ResNet¶
modified according to https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E5%9B%9B%E7%AB%A0/4.1%20ResNet.html#
https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
Gradient vanishing and explosion¶
梯度消失和梯度爆炸的根源主要是因为深度神经网络结构以及反向传播算法,目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过反向传播的方式,指导深度网络权值的更新。误差梯度是神经网络训练过程中计算的方向和数量,用于以正确的方向和合适的量更新网络权重。
在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。 网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。 在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
而在某些情况下,梯度会变得非常小, 网络层之间的梯度(值小于 1.0)重复相乘导致的指数级变小会产生梯度消失。在最坏的情况下,这可能会完全停止神经网络的进一步训练。例如,传统的激活函数 ( 如双曲正切函数 ) 具有范围 (0,1) 内的梯度,反向传播通过链式法则计算梯度。这样做的效果是,用这些小数字的 n 乘以 n 来计算 n 层网络中“前端”层的梯度,这意味着梯度 ( 误差信号 ) 随 n 呈指数递减,而前端层的训练非常缓慢。最终导致更新停滞。
针对这个问题,他们提出了ResNet以期望解决这个问题,ResNet 的出现也让神经网络逐渐真正走向深度神经网络。ResNet 最大的贡献在于添加了 shortcut connection 将输入直接连接到后面的层,一定程度缓解了梯度消失和梯度爆炸并提高了深度神经网络的效果。
# convolutional layers
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation,
)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=1,
stride=stride,
bias=False)
BasicBlock and BottleNeck¶
ResNet 网络是由很多相同的模块堆叠起来的。
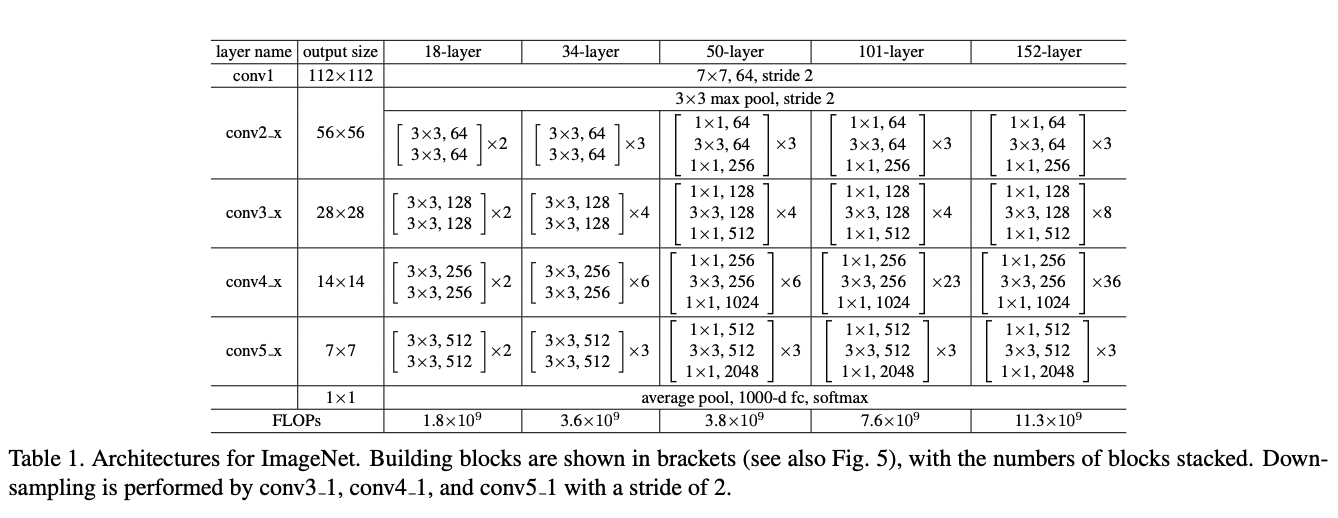
观察上面各个 ResNet 的模块,我们可以发现 ResNet-18 和 ResNet-34 每一层内,数据的大小不会发生变化,但是 ResNet-50、ResNet-101 和 ResNet-152 中的每一层内输入和输出的 channel 数目不一样,输出的 channel 扩大为输入 channel 的 4 倍(即 expansion
) ,除此之外,每一层的卷积的大小也变换为 1,3,1 的结构。基于这个发现,我们可以将 ResNet-18 和 ResNet-34 的构成模块当作一类,ResNet-50、ResNet-101 和 ResNet-152 这三类网络的构成模块当作一类。
为了保证代码具有可读性和可扩展性,ResNet 在设计时采用了模块化设计,针对不同大小的 ResNet,书写了 BasicBlock 和 BottleNeck 两个基本模块(分别为下面的左右两图
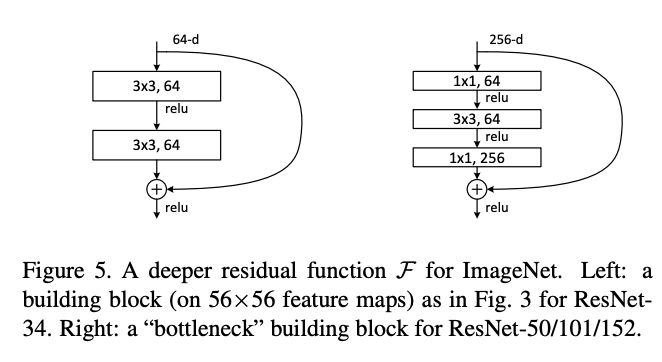
其中侧边的连接即为 shortcut connection / downsample ,一般对 x 进行简单的线性映射匹配纬度即可(最简单的情况即为使用 x 本身,输出 F(x)+x 。这个支路用于传递底层信息,使得模型能够训练的更深。BottleNeck 结构先通过 1x1 卷积核减少通道数,中间的普通卷积层输入输出通道数相同,最后的 1x1 卷积核又增加通道数,从而将输出通道数恢复到输入通道数。
BasicBlock 模块用来构建 resnet18 和 resnet34;BottleNeck 模块用来构建 resnet50,resnet101 和 resnet152。
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x # x 给自己先备份一份
out = self.conv1(x) # 对x做卷积
out = self.bn1(out) # 对x归一化
out = self.relu(out) # 对x用激活函数
out = self.conv2(out) # 对x做卷积
out = self.bn2(out) # 归一化
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 进行downsample
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4 # 对输出通道进行倍增
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
# Bottleneckd forward函数和BasicBlock类似
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]], # 选择基本模块
