appendix AE2RQVAE
我不是做计算机视觉的,了解 RQ-VAE 更多是为了学习生成式推荐。
自编码器和变分自编码器 ¶
Quote
- 理解变分自编码器(关于数学推导部分这里省略)
自编码器 (Auto-Encoder, AE) ¶
介绍 AE 之前,我们首先简要回顾一些与降维有关的概念:在机器学习中,降维是减少描述数据的特征数量的过程。可以通过选择(仅保留一些现有特征)或通过提取(基于旧特征组合来生成数量更少的新特征)来进行降维。
我们称编码器为从“旧特征”表示中产生“新特征”表示(通过选择或提取)的过程,然后将其逆过程称为解码。降维可以被理解为数据压缩,其中编码器压缩数据(从初始空间到编码空间,也称为隐空间,latent space
压缩 - 恢复的模式是有意义的,例如在信息传输时只传输 encoded data 以提高效率,图像除去噪声等。
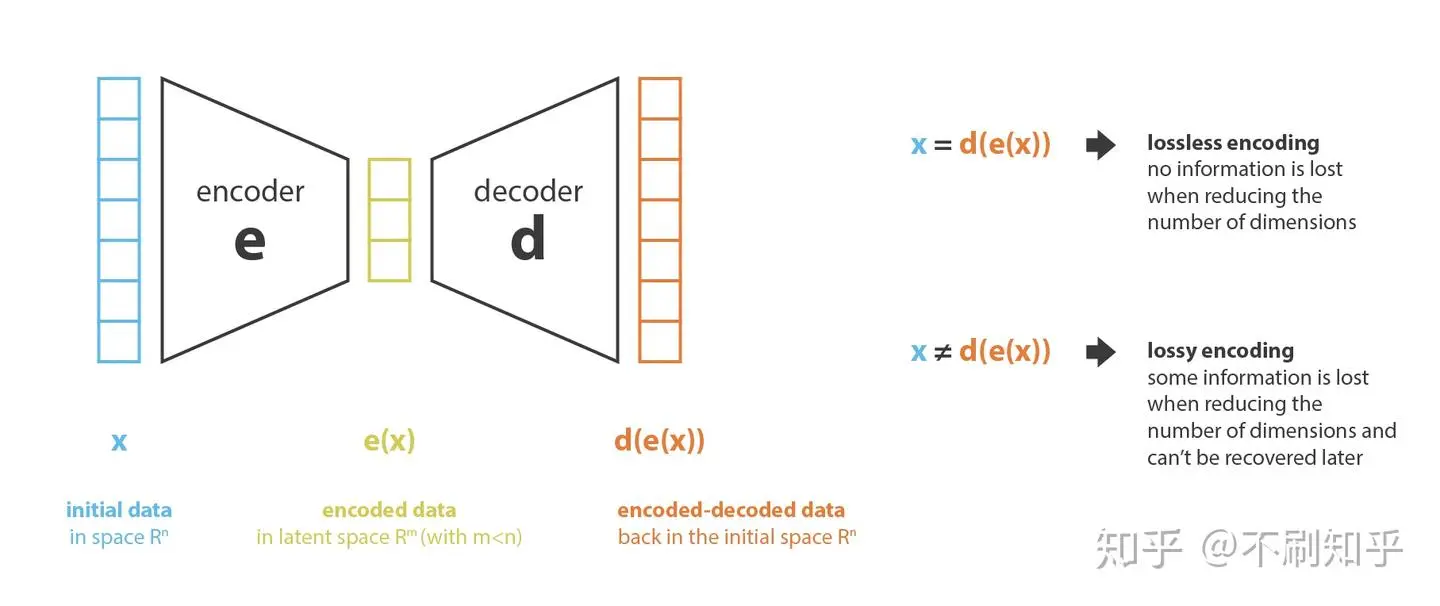
考虑 \(E, D\) 是所有候选编码器和解码器的集合,降维问题可以表征为:
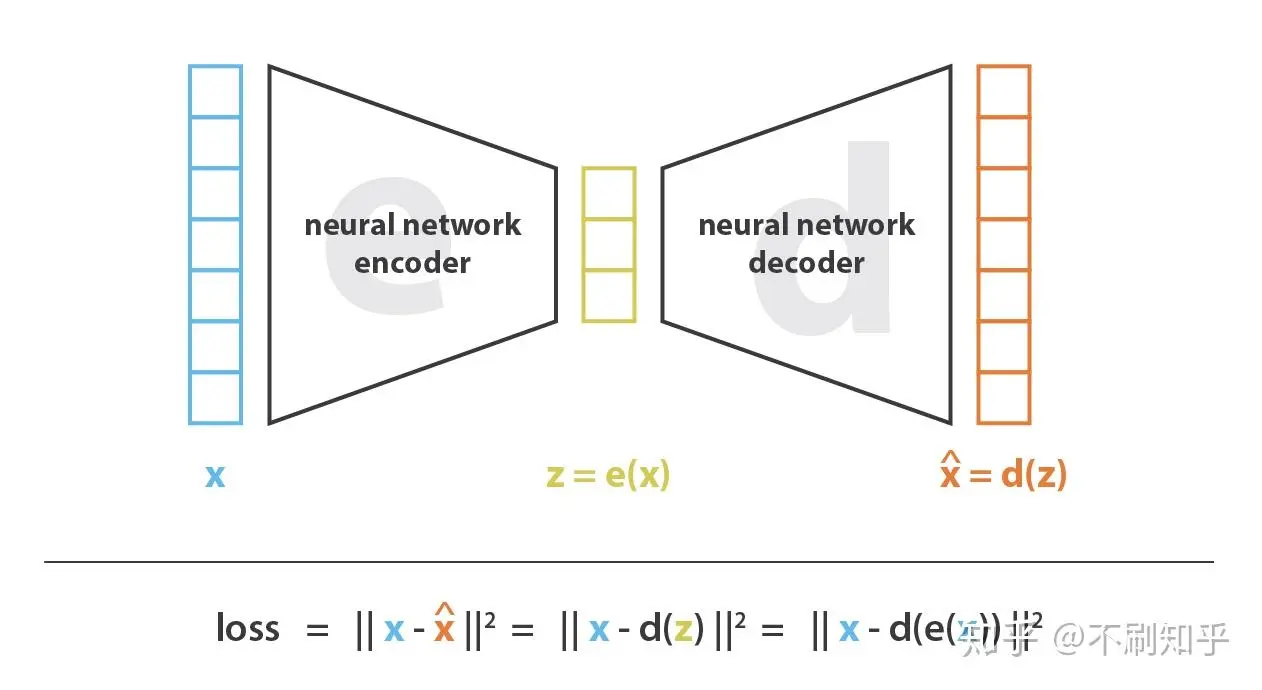
AE 简单来说就是用神经网络作为编码器和解码器,并使用迭代优化等方式学习最佳的模型的方案,损失函数一般使用均方 MSE,得到重构损失 (reconstruct loss):
