指标提升 ¶
指标提升一般需要综合提升推荐系统的整体性能,以及针对业务和结合经验做出调整。常见的提升手段如下(也是对前面学习内容的总结回顾)
- 改进、添加召回模型,改进粗排和精排模型; 提升召回、排序中的多样性
- 对新用户、低活用户;新物品、低曝光物品予以照顾(见 Improvement_05)
- 结合利用评论、转发、关注等稀疏交互行为(见 Improvement_06)
评价指标 ¶
评估整个推荐系统的性能时,对于知乎、Bilibili、小红书等平台,日活用户数 (DAU) 和用户留存率 (LT) 是最核心的指标,电商平台则可能以交易率、营业额为主。用户使用时长、总曝光数、总浏览数则为较为次要的指标。
留存
工业界常用 LT7/LT30 衡量用户的留存。
假设用户在 \(t_{0}\) 天浏览了平台,未来 7/30 天用户浏览平台的天数即为 \(t_{0}\) 对应的 LT7/LT30;LT 的提高往往意味着用户体验提升(除非 DAU 显著降低
- 动手实现推荐系统评价指标 AUC,GAUC,NDCG,HitRate,MRR,Recall,LogLoss¶
召回优化 ¶
双塔模型 ¶
非常多在讲解双塔模型时已经提及,这里进行简单回顾:
- 优化正负样本:在样本选取部分提及
- 改进神经网络:经典的双塔模型使用的是全连接层构成的神经网络,可以使用 DCN 等 1 替换优化,在用户塔引入 LastN
- 使用多向量模型
: (标准的双塔模型也叫单向量模型)如下所示,物品塔输出多个向量,每个向量的长度与物品塔输出向量长度一致(物品塔只输出一个,因为物品变化慢需存储)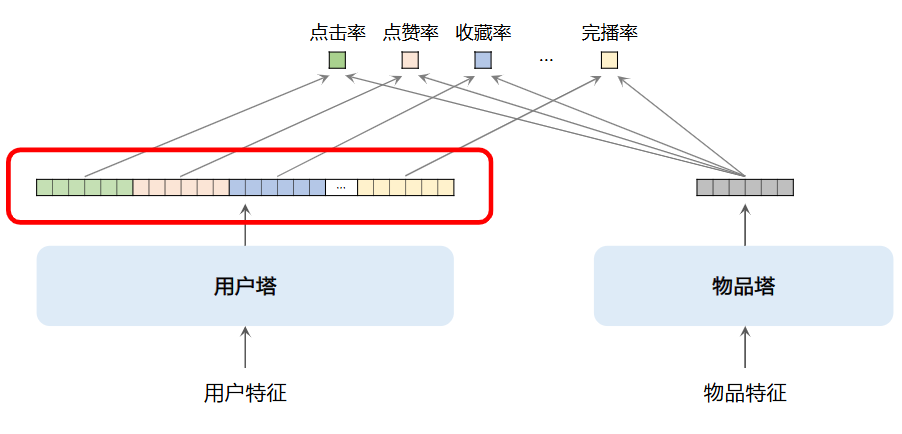
multi-vector
4. 改进训练方法:在模型训练部分提及
Item to Item (I2I)¶
I2I 基于相似物品进行召回,最常见用法为 U2I2I (User -> Item -> Item)。
衡量物品间相似度的方法我们在 Collaborative Filtering 中也提及了,ItemCF 和 Swing & Surprise 已经足够了,改进空间较小。
在特定场景下 U2A2I 和 U2A2A2I (A 表示 author)也是不错的选择。
排序优化 ¶
精排改进 ¶
模型改进 ¶
在精排过程中,无论物品特征还是用户特征,影响处理方法的是特征是否离散,因而精排模型可以表示为如下图所示
