可以直接将属于 A 的抛掷结果和属于 B 的抛掷结果分开,然后用极大似然估计法(即计算频率)来估计各自的概率。
- 硬币 A:总共抛了 3 组,共 30 次,其中正面 24 次,反面 6 次。 $$ \hat{\theta}_A = \frac{24}{24+6} = 0.80 $$
- 硬币 B:总共抛了 2 组,共 20 次,其中正面 9 次,反面 11 次。 $$ \hat{\theta}_B = \frac{9}{9+11} = 0.45 $$
情况 2:有隐变量(不知道每次选的是哪枚硬币) (page 28-30)
现在,我们不知道每次实验用的是 A 还是 B,这个“硬币的选择”就是隐变量。我们只观测到了 5 组独立的抛 10 次的结果。这时就需要 EM 算法。
EM 算法迭代过程:
1. 初始化:
随机猜测一组初始参数,比如 \(\theta_A^{(0)} = 0.60, \theta_B^{(0)} = 0.50\)。
2. E 步 (Expectation):
对于每一组观测(比如第二组“9 正 1 反”
对于“k 个正面,10-k 个反面”的观测: * 来自A的可能性(非归一化): \(L_A = (\theta_A^{(0)})^k (1-\theta_A^{(0)})^{10-k}\) * 来自B的可能性(非归一化): \(L_B = (\theta_B^{(0)})^k (1-\theta_B^{(0)})^{10-k}\)
以第二组“9 正 1 反”为例: * \(L_A = (0.6)^9(0.4)^1 \approx 0.004\) * \(L_B = (0.5)^9(0.5)^1 \approx 0.001\)
归一化后,这组数据来自 A 的概率(响应度)为 \(0.004 / (0.004+0.001) = 0.8\),来自 B 的概率为 \(0.2\)。
这意味着,我们把这组观测的“9 正 1 反”按比例分配给硬币 A 和 B: * 归属A的期望次数:\(0.8 \times 9 = 7.2\) 个正面, \(0.8 \times 1 = 0.8\) 个反面。 * 归属B的期望次数:\(0.2 \times 9 = 1.8\) 个正面, \(0.2 \times 1 = 0.2\) 个反面。
对所有 5 组数据都进行这样的计算,然后将归属于 A 和 B 的期望正反面次数分别相加。从图中可以看到,所有数据加权后,硬币 A 的总期望是 21.3 个正面和 8.6 个反面,硬币 B 是 11.7 个正面和 8.4 个反面。
3. M 步 (Maximization):
基于 E 步得到的期望(加权)计数,重新计算参数:
4. 重复:
用新的参数 \((\theta_A^{(1)}, \theta_B^{(1)})\) 重复 E 步和 M 步,直到参数收敛。如图所示,经过若干次迭代,参数最终会收敛到 \(\theta_A \approx 0.80\) 和 \(\theta_B \approx 0.52\) 附近。
这个例子生动地展示了 EM 算法的核心思想:通过“软分配”(计算响应度)来处理不确定性,然后基于这种软分配的结果来更新参数,循环往复,直至收敛。
习题 ¶
习题 9.1
如例 9.1 的三硬币模型,假设观测数据不变,试选择不同的初值,例如,\(π^{(0)}=0.46,p^{(0)}=0.55,q^{(0)}=0.67\),求模型参数为 \(θ=(π,p,q)\) 的极大似然估计。
- (1) 初始值 : \(\theta^{(0)}=(\pi^{(0)},p^{(0)},q^{(0)})\);
- (2) E 步 : 第二次抛出 B 硬币概率:
- (3) M 步 : 计算模型参数的新估计值
- (4) 停止条件 : 需要设定迭代停止的条件。常用的条件是:
- 参数变化足够小 : \(|| θ^{(i+1)} - θ^{(i)} || < ε_{1}\)
- Q 函数(或对数似然函数 L(θ))增量足够小 : \(|| L(θ^{(i+1)}) - L(θ^{(i)}) || < ε_{2}\) ( 或使用 Q 函数的变化 ) 其中 ε1, ε2 是预设的很小的正数。
使用 python 进行迭代有:
import numpy as np
import matplotlib.pyplot as plt
observations = np.array([1, 1, 0, 1, 0, 0, 1, 0, 1, 1])
n = len(observations)
# Initial parameters
pi_0 = 0.46
p_0 = 0.55
q_0 = 0.67
# EM algorithm implementation
def em_algorithm(observations, pi_0, p_0, q_0, max_iterations=100, tol=1e-6):