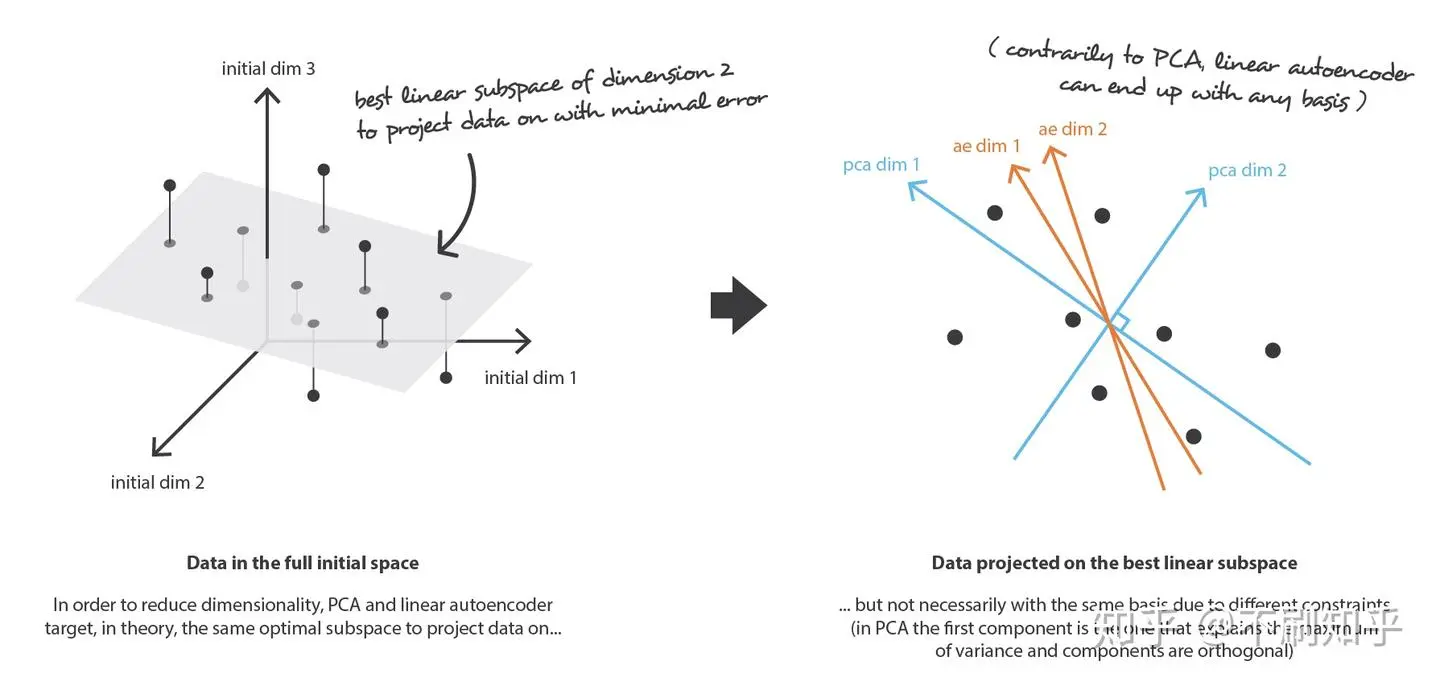
在 PCA 中, we 一般使用 SVD 等方法将特征提取并分解(特征是独立的
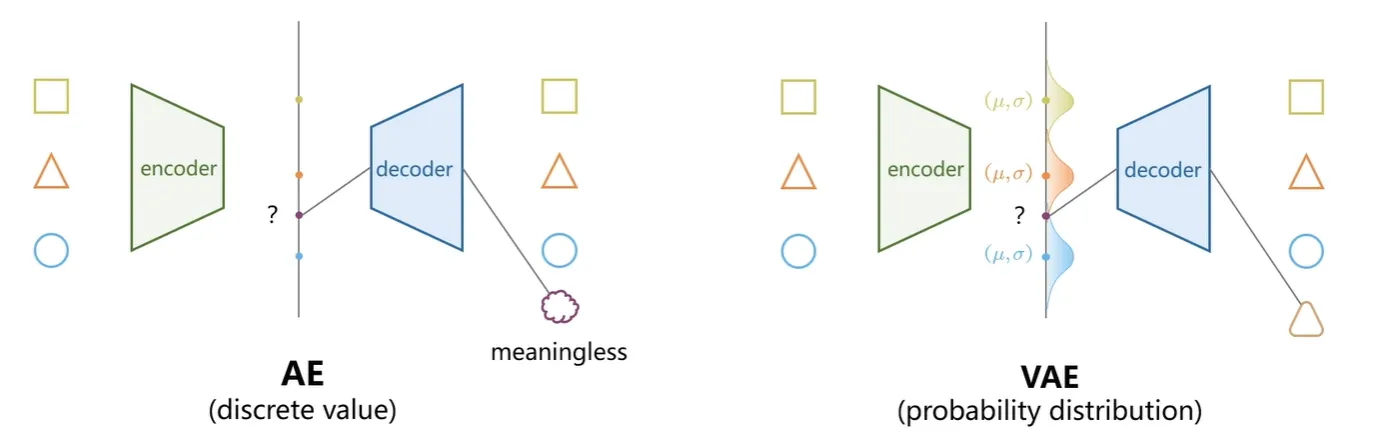
考虑到编码器降维后的 \(e(x)\) 是一个连续空间;解码器能够作用在 \(e(x)\) 上(即 \(d(e(x))\)
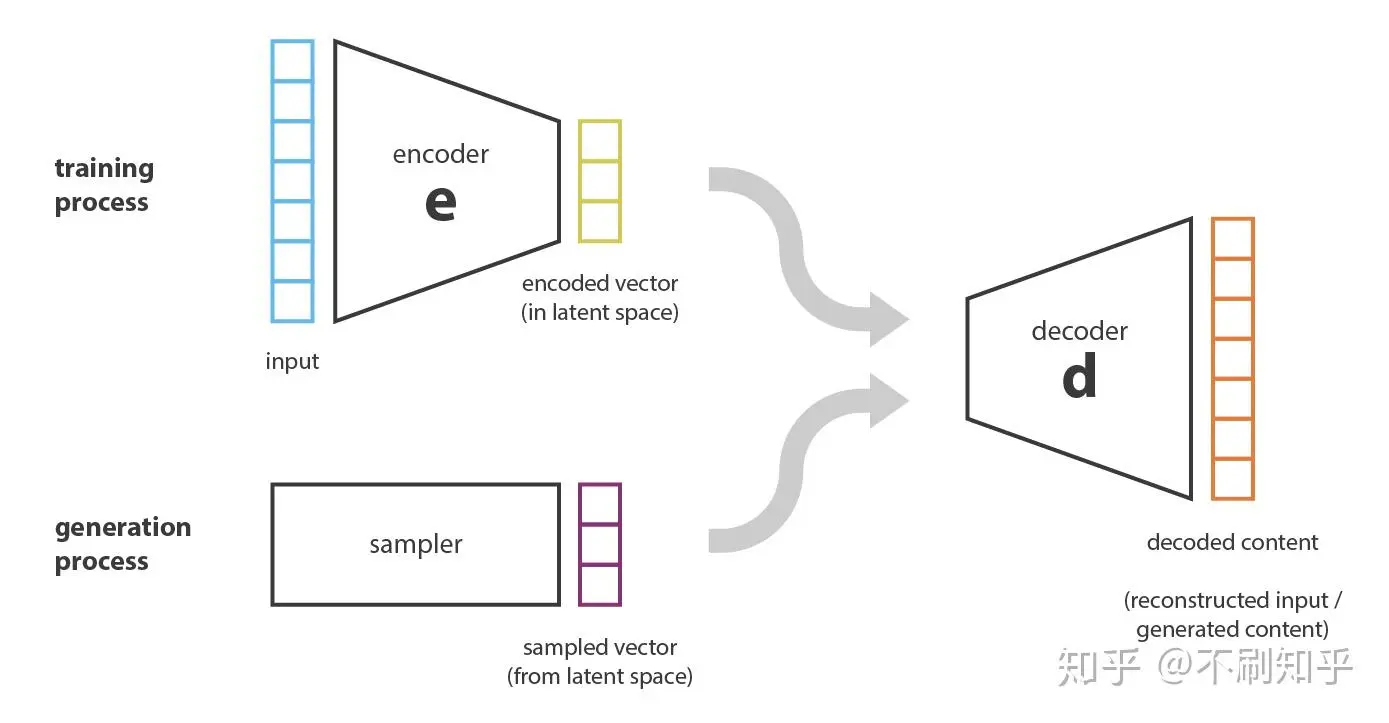
但是实际上自编码器的高自由度会导致严重的过拟合,仅以尽可能少的损失为目标进行训练,而不管隐空间如何组织。也就说,AE 的解码器只能恢复对应编码器编码的向量,而不能够生成图像。为了能够达到生成的目的,模型训练需要经过正规化以避免过度拟合,并确保隐空间具有能够进行数据生成过程的良好属性。

为了使生成过程成为可能,我们期望隐空间具有规则性,这可以通过两个主要属性表示:连续性(continuity,隐空间中的两个相邻点解码后不应呈现两个完全不同的内容)和完整性(completeness,针对给定的分布,从隐空间采样的点在解码后应提供“有意义”的内容
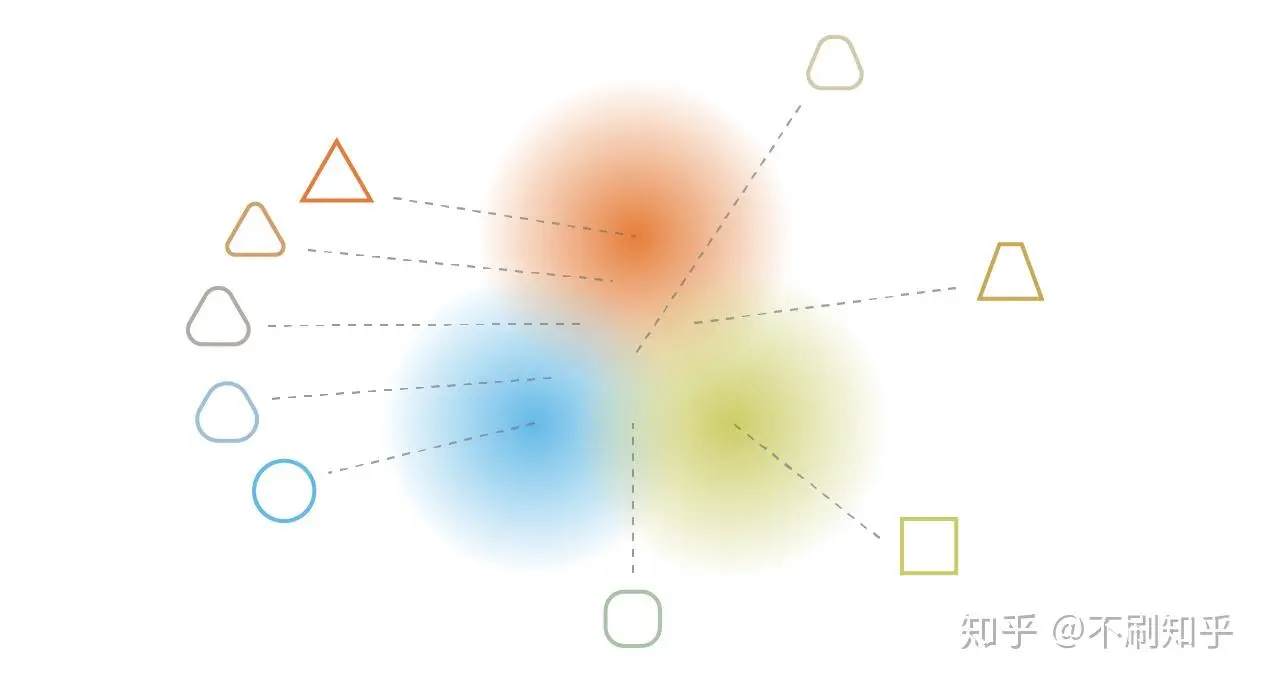
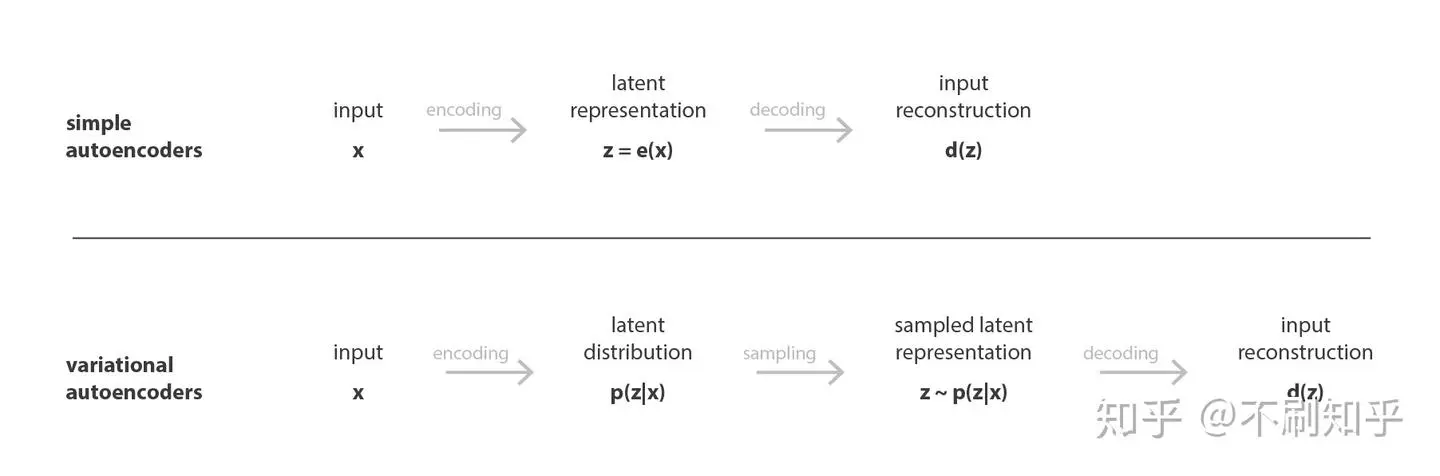
