VQ
Info
Overview¶
https://inria.hal.science/inria-00514462v2/document
(Quantization) Its purpose is to reduce the cardinality of the representation space, in particular when the input data is real-valued.
https://www.pinecone.io/learn/series/faiss/product-quantization/
Quantization is a generic method that refers to the compression of data into a smaller space.
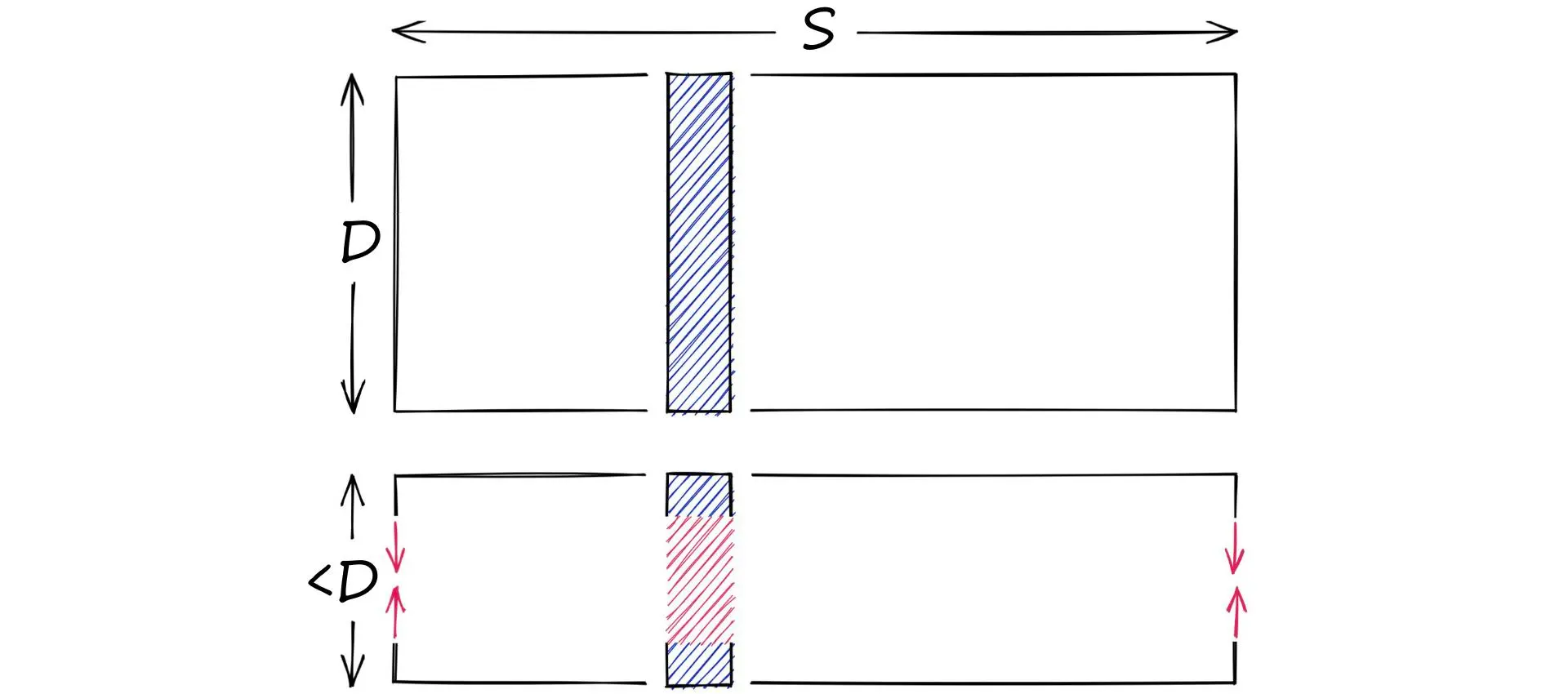
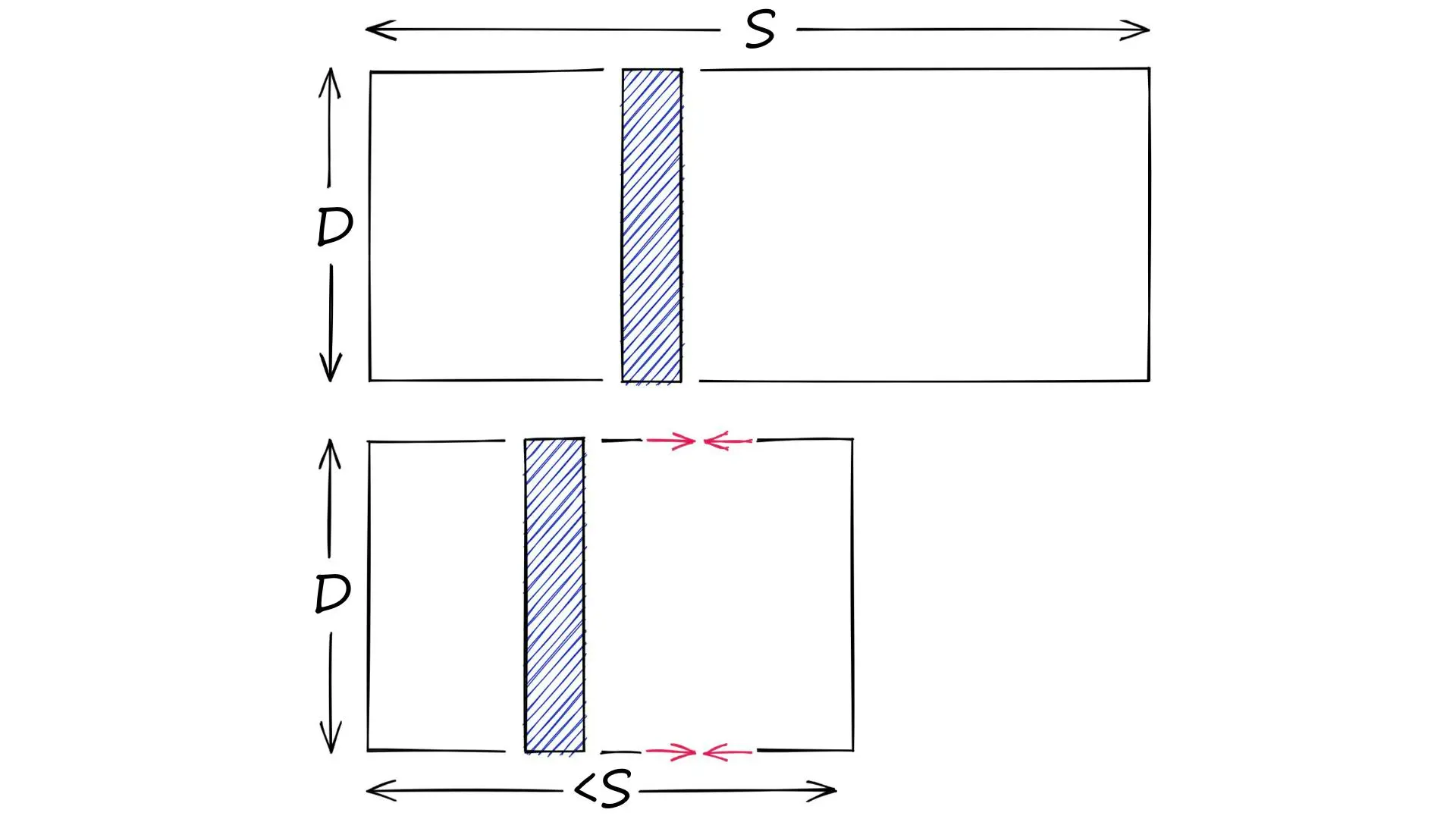
简单来说,量化是为了通过减小数据的值域来达到压缩的目的的一种技术。需要注意的是,量化和降维具有较为明显的差异:对于一个 D 维的向量,若其每个分量的可取范围为 S,那么
- 降维操作可以视为在缩小 D
- 而量化操作则视为在缩小 S
[SQ] Scalar Quantization¶
如果说有一个 128 维 32 位浮点向量,工程架构对存储和读取性能是有要求的,即不能直接将这 128 维浮点向量直接写数据库里面。
有没有一种量化方法,将一个 d 维 float 型向量,encode 为一个 d 维 int8 型的向量,这个 d 维 int8 型的向量经过 decode 后,与原始向量的误差尽可能小?
首先这种编码减少了内存开销,另外计算无符号整数肯定比计算一个 IEEE 754 单精度浮点数要快的。一个朴素的方案如下:
编码 ¶
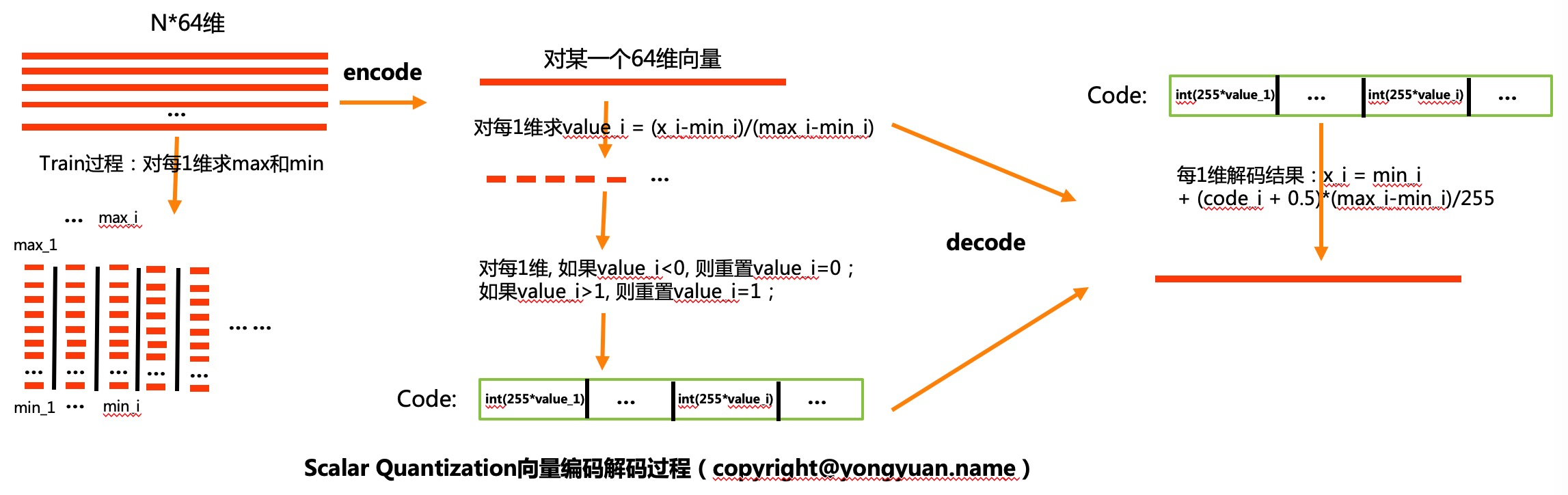
对于浮点向量 v,希望将其编码为 n bits 无符号整数向量(一般 n=8,即使用 C 语言中的 uint8 类型