pi = pi_0
p = p_0
q = q_0
n = len(observations)
history = []
for iteration in range(max_iterations):
history.append((pi, p, q))
# E-step: Calculate posterior probability that each observation comes from coin A
mu = np.zeros(n)
for j in range(n):
y_j = observations[j]
numerator = pi * (p**y_j) * ((1 - p) ** (1 - y_j))
denominator = pi * (p**y_j) * ((1 - p) ** (1 - y_j)) + (1 - pi) * (
q**y_j
) * ((1 - q) ** (1 - y_j))
mu[j] = numerator / denominator
# M-step: Update parameter estimates
pi_new = np.mean(mu)
p_new = np.sum(mu * observations) / np.sum(mu)
q_new = np.sum((1 - mu) * observations) / np.sum(1 - mu)
# Check convergence
if max(abs(pi_new - pi), abs(p_new - p), abs(q_new - q)) < tol:
pi, p, q = pi_new, p_new, q_new
history.append((pi, p, q))
print(f"EM algorithm converged after {iteration+1} iterations")
break
pi, p, q = pi_new, p_new, q_new
if iteration == max_iterations - 1:
print(f"EM algorithm reached maximum iterations {max_iterations}")
return pi, p, q, history
pi_final, p_final, q_final, history = em_algorithm(observations, pi_0, p_0, q_0)
print(f"Initial parameters: π = {pi_0}, p = {p_0}, q = {q_0}")
print(f"Final estimates: π = {pi_final:.6f}, p = {p_final:.6f}, q = {q_final:.6f}")
EM algorithm converged after 2 iterations
Initial parameters: π = 0.46, p = 0.55, q = 0.67
Final estimates: π = 0.461863, p = 0.534595, q = 0.656135
可以看到当前的情况收敛很快,最终 \(\theta = (0.461863, 0.534595, 0.656135)\) 。
习题 9.2 证明引理 9.2
\(若\tilde{P}_\theta(Z)=P(Z|Y,\theta)\) 则 \(\\\\F(\tilde{P},\theta)=\log P(Y|\theta)\) 。
由定义 9.3: \(F(\tilde P,\theta)=E_{\tilde P}[\log P(Y,Z|\theta)]+H(\tilde P)\),其中 \(H(\tilde{P}) = - E_{\tilde P} \log \tilde P(Z)\);由引理 9.1 得知: \(\tilde{P}_{\theta}(Z)=P(Z|Y, \theta)\) ;故而:
-
极大似然估计 (Maximum Likelihood Estimation, MLE):一种参数估计方法,其思想是找到一组参数,使得在这组参数下,我们观测到的样本数据出现的概率(似然)最大。 ↩
-
贝叶斯估计 (Bayesian Estimation):一种参数估计方法,它将参数也看作是随机变量,并结合了参数的先验分布和数据似然,来计算参数的后验分布。通常取后验分布的期望或众数作为参数的估计值。 ↩
-
Jensen 不等式 (Jensen's Inequality):对于一个凸函数 \(f(x)\),有 \(f(E[X]) \le E[f(X)]\)。对于一个凹函数(如 \(\log(x)\)
) ,则不等号方向相反,即 \(f(E[X]) \ge E[f(X)]\)。EM 算法的推导利用了 \(\log\) 函数的凹性。 ↩