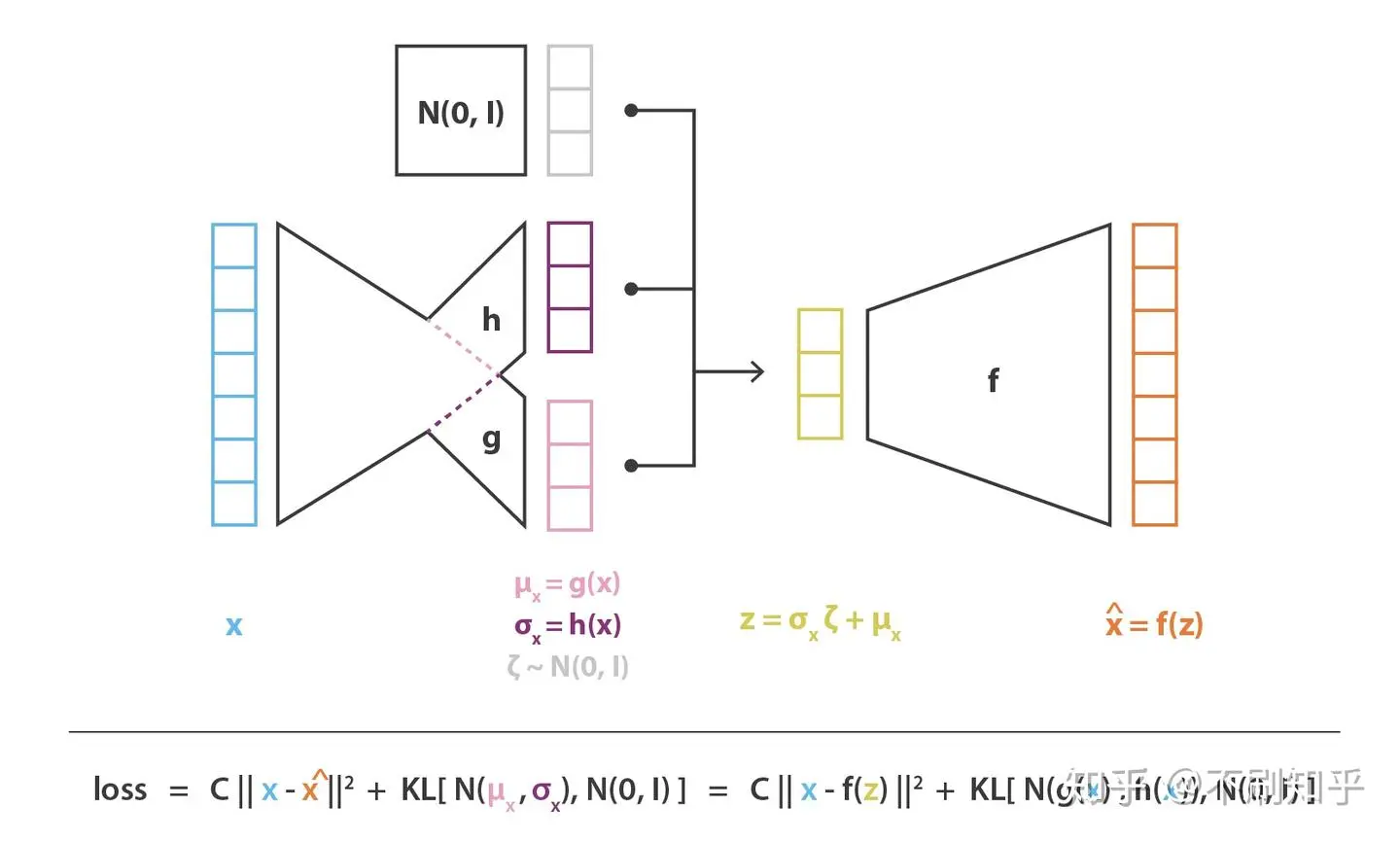
变分自编码器 (Variational Autoencoder, VAE) ¶
为了对模型进行正则化,VAE 通过引入概率框架来规整隐空间。
概率框架
我们用 \(x\) 表示数据变量,并假定 \(x\) 是由隐变量 \(z\) 生成的: 1. 具有先验分布 \(p(z)\) 采样隐变量 \(z\); 2. 从条件概率分布 \(p(x|z)\) 中采样数据 \(x\)。
这样看来,编码器可以用 \(p(z|x)\) 来定义,解码器则对应于 \(p(x|z)\)。
为了引入隐空间的某些正则化,我们对编码 - 解码过程进行了一些修改:我们不是将输入编码为隐空间中的单个点,而是将其编码为隐空间中的概率分布:
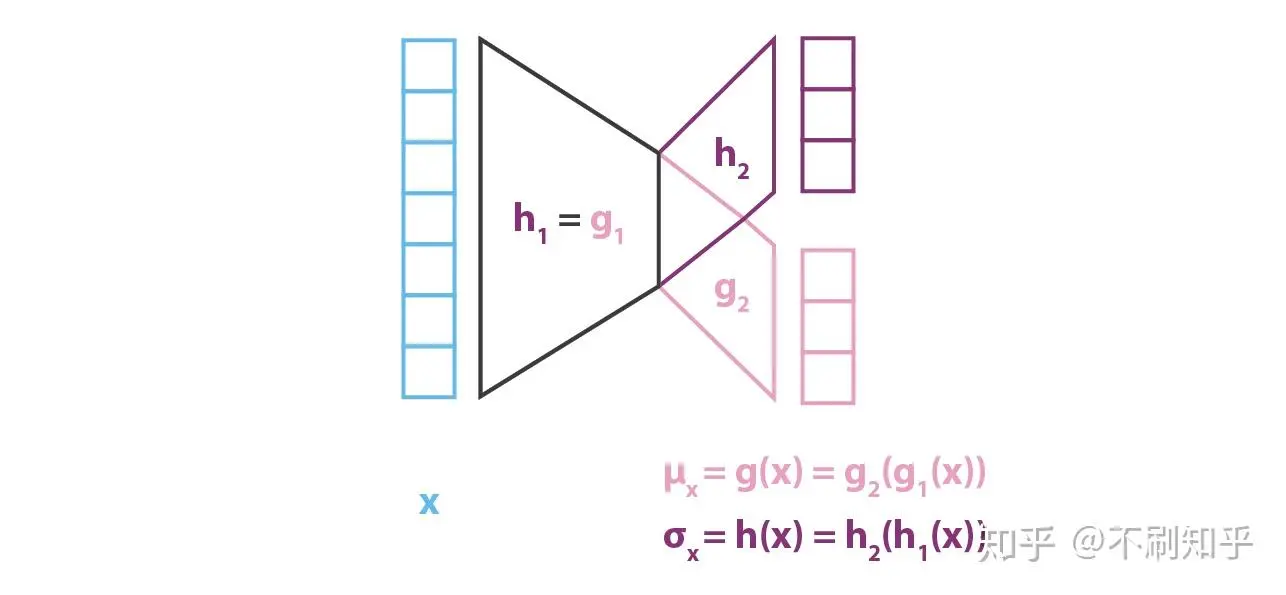
一般的,使用高斯分布 / 正态分布(便于采样,生成新数据
具体地,我们假设 \(p(z), p(x|z)\) 满足高斯分布,那么编码器 \(p(z|x)\) 也是高斯分布,我们使用 \(q_x(z)\) 来尝试近似 \(p(z|x)\),记为:
最后在损失函数中引入 KL 散度 (KL Divergence, similarity loss) 来约束编码器的输出接近一个正态分布:
向量量化变分自编码器 (Vector Quantized-Variational AutoEncoder, VQ-VAE) ¶
此时还有一个需要注意的地方:VAE 的隐状态是一个分布(是浮点数
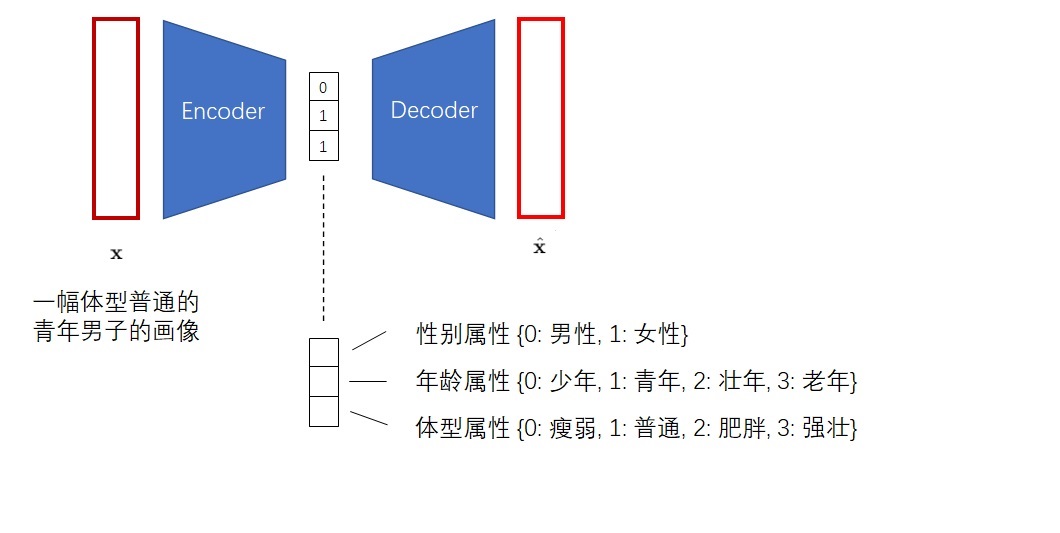
VQ-VAE 的作者认为,VAE 的生成图片质量不高,是因为图片被编码成了连续向量。而实际上,把图片编码成离散向量会更加自然。
比如我们想让画家画一个人,我们会说这个是男是女,年龄是偏老还是偏年轻,体型是胖还是壮,而不会说这个人性别是 0.5,年龄是 0.6,体型是 0.7。
所以 VQ-VAE 会尝试把图片编码成离散向量:
把图像编码成离散向量后,又会带来几个新的问题。
离散编码 ¶
第一个问题是,神经网络会默认输入满足一个连续的分布,而不善于处理离散的输入。
为了解决这一问题,我们可以借鉴 NLP 中对于离散单词的处理方法。为了处理离散的输入单词,NLP 模型的第一层一般都是词嵌入层,它可以把每个输入单词都映射到一个独一无二的连续向量上。这样,每个离散的数字都变成了一个特别的连续向量了。
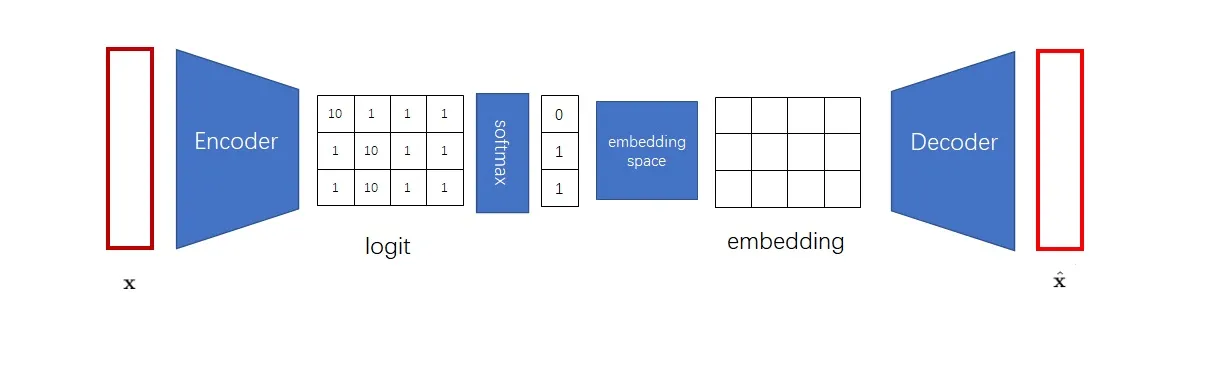
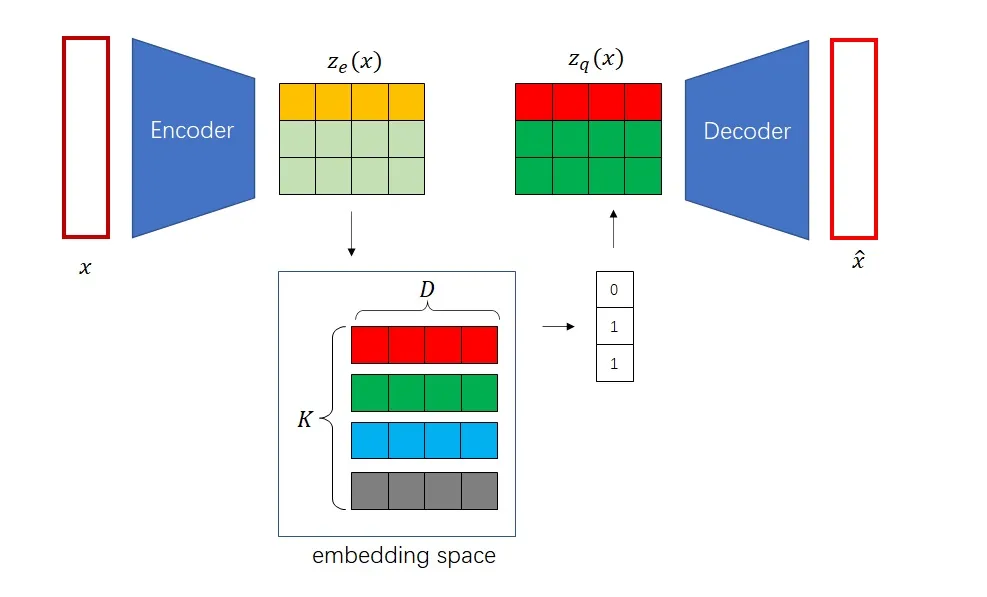