具体而言,在编码时,先将向量中的每个元素线性压缩到 [0, 1] 内;对于 \(\sigma(\cdot, n)\) 操作而言,一般为乘以 \(2^n - 1\) 并丢弃结果中的小数部分(C++ 中 float 转为 int 的逻辑为向 0 取整
解码 ¶
而在解码时,总体来看就是编码方法的逆过程:
但是注意到其中有一步 \(v'+0.5\),这是因为在编码时的最后一步 float 转为 int 的一定是向下取整,平均而言会损失 0.5,故而在对 \(v'\) 的第一步处理时先加上 0.5,减少重构后的量化损失。
n=8 时对应的代码片段如下:
// https://github.com/facebookresearch/faiss/blob/8cc9a31a2f3f6eba2060f947c7791740ea42aec0/faiss/impl/ScalarQuantizer.cpp
template <class Codec>
struct QuantizerTemplate<Codec, QuantizerTemplateScaling::NON_UNIFORM, 1>
: ScalarQuantizer::SQuantizer {
void encode_vector(const float* x, uint8_t* code) const final {
for (size_t i = 0; i < d; i++) {
float xi = 0;
if (vdiff != 0) {
// 归一化到 [0, 1]
xi = (x[i] - vmin) / vdiff;
// 裁剪到 [0, 1] 处理异常
if (xi < 0) {
xi = 0;
}
if (xi > 1.0) {
xi = 1.0;
}
}
Codec::encode_component(xi, code, i);
}
}
void decode_vector(const uint8_t* code, float* x) const final {
for (size_t i = 0; i < d; i++) {
float xi = Codec::decode_component(code, i);
x[i] = vmin + xi * vdiff;
}
}
...