layers: List[int], # 每一层block的数目构成 -> [3,4,6,3]
num_classes: int = 1000, # 分类数目
zero_init_residual: bool = False, # 初始化
#######其他卷积构成,与本文ResNet无关######
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
#########################################
norm_layer: Optional[Callable[..., nn.Module]] = None, # norm 层
) -> None:
super().__init__()
_log_api_usage_once(self)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64 # 输入通道
#######其他卷积构成,与本文ResNet无关######
self.dilation = 1 # 空洞卷积
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
#########################################
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 通过_make_layer带到层次化设计的效果
self.layer1 = self._make_layer(block, 64, layers[0]) # 对应着conv2_x
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0]) # 对应着conv3_x
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1]) # 对应着conv4_x
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2]) # 对应着conv5_x
# 分类头
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 模型初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck) and m.bn3.weight is not None:
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock) and m.bn2.weight is not None:
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
# 层次化设计,创建由多个块构成的序列层
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]], # 基本构成模块选择
planes: int, # 输入的通道
blocks: int, # 模块数目
stride: int = 1, # 步长
dilate: bool = False, # 空洞卷积,与本文无关
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None # 是否采用下采样
####################无关#####################
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
#############################################
# 当步长不为 1 或者 输入通道不等于预期输出通道数时,进行下采样,基于序列层构建下采样模块
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
# 使用layers存储每个layer
layers = []
# 添加第一个块,包含下采样操作
layers.append(
block(
self.inplanes,
planes,
stride,
downsample,
self.groups,
self.base_width,
previous_dilation,
norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
# 将layers通过nn.Sequential转化为网络
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x) # conv1 x shape [1 64 112 112]
x = self.bn1(x) # 归一化处理
x = self.relu(x) # 激活函数
x = self.maxpool(x) # conv2_x的3x3 maxpool x shape [1 64 56 56]
x = self.layer1(x) # layer 1
x = self.layer2(x) # layer 2
x = self.layer3(x) # layer 3
x = self.layer4(x) # layer 4
x = self.avgpool(x) # 自适应池化
x = torch.flatten(x, 1)
x = self.fc(x) # 分类
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)