得到离散编码后,下一步我们又要根据嵌入空间把离散编码转回一个向量。可见,获取离散编码这一步有一点多余。VQ-VAE 选择将 encoder 的输出 logit 向量 \(z_e(x)\) 直接在嵌入空间中进行最近邻搜索得到 \(z_q(x)\) 并作为 decoder 的输入,从而实现离散编码。
采样生成 ¶
另一个问题是它不好采样。回忆一下,VAE 之所以把图片编码成符合正态分布的连续向量,就是为了能在图像生成时把编码器扔掉,让随机采样出的向量也能通过解码器变成图片。所以 VQ-VAE 本身根本不是一个图像生成模型;它和 AE 一样,只能很好地完成图像压缩和解压,把图像变成一个短得多的向量,把向量“恢复”为一个图像,而不支持随机图像生成。
https://www.spaces.ac.cn/archives/6760
首先,你读完整篇论文就会明白,VQ-VAE 其实就是一个 AE(自编码器)而不是 VAE(变分自编码器
为了生成图像,原作者利用了他在之前设计的一种图像生成网络 PixelCNN,能够拟合离散分布(例如能够输出图像某像素某通道的值的概率分布
梯度优化 ¶
还有一个问题是编码器训练优化时的梯度问题:由于 VQ-VAE 其实还是一个 AE,损失函数还是原图像和目标图像的重构损失;按照 AE 中的损失函数,可以得到在 VQ-VAE 中的重构损失 (reconstruct loss):