}
struct Codec8bit {
static FAISS_ALWAYS_INLINE void encode_component(
float x,
uint8_t* code,
int i) {
code[i] = (int)(255 * x);
}
static FAISS_ALWAYS_INLINE float decode_component(
const uint8_t* code,
int i) {
return (code[i] + 0.5f) / 255.0f;
}
...
}
对于这里的 \(\min\) 和 \(\max\),faiss 有两类思路(考虑 n 个 d 维向量构成的矩阵 \(V\in\mathbb{R}^{n\times d}\)
- QT_xbits_uniform:\(\max(V)\) 和 \(\min(V)\)
- 使用 V 中所有元素中的最大值 / 最小值,但是可能会影响量化精度
- QT_xbits:\(\{\max(k)|k\in V^T)\}\) 和 \(\{\min(k)|k\in V^T)\}\)
- 考虑对于每个向量 / 维度分别取最大值 / 最小值,提高量化精度
[VQ] Vector Quantization¶
基于 SQ 的方法普遍存在一个问题:由于量化时都是线性变换,如果初始向量分量的分布就是不均匀的(例如,高斯分布
) ,由于量化时舍去小数产生的损失,可能会导致大部分分量被量化为同一个值。换言之,在上面一节中,Scalar Quantizer 并不能完全利用好整个的编码空间。
Tips
“SQ 编码空间利用不充分的问题”可能源于 SQ 利用的是天然的“有限代表”(即 \(\{0, 1, \dots, 255\}\)