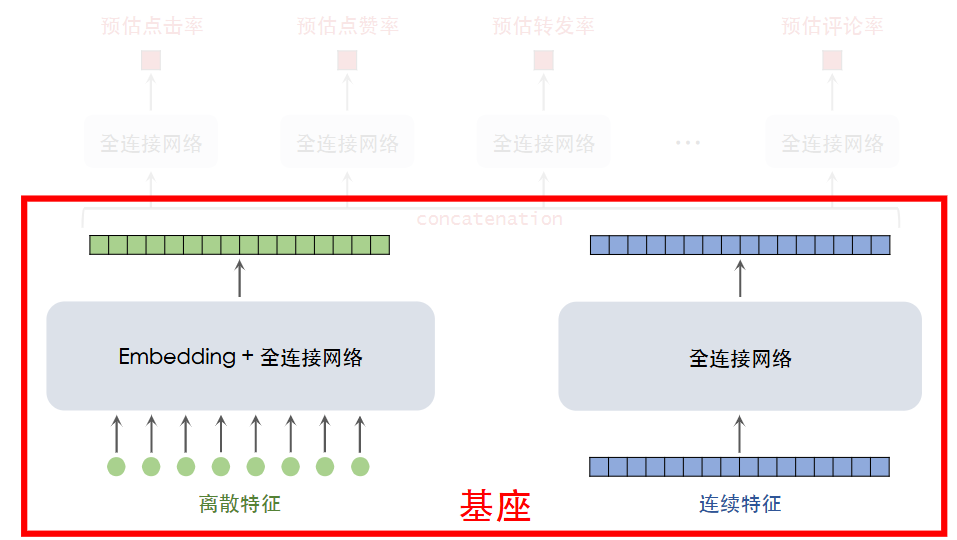
精排模型专注于准确性,可以适当的复杂化:
- 参考于 LLM 的放缩法则,我们可以将基座部分加宽加深,期望能够获得更好的嵌入向量,预测更准确;
- 做特征交叉以更好地捕捉特征,具体之前也讲过,如 LHUC 和 Bilinear Cross;
- 补充特征信息,如多模态内容特征
多目标预估优化 ¶
- 除去点击率、点赞率、转发率、评论率等指标,可以探索更多的指标并融合进入最后的评分公式。
- MMoE 等结构并不是总能够发挥作用,尝试后取舍;也可以尝试 PLE 等结构
粗排改进 ¶
粗排模型综合考量速度和精度,多向量双塔模型和三塔模型都是可行的选择;三塔模型的效果一般更好但工程实现难度较高。
有时为了让粗排模型与精排模型更为一致(不会有明显的分歧
- Pointwise 蒸馏
- 对于真实值 y 和精排预估值 p,以 \(\frac{y+p}{2}\) 作为粗排模型的预估目标
- Pairwise 或 Listwise 蒸馏
- 对于 k 个候选物品,让粗排模型和精排模型做排序
- 以精排模型排序结果为“真实值”,基于 logistic loss 对粗排模型进行训练
序列优化 ¶
基于用户的 LastN 交互行为,我们已经学习了 DIN 和 SIM 对用户的行为序列建模;SIM 是对于物品序列进行筛选后再做 DIN,改进思路其实也只是如此:
- 增加序列长度期望预估更加精准,但是开销增大
- 使用类目、聚类等方法加快筛选
- 对于行为序列中的物品,适当使用更多物品特征
老汤模型 ¶
在召回和更新部分我们知道模型每天都在进行训练更新,这可能导致一个问题:当我们尝试使用一个新的架构判断是否更优时,老模型训练更久,即便老架构不如新架构也会因为参数等训练的更好、结果更优。且线上服务不能够因为测试而停止更新老模型,那将带来巨大的损失。
如何快速判断新模型结构是否优于老模型
由于 embedding 层往往比全连接层更大、参数更多、学习更慢,可以让新模型复用老模型的 embedding 层,且都随机初始化全连接层,使用相同的数据(如最近 n 天)进行训练,比较最后的结果以比较两者的架构。
如何快速追平线上老模型?
老模型每天也在训练更新,更优架构的新模型实际效果优于前沿老模型才能够正式替换上线。
为了更快实现效果追平,可以尽可能多使用已经训练好的 embedding 层(随模型架构变化不大
-
PDN, DR, SINE, M2GRL 都是可以考虑的召回渠道 ↩