问题在于,其中的 \(z_q(x)\) 使用了 argmin,对于 \(x\) 不是一个可导函数,梯度在这里没法从解码器往前传到编码器处。VQ-VAE 使用了一个很精巧也很直接的方法,称为直通估计 (Straight-Through Estimator, STE);这种技术是说,前向传播和反向传播的计算可以不对应。你可以为一个运算随意设计求梯度的方法。基于这一技术,VQ-VAE 使用了一种叫做停止梯度 (stop gradient, sg) 的运算:
这就相当于梯度能够在函数的那个“端点”处复制传播,在 pytorch 中 (x).detach() == sg(x)。
嵌入优化 ¶
最后一个问题是我们的嵌入空间(即 codebook)怎么得到?我们期望中 \(z_e\) 与 \(z_q\) 很相近,所以考虑据此对损失函数进行正则化:\(L_e=||z_e(x)-z_q(x)||_2^2\)。
但作者认为,编码器和嵌入空间的学习速度应该不一样快(注意我们前面的离散编码部分是基于嵌入空间已经训练好讨论的
其中前半部分称为编码簿损失 (codebook loss),因为 sg 固定了编码器输出,希望嵌入空间向编码器输出靠齐;后半部分称为承诺损失 (commitment loss),在于约束编码器输出不要偏离嵌入空间中的向量太远。
最后的损失函数为(\(\beta\) 论文推荐为 0.25
残差量化变分自编码器 (Residual Quantized Variational Autoencoder, RQ-VAE) ¶