例如,压缩到区间 D 后,考虑在 D 上概率分布和累计概率分布,将 D 按照累计概率分布达到一定比例(例如 1/256)划分为一个区间,再在每个区间设法寻找出一个“代表”作为量化编码。
但是这个“寻找”方法在复杂分布的数据集上难以有较好的选择。
非均匀标量量化 ¶
后来发现一些非均匀标量量化(如 Lloyd-Max 量化)大抵就是这个思路,在密的地方细量化,在疏的地方粗量化;同时也发现均匀量化似乎不利于熵编码(如哈夫曼编码
这个“代表”的数据类型其实没有限制,因为只需要为每个“代表”分配唯一的 index;在数据传输前,双方先统一一个码本 (codebook, \(\mathcal{C}\)),码本内按照 index 映射了所有可能的“代表”(称为 codewords
Tips
VQ 的思路同样是寻找“有限锚点”;不同的是,既然锚点可以是任意数据类型,能不能就是向量?找“代表”的方法似乎都已经有现成的了,比如聚类算法。典型地,如果我们期望代表可以有 k 种选择,我们可以使用 k-means 聚类。
形式化建模 ¶
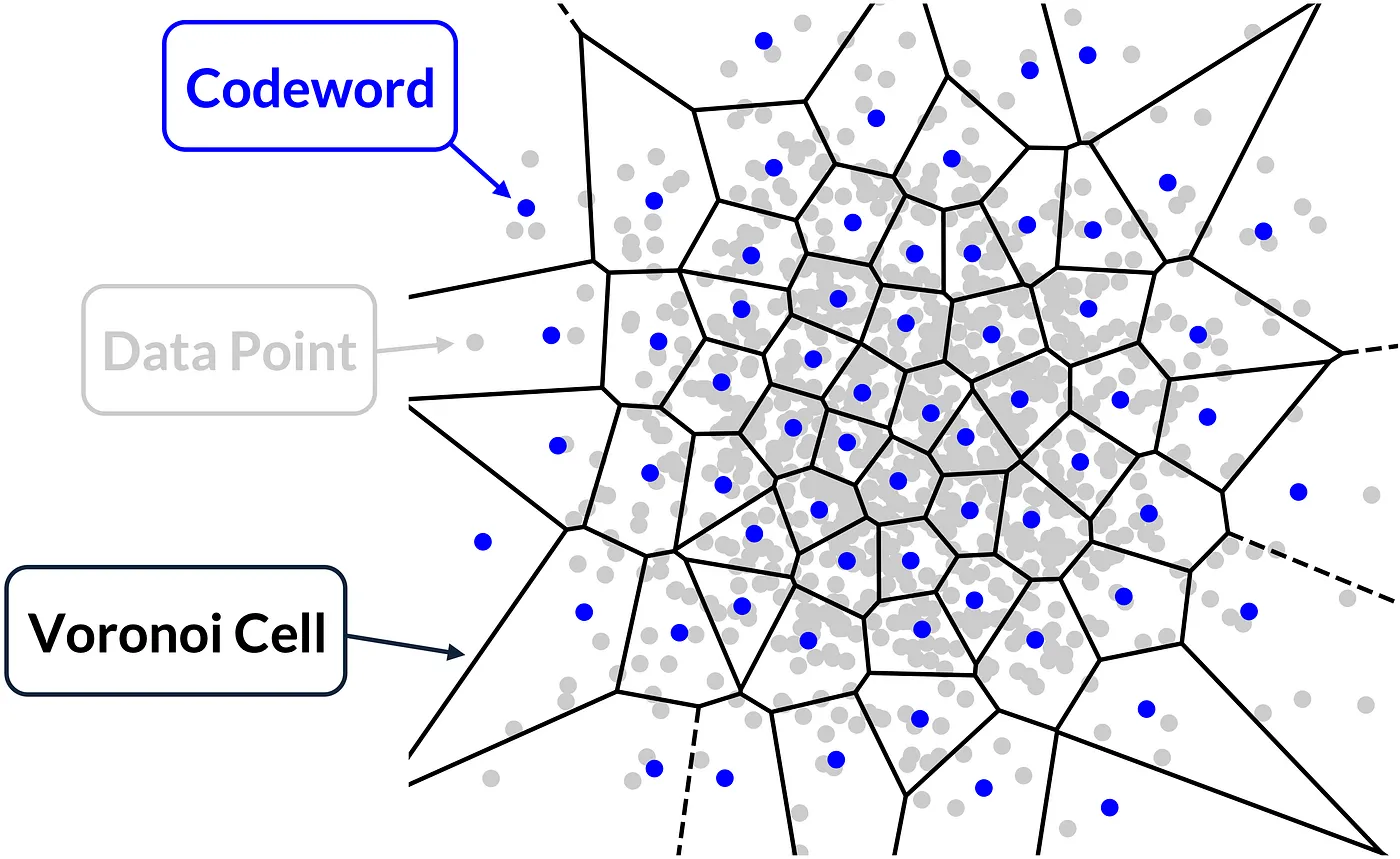
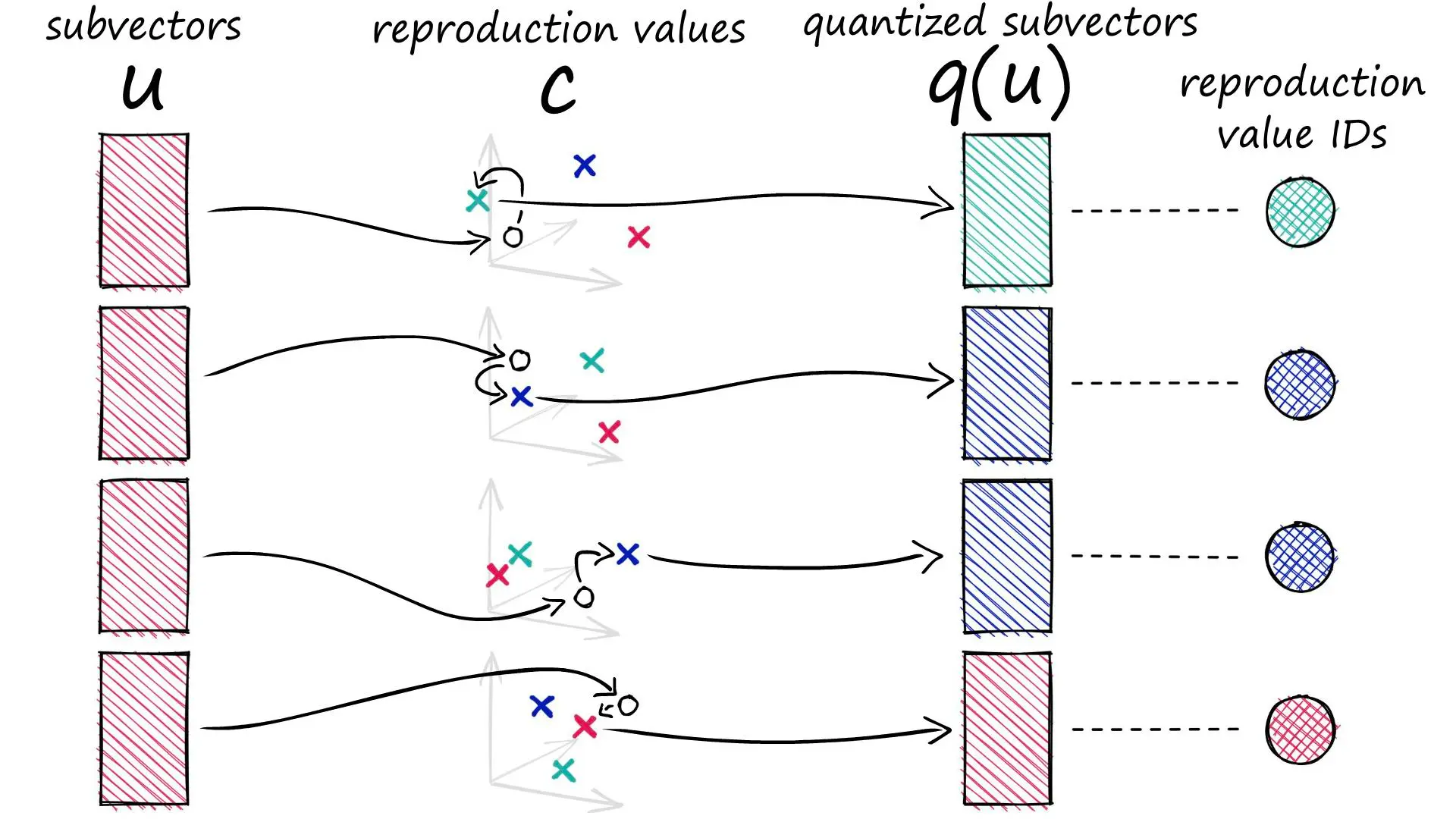
形式化地,考虑一个用于训练的向量池 E 中包含了 N 个 D 维度向量 \(x \in \mathrm{R}^{D}\),VQ 的目标是找到一个映射(如 k-means 聚类)使得:
显然这里的 x 代表了 index,\(c_x\) 代表了 codeword/code-vector,\(\mathcal{C}\) 代表了 codebook;在二维空间中如下图表示:
编码和解码 ¶
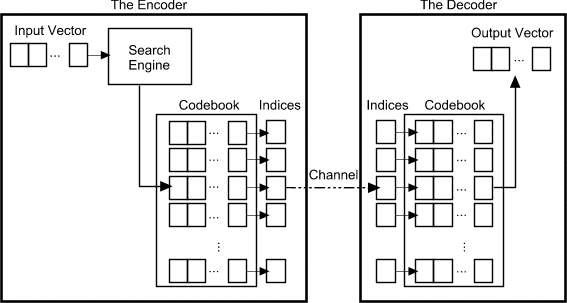
聚类算法将数据空间划分为 k 个沃罗诺伊单元 (Voronoi Cell);传输时,每个单元内的数据向量 (Data Point) 将使用该单元的码字 (codeword) 对应的索引表示,只需要传输码本和码字编码的向量即可,具体的编码和解码过程如下图所示:
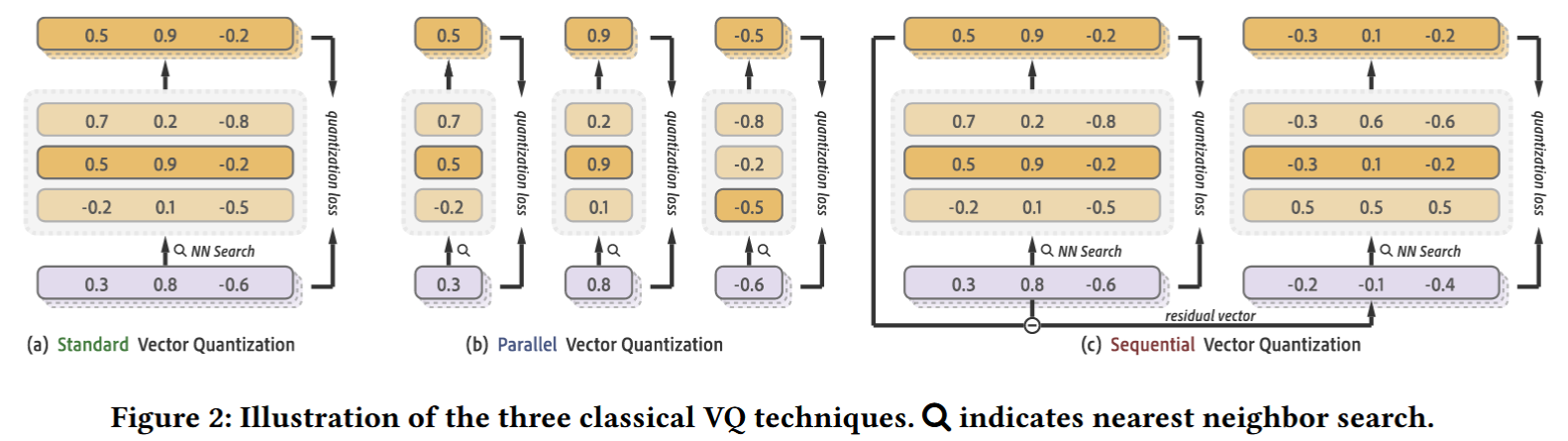
上述过程被称为 Standard VQ,只使用一个码本;后续针对 VQ 的研究提出了不同的变体,大致可以分为两类:parallel VQ 和 sequential VQ,它们都使用了多个码本,不同点在于码本之间的关系。
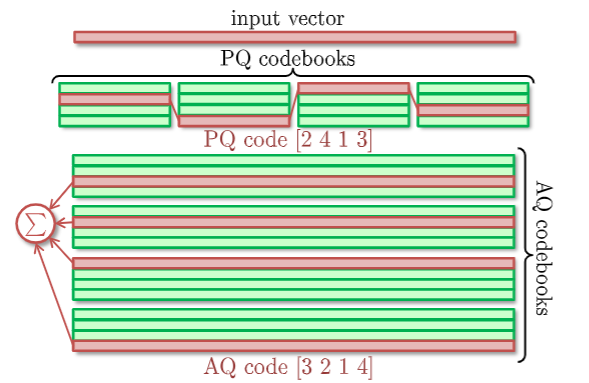
[PQ] Product Quantization¶
Info
Product Quantization 的名字顾名不思义,与我们常见的内积什么的没有什么关系,Cartesian Product(笛卡尔积)的 Product 也是 Product。
Standard PQ¶
PQ 属于 parallel VQ,基本思路是:如果将一个维度为 D 的向量 e 划分为 m 段(等长的)子向量 (sub-vector) \(u_j(e), j \in \mathrm{range}(m)\),那么 e 的欧式空间可以看作是每一段 \(u_j(e)\) 的欧式空间的笛卡尔积。
Warning
简单而言,针对集合 A、B 的笛卡尔积操作定义为:
也即是说集合 A 与 B 的笛卡尔积是 A、B 中元素能构成的所有组合的集合。
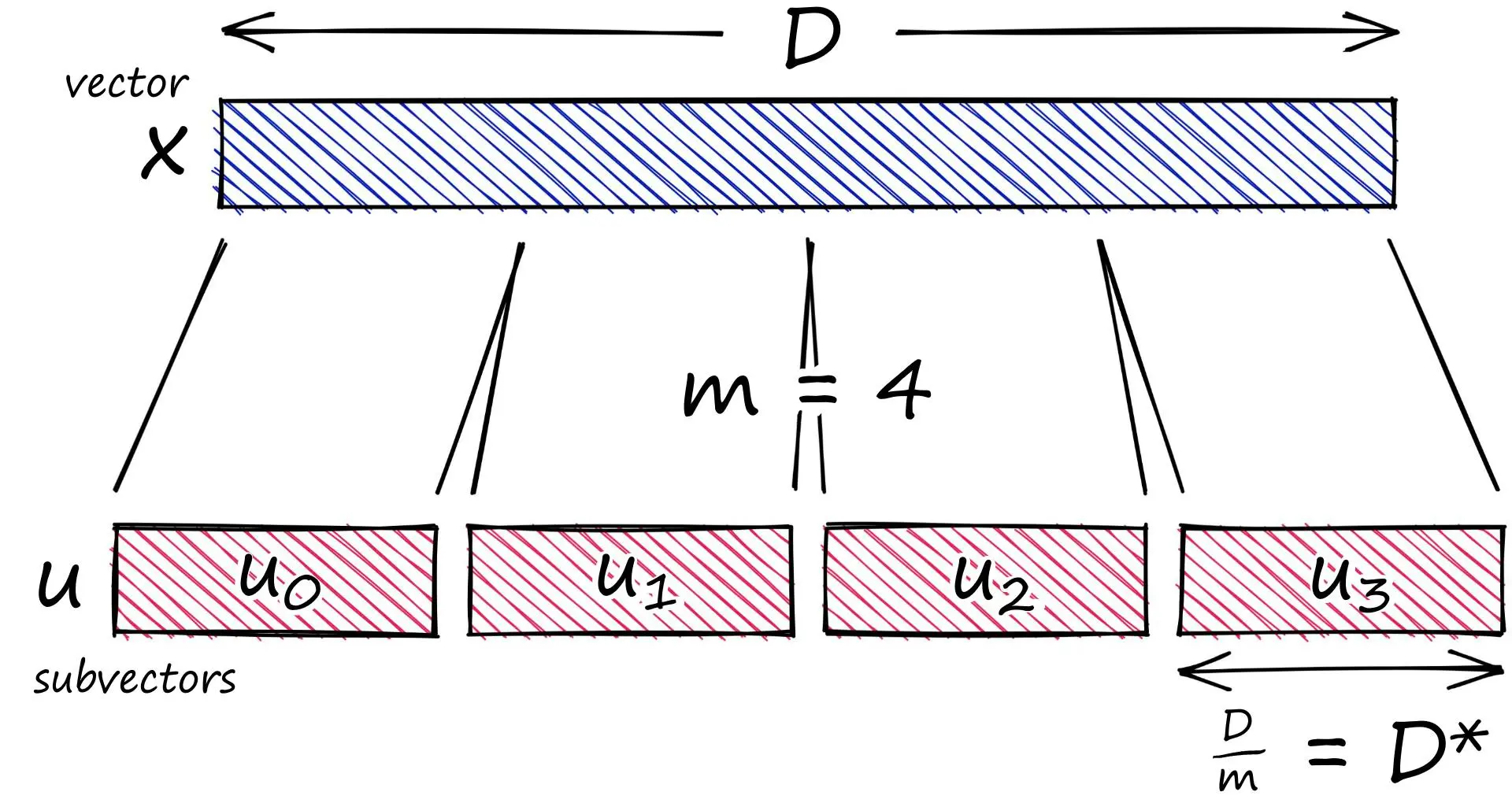
如此将向量 \(e \in \mathbb{R}^{D}\) 的量化问题变为对每段 \(u_j(e) \in \mathbb{R}^{\frac{D}{m}}\) 的量化问题,我们将 \(u_j(e)\) 作为子量化器 (subquantizer) \(q_j(\cdot)\) 的输入。框架整体如下图所示:
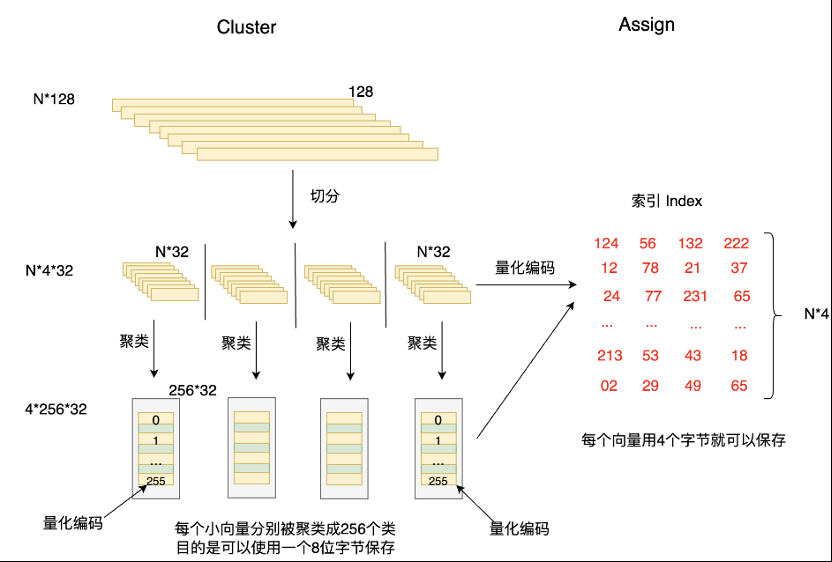
在训练 / 聚类时:
- 从一个具有 N 个 \(e \in \mathrm{R}^{D}\) 向量的向量池 \(E \in \mathrm{R}^{N \times D}\),能够获得 m 个具有 N 个子向量 \(u_j(e)\) 的子向量池 \(E_j \in \mathrm{R}^{N\times\frac{D}{m}}\) - 一般而言将会以子向量池为单位对这些子向量进行聚类(例如 k-means)
- 对于向量池中的每一个簇,我们为其分配一个中心向量 (reproduction values) \(c_j\in \mathbb{R}^{\frac{D}{m}}\) - 显然,对于一个 \(q_j(\cdot)\),共有 k 个 \(c_j\)
- 在 [0, k-1] 内对这些 \(c_j\) 进行编号并按序组合成矩阵 \(\mathcal{C}_j \in \mathbb{R}^{k\times \frac{D}{m}}\) - 如果我们认为每个子向量都可以用其所在簇的中心向量表征 - 如果我们认为每个向量可以用子向量对应中心向量拼接表征 - 那么对于每个 \(q_j(\cdot)\),我们只需要存储子码本 \(\mathcal{C}_j\) 即可
在编码 / 分配时:
- 将向量 \(e \in \mathbb{R}^{D}\) 划分为 m 段 \(u_j(e) \in \mathbb{R}^{\frac{D}{m}}\)
- 对于每一段 \(u_j(x)\),在 \(\mathcal{C}_j\) 中找到最近的中心向量 \(c_j\),找到其在 \(\mathcal{C}_j\) 中的索引 \(x_j \in \mathcal{I}_j\)