Quote
- VQVAE 在训练时 vq_loss 不稳定是什么原因
? (码本坍缩,利用率过低)
VQ-VAE 面临着码本坍缩的问题而训练困难,RQ-VAE 的改进在于将“一次查找码本”的过程改进为“使用残差多次查找码本”。
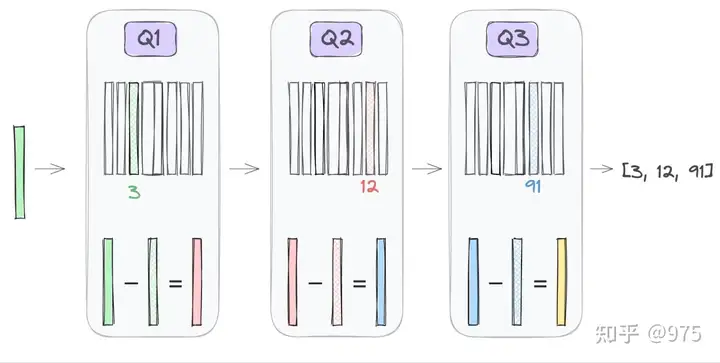
具体而言,对于查找 k 次的 RQ-VAE:
- 初始编码:由编码器给出初始编码 \(z_{e_0}\)
- 初始量化:对于第 \(i\) 次得到的编码 \(z_{e_i}\) 查找到的离散编码 \(z_{q_{i}}\)
- 计算残差:计算其差作为下一次的输入 \(z_{e_{i+1}}=z_{e_i} - z_{q_i}\)
- 残差量化:经过 \(k-1\) 轮重复 2-3 步骤,得到一组离散编码
- 编码聚合:对所有的离散编码求和得到解码器的输入 \(z_q = \sum_{i=0}^{k-1}z_{q_i}\)
在提出 RQ-VAE 的论文中,编码本在各轮是共享的,以缓解码本坍缩问题。
当然,我看 RQ-VAE 是为了生成式推荐,所以关注其在 TIGER 中的应用:
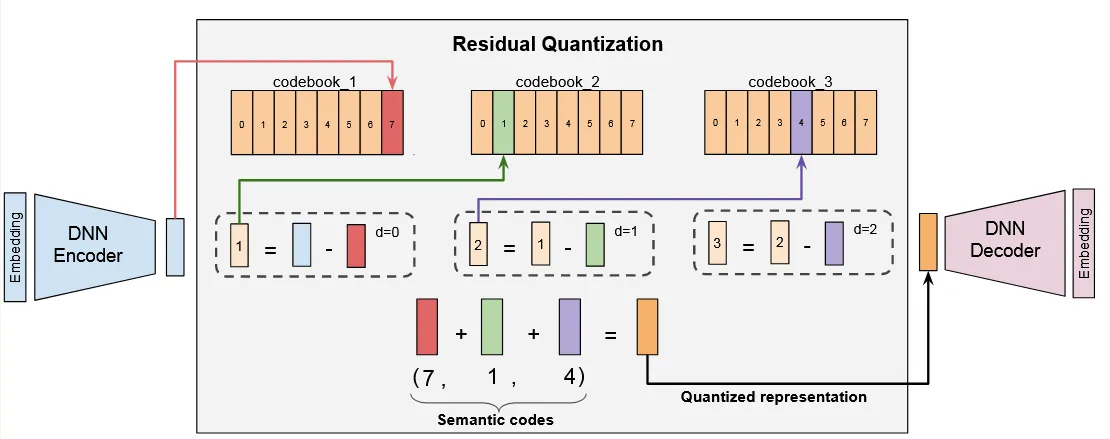
接下来我使用 TIGER 中的符号标记,出于方便用 \(E\) 表示 \(\mathcal E\),其余同理
- 编码器 \(\mathcal{E}\) 将输入编码为隐表征 \(z := \mathcal{E}(x)\)
- 记有 \(m\) 层编码本 (Cookbook),大小为 \(K\),第 \(d \in \text{range}(m)\) 层表示为 \(\mathcal{C}_d := \{e_k\}_{k=1}^K\)
- 对于第 \(0\) 层,残差记为 \(r_0 = z\)
- 对于第 \(d\) 层,\(c_{d-1} = \arg\min_{k} \|r_{d-1} - e_k\|\),残差记为 \(r_d = r_{d-1} - e_{c_{d-1}}\)
- 经过 \(m\) 层,得到一组大小为 \(m\) 的索引 \(\{c_d\}_{d=0}^{m-1}\),即为语义表征 (Semantic ID, sid)
- 最终的离散编码为 \(\hat{z} := \sum_{d=0}^{m-1}e_{c_{i}}\),作为解码器的输入。
这种递归的方式将输入由粗到细地进行了近似;在这里,为了体现“粗细粒度”的不同,每层的编码本是独立的;所以码本的总大小为 \(mK\)。
损失函数的形式与 VQ-VAE 类似(其中 \(\hat{x}\) 表示解码器输出,sg 表示 stop-gradient