- 记 e 在 \(q_j(\cdot)\) 处的量化结果为 \(q_j(u_j(e)) := x_j\),那么整个 e 的量化编码结果为
其中 \(\prod\) 的乘法为笛卡尔积;因此 PQ 的核心实现如下图所示:
对于所有的向量 e,我们只需要存储、传输其量化编码 \(q(e)\) 和码本 \(\mathcal{C} := \prod_{j=0}^{m-1}\mathcal{C}_j\)。
在解码 / 查询时:
- 只需要按照 \(q(x)\) 的分量从对应的子码本中取出对应的中心向量,拼接后作为重构向量,这部分与 Standard VQ 部分是一致的。
Optimized PQ¶
Tips
考虑一个 \(m = D\) 的 PQ 操作,也就是说对向量 e 按照分量进行划分,每一个维度都单独考虑;这是否可以认为是让 e 的每一个分量分别代表物品的一个“特征”?如果缩小 m,让一段分量(即 \(u_j(e)\),而不是一个标量)代表物品的一个“特征”应当是一样的。类似于主成分分析 (PCA),我们能否让“特征”之间尽可能不相关(正交)来提高整体的表征性能?
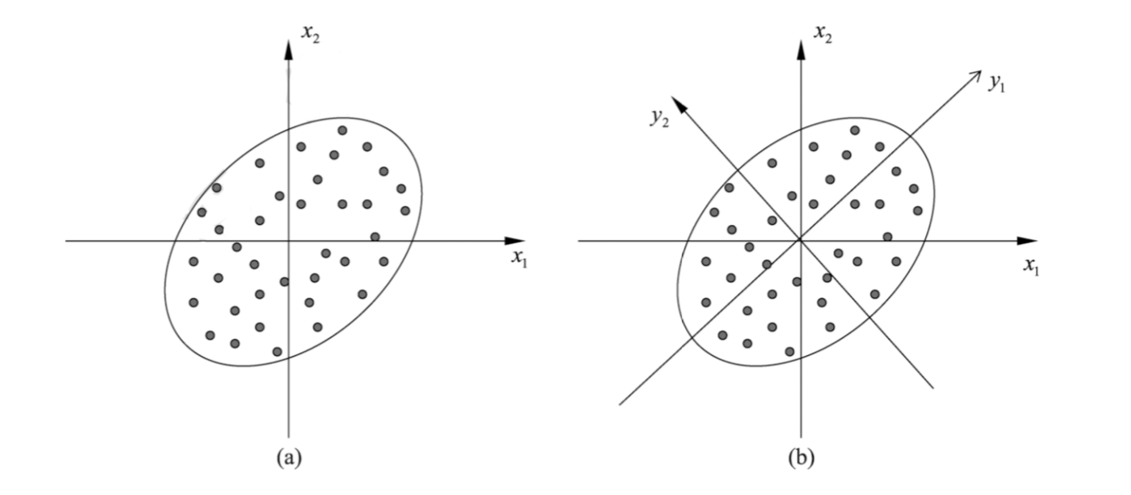
Optimized PQ (OPQ) 对 PQ 的主要改进在于对输入进行了一次线性变换:
其中 R 是一个正交矩阵 (orthonormal matrix),我们知道这相当于在物品嵌入空间中对坐标轴进行了旋转;所以有些论文中也称其为旋转矩阵 (rotation matrix)。OPQ 将 \(E'\) 作为原本 PQ 的输入,期望通过 R 来调整嵌入空间的坐标,也就是在解耦切分后子空间,"relax the constraints on the codewords"。因此 OPQ 将 R 也加入了需要学习的参数,目标可以表示为如下优化问题:
其中需要注意的是让 \(e\approx c\) 等同于 \(Re \approx Rc\);也就是意味着码本中的码字能够表示变换后的 \(e':= Re\);对于解码后重构的向量 \(\hat{e'}\),需要施加逆变换(对于正交矩阵等同于转置矩阵)即可得到重构向量 \(\hat{e}:=R^T \hat{e'} \approx e\)。
[RQ] Residual Quantization¶
Standard RQ¶
RQ 属于 sequencial VQ,同样使用了多个码本;RQ 的作者认为前面的量化方法针对每个维度至多只进行了一次量化,重构损失为 \(r = e - \hat{e}\);RQ 将这部分的损失记作“残差”;如果将这部分的残差再进行量化并一同传输,一定能够让重构损失减小,依次类推多层,得到了 RQ。
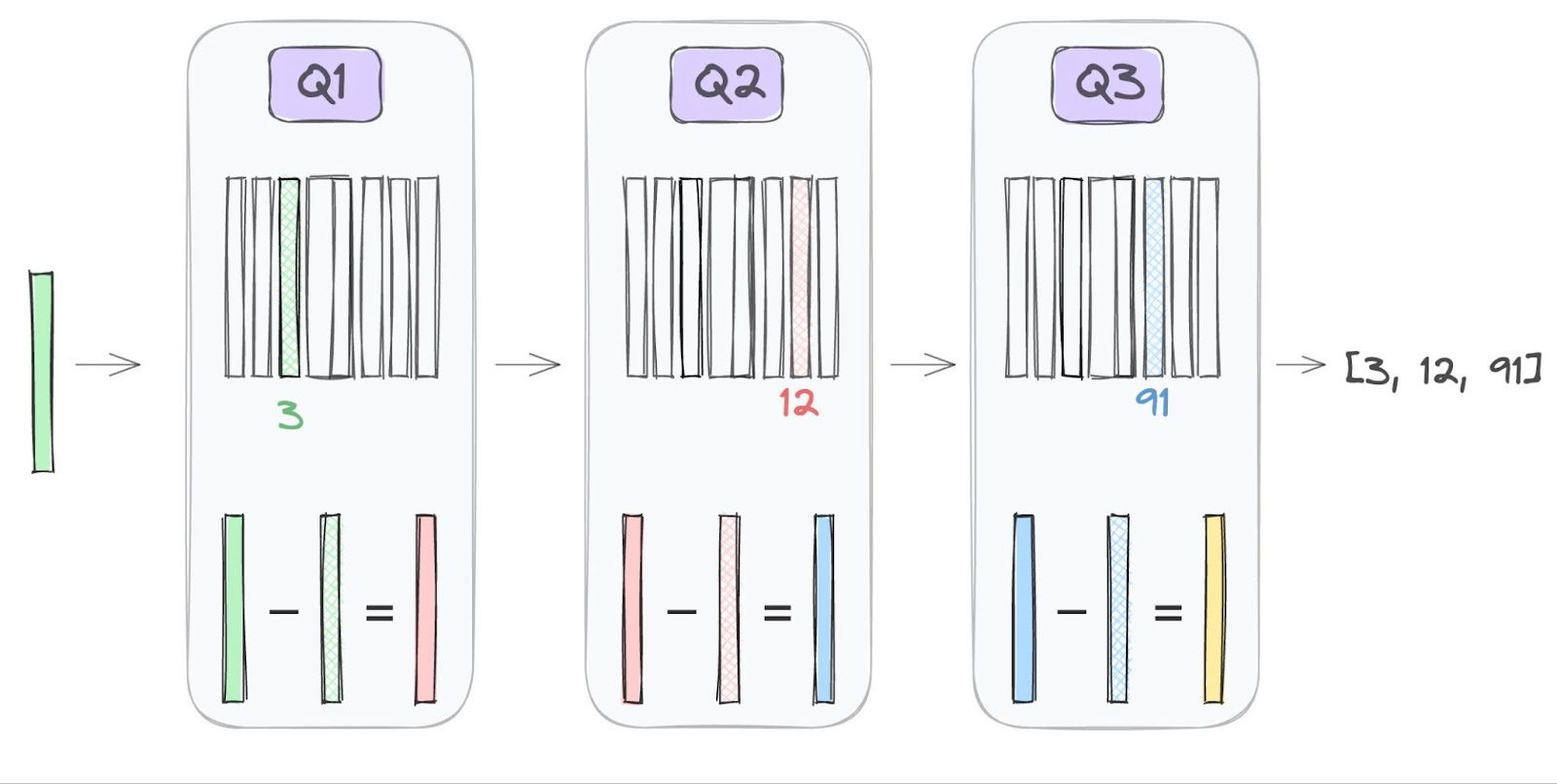
符号表示和流程与 VQ 基本一致,不再赘述;RQ 的过程可以表示为
- \(r_0 = e\)
- \(c_j = \mathrm{VQ}(r_{j-1}), r_j = r_{j-1} - c_j, \text{ where } j \in \{1, 2, \dots, m\}\)
- \(\hat{e} = \sum_{j=1}^{m}c_j\)
Additive Quantization¶
AQ 基于 RQ 进行了改进,其认为既然是序列量化,而当前 RQ 在每次量化时使用 ANN 选择最近的向量,正好类比于“贪婪搜索 (Greedy Search)”;对应的,还有一个“束搜索 (Beam Search)”,更加有利于避免局部最优导致的全局非最优。
AQ 的核心思想是用 m 个全维向量的和来近似原始向量,且这 m 个向量是联合优化的,而非像 RQ 那样顺序贪婪优化,也不像 PQ 那样受限于子空间。